
基于概率校准的弥漫性大B细胞淋巴瘤患者死亡风险预测*
2021-11-22 07:38范双龙赵志强余红梅郑楚楚黄雪倩阳桢寰罗艳虹
中国卫生统计 2021年5期
范双龙 赵志强 余红梅 王 蕾 郑楚楚 黄雪倩 阳桢寰 邢 蒙 吕 庆 罗艳虹△
【提 要】 目的 基于概率校准,预测弥漫性大B细胞淋巴瘤(diffuse large B-cell lymphoma,DLBCL)患者两年内的死亡风险,为医生决策和临床治疗提供参考。方法 使用Cox回归筛选DLBCL患者两年内死亡的影响因素。选择logistic回归(logistic regression,logit)、随机森林(random forest,RF)、支持向量机(support vector machines,SVM)、前馈神经网络(feedforward neural network,FNN)构建风险预测模型。同时,使用三种概率校准方法对上述模型进行校准:platt scaling(Platt)、isotonic regression(IsoReg)、shape-restricted polynomial regression(RPR)。使用ROC曲线下的面积(AUC)评价模型的区分性能,使用Hosmer-Lemeshow(H-L)goodness-of-fit test、expected calibration error(ECE)、maximum calibration error(MCE)评价模型的校准性能。结果 logit和FNN能够提供准确的概率估计,校准后其预测性能无提升;RF和SVM的预测概率与真实概率的差异具有统计学意义。除SVM-IsoReg外,三种概率校准方法都能对有偏预测进行良好的校准,且RPR校准效果最好。结论 logit和FNN具有良好的校准性能,而RF和SVM校准性能较差,概率校准能够有效降低它们的预测误差。基于概率校准所构建的风险预测模型达到预期效果。
弥漫性大B细胞淋巴瘤是一种常见的恶性淋巴瘤,由于其在临床表现和预后方面具有很强的异质性,目前仍是一个巨大的临床挑战[1-2]。尽管有超过50%的病例经过标准治疗可以达到持续缓解,但是仍有近三分之一的患者出现耐药或复发,使得生存率大大降低[3-4]。准确的风险估计是实现精准医疗的关键,这能够帮助临床医生做出最佳决策,使患者尽早地开始合适的治疗,减少无效药物的使用,并最终改善个体患者的临床结局[5-7]。因此,有必要为DLBCL患者提供准确的死亡风险预测。
