
基于数据挖掘下机器学习算法对学生成绩影响因素的研究
2021-11-21 11:47胡柳青
南昌航空大学学报(自然科学版) 2021年3期
胡柳青,赵 刚
(南昌航空大学 数学与信息科学学院,南昌 330063)
引 言
随着信息量的增加,数据的计算和分析方法也在不断地创新,机器学习算法被广泛应用于实际生活中。数据挖掘是一个对海量信息进行沙里淘金的过程,它能将多元异构的信息转化成可以直接应用的知识和商业价值。致力于利用大数据技术和机器学习算法解决各类应用问题的技术。而决策树技术在数字化教育领域中的信息挖掘和知识发现这两个层面的研究具有明显的预测效果。大数据背景下在线学习数据分析方案设计[1-2],大数据环境下数据分析是数据价值挖掘的重要过程,该方法用于在线学习课程成绩预测分析项目中,对其他数据分析项目也具有通用性。
基于学习分析的在线学业成绩影响因素的研究[3-4],对现有文献分析出目前研究中主要影响学业成绩的要素。结合对原始数据的深度处理,得到和学习相关的高级行为指标利用机器学习中决策树算法进行建模分析。基于教育数据挖掘的大学生实验课成绩预测研究[5-6],可以根据过去的行动数据来预测未来的行为。模型预测为学习分析提出更有意义的组成部分,通过教育技术方法帮助学习者不断提高学习成绩[7-10]。基于数据挖掘的高校学生成绩预测分析[11-13],以数据为基础的知识规则研究已经成为当前高校改进教学手段和提高教学质量的重要方法。基于决策树算法的成绩预测模型研究及应用[14-15],很好的运用机器学习方法能帮助老师更好的预测学生成绩,能及时发现学生在学习中存在的问题,为学生更好地学习提出建议。随着电化教育的兴起,数据挖掘技术已经广泛应用到了各个科学领域。决策树算法是机器学习中常用的一种数据分析算法,它既可用于解决分类问题,也可用于解决回归问题,本文通过介绍决策树算法对学生成绩进行预测,通过决策树来拟合数据建立模型,通过模型可以直观的反映数据所反馈的信息,从而进行预测。
1 数据收集和预处理
1.1 数据收集与流程概述
通过数据收集、数据清理、特征处理、误差分析等步骤,建立了良好的线性回归模型,寻找学生表现的最佳模型来预测学生成绩。数据如表1所示。

表1 学生考试成绩数据集文件
这是一个国外高中学生在校的学习行为和考试成绩的一个数据集,可以看出这是一个分类变量的数据集。
1.2 数据预处理
机器学习在进行数据建模时,要求数据集不包含无关数据和缺失值,但原始数据集不满足这一要求。因此,在建模之前应该通过数据清理来删除缺失值。
1) 用pandas,numpy来读取csv数据,利用sklearn来实现决策树的形成。
2) 导入数据集。该数据集是某高中学生在校学习行为,家庭背景及学生成绩的一个数据集,这是一个经典的决策树数据集。
3) 用pandas来读取csv文件,得到一个分类变量的数据集。为了方便建模,把数据集中的数据转换成数值变量,结果如表2所示。

