
基于句法规则层次化分析的神经机器翻译
2021-11-22 08:03张海玲邵玉斌杜庆治
小型微型计算机系统 2021年11期
张海玲,邵玉斌,杨 丹,龙 华,杜庆治
(昆明理工大学 信息工程与自动化学院,昆明 650500)
1 引 言
随着信息时代的快速发展,自然语言处理(Natural Language Processing,NLP)的研究更加如火如荼.机器翻译是借机器的力量将一种自然语言翻译成另一种自然语言,是人工智能和自然语言处理领域的重要研究方向[1].机器翻译研究一直在不断的革新,从最初传统的基于规则的机器翻译,到基于统计的机器翻译,再到目前主流的神经网络机器翻译(Neural Machine Translation,NMT).神经网络机器翻译是基于词、短语和句子,使用一个非线性网络找到语言之间的关系,实现自然语言之间的转换[2],NMT因其翻译性能突出,已成为当下工业界和学术界的研究热点.目前在中文到英文的基于注意力机制的神经机器翻译模型取得了令人瞩目的成绩,但仍然存在一些不足,其中一个很重要的原因是中文句式结构的复杂性和语义的多变性造成了翻译效果不佳,如何利用语言学的知识增强翻译模型的性能是一个值得深入的研究方向.
句子的构成总是依赖于句法结构,比如句子可分为主谓宾定状补等成分,每种成分都会有对应的单词,在句法的约束下这些成分才能构成完整、通顺、流畅的句子.句法分析对语言是极其重要的.NMT在处理输入源语言和输出目标语言时,都采用序列化形式,往往忽略了语言中蕴含的句法结构知识[3].与其让模型单独依靠在训练过程中学会隐型句式结构,不如通过更为显性的方式将句法结构信息整合到模型中,强化翻译模型.
本文针对NMT翻译句式复杂的长句效果欠佳的问题,提出了一种基于句法规则层次化分析的神经机器翻译方法,利用该句法层次化分析方式,对长度超过一定阈值的句子提取最长短语(Maximal-length Phrase,MP),再分别翻译MP和句子框架,翻译内容重新组合之后得到更高质量的译文.该方法通过在句法分析上缩短句子长度、简化句子结构的方式与神经机器翻译学习能力强等优势相结合,在一定程度上达到了增强NMT翻译性能的目的.
2 相关研究
2.1 句法分析的应用
句法分析在自然语言处理中起着承上启下的作用,其基本任务是在句子分词之后,对输入的文本进行分析得到句子的句法结构,识别出高层次的结构单元来简化句子的描述,确定句子所包含的句法单位之间的依存关系,将成分使用树状或依存关系的形式表示出来.句法分析方法主要有成分句法分析、依存句法分析、深层文法句法分析等.句法分析应用较广泛,如机器翻译、文本校对、情感分析、信息抽取等.
在机器翻译任务中,由于语种的特点,特别是汉语不具有诸如英语、法语等其他语言那样严格意义的形态变化[4,5],汉语句式和语义复杂性造成翻译效果不佳,这时句法分析模型就显得尤为重要.机器翻译大都是词语级的模型,所包含的句法信息较少.句法是重要的关于句子结构的理论,将词语级的翻译模型扩展至基于句法的翻译模型,是神经机器翻译模型架构创新的重要体现.
