
自适应云资源大块数据对象并行存取方法
2021-11-19 08:17刘述木
计算机仿真 2021年10期
杨 建,刘述木
(1.四川省装备制造业机器人应用技术工程实验室,四川 德阳 618000;2.四川大学软件学院,四川 成都 610065)
1 引言
网络上的海量数据文件格式不同、复杂程度不同,如何在海量的数据文件中自由存取自己需要的数据,逐渐成为人们的焦点[1]。在传统的方法满足不了人们对云资源大块数据处理需求时,提出一种新型的大数据块对象的并行存取方法尤为迫切[2]。
李良[3]等提出基于NET的自适应云资源大数据块对象的存取方法。该方法首先在ASENET平台上使用C#对大数据块中的数据进行编程,再通过ADO-NET对数据库的后台进行访问,利用内存流对大数据块对象中的数据进行读取,最后启用通用自定义HTTP请求对大数据块对象中的数据进行处理,以此实现对自适应云资源大数据块对象的并行存取。该方法由于在对大数据对象进行并行存取时没有利用数据挖掘理论构建自适应云资源大数据块对象的并行存取模型,所以导致并行存取的存取时间长、存取效率低。索剑[4]等提出基于传统关系型数据,对大数据块对象中的数据进行结构处理,并将其分为模式与无模式两个部分,再分别对其进行预处理从而解决数据一致性与高效存取的矛盾。最后在同一数据库中对相同数据分别进行模式与无模式环境下的数据插入,查询等操作,以此完成自适应云资源大数据块对象的并行存取。该方法由于在并行存取时没有对大数据对象的数据采样梯度函数进行计算,获取大数据块对象的输出密度导致并行存取的正确率低,内存占比高。雷晓勇[5]等提出基于HWS的大数据块对象并行存取方法。该方法首先对常见的存储格式进行分析,并以分析结果为基础构建一个分级的数据存储格式,再利用高级的波形数据存储函数对大数据块对象中的数据进行计算,获取双精度的浮点数据。最后将其放入HWS中读取,以此完成自适应云资源大数据块对象的并行存取。该方法由于在并行存取时未能利用数据挖掘理论对数据的自适应调度加权系数进行计算,获取系数中的最低负载迁移量,所以导致并行存取的时间长、效率低。
为解决上述并行存取方法中存在的问题,提出基于数据挖掘的自适应云资源大数据块对象的并行存取方法,其创新之处在于利用聚类算法对大数据块对象中的数据进行缺失值填充后,将完整数据放入模型中进行自适应寻优处理,保证并行存取的完整度的同时,优化存取时间和正确率。
2 数据预处理
利用聚类算法对大数据块进行数据预处理,获取新的数据集。
2.1 DBSCAN算法
基于聚类算法(DBSCAN)对数据中的缺失值进行填充,过程如图1所示。
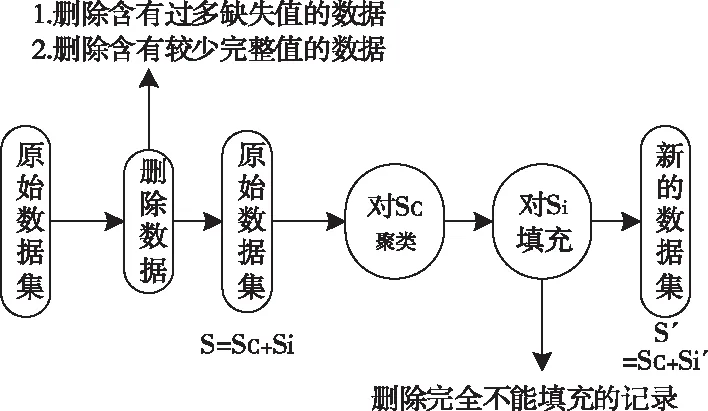
图1 数据填充过程
自适应云资源大数据块对象的原始数据中会存在部分的不完整数据,包括数据属性不完整、缺失值较大等问题。一般情况下,若缺失的属性值占属性记录的大半,那么就要将其从记录中删除。若某数据的属性值占比较小,也将其属性删除(其中若有数据的属性是独立的则可以保留),不然会对大数据对象的并行存取产生影响。利用删除属性策略对大数据集中的不完整数据进行删除,输出数据集S以及完整的子集Sc、缺失的数据集Si。
将原始数据集分为两个子集后,利用DBSCAN算法对自适应云资源大数据块进行聚类,产生k个簇。
基于产生每个簇的重心,计算缺失数据子集中每个属性记录与k个簇重心之间的相似度,并将记录值赋予给它相邻的簇,利用这个簇的属性均值填充该记录的缺失值。若缺失数据集中某一记录的缺失值无法填充就可以删除此条记录。填充过后,输出最终的清洗结果S′,S′则是由自适应云资源大数据块中完整的数据子集Sc以及经过填充处理的子集Si组成的。