表2 标签编码后量化后的学生成绩数据集
4) 提取训练集与测试集。
5) 标准差标准化(standardScale),使处理的数据符合标准正态分布。
2 决策树
2.1 决策树简介
决策树算法是一种有监督机器学习算法,通过树状图的结构直观反应数据的规则,达到数据可视化从而解决分类和回归的问题。其模型在机器学习中常被用于分类构成。
2.2 决策树生成
1)创建或载入数据集。
创建或载入训练的数据集,更常用的是利用numpy这个库来读取csv文件,载入一个数据集。Sklearn.tree中的决策树的类都在“tree”这个模块下处理流程如图1所示。
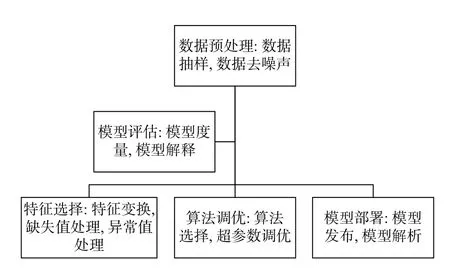
图1 数据预处理流程
2)生成决策树模型。
生成决策树,分割后的数据不一定都属于同一类,需要根据多数投票标准对子数据集进行分类。具体步骤如下:
(1) 实例化,用训练集数据训练模型,从接口中调用需要的信息;
(2) 交叉验证,决策树是基于决策及其对情况的可能后果的树状结构或图形,并且子节点的不纯度一定低于父节点的不纯度,决策树的拟合程度越好,模型预测的精准度就越高。通常使用基尼系数来选取参数,数据准备后划分训练集与测试集。
3)决策树可视化。
以字典的形式表示决策树更加抽象,通常以图像的形式呈现(如图2)。Matplotlib可视化决策树通过jupyter notebook直接生成图像。将treePlotter.py拷贝到文件的根目录,调绘决策树函数即可构建决策树模型,从sklearn,tree中调用DecisionTree-Classifier运行来画出一颗决策树,并且得到一个训练集和测试集的一个分数1分,可以得到结果1,说明决策树算法很适用于该数据集。决策树算法用来创建到达目标规划,并用来辅助决策,判其预测数据的可行性。
4)决策树结论。
该决策树基于gini系数大小比较首先来得到这个决策树分类的根节点,决策树的本质上通过是一层一层地根据条件递归从而做出判断,叶节点对应决策结果。在这个数据集展现出来的决策树中其预测的综合得分率为80%,显示预测结果具有一定程度上的可参考性,其中,其基尼系数越小,表示该数据纯度越高。当基尼系数最小趋近于0时,每一个参数对应的预测结果比例如表3所示。

表3 决策树基尼系数各参数预测比例
由表3可得:“父母学历水平”这个参数在整个参数比例系数达到80%最高,可预测学生成绩的参数评价比例最大,其次是“为考试做准备”这个参数在整个参数比例达到75%,可预测学生成绩比例很大。
3 学生成绩预测
3.1 数据预处理
1) 把学生的数学成绩及格分数定为40分,以这个分数来作为划分等级的起征点。
2) 利用pandas来读取数据集csv文件,使用pandas库中的数据框架描述函数,来观察数据的范围、大小、波动趋势、可以得到该数据集中学生成绩的各科分数的特征,包含了各科分数的平均数,标准差和方差,最大值和最小值。
3) 判断该数据是否存在缺失值。
4) 数据集包括8个参数:gender 性别,race/ethnicity 种族,parental level of education 父母教育水平,lunch 午餐,test preparation course 考试准备课程,math score 数学,reading score 阅读和writting score 写作。
5) 对数据集进行标签编码,并在数据框增加一列三科平均成绩,如图3所示。

图3 学生三科成绩总平均分
3.2 数据可视化
1) 父母的教育水平是否会影响该数据集学生三科总成绩的平均成绩;通过箱线图展示会加直观,运行数据如下图4所示;有没有为考试课程准备对该数据集学生三科总的平均成绩的影响,运行数据如图5所示。
图4中0,1,2,3,4,5分别表示副学士学历,学士学位,高中学历,硕士学位,大学学历,一些高中学历。从图5可知有为考试课程做准备的学生三科总的平均成绩比没有为考试做准备的学生三科总的平均成绩更高,其中父母具有研究生学历的孩子的三科总成绩的平均分数最高,其次是学士学位,副学士学位等。

图4 学生家长教育水平对学生成绩的影响图示
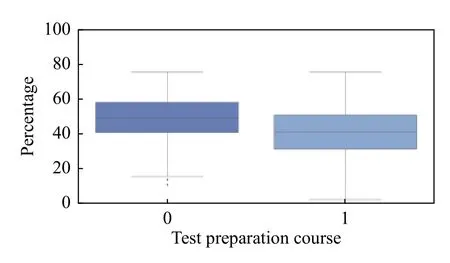
图5 学生有无考试准备对成绩的影响图示
3.3 学生成绩分等级
1) 如果以一个指标作为依据实现起来就比较简单;比如是平均成绩小于40即为挂科的话,在这一千个数据的数据集里,我们可以看到,三科合并GHA通过的有970人,三科合并GPA不通过的有30人。
2) 让我们来分配学生成绩分数,定等级 80以上 = A分,70 至 80 = B级,60 至70 = C级,50 至60 = D级,40 至50 = E级,40以下 = F级(表示不及格),我们将把获得的学生三科总的平均成绩按顺序画出来,运行代码,得到如下图6所示,通过图6可知A等级198人,B等级261人,C等级256人,D等 级178人,E等 级56人,F等 级51人。