区分度和校准度是评价一个临床预测模型不可或缺的两个尺度[8]。区分度是指将会发生某一结局的患者与不会发生该结局的患者区分开的能力。校准度衡量的是在不同风险分层的患者中,模型的预测概率与真实概率的吻合程度。虽然本文的目的是为DLBCL患者提供准确的风险估计,但是当一个模型区分度较差时,无需进一步评价其预测概率的准确性[8]。因此,本文选择logit、RF、SVM、FNN,四个常用且在以往报道中具有良好分类性能的分类器构建预测模型。既往研究表明:一个具有良好区分度的模型,仍然可能提供有偏的概率估计,例如RF和SVM[9-12]。幸运地是,这些有偏的预测值可以通过概率校准方法进行校准。概率校准是指寻找一个校准函数,将初始预测映射为更加精确的后验概率[9]。
Platt是一种参数化校准方法,其通过使用sigmoid函数修正有偏的预测值。但是当模型的输出不是“S”型的情况下,此方法校准效果较差[10,12]。IsoReg试图找到一个保序(非递减)函数对有偏的预测值进行校准,由于其约束简单,适用性较强。然而,有研究表明在训练样本较少的情况下,此方法校准效果较差[12]。相比于Platt和IsoReg,RPR是一种更为灵活和具有普遍适应性的方法,其不受特定分类器及样本量的约束[13]。本文同时引入以上三种校准方法,探讨在不同分类器下的校准性能。本研究旨在为DLBCL患者提供准确的死亡风险估计,为医生决策和临床治疗提供参考。
资料与方法
1.数据来源
本研究所使用的数据来源于某医院2010-2017年确诊的406例DLBCL患者,其中两年内死亡人数为116人。通过电子病历记录,共搜集了17个特征,具体特征及分组见表1。

表1 406例DLBCL患者特征及分组
2.方法
(1)概率校准
概率校准是指将分类器的初始概率估计或得分映射为更加精确的预测,即寻找校准函数f,使其满足下述目标:
f(s)=P{y=1|s(x)=s}
其中,s是样本x的初始概率估计或得分,P为该样本属于类别1的真实概率。
①Platt
Platt是一种参数化方法,其通过sigmoid函数,将分类器的原始输出映射为更加精确的后验概率[10]:
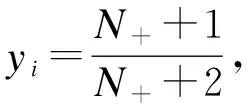
②IsoReg
IsoReg是一种非参数方法,其试图找到某个保序(非递减)函数满足下述的目标[14]:
其中,yi=[y1,y2,y3,…,yN]是样本按照初始得分排序后所对应的标签序列,如果样本属于正类,则对应标签为1,否则为0。
pair adjacent violators(PAV)算法可以用来估计保序函数[15]。在使用该算法时,首先从标签序列的首个元素开始观察,一旦出现乱序元素,则停止观察,从该乱序元素开始逐个吸收下一个元素组成一个序列,直到此序列所有元素的平均值小于或等于下一个待吸收的元素,并以平均值取代此序列中的所有元素。上述过程递归执行,直到f1≤f2≤…≤fN。最终,可以在初始得分区间上获得一个分段常数解。当预测一个新样本x时,只需找到其得分s(x)所在区间,该区间对应的分段常数即为该样本校准后的概率。
