
基于自注意力机制的多模态语义轨迹预测*
2021-11-22 08:44朱少杰刘佰龙张雪飞
计算机工程与科学 2021年11期
刘 婕,张 磊,朱少杰,刘佰龙,张雪飞
(1.中国矿业大学矿山数字化教育部工程研究中心,江苏 徐州 221116; 2.中国矿业大学计算机学院,江苏 徐州 221116;3.内蒙古广纳信息科技有限公司,内蒙古 乌海 016000)
1 引言
随着移动互联网的发展和智能终端的普及,众多社交媒体网站(如Twitter、Sina和Instagram等)每天产生数以亿计的多模态语义轨迹数据。而多模态语义轨迹中存在时间依赖、空间依赖和活动依赖等多种依赖关系。空间依赖是指用户在访问下一位置时通常会考虑自身与目标场所的距离。时间依赖体现在用户对所处时段的敏感性,即用户在不同时段对访问兴趣点类型的偏好不同。活动依赖则是指用户即将进行的活动类型可由用户之前的活动序列推测得到,并且用户已完成的活动类型在同一轨迹序列中再次出现的概率较低。这些依赖关系相互联系紧密又具有复杂性,并且在轨迹预测中起到很重要的作用,准确分析和量化这些依赖关系能够有效提升预测的准确率。
传统的轨迹预测方法,如基于马尔可夫[1,2]、矩阵分解[3]等方法,并不能很好地解决轨迹中的长期依赖问题。深度学习方法是处理长期依赖的有效方法。ST-RNN(SpatioTemporal Recurrent Neural Network)[4]联合时空规律和循环神经网络建模来处理时序关系。采用长短时记忆LSTM(Long Short-Term Memory)网络[5,6],通过时间步参数共享和门机制解决轨迹中的长期依赖。卷积神经网络可以有效抽取轨迹的空间特征[7,8]。但是,这些方法没有考虑或单纯考虑时间和空间模态特征,忽略了轨迹的丰富语义特征。而针对多模态语义轨迹的研究较少,Karatzoglou等[9]在多维马尔可夫思想的基础上提出了PoVDSSA(Purpose-of-Visit-Driven Semantic Similarity Analysis)模型,实现了对语义轨迹的建模,并证明了加入了语义特征的预测模型可以缩短训练时间,提高准确性和鲁棒性[10]。Yao等[11]联合时间、空间、活动文本和用户偏好等多种模态特征,提出了SERM(Semantics-Enriched Recurrent Model)。上述方法虽然取得了不错的成果,但它们均未对轨迹中的复杂依赖关系进行量化,并且在模型训练过程中也并未处理特征分布偏移的问题。本文针对这2个方面进行设计改进,以提高预测有效性。
为了解决上述问题,本文提出了基于自注意力机制的多模态语义轨迹预测SAMSTP(Self- Attention mechanism based Multi-modal Semantic Trajectory Prediction)模型。该模型先对多种模态特征进行联合嵌入表示,以联合学习各模态特征及其相互之间的关系。随后结合Position Encoding[12]对轨迹点的相对位置关系进行记忆,以弥补自注意力层会带来的部分时序信息丢失的缺陷。然后设计自注意力机制准确量化和自动学习轨迹点间的复杂依赖关系,并且自注意力层在计算每个轨迹点的依赖权重时,轨迹点间计算步长始终为1,从而很好地解决了各依赖关系的长期性。而LSTM[12]则负责处理长轨迹序列时序上的长期依赖问题。最后本文设计模式规范化MN(Mode Normalization)对轨迹样本进行实时监测和规范,以达到预防依赖关系失真并加快模型收敛速度的目的。
