
二语水平在三语习得者反向迁移中的调节作用
2021-11-26 07:24陈玉娟
山东理工大学学报(社会科学版) 2021年6期
毛 毳,陈玉娟
引言
近年来,多语言习得研究在理论语言学和应用语言学的各个分支领域已引起广泛关注,其中的一个核心问题是跨语言影响(crosslinguistic influence,CLI)的性质,即语言迁移的来源、方向及其影响因素。 在过去的二十多年里,关于一语[1]、二语[2-6]到三语的正向迁移的研究蓬勃发展,而反向迁移的研究则仍处于起步阶段。 对语言反向迁移的研究有助于全面剖析语言习得中所涉及的多种进程和影响因素。
与二语习得相比,三语习得是一个更为复杂的进程,涉及到更多的影响因素。 Murphy[2]认为三语习得过程中最主要的影响因素包括语言水平,目标语言的接触和使用量,语言组合模式,年龄及教育背景。
三语习得领域关于语言水平的研究多聚焦于受试者二语水平和三语水平之间的相关性,本文则尝试探讨二语水平是否调节三语对二语的反向迁移。 Ahn 和Mao[7]发现汉英韩语言组合的三语学习者在二语反身代词加工时其准确率受三语影响,即证实存在三语(韩语)对二语(英语)习得的反向迁移,而影响此反向迁移的要素有哪些尚不明确。 因此,本文采用与Ahn 和Mao[7]相同的实验设计,控制受试者的二语水平,从而探究高、低两个二语水平是否调节三语对二语反身代词加工的反向迁移。 如果二语水平影响该反向迁移,其影响幅度在不同群体中是否存在差异? 语言水平是促进还是抑制该调节作用?
一、文献综述
二语习得和三语习得领域对反身代词约束原则习得研究的侧重点有所不同。 前者主要关注局域性和方向性等句法特征的习得,句法和语用因素的交互作用,以及调节语言迁移的因素;而后者则侧重探究语言迁移的来源、方向,以及影响三语习得的其他因素。
在二语习得领域,语言水平是否影响二语反身代词的习得颇具争议。 Hirakawa[8]发现一语对二语反身代词的加工产生负迁移,且不同年级的受试反身代词加工的正确率没有显著差别。Demirci[9]发现土耳其语-英语受试者反身代词先行词的选择优先遵循语用约束原则而非句法约束原则,表明受试对英语反身代词的理解受到一语土耳其语的影响,且该影响并未随二语水平和输入量提高而消失。 Lee[10]发现不同水平的韩语-英语学习者英语反身代词约束性原则的加工更多依赖语境因素而非句法原则。 Sperlich[11]对不同二语水平的韩语-汉语受试者汉语反身代词的习得进行比较,发现不同组别的受试均依赖语用原则而非句法原则选择先行词。
上述研究均表明不同二语水平的受试者反身代词的加工模式大致一致,而另一些研究则发现二语水平影响反身代词的加工。 Akiyama[12]比较了不同语言水平的日语-英语学习者英语反身代词局域性原则的习得情况,发现限定性-非限定性双子句的不对称性在早期就出现并持续存在。在限定性双子句条件下,长距离约束原则的习得在不同二语水平的组别之间有显著差异。Jiang[13]发现二语水平对反身代词局部约束域的习得有明显的调节作用,中等水平学习者在限定性-非限定性双子句之间的不对称性最为显著。