③RPR
RPR通过多项式回归校准初始概率,其校准函数具有以下形式[13]:
通过以下优化问题进行求解:
(1)
(2)
(3)
通过约束(1),所有校准后的概率都保证落在[0,1]区间。约束(2)来源于多项式的导数,能够保证校准函数在整个得分区间的单调性。在约束(3)中,通过a的l1-范数,防止多项式过拟合。
(2)评估及度量
随机抽取五分之四的样本作为训练集,剩余样本作为测试集。为了尽可能保证数据分布的一致性,每次划分均采用分层抽样。为防止校准函数过拟合,将分类器在交叉验证中的验证集上得分的合集来训练校准函数。首先训练上述分类器及三种校准函数,然后在测试集上进行评价。为减少因数据划分而带来的变异,上述划分与评估重复300次。最终评价依据300次结果的中位数。
模型评价基于区分度和校准度。虽然我们的目的是提供准确的风险估计,但是当一个模型区分度较差时,无需进一步评价其校准性能。因此,我们使用AUC评价模型的区分性能,使用H-L检验、ECE、MCE评价模型的校准性能。
H-L检验用来评估预测概率与真实概率的差异是否由抽样误差造成[16]。ECE和MCE是与可靠性图(reliability diagram)相关的两个度量[17]。在计算这些指标时,预测值被由小到大排序,然后分成大小相似的k个区间。对于每个区间,预测概率为该区间中所有预测值的均数,真实(观测)概率为该区间中阳性样本所占比例。ECE和MCE分别测量这些区间上平均预测误差和最大预测误差:
MCE=max(|pi-oi|),i=1,2,…,k
其中,pi和oi分别为第i个区间的预测概率与观测概率。ECE和MCE越小,则预测值的校准误差越小。
(3)参数及实现
logit、RF、SVM在R 3.6中分别使用 “glm”、“randomForest”、“e1071”包实现。FNN和RPR在Python 3.6中分别使用Keras和CVXPY实现[23-24]。
结 果
1.Cox回归结果
本研究中,与结局呈单变量关系(P<0.1)的特征被纳入到多变量Cox回归中,结果如表2所示。性别、疾病分期、IPI、KPS及是否使用利妥昔单抗是DLBCL患者两年内死亡的独立影响因素(P<0.05),将被用作风险模型的预测因子。
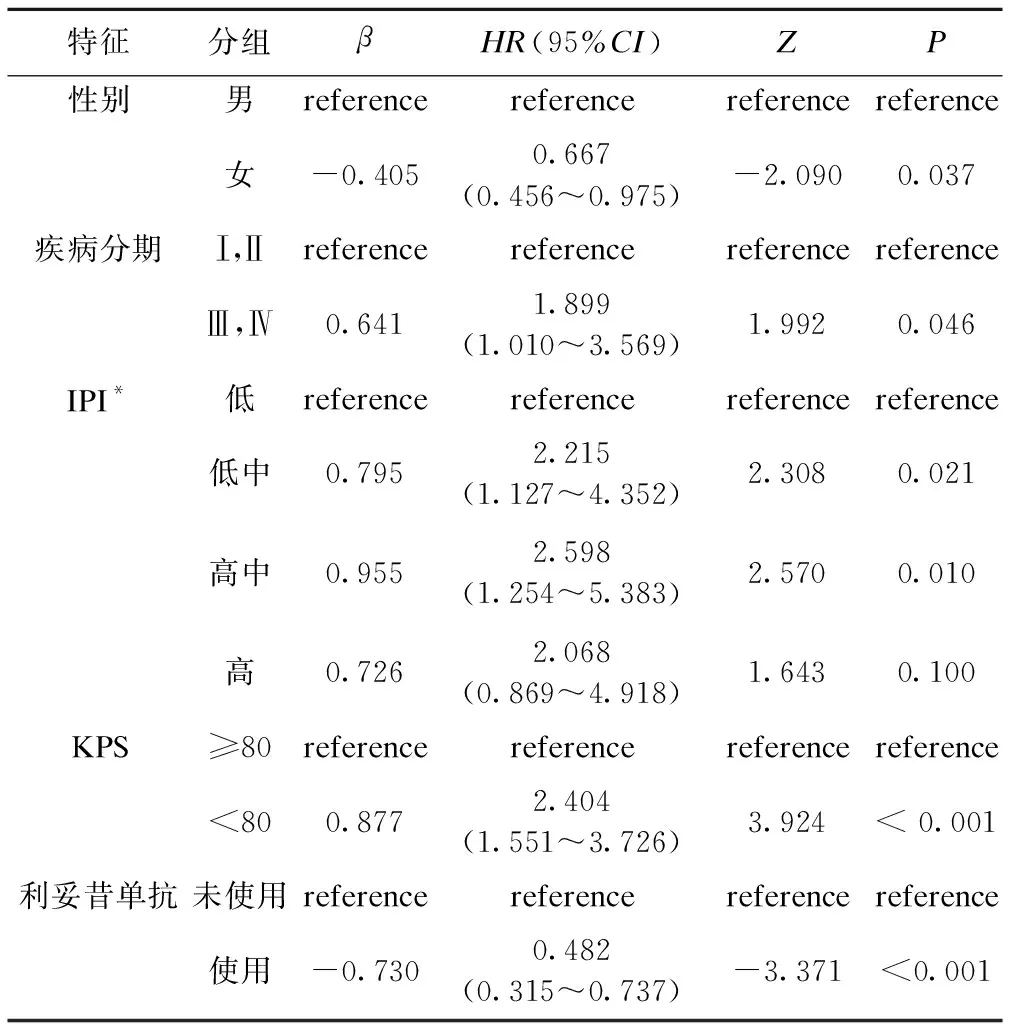
表2 多变量Cox回归结果
2.各模型校准前后性能比较
表3给出了各模型校准前后的性能。“-Platt”、“-IsoReg”、“-RPR”分别代表对应模型使用三种概率校准方法校准的结果。主要特点总结如下:
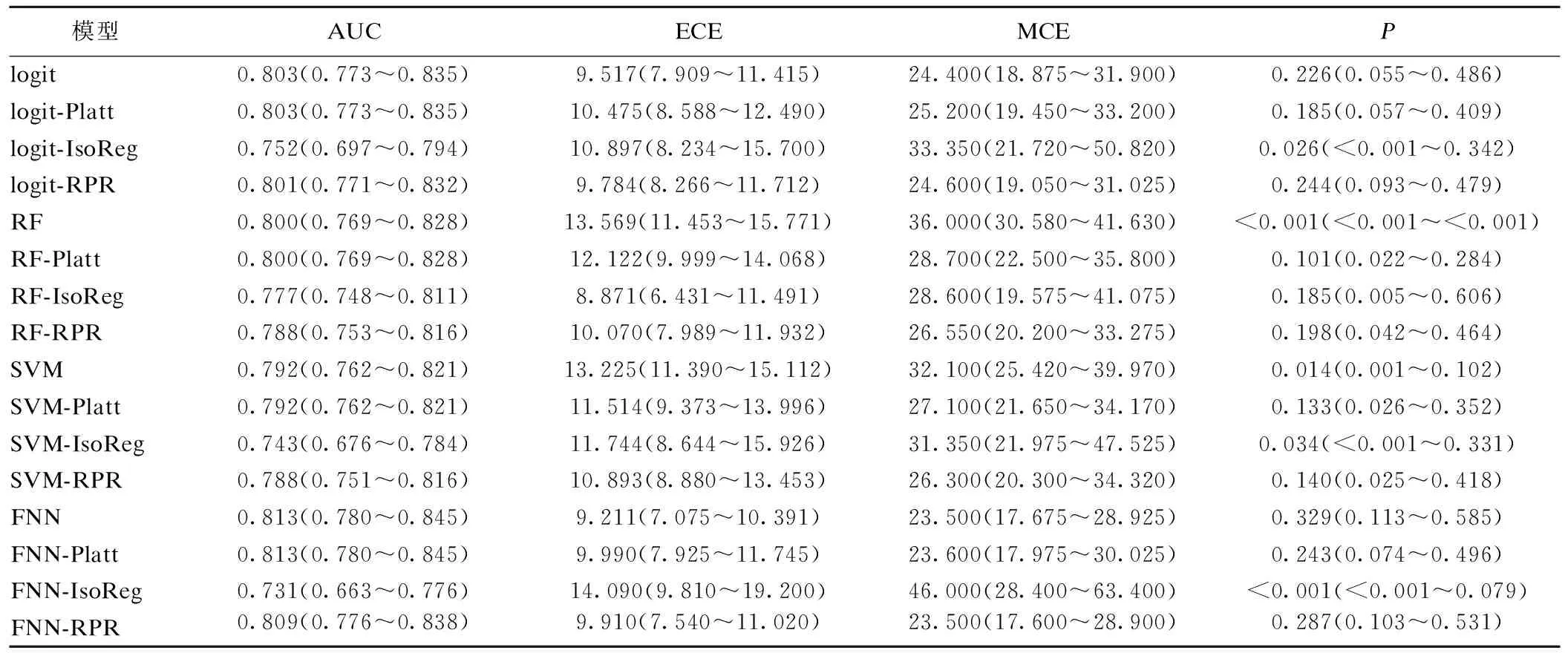
表3 各模型校准前后的性能
四个分类器的AUC均大于0.75,可以认为具有较好的区分性能。其中,FNN的AUC最大,为0.813,SVM最小,为0.792。
logit和FNN具有良好的校准性能,预测概率与真实概率的差异不具有统计学意义(P>0.05)。对于它们而言,无论使用何种校准方法,校准误差都无显著改善,特别是在logit-IsoReg和FNN-IsoReg中。
RF和SVM校准性能较差,预测概率与真实概率的差异具有统计显著性(P<0.05)。对于RF,三种校准方法都能改善模型的校准性能。其中,RF-IsoReg的ECE最小,RF-RPR的MCE最小,分别为8.871和26.550。对于SVM,Platt和RPR能实现良好的校准,而IsoReg不能。其中,SVM-RPR具有最小的校准误差,ECE和MCE分别为10.893和26.300。
在所有模型中,RF-IsoReg具有最小的ECE,为8.871;FNN和FNN-RPR具有最小的MCE,为23.500。
讨 论
本文使用logit、RF、SVM、FNN四种分类器构建DLBCL患者死亡风险预测模型,同时使用三种概率校准方法进行校准。
虽然四个分类器在区分性能上是十分相似的,但是校准性能差异较大。根据H-L检验可知,logit和FNN可以产生准确的概率估计,而RF和SVM的预测概率与真实概率具有显著差异。该结果与某些研究一致。对于RF,由于很难在所有树上获得相同的预测结果,概率估计往往会被推离0和1[9,11-12]。对于SVM,预测值将被推离0和1,同时发生“S”型扭曲[10,12]。尽管决策值的大小可以作为预测信心的一种度量,但是这些值往往没有经过良好的校准。
当预测值发生“S”型扭曲时,Platt是一种有效的校准方法。在我们的研究中,Platt对RF和SVM都实现了良好的校准。因为仅要求校准函数是非递减的,因此IsoReg是一种通用的校准方法。然而,在我们的研究中,SVM经过IsoReg校准后,校准性能并没有显著改善。这可能是因为样本量较少而发生了过拟合。Niculescu-Mizil的研究表明,IsoReg不适用于较小的数据集,特别是在样本量小于1000时[12]。相比于Platt和IsoReg,RPR是一种更为灵活和强大的校准方法。不同于Platt,由于对初始预测值的分布没有要求,RPR适用于各种分类器。与IsoReg相比,RPR在整个得分区间上是连续的。另外,RPR严格满足校准函数的单调性要求,并且可以通过某些优化工具方便地求解,例如CVXPY。理论上,随着多项式次数的增加,RPR可以拟合具有任意复杂度的校准函数。在我们的研究中,RPR对SVM的校准效果最好。无论是ECE还是MCE,SVM-RPR均小于SVM-Platt和SVM-IsoReg。对于RF,虽然RF-IsoReg的ECE小于RF-RPR,但是如果同时考虑校准性能分布,可以认为RPR校准效果最好。