将语言学知识融入机器翻译,是众多研究学者们一直在深入的任务.宋鼎新等人提出了一种融合句法短语的汉英统计机器翻译方法[6],将得到的句法短语对与基于短语的统计机器翻译系统相融合,使用加入短语表和使用新特征的方式证明句法短语对短语翻译模型的改进作用,结果表明,在不同规模的训练语料环境下,BLEU值分别提高0.56和0.62.尽管融合了句法短语知识,但统计机器翻译的效果不如神经机器翻译好.汪琪等人提出一种融入依存关联指导的神经机器翻译方法[7],通过在源端进行关联性建模,融入依存关联指导,以此加强源端单词之间的关联性,提高机器翻译的性能,该方法仅考虑源端语句之间直接存在的依存信息,不考虑存在间接依存关联的其他节点,并且不区分当前词是与其有依存关系的子节点还是父节点.张学强等人提出一种基于最长名词短语分治策略的神经机器翻译方法[8],该方法识别并抽取句子中的最长名词短语,利用分治法的思想进行翻译,与基线系统相比BLEU值有一定的提升,缓解了神经机器翻译对句子长度敏感的问题.但是该方法仅针对名词短语结构,没有考虑到其他类型的短语,结构比较单一,还需在句法上进一步扩充.
2.2 神经机器翻译
机器翻译的思想,最早提出的是基于规则的机器翻译(Rule-based Machine Translation,RBMT).随着统计学的发展,研究者通过对双语文本语料库的分析来生成翻译结果,称为统计机器翻译(Statistical machine translation,SMT).2003年,Bengio等人提出了基于神经网络的语言模型,改善了传统 SMT 模型的数据稀疏性问题[9],为未来神经网络在机器翻译上的应用奠定了基础.2013 年,Nal Kalchbrenner 和 Phil Blunsom 提出了端到端的“编码器-解码器”机器翻译模型[10],该模型使用卷积神经网络将源文本编码成一个连续向量,然后再使用循环神经网络作为解码器将该状态向量转换成目标语言.使用深度学习方法获取语言之间的映射关系,NMT 的非线性映射不同于线性的 SMT 模型,NMT使用了连接编码器和解码器的状态向量来描述语义的等价关系.此外,循环神经网络理论上能得到无限长句子的信息,从而解决长距离重新排序(Long Distance Reordering)问题[11].但是实际上梯度爆炸或消失问题[12]让循环神经网络难以处理长距依存(long distance dependency).2014 年,Sutskever I和Cho K等人提出了序列到序列的模型,可以将循环神经网络用于编码器和解码器[13],并且还为NMT引入了长短时记忆(Long Short-Term Memory,LSTM),梯度爆炸或消失问题得到了控制,从而让模型可以更好地捕获句子中的长距依存.2017年Vaswani A等人提出了完全基于注意力的Transformer神经机器翻译模型[14],更好地解决长距离依赖,翻译性能获得大幅度提升.
Transformer模型完全使用注意力机制对源端的目标端序列建模[15],它的主要特点在于仅通过自注意力机制计算输入x=[x1,x2,x3,…,xm]和输出y=[y1,y2,y3,…,ym]的表示,实现端到端的神经机器翻译.该模型将句子中的每个词和所有词进行注意力计算,学习句子内部的依赖关系,捕获句子的内部结构.其较少的训练时间以及更好的翻译效果使Transformer成为目前常用的模型.模型的整体结构如图1所示.
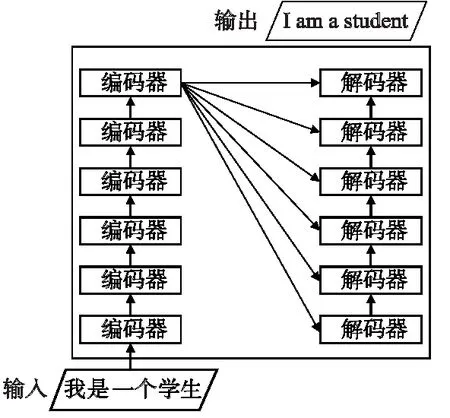
图1 Transformer整体结构图
Transformer模型分为编码器和解码器两部分,都是多层网络结构,其内部结构如图2所示.
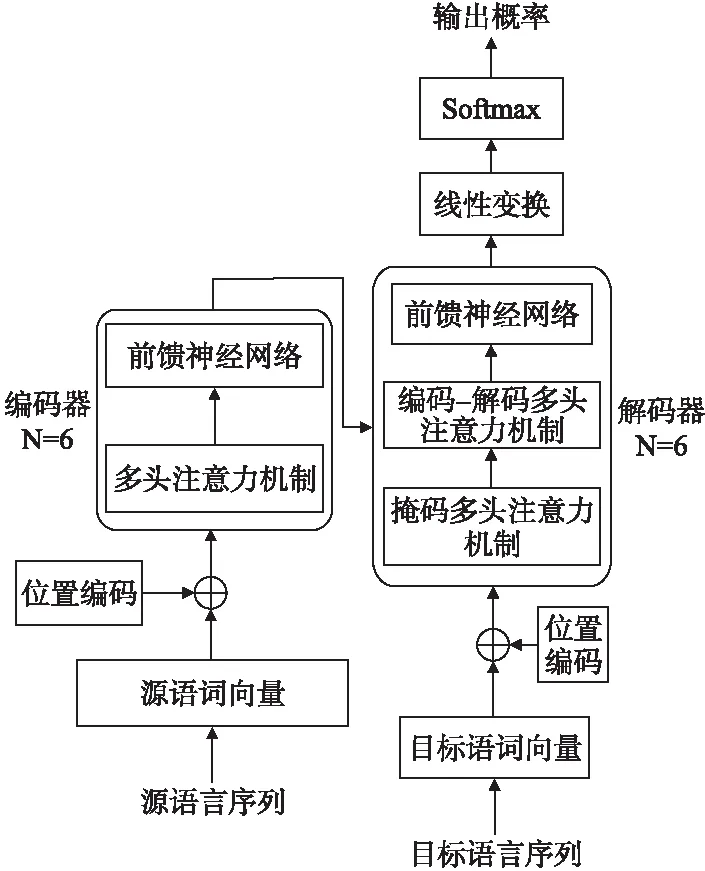
图2 Transformer内部结构图
编码端由N个相同层组成,每一层有两个子层,第1个子层是多头注意力机制,第2个子层是前馈神经网络.解码端同样也是由N个相同层组成,每一层有3个子层,第1个子层是掩码多头自注意力机制,第2个子层是编码-解码多头注意力机制,最后一个子层是前馈神经网络.