在三语习得领域关于反身代词习得的研究多聚焦于不同语言组合的学习者约束原则的习得路径,且主要关注由一语、二语向三语的正向迁移。Tsang[14]研究了塔加洛语-英语-粤语学习者三语粤语反身代词的习得情况,发现学习者未受一语、二语语法规则影响,在限定性和非限定性双子句中均明显偏好短距离约束。 这一结果可以归因于“最小距离”偏好,即将反身代词与最接近的先行词相照应,而忽略更远的选项,以获得信息的即时理解。 Yoshimura 等[15]比较了两个二语组别(英语-日语和汉语-日语)和两个三语组别(汉语-英语-日语和土耳其语-英语-日语)日语反身代词的习得情况,发现两个二语组和土耳其语-英语-日语三语组在真值条件下,短距离约束和长距离约束理解的准确率存在显著不对称性,因此推断局域性原则是语言习得的核心概念,一语并未在二语或三语长距离约束原则的习得过程中发挥作用。
Tsang[16-17]尝试探讨三语习得领域是否存在三语向二语的反向迁移,发现相对于二语组别,三语组别更容易发现其一语和二语之间的语言相似性及差异性,而更高的语言敏感度或可归功于三语组别有更为丰富的跨语言经验。 三语水平在反向迁移中起到调节作用,而该调节作用只有当学习者的三语水平达到一定阈值时才会发生。
本研究采用与Ahn 和Mao[7]相同的实验设计,考察在反身代词约束原则的习得过程中,三语习得者的二语水平是否对三语向二语的反向迁移产生调节作用,以期丰富三语习得领域反向迁移影响机制的研究,进一步揭示三语习得者的语言发展路径。
二、研究方法
招募汉英、汉英韩及韩英三个不同组别的受试,依据其英语水平将每组受试分为高、低语言水平组。 受试在实验中完成剑桥英语水平快速定位测试、基于故事的真值判断任务(TVJT)以及语言背景调查问卷。 所有测试均为线下测试,在课堂上进行。 三项测试的指令为英语。 测试没有时间限制,要求受试快速、准确地完成所有内容。
山东省某大学共计120 名中国本土大学生(42 名男生,78 名女生;平均年龄为 19.5 岁)参加本次实验并完成所有实验任务。 所有受试均报告自小学起开始学习英语(开始习得英语的平均年龄为8.65 岁),无课堂以外的英语学习经历。 其中73 人(汉英组别)主修电子与通信工程,且无第三语言学习经历;47 人为韩语专业一、二年级学生(汉英韩组别,开始习得韩语的平均年龄为18.11 岁)。 此外,本研究在韩国首尔某大学招募了44 名韩国本土大学一年级学生(韩英组别)参加测试(10 名男生,34 名女生,开始习得英语的平均年龄为8.26 岁),无课堂之外英语学习经历,无第三语言学习经历。
真理价值判断任务的设计基于汉语、英语和韩语中反身代词的局域约束域跨语言差异。 英语只允许短距离约束,而汉语和韩语则允许短距离和长距离约束,如下列所示:
(1)a. Johnithought Maryjtrusted himself*i/j.