自适应云资源大数据块中同类数据之间存在很多的相似属性[6],所以要通过对属性的计算获取聚类结果。再基于DBSCAN的缺失清洗算法对聚类结果进行计算,过程如下:
首先输入一个给点对象的半径b以及b区间(-b邻域)内的若干数据个数。
1)将自适应云资源大数据块中的数据集S分为两个子集,完整的记录子集为Sc(无任何属性含缺失值)及缺失的数据集Si(属性中有一个或多个缺失值)。
2)利用DBSCAN算法计算完整的数据子集Sc,选取自适应云资源大数据块的核心对象以及-b邻域,依据直接密度可达、密度可达、密度相连的方法对数据子集中的对象进行聚类并在聚类后计算每个簇中对象的均值,以此使目标函数值达到最小。
3)从自适应云资源大数据块的非完整数据子集Si中按顺序提取属性记录,计算记录与Sc的几个类中任一类的相似度,选出相似值为最大的记录,把该记录标记为Xi(i=0,1,2,…,k)类,重复上述过程一直持续到数据子集为空。
4)依据非完整数据子集的记录分配k簇,利用下式对记录缺失值进行处理

(1)
由于不完全数据子集Si中的每条记录都被赋予了最接近它的簇,而且不完全数据子集中的每条记录和被赋予的簇都有许多相似的属性,因此要使被赋予的簇具有完整的属性,就需要用它的平均值来填充[7]。式中,Ai代表数据集中缺失值被分配的第i个完整记录的数据值,n为属性的记录总数。
根据聚类算法可知,DBSCAN的缺失值填充算法对空间的需求不是很大,这主要是因为清洗数据时只需要存储数据集,其空间的复杂度为O(n-m+k),n为自适应云资源大数据块数据集中的记录数目[8],m为缺失值的记录个数,k为簇的数目。由于本算法在时间上同样没有什么需求,所以其时间的复杂度为O((n-m)kt1),(n-m)是自适应云资源大数据块数据集中的完整记录数目,t是需要进行迭代的次数。
根据上述过程,完成自适应云资源大数据块内的数据属性缺失值的填充。
2.2 数据分割
基于填充过缺失值的自适应云资源大数据块的完整数据集,采用均值聚类算法对数据集进行数据分割。
首先,设定数据集的给定聚类数为k,再基于算法的初值敏感问题优化初始中心的k-均值算法,分割过程如下所示:
1)确定分割区域
在填充过缺失值的数据集中设定一个半径R,再以此为基础为每个数据确认一个球形邻域,计算落在邻域内的数据个数。若邻域内的体积与邻域内数据个数的商不小于空间总体积与数据总个数的商,就可以认定该数据在高密度区域内。
2)选取初始聚类中心
设高密度区域内有m*个数据,首先随机选定一个数据作为第一中心y1;再选定距离y1最远的数据作为第二中心y2;选定一个数据yj作为第三中心,这时yj要满足下式
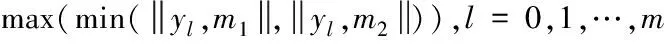
(2)
根据上述标准,继续选定m4,…,mk,找出高密度区域内的k个中心m1,m2,…,mk。
依据设定的P指标计算下式
(3)
式中
(4)
其中,m为自适应云资源大数据块对象中数据集的样本个数[9-10],数据的划分矩阵为U(X)=[uij]k×m,这时若xj∈Ci,uij=1,若不是uij则为0,mi是聚类Ci的中心,q=2。
依据选定的k范围,重复上述计算获取最终的P指标。
最后利用下式,对数据进行最终分割
koptimal=arg maxkP(k)
(5)
3 基于数据挖掘理论的并行存取方法