(1)
多头注意力是指采用h个注意力操作表示输入信息,将各个注意头的级联输出乘以权重矩阵计算所得.如式(2)所示.
MultiHead(Q,K,V)=Concat(head1,…,headh)WO
(2)
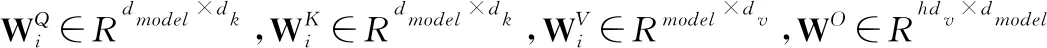
FFN(x)=max(0,xW1+b1)W2+b2
(3)
由于attention不包含位置信息,所以需要根据句子中词的位置信息给词嵌入添加位置编码向量.为了让模型能够学习到相对位置信息,使用位置编码生成固定位置表示,如式(4)所示.
(4)
已知三角函数公式如式(5)所示.

(5)
因此,PEpos+k可以表明PEpos的线性变换,如式(6)所示.

(6)
尽管目前主流的基于注意力机制的神经机器翻译模型能有效捕获长距离依赖,提升翻译效果.但是中文句式结构的复杂性和语义的多变性对模型而言具有一定的挑战性,这时利用语言学的知识增强翻译性能就显得至关重要.
3 基于句法规则层次化分析的神经机器翻译
近年来,神经机器翻译飞速发展取得了令人瞩目的成就,但目前的方法主要是从语料数据中自动学习翻译知识,没有在翻译过程中充分融入语言学知识[16].除此之外,对于不同长度的句子,神经机器翻译都使用固定维度的向量去表示,从而造成结构复杂的长句翻译效果不佳.
针对以上问题,本文提出了基于句法规则层次化分析的神经机器翻译,采用“句法分析——翻译短语MP和句子框架——译文重组”的方式进行.该方法旨在将复杂长句转化为一个或多个携带子句信息的最长短语和一个维系主要信息的主干句子框架,分别翻译之后重组译句,从而提升翻译效果.
3.1 句法规则层次化分析
句子s=[w1|t1,w2|t2,w3|t3,…,wi-1|ti-1,wi|ti,wi+1|ti+1,…,wn|tn],其中,S表示由n个词元有序组合而成的句子.字符wi表示S的第i个词元,词元wi的词性为ti.按照句法合成规则,将句子S通过迭代合成的方式得到最优结果.
3.1.1 句法规则库的构建
对于句法规则的制定,采用计算所汉语词性标记集[17],其共计99个(22个第1类,66个第2类,11个第3类).为了在规则制定中能够实现有效性及合理性,即采用词性标记集中的第1类标记作为规则需要.
根据对汉语句子组合信息的分析以及现代汉语语法研究对汉语句法的解读[18,19],通过提炼出的词性标记集和语言规则相结合的方式,实现句法合成规则库的构建,如表1所示.