b.Johni认为 Maryj相信自己i/j。
c.JohniMaryj-ka cakii/j-lul sinloyhaysstako sayngkakhayssta.
在(1)a 中,英语反身词himself 必须以小句主语Mary,而不是以主句主语John 作为其先行词;而在(1)b 和(1)c 中,中文的“自己”和韩文的caki既可以取主句主语John,也可以以内嵌主语Mary 作为其先行词。 由此可见,英语中的反身代词受局部约束域限制,而汉语和韩语的反身代词则可以是长距离约束的。
然而,Pollard 和 Sag[18-19]指出,英语反身代词中有一个类别允准长距离约束,称为exempt anaphors,如下例所示:
(2)a. Bill said that the rain had damaged pictures of himself.
b. Max boasted that the queen invited Lucie and himself for a drink.
c. Joe worried that his girlfriend was pulling away from himself.
d. John decided that Mary’s remarks had been intended for himself.
e. Tom thinks that Julie admires everyone but himself.
以上各句中的反身代词的照应均违反局部约束原则,以主句主语为先行词,即允准长距离约束。 因此,英语中的这类特殊反身代词与正常反身代词在约束现象上构成鲜明对比。 上述两类反身代词的约束原则加工机制不是本研究探讨范围,仅作为区分、设计实验项目的依据。
实验使用的基于故事的真值判断任务,由Yoshimura 等[15]设计的任务改编而来。 受试者阅读两个对话者之间3~5 个话论的简短对话,根据阅读内容判断随后的测试句为真或假。 对话和测试句均为英语,合计38 个题目。 测试开始前有两个练习题目,以确保受试者能正确理解并顺利完成测试环节的任务。 测试句在约束类型(长距离/短距离约束)、句子类型(限定性/非限定性双子句)和真值(真/假)三个水平上平衡,测试句子只允准一个可照应成分,句子的真值由故事内容所决定。 所有的测试句子在语法上都是正确的,如测试句为假,则因为反身代词与语法允准的先行词之间的照应关系与故事叙述的内容不一致,而非因为照应关系本身违反了约束原则。
三、结果与讨论
本实验旨在探讨二语(英语)水平是否对汉英、汉英韩和韩英三个组别受试者反身代词照应关系解释的正确率存在调节作用。 依据受试者剑桥英语水平快速定位测试(第二版)的成绩将三个组别的参与者各分层为高、低两个水平组。
(一)高、低水平组的划分
用SPSS 25.0 对受试者的二语分数进行描述性统计,以确定高、低水平组之间的分界线,具体见表1。