2 多模态语义轨迹预测
2.1 问题定义
定义1(网格索引序列) 对兴趣点序列P={p1,…,pj,…,pDG}进行网格划分生成位置索引序列L={l1,l2,…,lDM}。pj∈P是一个二元组(lonpj,lapj),DG为数据集中兴趣点总数。DM=Grid×Grid,表示划分网格数。二元组元素lonpj和lapj分别定义为兴趣点pj的经度和纬度。
给定划分后网格索引序列L={l1,l2,…,lDM},现在给定用户序列U={u1,u2,…,uDu},Du为用户总数。下面为每个用户ui∈U定义多模态语义记录点序列:
定义2(多模态语义记录点序列) 用户ui的多模态语义记录点序列是一个时间序列Raw(ui)={r1(ui),…,rk′(ui),…,rDs(ui)}。Ds表示用户ui的记录点总数。每个记录点rk′(ui)∈Raw(ui)是一个四元组(lk′,tk′,ck′,fk′)。元组各元素定义如下:(1)tk′是时间戳;(2)lk′是用户ui在时间tk′的网格位置索引,且lk′∈L;(3)ck′是描述用户ui在时间tk′时活动的文本描述;(4)fk′是用户ui在时间tk′时的活动类型。
用户ui的记录点序列Raw(ui)中,2个相邻的位置记录点时间相关性可能很低。因此,本文引入时间间隔约束机制将原始多模态语义轨迹序列划分成多个多模态语义轨迹。
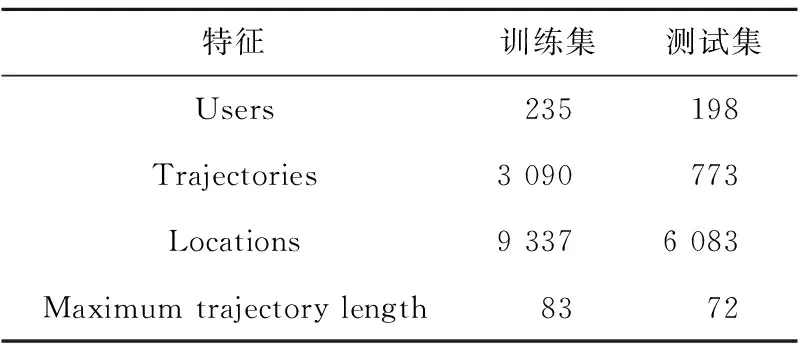
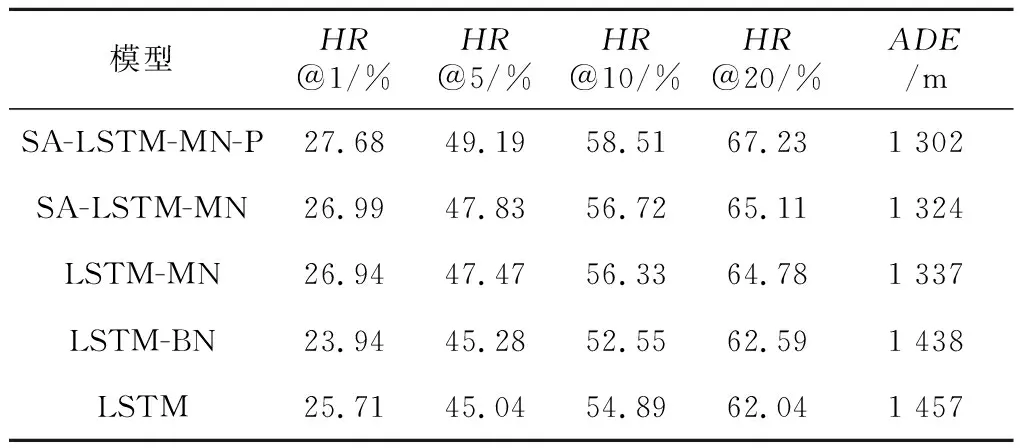
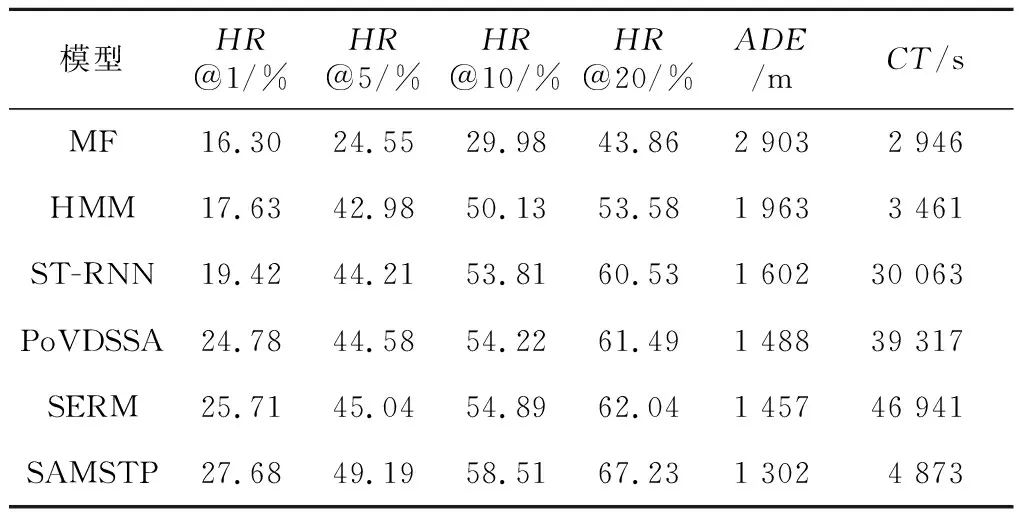
定义3(多模态语义轨迹序列) 定义用户ui的一个多模态语义轨迹序列为T(ui)={r1(ui),…,rk(ui),…,rK(ui)},1≤k≤K,0 定义4(多模态语义轨迹预测) 给定多模态语义轨迹序列Tn(ui)={r1(ui),r2(ui),…,rK(ui)},多模态语义轨迹预测任务是将Tn(ui)中前K-1个点{r1(ui),r2(ui),…,rK-1(ui)}输入到模型中,从网格位置索引序列L中预测地表真实位置lK。 Figure 1 Overall framework of SAMSTP 图1 SAMSTP总体框架图 (1)复杂依赖关系计算,如图1左上角的②。该模块采用自注意力机制结合Position Encoding量化多模态语义轨迹中的复杂依赖关系。具体内容将在第3节进行详细说明。 (2)LSTM网络捕获时序关系,如图1右上角的③。对于K个记录点的轨迹序列,LSTM层的时间步为K。将每个记录点rk(ui)的依赖关系向量sk作为第k时间步LSTM单元的输入,然后计算隐藏状态值hk,如式(1)所示: hk←f(W·hk-1+G·sk+b) (1) 其中,隐藏状态值hk∈RDh,Dh表示 LSTM单元中隐藏神经元的数量,代表第k时间步单元的隐藏状态值。