严格单调的校准函数不会改变ROC。因为经过概率校准,根据预测值排序后的样本的顺序不会发生改变。本文中,对于以sigmoid函数进行校准的Platt,各模型校准后的AUC与校准前均一致。对于IsoReg和RPR,由于它们在整个得分区间上仅是非递减的,所以某些初始预测值相近的样本在校准后可能会获得相同的概率预测值,而样本的“排序”也可能会受这部分样本的影响而发生改变。因此,各模型经上述两种方法校准后的AUC与校准前相比均有降低。与RPR相比,IsoReg降低程度较大,这或许是因为其校准函数为不连续的分段常数所致。RF和SVM经RPR校准后AUC略有降低,与其所带来的校准性能的提升相比,这或许是可以接受的。
本文选取logit、RF、SVM、FNN构建DLBCL患者死亡风险预测模型,同时使用三种概率校准方法对概率估计进行校准。logit和FNN以及经过校准的RF和SVM能够提供准确的风险预测,达到了预期效果。其中,RF-IsoReg具有最小的ECE,FNN和FNN-RPR具有最小的MCE。罗艳虹等使用WSVM和WRF构建先天性心脏病概率预测模型并分别使用Platt和IsoReg进行校准。结果显示,校准后的模型预测性能更优[25]。吕奕等对AdaBoost和SVM进行概率校准后,构建肠癌转移预测的集成模型。与直接将分类器进行集成相比,引入概率校准后的模型性能进一步提高[26]。
本研究存在不足:首先,AUC及MCE仍有较大提升空间,下一步可以收集更多相关特征,探讨这些新特征加入模型后是否会带来性能的提升。其次,本文所构建的模型基于某家医院提供的数据,对于模型的泛化性能如何,需要进行外部验证。
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05
今日农业(2021年19期)2022-01-12
中学生数理化·中考版(2021年6期)2021-11-22
环境保护与循环经济(2021年7期)2021-11-02
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
国外核新闻(2020年8期)2020-03-14
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
电测与仪表(2014年15期)2014-04-04