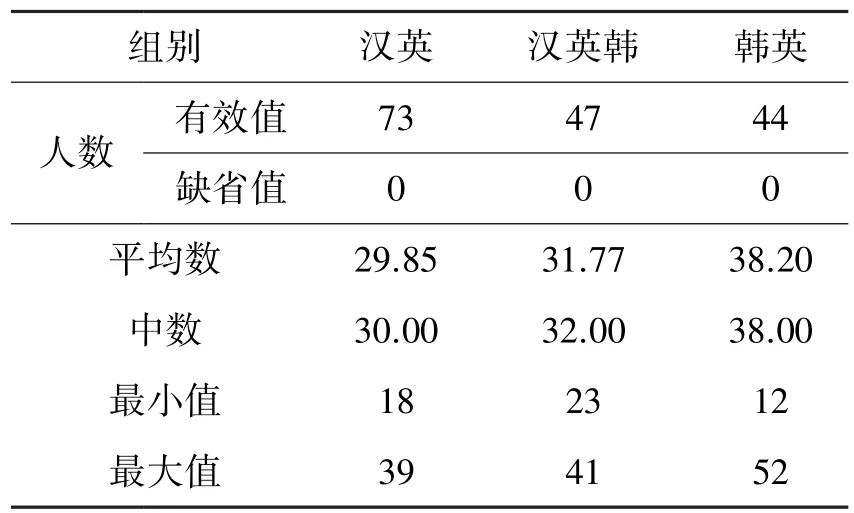
表1 英语水平测试分数描述性统计结果
如表1 所示,汉英、汉英韩和韩英组的二语水平测试得分没有缺失值。 为探究不同组别受试者的二语水平对其二语反身代词约束原则的加工是否具有调节作用,以各组测试分数的中位数(汉英组中位数为30,汉英韩组为32,韩英组为38)为分界线,将各语言组的受试者分为低水平和高水平组(汉英-低,汉英-高;汉英韩-低,汉英韩-高;韩英-低,韩英-高),以保证各语言组内高、低水平的受试者数量平衡。 图1 为三个语言组别二语水平分组的结果。
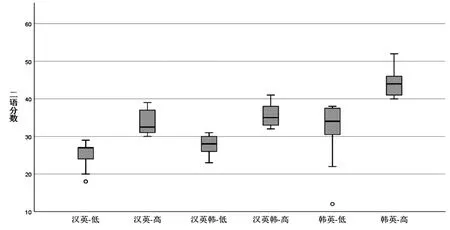
图1 各语言组别二语水平分组情况
(二)二语分数与真值判断任务分数
受试者真值判断任务得分采用D-Prime 评分(d's),即根据受试者“命中”(hits,简写为H)和“误报”(false-alarms,简写为F)的比例来辨别答题准确度[20]。d's得分越高,表明 H 和 F 之间的差异越大,受试者的敏感性越高。
表2 为汉英、汉英韩和韩英组的高、低水平组别的真值判断任务d's评分的描述性数据。
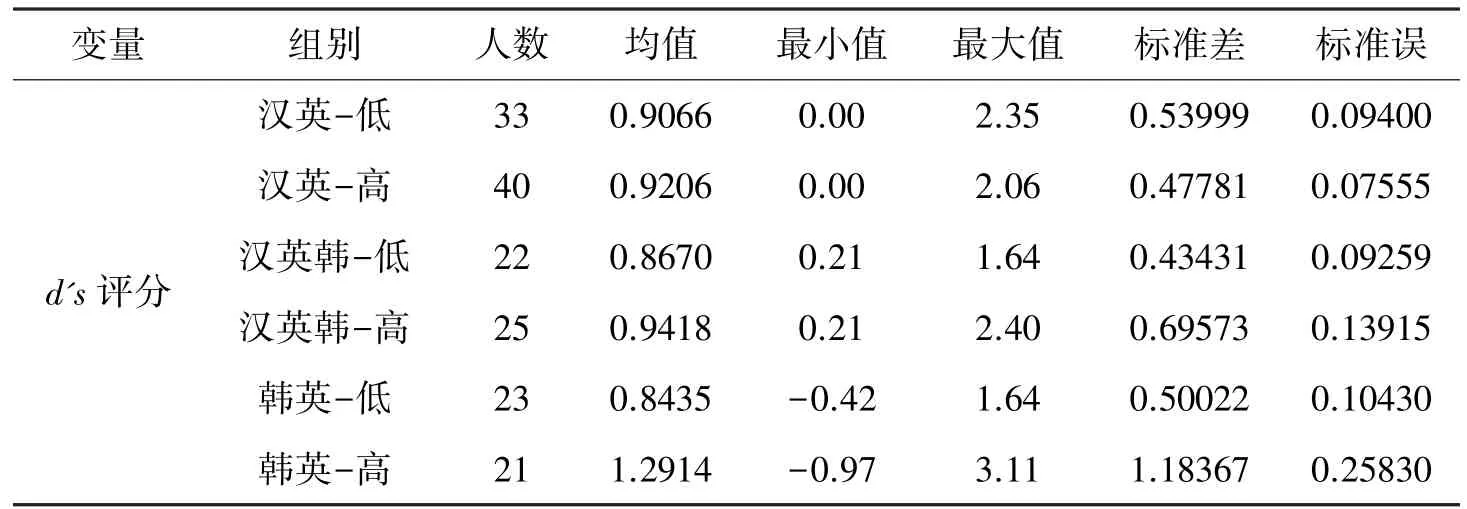
表2 各语言组别真值判断任务d's 得分
为检验高、低水平组的二语得分是否存在显著差异,并探索不同语言水平的组别在反身代词约束原则的加工上是否存在显著差异,即高、低水平组别在真值判断任务d's评分上是否存在显著差异,下文以汉英、汉英韩和韩英组为研究对象,以二语水平为自变量,以二语分数和d's分数为因变量,进行三次独立样本T 检验,结果见表3。
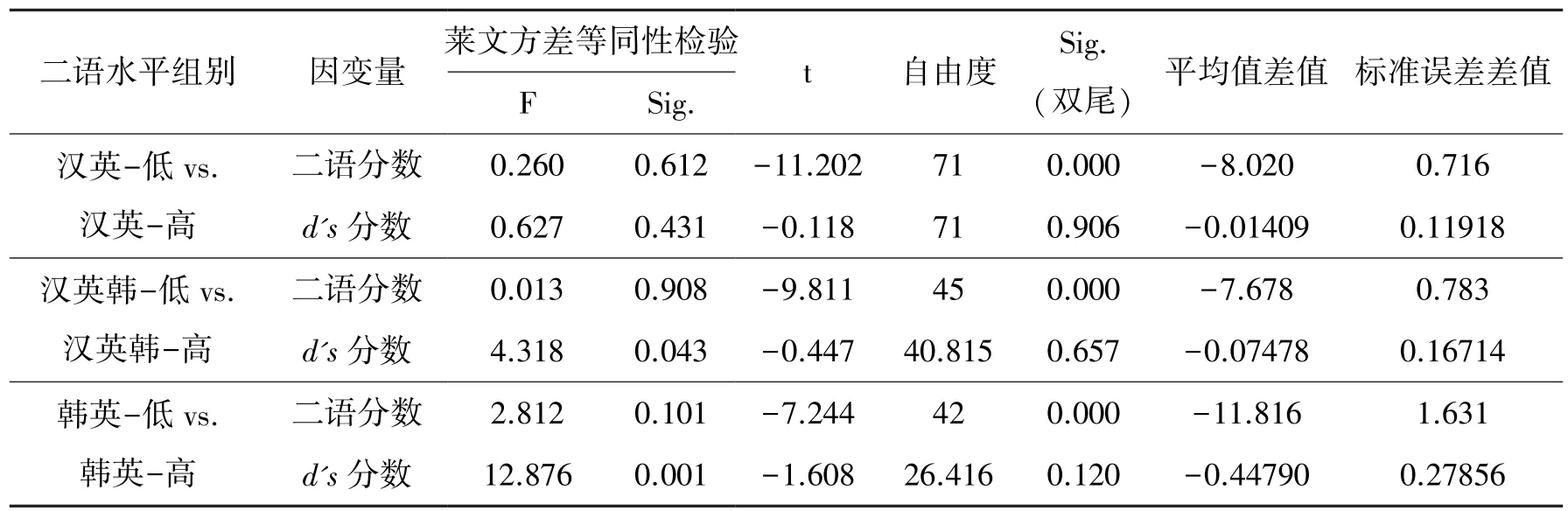
表3 各语言组别二语分数和真值判断任务d's 分数T 检验结果
表3 的结果再次证实各语言组内二语高、低水平组之间二语分数存在显著差异。 在汉英语言组内,汉英-低(均值=25.45,标准差=3.103)与汉英-高(均值=33.48,标准差=2.996)组别之间的二语分数存在差异显著(t(71)=-11.202,P =0.000),而汉英-低(均值=0.9066,标准差=0.5400) 和汉英-高(均值=0.9206,标准差=0.4778)在d's分数上的数值差异则没有达到显著水平(t(71)= -0.118,p =0.906)。 同样,汉英韩-低(均值=27.68,标准差=2.607)在二语水平测试中的得分显著低于汉英韩-高(均值=35.36,标准差=2.737)(t(45)= -9.811,p =0.000),但在d's评分中的差异则没有达到显著水平(t(45)= -0.447,p = 0.657),尽管汉英韩-低(均值 =0.8670,标准差=0.4343)和汉英韩-高(均值=0.9418,标准差=0.6957)水平之间存在数值差异。 韩英组内低、高水平组之间的二语分数和d's分数的数值差异最大。 韩英-低(均值=32.57,标准差=6.515)的平均二语得分显著低于韩英-高(均值=44.38,标准差=3.827),而d's评分差异则没有达到显著水平(t(42)= -1.608,p =0.120),韩英-低(均值=0.8435,标准差=0.5002)低于韩英-高(均值=1.2914,标准差=1.1837)。