前一时间步隐藏状态值hk-1、第k个记录点复杂依赖向量sk、常数偏置项b经由非线性变换函数f(·)计算得到hk。公式涉及的参数有:参数矩阵W∈RDh×Dh,G∈RDh×De,常数偏置项b∈RDh。 (3)依赖关系失真预防及轨迹预测,如图1右下角的④。该模块主要包括MN机制规范化预防依赖关系失真和轨迹预测2部分。MN机制实时规范化轨迹样本以预防依赖关系失真,并且加快模型收敛速度,该机制实现过程将在第4节进行具体介绍。 (2) 训练过程中使用交叉熵作为损失函数。对于一个包含Z个样本的训练集,定义损失函数如式(3)所示: (3) 其中,Θ={Et,El,Ec,Ef,Eu,W,G,H,b,a}为需估计的参数,δ为预定义常数以防止过拟合。其中,ynk表示第n条轨迹中第k个位置的预测概率。本文使用SGD(Stochastic Gradient Descent)和BPTT(Back Propagation Through Time)算法学习参数集Θ。 PE2i(k)=sin(k/100002i/De) (4) PE2i+1(k)=cos(k/100002i/De) (5) 本文采用自注意力机制对多种依赖关系进行联合学习,而不同于其他注意力预测方法对各特征分别设立独立的注意力模块,如DeepMove[14]。原因在于本文考虑到各依赖关系之间同样具有相关性,将各特征联合后采用自注意力机制更易于捕获数据或特征的内部相关性,实现更精准的预测。 (6) (7) 最后,将并行头部产生的所有向量连接起来,形成依赖关系向量S,如式(8)所示: S←Concat(M1,M2,…,Mi,…,MH)·WS (8) 其中,复杂依赖关系向量S={s1,s2,…,sk,…,sK}∈RK×De,WS∈RDe×De为映射参数矩阵。 训练过程中,轨迹样本的模态特征会发生偏移而导致依赖关系失真,并且每种模态特征的偏移方向并不一致,若使用单一分布的规范化如BN(Batch Normalization)[15],由于其并不适应多分布的轨迹样本,反而会导致模态特征泛化失真,降低预测效果。所以,为了更准确地学习依赖关系权重,避免模态特征的偏移导致计算得到的依赖关系失真,本文设计MN机制对轨迹样本进行多分布规范化,以适应每个模态特征不同的迁移方向,在训练过程中实时监控并规范化特征分布,从而达到预防依赖关系失真的效果。并且MN机制能保持较大的梯度更新参数,明显提升收敛速度,克服了大部分轨迹预测方法中建模复杂导致的参数量大,难以收敛的问题。 训练中MN为每种模式分布确定新的分量估计,估计分量如式(9)~式(11)所示: Nq←∑ngnq (9) (10) (11) (12) 本文实验基于美国纽约市的Foursquare数据集。数据集包含了从2011年1月到2012年1月的30万条Foursquare签到记录。首先提取不同用户的签到记录,删除记录数小于50的用户,并且根据时间约束tcon<10 h将序列划分为不同长度的时空语义轨迹记录。此外,删除长度小于3的时间相关性序列。本文将兴趣点GPS坐标通过网格划分转换为网格位置索引。经过以上处理,一共得到235个用户的3 863条时空语义轨迹序列。本文随机选取轨迹序列的80%作为训练集,剩下的20%作为测试集。训练集和测试集数据特征统计如表1所示。 