表1 句法合成规则库
说明:
1)对标注好词性之后的语料,进行词性预处理.例如,将“nr”、“nsf”等第2类第3类词性统一记为一类词性“n”;
2)表1中第1列代表优先级,即每次迭代合成的顺序;
3)表1中第2列pos1和第3列pos2表示句中两相邻词分别对应的词性;
4)句子迭代过程通过规则Ri(pos1⊕pos2→synthetic_pos)实现两相邻词元结合得到第4列新词性.
据表1规则库,实现由pos1,pos2匹配合成得到Synthetic_pos的具体流程如图3所示.其中,POS_t是由句子S=[w1w2w3…wi-1wiwi+1…wn]获取的词性序列[w1_t,w2_t,…,wi_t,…,wn_t],对该序列从右至左依次获取,规则库按照自顶向下的方式对连续词元的词性进行匹配,合成新的hcc_t词性,再对原词性序列进行替换,直至遍历完POS_t.
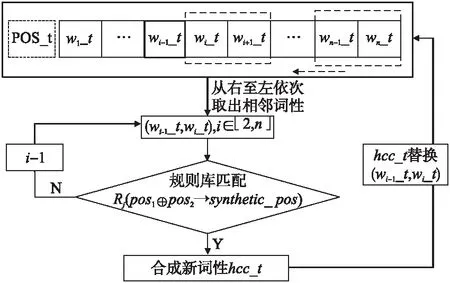
图3 规则合成示意图
3.1.2 层次化解析
在层次化语句分析过程中,利用分词和词性标注模型对中文句子进行处理,词与词之间用空格分开,每个词元与其词性之间用“|”分隔.例如,句子s=[中国|n人民|n政府|n给|v贫困|a的|ud农村|n家庭|n提供|v了|ul一笔|m现金|n补助|n]的层次化解析过程如图4所示.

图4 层次化解析示例
将整个层次化语句解析过程转化为树形结构格式,其可视化结果如图5所示.
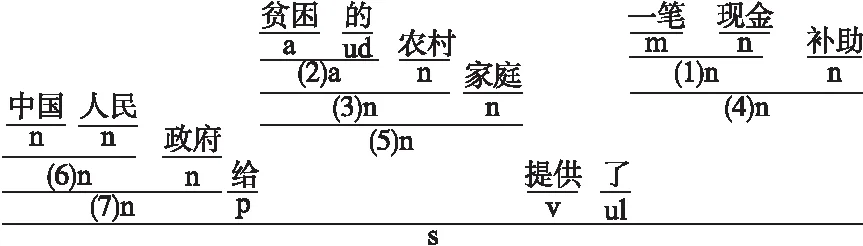
图5 语句解析可视化示例
3.1.3 提取短语MP
句法规则层次化分析,可以对中文句子进行短语结构的识别.该方法的优势在于可以随时调整规则库文件,从而更新得到最优合成方式,进一步提取出完整且符合要求的高质量最长短语MP.
该方法主要针对结构复杂的长句,考虑到短句子的译文质量较好,所以只对长度超过一定阈值(L=20)且可以进行句法分析的句子进行短语提取.由于较短的MP对缩短句子长度,降低句子结构复杂度的影响较小,提取过程中过滤掉长度小于3的短语,以及需要过滤掉符号标点等特殊字符.
提取短语MP时,本文采用两种方式在句子框架中保留特殊标记.
方法1:用MPi(i=1,2,3,…)代替最长短语本身保留在句子框架中,从而保证了短语和句子框架的对齐关系.
方法2:用最长短语的核心词代替最长短语本身保留在句子框架中,从而保证了语言的流畅度和语义的完整性.这两种方式都能缩减句式结构上的歧义带来的消极影响,降低句子的复杂度,缩短翻译句子的长度.
3.2 翻译MP和句子框架
利用句法规则层次化分析算法,从同源数据语料中获取得到最长短语,使用GIZA++开源工具训练得到中英MP对齐语料.训练神经机器翻译模型可以采用如下方式.
Model-Ⅰ:将MP语料加入到原训练语料中,扩展训练语料,通过训练得到既可以翻译MP又可以翻译句子的神经机器翻译模型.
Model-Ⅱ:MP语料和原训练语料分别训练,得到两个有针对性的翻译模型:短语翻译模型和句子翻译模型.
3.3 译文重组
将通过翻译模型得到的MP译文和句子框架译文进行重新组合,即把MP译文替换到句子框架译文中的相应位置,从而得到最终译文.由于提取短语时,在句子框架中保留特殊标记使用了两种不同的方式,则重组过程分别为:1)使用第i个MP译文替换句子框架中的特殊标记MPi;2)找到句子框架译文与MP译文关联度最高的词,该词即为核心词译文,再用MP译文替换句子框架的核心词译文.
3.4 整体流程描述
基于分治法的思想,将长句子翻译分解为若干个规模较小的短句进行翻译.即通过句法分析,分解得到短语部分和句子框架,再分别进行翻译,最后重组译文.本文采用了“句法分析——翻译短语MP和句子框架——译文重组”的方式,增加了语言学的知识,从而实现神经机器翻译性能的提升.整体翻译的流程如图6所示.
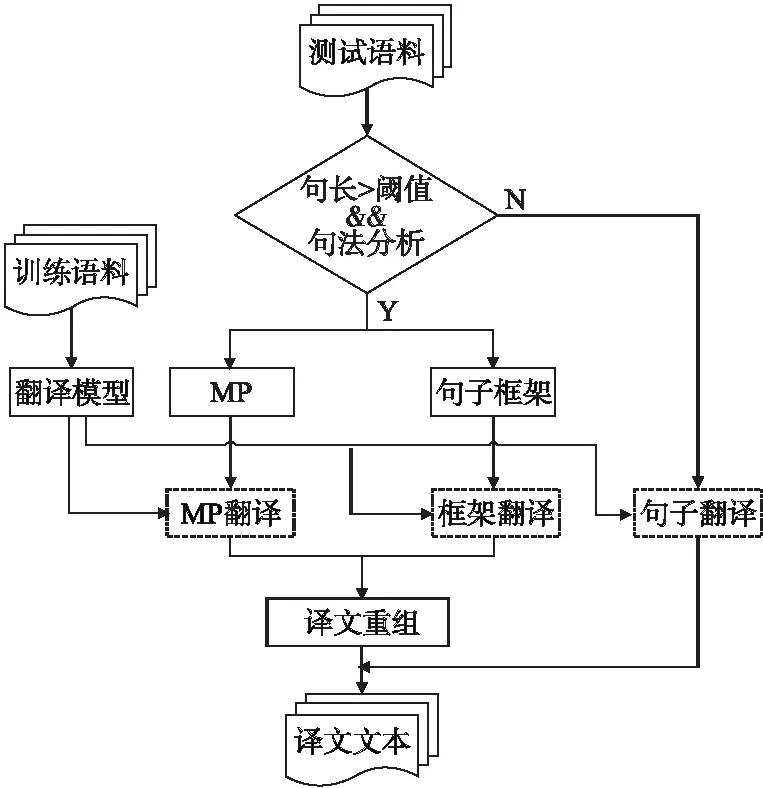
图6 整体翻译流程图
据翻译流程,表2给出了具体句子的翻译示例.