(三)短距离和长距离约束条件下d's 分数对比
Ahn 和Mao[7]对短距离和长距离约束条件下反身代词照应关系理解的准确率进行了比较,发现汉英、汉英韩和韩英三个语言组别的表现不一致。 韩英组在短距离约束条件下的准确率显著高于其在长距离约束条件下的准确率。 汉英韩组别在两种约束条件下的准确率差异接近但未达到显著水平,而汉英组别在两种约束条件下的准确率则没有差异。 由于短距离约束和长距离约束条件下的反身代词照应关系理解准确率的不对称性仅出现在韩英组受试者的结果中,而韩英组的二语分数均值显著高于汉英韩组和汉英组,因此二语水平是否对短距离-长距离约束不对称性的存在起决定作用有待进一步探讨。
采用同样的方法分别计算短距离和长距离约束条件下的d's分数,分别得出汉英组、汉英韩组和韩英组高、低水平组受试者在短距离(SD-d's)和长距离(LD-d's)约束条件下的d's分数,结果见表4。
表4 中的描述性数据表明,在短距离约束条件下,来自汉英、汉英韩和韩英组的高、低水平组表现出一致的趋势,即高水平组的d's分数均值高于低水平组。 尤为引人注意的是,汉英韩-低(均值=0.8266,标准差=1.045)和汉英韩-高(均值=1.034,标准差=0.958)水平组别之间,汉英-低(均值=0.7015,标准差=0.893)和汉英-高(均值=0.9419,标准差=0.841)水平组别之间,以及韩英-低(均值=0.8186,标准差=0.824)和韩英-高(均值=1.349,标准差=1.102)水平组别之间的差异呈递增趋势。
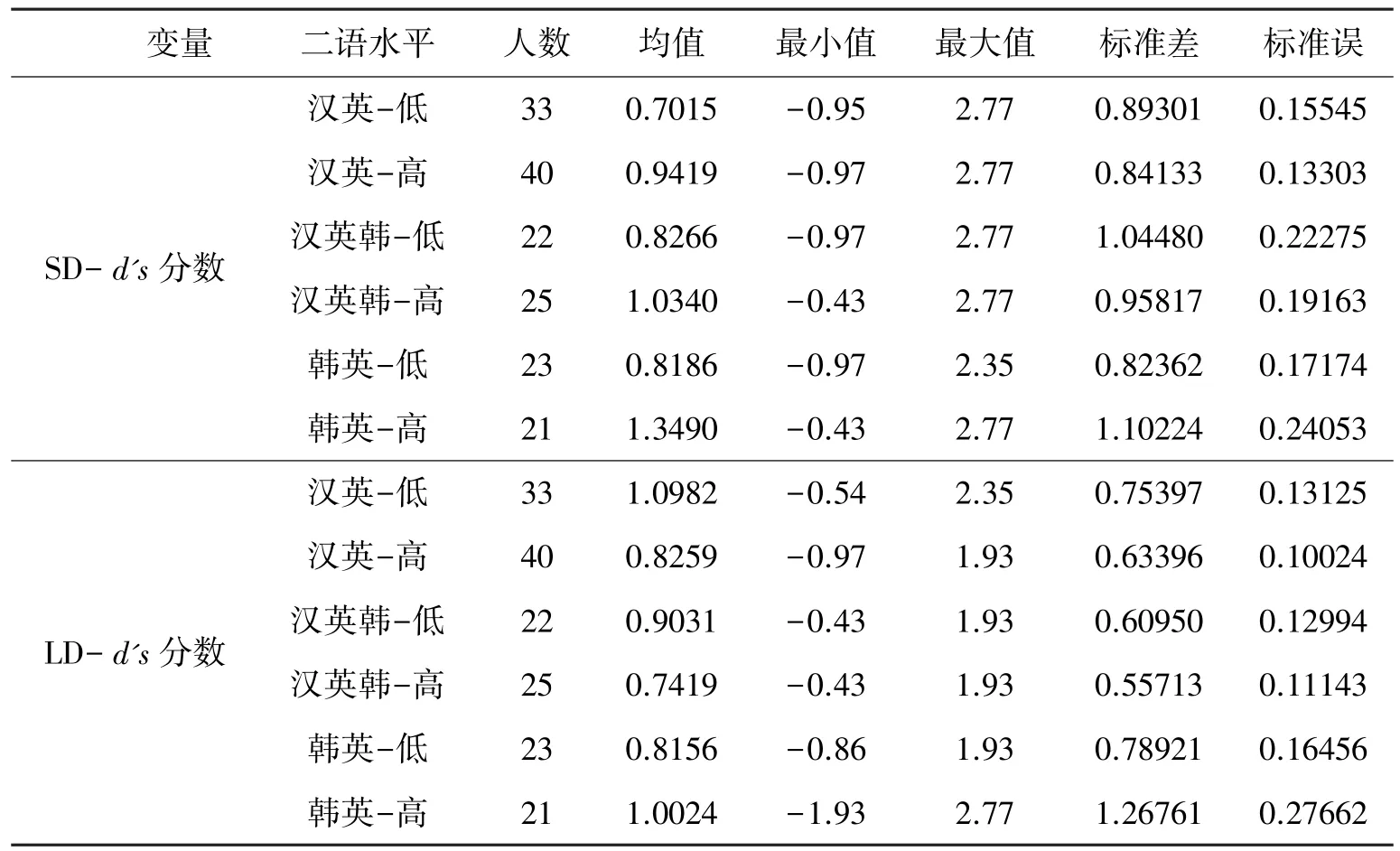
表4 短距离约束和长距离约束条件下d's 分数
长距离约束条件下的结果与上述短距离约束条件下的结果截然不同, 呈现出两种相互矛盾的趋势。 汉英-低(均值=1.9082,标准差=0.754)和汉英韩-低水平组(均值=0.9031,标准差=0.609)的d's均值高于其对应的汉英-高(均值=0.8259,标准差=0.634)和汉英韩-高水平组(均值=0.7419,标准差=0.557)的d's均值。 相反,韩英-低水平组(均值=0.8156,标准差=0.789)的d's得分则低于韩英-高水平组(均值=1.002,标准差=1.268)。
以二语水平为自变量,以短距离、长距离约束条件下的d's分数为因变量,分别对三种语言组合的高、低水平组别进行了三次独立样本t 检验,结果见表5。
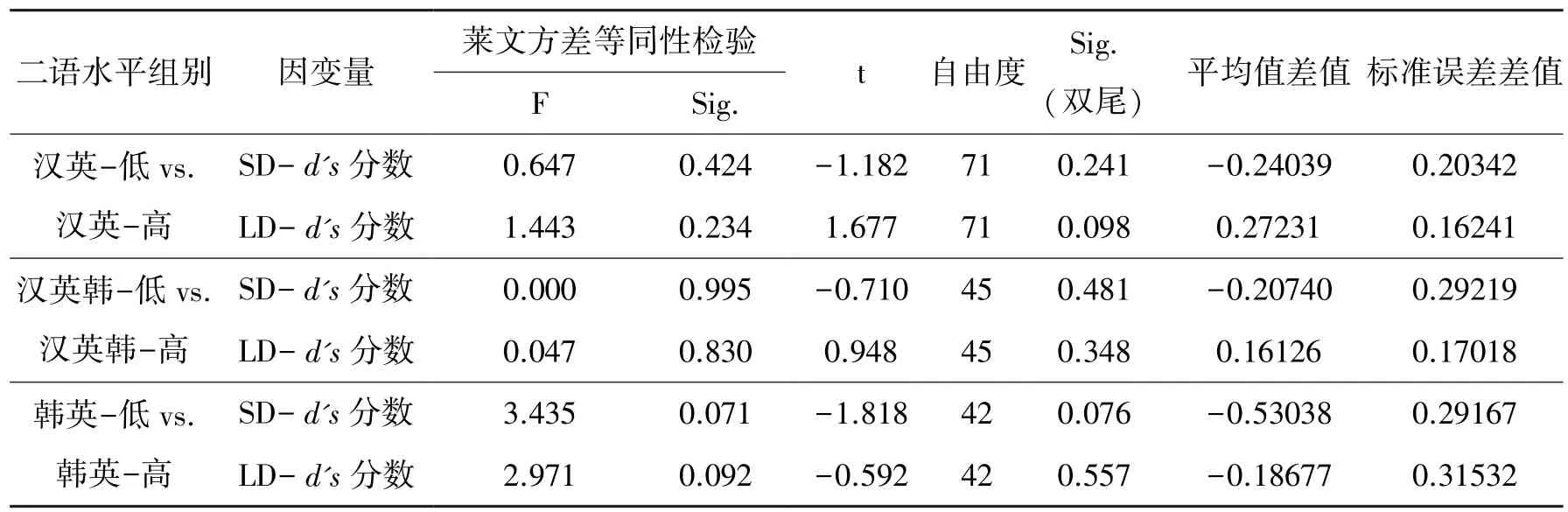
表5 短距离约束和长距离约束条件下d's 分数T 检验结果