Table 1 Statistics of data characteristics表1 数据特征统计 由表1可知,训练集包含235个用户的3 090条轨迹,所有轨迹点覆盖9 337个网格位置,其中最长一条轨迹所包含的轨迹点数为83个。测试集同理。 本文实验在Python 2.7下完成,采用版本号为2.2.4的Keras框架,TensorFlow版本号为1.5.0。所用设备主要硬件参数为:CPU 12核,内存32 GB,NVIDIA Tesla P100显卡,显卡内存为12 GB。 本文使用如下4种评价标准来衡量模型的性能: (1)交叉熵损失CCEL(Categorical Cross- Entropy Loss),即预测轨迹概率的损失值。计算公式如式(3)所示。CCEL用来评估模型对参数的敏感性。 (2)HR@k(Hitting Ratio @k),即轨迹真实下一位置索引出现在Top-k预测索引列表中的概率。 (3)平均距离误差ADE(Average Distance Error),即计算轨迹真实下一位置索引和Top-5预测索引列表的地表真实距离平均误差。 (4)模型收敛时间CT(Convergence Time),CT根据迭代次数和单步平均迭代时间OAET(One-step Average Epoch Time)计算得出。 本文对参数进行了优化实验,限于篇幅,此处不再具体展示实验细节。通过实验结果对比,本文最终设置各个嵌入维度Dt=Dl=De=Df= 50,LSTM隐藏单元数Dh=50,样本分布模式数Q= 2,多头自注意力机制头数Heads=8,学习率(Learning Rate)LR=0.0005,批次大小BatchSize=100。 本文通过对不同模块进行组合,来验证模型中各模块的有效性。实验设置遵循控制变量原则。5种模块组合方式设置如下:(1)LSTM,表示长短时记忆网络;(2)LSTM-MN,表示在LSTM的基础上增加MN模块;(3)LSTM-BN,表示在LSTM的基础上增加BN模块;(4)SA-LSTM-MN,表示在LSTM-MN的基础上增加自注意力模块;(5)SA-LSTM-MN-P,表示在 SA-LSTM-MN 基础上增加Position Encoding模块(SA-LSTM-MN-P即代表SAMSTP模型)。 根据以上模块组合方式,本文设计2个对照实验:(1)比较SA-LSTM-MN、LSTM-MN和SA-LSTM-MN-P,验证自注意力机制以及位置嵌入对复杂依赖关系计算的有效性;(2)比较LSTM-MN、LSTM-BN和LSTM,验证MN机制的有效性。 本文选取以下模型与SAMSTP模型进行比较:(1) MF[3]:为用户和位置学习低维向量,并为用户的下一次访问推荐最相似的位置;(2) HMM(Hidden Markov Model)[1]:学习隐马尔可夫模型来选择下一个位置预测概率最大的位置;(3) PoVDSSA[9]:建立了一个类似多维上下文感知的马尔可夫链结构来建模丰富的语义轨迹;(4) ST-RNN[4]:基于递归神经网络,着重对时空转换矩阵的建模;(5) SERM[11]:将一个递归神经网络的多因素(用户、位置、时间、关键字)和过渡参数嵌入在同一的框架中进行联合学习。以上方法参数均调至最优。 (1)先比较LSTM-MN、SA-LSTM-MN和SA-LSTM-MN-P。由表2知,相比LSTM-MN,SA-LSTM-MN各项评价标准均有所提高,表明使用自注意力机制计算复杂依赖关系的确能够提高预测的准确率,然而增幅不大。这是因为单独使用自注意力机制计算轨迹点依赖关系时,会丢失轨迹点之间的部分时序关系,所以预测效果提升不明显。但是,SA-LSTM-MN-P的各评价标准均比LSTM-MN的高出许多,这是由于Position Encoding保留了轨迹点之间的相对位置关系,有效弥补了自注意力机制的不足,二者结合实现了复杂依赖关系的准确量化。由表2可知,SA-LSTM-MN-P的各HR@k分别比LSTM-MN高0.74%,1.72%,2.18%和2.45%,ADE下降了35 m。 Table 2 Performance of different combination of modules表2 模块有效性表现 (2)表3中对比了LSTM、LSTM-BN和LSTM-MN在各个评价标准下达到最优表现所需的收敛时间CT以及单步平均时间OAET。可以看出,LSTM-BN和LSTM-MN收敛时间相比LSTM大大缩短,其中LSTM-MN的收敛速度在各标准下比LSTM分别提升了8.274,4.061,3.624,7.939和15.967倍,说明MN能大幅加快模型的收敛。但是因为LSTM-BN和LSTM-MN增加了计算量,所以OAET分别增加了7 s和12 s。在表2中,LSTM-BN在HR@1和HR@10时的准确率低于LSTM的,结合表3发现LSTM-BN虽然能加快模型的收敛,但是部分评价标准的表现会有所降低。这是由于在训练过程中轨迹样本的特征偏移方向并不一致,使用BN这样的单一分布模式规范化并不能很好地预防依赖失真的问题。而LSTM-MN的各个评价标准的表现都优于LSTM和LSTM-BN的,表明引入MN采用多分布对轨迹样本进行规范化是必要的,它能够解决依赖关系失真问题,明显提升预测的有效性。 Table 3 CT of optimal performance and the OAET for LSTM,LSTM-BN and LSTM-MN under LR=0.0005表3 LSTM、LSTM-BN和LSTM-MN在LR=0.0005时的CT最优表现及OAET 如表4所示,在相同数据集上,SAMSTP在各项评价标准下的表现均是最好的。SAMSTP与这些模型的预测有效性比较如下:(1)MF的预测效果是这些模型中最差的,因为它没有捕捉到连续的转移规律。(2)HMM性能较差的主要原因在于它依赖于用户行为的分布假设,只对轨迹建模一阶依赖关系,难以捕捉轨迹中的长期依赖。(3)ST-RNN将空间和时间划分为若干个,并学习每个时空单元的转换矩阵,导致参数量较大,影响预测的可靠性。(4)PoVDSSA模型利用类似多维上下文感知的马尔可夫链结构对丰富的语义轨迹进行建模,但是仍旧不能很好地解决长期依赖问题。(5)SERM模型的效果仅次于SAMSTP的。因为SERM模型忽视了轨迹点之间的复杂依赖关系,并且没有考虑多模态特征模式分布规范化的问题。由表4可知,SAMSTP的各HR@k分别比SERM的高1.97%,4.15%,3.62%和5.19%,ADE下降了155 m。 