表2 句子翻译示例
4 实 验
4.1 语料设置
本文实验语料来源于全国机器翻译研讨会(CWMT)的中英双语平行语料.其中,训练数据集共900万句,对原始训练数据进行清洗、去重处理,实验过程只随机抽取600000句对语料作为训练数据集.开发数据集和测试数据集各2000句对.
双语MP数据集按照3.1.3节所述方式进行构建.本文随机从训练数据集中抽取100000句对中英双语平行语料,然后利用句法规则层次化分析的方法提取短语,使用GIZA++开源工具训练得到中英对齐MP语料359842句对,对该语料进行数据清洗,统一格式,删除乱码,统一全半角字符,去重等处理后得到162215句对中英对齐MP语料.实验语料的相关信息如表3所示.
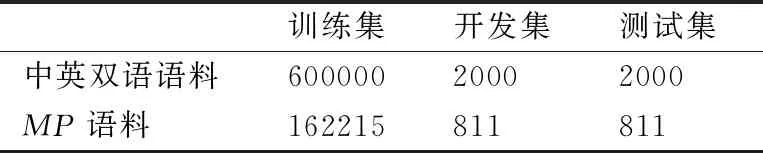
表3 实验语料信息
实验开发数据集和测试数据集语料信息如表4所示.

表4 验证/测试语料信息
对于测试语料,同样按照句法规则层次化分析的方式进行处理,测试语料句子的平均长度由 26.51个词降低到句子框架的12.73个词,极大程度上缩减了翻译句子的长度.
4.2 系统设置
本文的翻译系统,建立在基于完全注意力机制的Transformer神经机器翻译模型上,采用的深度学习框架tensorflow,以python作为开发语言,操作系统为Linux,使用RTX2080ti X4训练模型.表5给出实验中神经网络的主要参数设置和部分说明.
表5中,由于词表大小对神经机器翻译的影响较大,词表不能包含所有的词语,本文根据词出现的频率排序后获取前32000个得到词表,此表包含、、表示句子的开头,表示句子的结束,未出现在词表的词统一用