基于关联规则项的引导将分割后自适应云资源大数据块对象进行并行存取。过程如图2所示。
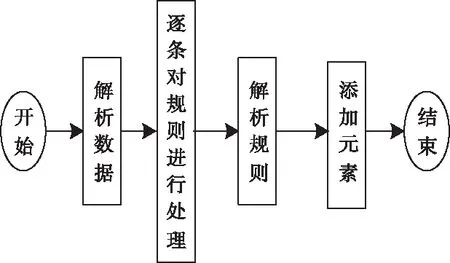
图2 并行存取过程
3.1 引入关联规则
依据随机概率的密度分布[11-12],对自适应云资源大数据块对象的数据实体节点与Sink节点进行均衡控制,并对其关系进行偏导函数求解,过程如下式所示
gk+akkoptimal=0
(6)
建立基于数据挖掘理论的自适应云资源大数据块对象的并行存取模型,首先要获取存取输入层神经元,如下式所示
(7)
大数据块对象中的数量小的端口节点负载神经元状态为下式所示
uni(k)=netni(k)
(8)
大数据块对象数据存取的输入层神经元输出如下式所示
(9)
式中,uni(k)为自适应云资源大数据块对象数据流量负载的边节点向量,采用控制律构建自适应云资源大数据块对象的数据调度控制模型。
把大数据块对象中最大或最小的数据神经元、,映射成随机生成的T个初始解,求解自适应云资源大数据对象的数据采样梯度函数,下式表示
xij=xmin,j+rand(0,1)(xmax,j-xmin,j)
(10)
利用关联规则对自适应云资源大数据对象进行并行存取,获取的输出密度如下式所示
opij=k*(minj+maxj)-xij
(11)
以输出密度为约束条件,即可得到数据的最佳寻优轨迹。
3.2 并行存取
采用模糊约束法对数据存储路径进行寻优,在自适应云资源大数据块对象的并行存取中,利用柯西的不等式理论计算数据块对象的二阶梯度,获取Δ2F(x),再利用多个非线性成分的联合统计法对大数据块对象中的数据进行高维空间重构,最后结合模糊聚类对大数据块内的数据进行自适应分类处理,获取数据存取的负载,如下式所示:

(12)
式中,自适应云资源大数据块对象的数据预测控制目标函数为F(x),数据块对象中的神经元三层前向神经元网格输入为νi(x)。最后运用模糊指向性聚类构建大数据块对象内的数据库及控制系统,最终获取数据挖掘的存储模型如下式所示
(13)
依据模糊约束进化论,建立基于数据挖掘理论的自适应云资源大数据块对象的并行存取模型,过程如下式所示:
(14)
通过对上式的计算,获取自适应云资源大数据块对象的自适应调度加权系数,系数中最低的负载迁移量则如下式所示
(15)
以上,利用上述模型对模糊约束进化的数据进行自适应寻优,再基于关联规则项的引导性融合法来实现自适应云资源大数据块对象的并行存取。
4 仿真研究
为了验证上述存取方法的整体有效性,需对此方法进行仿真测试。
4.1 仿真环境与数据来源
采用的操作系统为WindowsXP、程序Visual Studio、平台为Eclipse、内存为4G、硬盘为120G,仿真软件为MATLAB。
在Googledatasets(https:∥cloud.google.com/bigquery/public-data/)中,随机选取20,000个应用程序的相关信息,并抽样选取数据样本。为了使移动应用程序样本信息更加均匀分布,在样本的训练过程中,使用某个数据集中的移动应用程序标签,进行大块数据属性的自定义,包括音频、图片、视频、表格、文档类型,其中图片数据集由10个大块数据对象组成,大小为10 MB;视频数据集由10个大块数据对象组成,大小为150 MB;表格数据集由10个大块数据对象组成,大小为160 MB;文档数据集由10个大块数据对象组成,大小为60 MB;其它则使用模型默认参数值。
4.2 实验结果与分析