如表5 所示,在韩英-低和韩英-高(t(42)=-1.818,p=0.076)水平组之间,短距离约束条件下d's分数的差异接近显著水平,而在汉英-低和汉英-高水平组之间(t(71)= -1.182,p>0.05),或汉英韩-低和汉英韩-高(t(42)=-0.710,p>0.05)水平之间则没有显著差异。 在长距离约束条件下,低、高水平组d's分数之间均未达到显著水平,汉英(t(71)= 1.677,p>0.05),汉英韩(t(42)= 0.948,p>0.05),韩英(t(42)= -0.592,p>0.05)。
以每个水平组别在短距离和长距离约束条件下的d's分数为配对样本,进行配对样本t 检验,探讨在两种约束条件下,汉英、汉英韩和韩英语言组别高、低水平组别内d's得分是否存在组内差异,结果见图2。
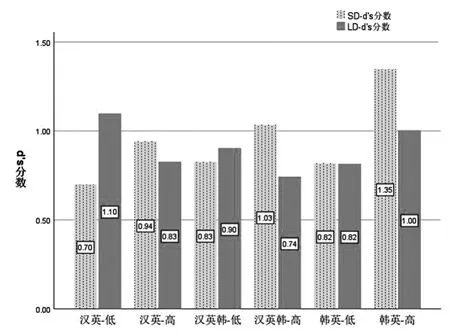
图2 各水平组内短距离和长距离约束条件下d's 分数均值
韩英-低水平组在两种约束条件下的d's分数完全相同,除此之外,其他五个语言水平组别在短距离和长距离约束条件下d's分数之间都有数值上的差异。 然而,这些差异均未达到显著水平。总体来说,韩英-低水平组在短距离和长距离约束条件下的d's得分完全相同,汉英韩-低水平组在长距离约束条件下的得分略高于短距离约束条件下的得分。 汉英-低水平组在长距离约束条件下的d's得分中明显高于短距离约束下的d's得分。 三种语言组合的高水平组表现出较为一致的趋势,即短距离约束条件下d's得分高于长距离约束条件下的得分。 此外,两种约束条件下的d's得分的平均差异,汉英-高组最小,韩英-高组最大,汉英韩-高组介于两者之间。
(四)讨论
本研究以各语言组别受试者剑桥快速分级测试分数的中位数为界限,将汉英、汉英韩和韩英组的受试者分为高、低两个语言水平。 三个语言组别二语测试分数的中位数各不相同,因此各语言组之间低水平组和高水平组的分界线并不相同。本研究旨在探讨二语水平对反身代词照应关系的解释是否存在调节作用,因此在真值判断任务中的d's分数、SD-d's分数和LD-d's分数的比较均在各语言组内的两个语言水平之间进行,没有跨语言组别进行比较。
尽管汉英、汉英韩和韩英组的高、低水平受试者的二语水平存在显著差异,但高、低水平组之间d's分数均值的差异并不显著。 这一结果与Berkes 和Flynn[5]的结果一致,在对二语和三语学习者定语从句习得的研究中,他们发现定语从句的语法构建遵循一个特定的发展过程,该过程对不同语言背景的学习者来说是相同的。 然而,构建目标语法的具体过程并不一定体现由传统方法衡量的语言熟练程度。 本文所采用剑桥快速定位测试衡量受试者的二语水平,而所测得的二语水平的显著差异,并没有对二语反身代词约束原则理解的正确率产生调节作用。 同样,分别比较短距离约束和长距离约束条件下照应关系的理解,高、低水平组的准确率仍然没有显著差异。