表5 模型参数设置
在训练过程中,模型设置运行20轮,使用目前工作性能比较优秀的Adam优化器[20]进行参数更新,使用labelsmoothing平滑方式防止损失函数过拟合.
实验采用目前机器翻译研究中比较常用的BLEU(Bilingual Evaluation Understudy)[21]自动评价方法分析所述机器翻译系统的性能,均使用大小写不敏感的BLEU衡量测试集的翻译质量.
4.3 实验结果及分析
4.3.1 句法分析算法识别效果
本文采用基于句法规则层次化分析的神经机器翻译方法来实现翻译性能的提升,因此,通过句法分析方式能否成功提取MP就显得尤为重要.本文从成功进行句法分析的句子中随机抽取200句,对句中的MP进行人工标注,通过句法分析模型识别结果与人工标注结果对比,得到该句法分析模型识别MP的准确率、召回率和F值.如表6所示.

表6 MP识别结果
表6中,MP识别准确率达到了80.57%,表明该句法分析模型的加入不会对后续的句子翻译过程造成消极影响.
4.3.2 翻译性能分析
实验以Transformer模型作为基准系统.按照2.2节所述方式得到两种翻译模型,Model-Ⅰ:MP语料加入到原语料得到既可以翻译MP又可以翻译句子的神经机器翻译模型;Model-Ⅱ:MP语料和原语料分别训练得到短语翻译模型和句子翻译模型.按照不同的标识方式进行译文质量对比.结果如表7所示.

表7 翻译结果对比
由表7可知,相比较于基线系统,Model-Ⅰ和Model-Ⅱ的翻译性能都获得了一定程度的提升.其中,Model-Ⅰ的MPi标识方式提升了0.21个BLEU值,保留MP核心词方式提升了0.62个BLEU值;Model-Ⅱ的MPi标识方式提升了0.40个BLEU值,保留MP核心词方式提升了0.95个BLEU值.
Model-Ⅱ的训练语料分布较为均匀,训练出的模型效果较好,即Model-Ⅱ翻译性能优于Model-Ⅰ;在翻译句子中保留MP核心词的方式保证了句子的流畅性和语义的完整性,所以其翻译性能优于MPi标识.
4.3.3 不同句长翻译分析
本文提出的基于句法规则层次化分析的神经机器翻译模型,主要针对长句的翻译.为验证本文模型的有效性,对测试集的句子按照不同长度划分后进行翻译实验.以性能较好的Model-Ⅱ作为对比实验.翻译结果如图7所示,横坐标表示不同句长的分布情况,纵坐标表示译文质量BLEU值.

图7 不同句长对应译文的BLEU 值
由图7的结果表明,总体译文质量随着句子长度的增加而逐渐降低.在句长小于20的句子翻译中,Model-Ⅱ的译文BLEU值相较于Baseline翻译模型不但没有提高,反而还有小幅度降低,这主要是由于在句法分析过程中造成了一定的损失,例如MP提取错误对翻译造成了一定的干扰;句长在20-40区间内,Model-Ⅱ的译文BLEU值比Baseline有小幅提升,之后随着句子长度的增加,基于句法规则层次化分析的神经机器翻译模型的翻译效果较好,且保留了MP核心词的方式的翻译性能较优.
5 结束语
本文针对目前机器翻译模型在翻译复杂长句时效果不佳的问题,提出了一种基于句法规则层次化分析的神经机器翻译方法.利用句法规则层次化分析算法从长句中提取短语MP,进一步分别翻译MP和句子框架,最后对译文重新组合.通过在一定程度上降低句子复杂度的方式来提升翻译性能.实验结果表明,相比于基线系统,BLEU值整体提高了0.95,并且复杂长句的翻译优势更加明显,该方法给神经机器翻译带来了积极有效的影响,在利用语言学知识增强机器翻译性能的研究中具有较好的参考价值.
实验主要是利用了中文的语言学知识,来实现中英翻译性能的提升,因此下一步可以考虑进行将本文方法迁移到中文到其他语言的神经机器翻译实验.由于中文本身的复杂性,语义多变性等特点,句法规则层次化分析提取MP的过程,会在翻译时对句子语义完整性造成一定的损失,后续还应对目前方法做进一步扩充和完善.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
华文教学与研究(2022年1期)2022-04-27
北京大学学报(自然科学版)(2022年1期)2022-02-21
现代计算机(2021年33期)2022-01-21
吉林大学学报(信息科学版)(2022年1期)2022-01-14
计算机测量与控制(2021年9期)2021-10-08
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
中华诗词(2018年3期)2018-08-01
中国房地产业·上旬(2018年1期)2018-05-14