分别采用基于数据挖掘的方法(方法1)、基于NET的方法(方法2)以及基于传统关系型数据的方法(方法3)进行测试;
1)在相同的实验环境下对方法1、方法2以及方法3的自适应云资源大数据块对象的并行存取时间进行测试,测试结果如图3所示。

图3 并行存取的存取时间测试结果
分析图3可知,方法1的大数据对象并行存取时间要低于方法2和方法3,且能够将数据的并行存取时间维持在20秒左右,与方法2和方法3相比,本文方法较为稳定。这主要是因为方法1在对大数据块对象进行并行存取时利用数据挖掘理论构建了自适应云资源大数据块对象的并行存取模型,并通过计算获取了并行存取的输入层神经元,所以在运用该方法对大数据块对象进行并行存取时,存取时间短、并行存取的效率高。
2)在相同的实验环境中,对方法1、方法2以及方法3的自适应云资源大数据块对象并行存取的内存占比率进行测试,测试结果如图4所示。

图4 大数据对象并行存取的内存占比率测试结果
分析图4可知,在大数据块对象的并行存取时,方法1的内存占比率要优于方法2以及方法3,虽然方法3在测试初期的内存占比率一度低于方法1,但随着检测次数的增加,方法3的内存占比率呈急速上升趋势。这主要是因为方法1在对自适应云资源大数据块对象进行并行存取时,利用模糊指向性聚类构建大数据块对象内的数据库及控制系统,获取数据挖掘的存储模型,并将自适应云资源大数据块对象放入模型中进行自适应寻优处理,以此完成自适应云资源大数据块对象的并行存取,这样就可以缩短并行存取所用的时间,降低并行存取的内存占比率。
3)根据上述两个测试结果对方法1、方法2及方法3的并行存取正确率进行测试,测试结果如图5所示。
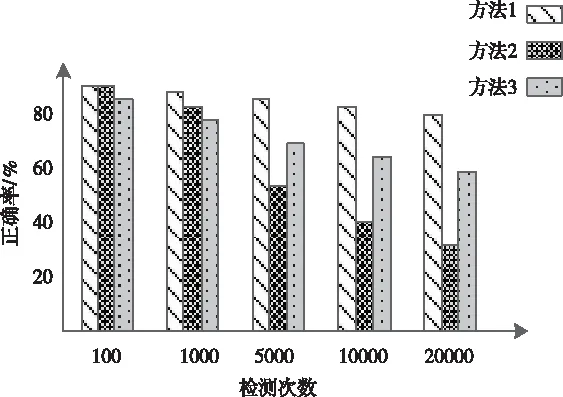
图5 大数据块对象并行存取正确率测试结果
分析图5可知,方法1的并行存取正确率要高于方法2和方法3,方法2虽然在测试初期正确率与方法1基本持平,但随着测试次数的增加,方法2的正确率急速下降,呈现出不稳定趋势。这主要是因为方法1在进行大数据块对象的并行存取时,利用数据挖掘理论对数据的自适应调度加权系数进行计算,获取系数中的最低负载迁移量。运用该方法对大数据对象进行并行存取能够提高存取的正确率,缩短存取时间。
5 结束语
1)针对传统方法在对大数据块对象进行并行存取时出现的存取时间长、内存占比高、存取正确低的问题,提出基于数据挖掘理论的自适应云资源大数据块对象的并行存取方法。
2)利用聚类算法与数据挖掘算法对大数据块对象中的数据进行数据缺失值填充以及数据分割处理。再利用数据挖掘理论计算偏导函数,构建并行存取模型,其并行存取时间维持在20秒左右。
3)将自适应云资源大数据块对象放入模型中进行自适应寻优处理,以此完成自适应云资源大数据块对象的并行存取,内存占比率最高仅为39%。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
九江学院学报(自然科学版)(2022年2期)2022-07-02
南京理工大学学报(2022年1期)2022-03-17
廉政瞭望·下半月(2021年5期)2021-07-20
计算机应用与软件(2021年7期)2021-07-16
大众投资指南(2021年35期)2021-02-16
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
意林(2018年3期)2018-03-02
汽车生活(2018年1期)2018-02-02
电子技术与软件工程(2016年24期)2017-02-23