综上所述,本文研究结果表明,学习者构建反身代词约束原则的语法进程与Yoshimura 等[15]所阐释的进程不一致。 Yoshimura 等在研究中发现在二语日语反身代词zibun的习得过程中,学习者在短距离约束条件下的理解准确率在早期就已经达到较高水平,而长距离约束条件下的理解准确率则远远滞后。 他们认为,短距离约束解释的跨语言早期习得可以归结为局域性是人类认知的核心概念,而长距离约束解释习得的延迟则是由于zibun兼有句法和语用两方面的特征。 长距离约束原则中涉及的语用知识,增加了其解释的复杂性,因此二语学习者需要更多的时间去掌握。
而本研究结果则表明,上述反身代词约束原则的语法构建进程并不适用于母语允许长距离绑定的二语学习者。 在本文实验中,汉英组和韩英组的受试者并没有呈现在短距离和长距离约束条件下准确率的不对称性,即在短距离约束条件下准确率显著高于长距离约束条件下准确率。 相反,韩英组在两种约束条件下的准确率大致相等,汉英组在约束原则习得初期,则表现为在长距离约束条件下的准确率在数值上高于短距离约束条件下准确率。 在随后的学习过程中,受试者逐步构建了正常反身代词只允许短距离绑定的规则,从而提高了短距离约束条件下照应关系解释的准确率。 同时,汉英组对正常反身代词不允许非局域性解读这一语法规则的习得迁移到了特殊反身代词的约束原则的习得进程中,导致特殊反身代词长距离约束原则理解准确率在数值上有所下降。 韩英组在短距离和长距离约束条件下的理解正确率随语言水平的提高都表现出数值上的增长,但正常反身代词理解准确率的上升幅度数值上大于特殊反身代词理解准确率。
对汉英韩三语习得者来说,一语汉语和三语韩语都存在允许长距离约束的反身代词,这一组别的习得模式尤为复杂。 从描述性数据可知,三语组别的受试者在初始阶段对长距离绑定的特殊反身代词的理解较汉英和韩英两个二语组别而言略显优势,长距离和短距离约束条件下的准确率差值较小。 在约束原则习得初始阶段,汉英组别在长、短距离约束条件下的正确率有较大的数值差异,而韩英组别在两种约束条件的正确率持平。在构建英语反身代词约束照应关系的语法规则过程中,汉英韩组的受试者得益于学习第三语言韩语的经历,相对于一语和二语学习者而言,三语学习者在反身代词约束原则这一目标语法规则的储备上更为丰富。 在学习和应用二语反身代词约束原则的过程中,可运用已经掌握的三种或三种以上的语言知识来学习该语言规则。 这一结论与Berkes 和Flynn[5]所提出的累积-增强模型(cumulative-enhancement model)一致,即在学习更多语言的过程中获得的句法知识并不是简单的相加,而是对后续的语言学习产生了倍增效应。 但是,本文研究结果也无法完全纳入累积-增强模型,汉英韩组在长距离约束特殊反身代词的解释上并没有取得明显的进步。 相反,长距离约束原则理解的正确率随语言水平提高呈现出递减趋势,这在累积-增强模型的框架内是无法解释的。