图6 各等级数据分布条形图
3.4 影响学生成绩等级的各个参数的分布情况
1) 父母的教育水平是否会影响该数据集学生的三科总成绩平均分成绩等级,数据可视化如图7所示。有没有为考试课程做准备影响该数据集学生的三科总成绩平均分成绩等级的分布,数据可视化如图8所示。有没有吃午饭对该数据集学生三科总的平均成绩等级的划分有没有合格的影响,如图9所示。男生女生的性别对该数据集学生三科总的平均成绩等级划分有没有合格的影响,如图10所示。

图7 “家长不同教育学历”与学生成绩的分布条形图

图8 “考试准备课程”与学生成绩的分布条形图
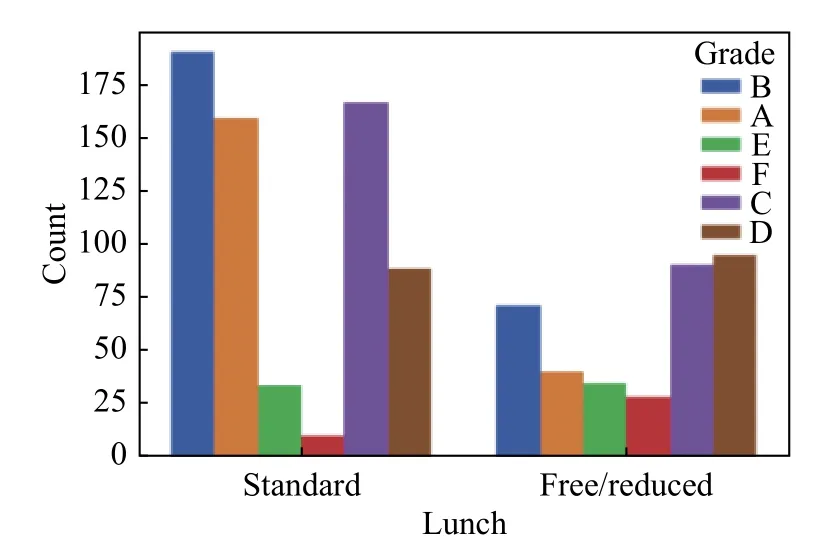
图9 “午饭”与学生成绩的分布条形图
图7中bd、sc、md、ad、sc和hs分 别 表 示bachelor’s degree,somecollege,master ’s degree,associate’s degree、some college和highschool,可得学生父母学历在“硕士”这个学位这一类A等级最高,在“一些大学−本科”这个学历这一类B等级最高。从图8可知有为考试课程做准备的这一类A等级最高,没有为考试做准备的这一类B等级最高。图9表明有标准午餐的学生在A等级最多,B等级最多。图10表明在女生这一类中A等级最多,在B等级最多。

图10 “性别”与学生成绩的分布条形图
4 结 论
根据以上的分析可知,“父母的教育水平”;“有没有为考试课程准备”;“来自不同种族和不同民族”;“有没有吃午饭”;“学生的性别”。根据数据的分析,我们发现在‘父母的教育水平’这个参数中的“研究生学历”的父母的小孩三科总成绩的平均分数通过率最高,成绩最为明显。本篇数据集中学生成绩三科的总平均分数在(70~80)B等级最明显,人数占有量最高,学生成绩三科的总平均分数在(60~70)C等级的人数在总排名的第二位;其次是(80以上)A等级的人数;(50~60)D等级的人数;(40~50)E等级的人数排第三位;最后是(40以下)F等级即不及格的人数。“父母学历”这个参数中“研究生学历”这一列属性‘A等级’人数最为明显和集中;‘有没有为考试课程做准备’这个参数中“准备”这一列属性“A等级”人数最为明显和集中;“有没有吃午饭”这个参数中“合格标准”属性这一列“A等级”人数最为明显和集中;最后“性别”这个参数中“女生”这一列属性“A等级”人数最为明显和集中。得出可以通过数据挖掘下机器学习等一系列算法来分析学生成绩的影响因素。
猜你喜欢
科学与信息化(2019年28期)2019-10-21
课外语文·下(2018年3期)2018-06-23
新作文·高中版(2017年5期)2017-06-10
农业工程技术·综合版(2017年1期)2017-04-05
科学与财富(2016年32期)2017-03-04
东西南北(2015年9期)2015-09-10
中国对外贸易(2014年7期)2015-04-22
疯狂英语·口语版(2013年2期)2013-03-19
决策与信息·下旬刊(2013年1期)2013-03-11
环球时报(2009-04-27)2009-04-27