Table 4 Comparison of optimal performance for different models表4 不同模型最优表现对比 另外,为了验证SAMSTP在提高模型收敛速度上的有效性,本文计算了各模型的CT最优表现。如表4所示,MF和HMM的模型结构简单,参数量较小,所以收敛速度很快,但其预测效果较差。ST-RNN的模型结构复杂,参数量巨大,导致收敛时间明显较长。PoVDSSA、SERM和SAMSTP都引入了丰富的语义信息,增大了训练计算量,所需收敛时间比未考虑语义特征的模型更长。但是,SAMSTP收敛所需时间远低于前二者,原因在于SAMSTP对训练样本进行规范化,使得模型始终保持较大的梯度更新参数,抑制梯度达到饱和,因此显著提高了收敛速度。 现有的多模态语义轨迹预测方法中存在难以充分学习复杂依赖关系的缺点。针对这一问题,本文提出了基于自注意力机制的多模态语义轨迹预测模型。该模型通过对多模态特征的联合嵌入,降低了数据的稀疏性;并采用Position Encoding对轨迹点进行编码处理,弥补依赖关系计算中造成的时序信息丢失缺陷,增强轨迹点间时序关系。然后结合自注意力机制精准量化轨迹点之间的复杂依赖权重,从而显著提高轨迹预测的有效性。本文还设计了MN机制实时监测数据模式,将轨迹样本分配给不同的分布并对其进行规范化,有效解决了单一分布规范化会丢失模式信息的问题,从而减少特征偏移量,以达到预防依赖关系失真的目的。并且MN机制能够加速模型的收敛。由此,预测的有效性和鲁棒性得到了极大提升。本文在纽约真实轨迹数据集上进行了实验,结果表明,与SERM相比,SAMSTP提高了预测准确率,预测总体速度提升了9.633倍,并且在各评价标准下表现最优。 未来工作的目标是引入更丰富的非结构化信息,如用户之间的关系,以进一步提高本文模型的性能。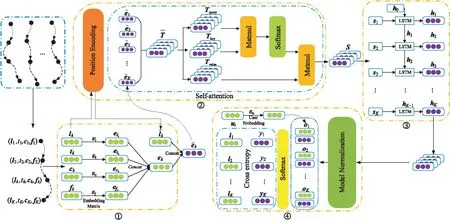
2.2 总体框架
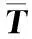

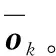
3 Self-attention计算复杂依赖关系
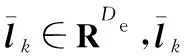

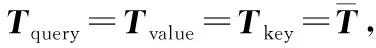

4 MN机制预防依赖关系失真
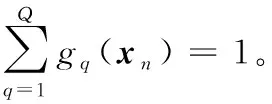


5 实验与结果分析
5.1 实验数据及设置
5.2 评价标准及参数设置
5.3 实验内容
5.4 实验结果分析

6 结束语
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
开放教育研究(2020年2期)2020-03-31
现代装饰(2018年5期)2018-05-26
传媒评论(2017年3期)2017-06-13
中国三峡(2017年2期)2017-06-09
第二课堂(课外活动版)(2016年2期)2016-10-21
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