从描述性数据看,三组受试对短距离约束的照应关系理解的准确率随二语语言水平的提高均有数值上的增长,但未达到显著水平;而长距离约束原则的习得则相对滞后。 对特殊反身代词的解释准确率相对较低,一方面可能是由于测试句子本身复杂程度较高,另一方面则可能是由于特殊反身代词的理解兼有句法和语用两个层面的规则[21-22]。 因此,后续研究有必要对真值判断任务中涉及特殊反身代词的测试句子进行深入分析,以探讨句子的复杂程度,语用特征,如先行词与反身代词之间性别、数量或生命性等特征的一致性,是否会影响反身代词约束原则的习得。
四、结语
本研究探讨了二语水平对汉英、韩英和汉英韩三个语言组别二语反身代词约束原则的解读是否存在调节作用,实验结果未提供证据表明二语水平在约束原则的习得过程中发挥积极作用。 这一结果进一步证实了Ahn 和Mao[7]所得出的结论,即韩英组别在真值判断任务中的准确率高于汉英韩组别,这一显著差异并非由于其二语分数的存在显著差异所导致的。 以传统方式衡量的语言水平并不能体现反身代词约束原则这一目标语法的发展路径。 对于一语、三语或一语和三语都允许非局域性约束的学习者来说,习得二语反身代词约束原则的起点并非一定是局域性这一人类认知的核心概念[23]。 特殊反身代词长距离约束原则的习得相对滞后,可能是由于特殊反身代词句法和语用规则的交织,这就需要后续研究进一步探讨句子的复杂程度及先行词与反身代词之间语用特征的一致性是否影响约束原则的习得。
本研究旨在探索二语水平的调节作用,但在研究方法上仍有较大的局限性。
首先,就二语水平而言,由于汉英、汉英韩和韩英组的初级和高级学习者的参与者人数较少且不平衡,因此实验结果没有包含不同语言组初级和高级水平的学习者的数据,仅把中级水平的受试者依据各组语言水平测试分数中位数分为低、高水平组。 在初级、中级、高级等不同能力水平上招募数量相当的参与者,并在组内和组间进行多维的比较,可以更为全面地探索二语水平是否对三语向二语反向迁移产生调节作用。
其次,本研究没有对三语组别的受试者进行三语水平测试,仅依据受试者在调查问卷中所述的开始学习三语的年龄及所在年级,将其标注为低级到中级学习者。 由于研究对象来自同一所大学的两个班级,接触和使用三语的频率基本一致,因而这部分研究对象在三语水平上的潜在差异可能会使得三语向二语的迁移模式模糊不清。 后续研究可加入三语水平测试,依据三语水平对参与者进行细分,以探索三语反向迁移现象中可能存在的差异。
猜你喜欢
体育科技文献通报(2022年5期)2022-06-05
建材发展导向(2021年13期)2021-07-28
英语世界(2021年13期)2021-01-12
海峡摄影时报(2018年2期)2018-03-21
东方教育(2016年8期)2017-01-17
长江学术(2016年3期)2016-08-23
户外探险(2016年4期)2016-04-07
体育科研(2016年2期)2016-02-28
现代企业(2015年6期)2015-02-28
文教资料(2009年21期)2009-09-03
