
基于优化聚类算法的大数据信息分流系统设计
2021-11-19 02:47广西电网有限责任公司信息中心万义飞梁彪周迪贵
数字技术与应用 2021年10期
广西电网有限责任公司信息中心 万义飞 梁彪 周迪贵
目前分流系统分流大数据信息效率较低,为此提出基于优化聚类算法的大数据信息分流系统设计。根据博弈论,建立信道选择模型;设计信道选择步骤,选择信息分流信道;采用优化聚类算法,聚类大数据信息,生成混沌序列,分流大数据信息。实验结果:设计系统相较此次实验选择系统,平均信息分流效率更高。
0 引言
大数据信息分流,是通过不同的网络,制定数据传输方案,增强网络容量。国内外十分重视大数据信息分流技术,目前国外已经研究出PBP、贪婪算法、DH算法、TH算法、TRH算法、快速交换算法等信息分流技术;国内虽然从整体上的研究成果上看,落后于国外研究成果,但是,也研究出FDLB算法、负载自适应均衡算法、网络入侵检测算法等信息分流技术[1]。在国内外研究基础上,文献[2]在系统中设计了信息特征采取及调度模块,实现数据分流。将这一研究方法,应用在大数据信息分流中,其信息分流效率较低,为此,引入优化聚类算法,聚类大数据信息,加快信息分流效率,设计基于优化聚类算法的大数据信息分流系统。
1 基于优化聚类算法的大数据信息分流系统设计
在当前分流系统硬件设计基础上,设计系统软件。考虑系统主要功能,建立信道选择模型,通过优化聚类算法,聚类大数据信息,依据聚类结果,实现大数据信息分流。
1.1 建立信道选择模型
大数据信息分流,需要先选择信息分流信道,而信道的选择是一个博弈的过程,因此采用博弈论,建立信道选择模型,则有:

(1)式中, 表示大数据信息的移动设备选择信道策略,其中,nb表示第 n台移动设备,选择的信道策略;nE表示设备在选择策略过程中,所产生的能量消耗;N表示传递大数据信息的移动设备总数量。
从(1)式中可以看出,当多个移动通信设备,在选择信道传输大数据信息时,若存在空闲信道,则这些用户都会考虑是否要转移到空闲信道上,移动通信设备所产生的能量消耗,就会发生变化。但是,每一个信道上的用户,都只能感知自身能量的消耗,并不了解总体上的消耗,产生的信道选择博弈,属于不对称博弈。在这一博弈下,移动设备产生的能量消耗的负方程 nE- 为:

(2)式中, b-n表示除第 n个移动设备外,其他移动设备选择的信道集合;Un表示效用方程。结合(1)式和(2)式,将信道选择模型定义为策略博弈 Γ,则有:

(3)式中,nς表示策略博弈空间。综合上述3个公式,即为此次设计建立的信道选择模型。为了让信道选择效用达到最大,需要将移动设备产生的能量消耗控制在最小范围内,因此,在此次计算中,-表示统一。
1.2 选择分流信道
根据此次设计,建立的信道选择模型,其选择信息分流信道过程,如下式所示:
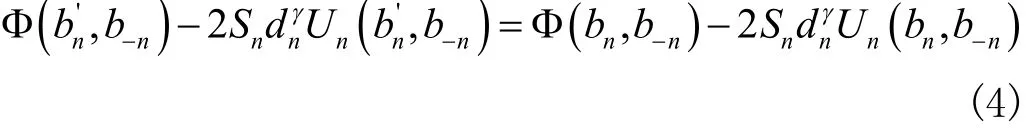
(4)式中, bn'表示第 n个移动设备,相较于 b-n信道选择集,选择的最佳信道;dn表示第 n个移动设备到基站的距离; Φ表示潜方程; Sn表示移动设备需要发送的信息量;表示大数据信息传输路径损耗系数[3]。
从(4)式中可以看出,移动通信设备改变信道选择策略后, Φ的变化与 nU的权值一致。基于此,设计的信道选择分流过程如下:
第二步,所有移动设备选择的信道策略均为bn;
第三步,在同一信道上,移动设备均要将大数据信息传输给用户h,需要信道中的信头采集所有移动设备大数据信息;
第四步,信头通过信道,将采集到的大数据信息传输给基站。在这一过程中,每一个移动设备都会在信道bn上,产生能量消耗,根据(2)式计算设备消耗;
第五步,随机选择一个新的信道策略bn',再次根据(2)式计算设备消耗;
第七步,重复步骤5和步骤6,计算每一个移动设备,实现每一个移动设备传输大数据信息的信道选择。
1.3 基于优化聚类算法分流大数据信息
当移动设备完成信道选择后,需要在信道中搜索 D维大数据信息,为此,假设信道属于一个种群,其中存在的大数据信息,为若干个粒子,则信道中,大数据信息高维映射矢量 χ,所对应的函数 fi(t)为:

在(5)式的作用下,数据聚类中心,会聚集信道中的大数据信息,此时,得到的聚类目标函数 A的表达式为:


(7)式中, Yn+1表示混沌序列;Yn表示 Yn+1中的子序列。依据(7)式产生的混沌序列,采用扰动的方式,提高粒子群的搜索能力,则得到的粒子扰动向量为:

(8)式中,id D∈ ,表示第 i个粒子的维度; g表示最高适应度的搜索空间维度;表示任何维度中的粒子上限值;δ表示任何维度中的粒子下限值。此时,重新迭代计算粒子,得到的混沌序列 Y为:

(9)式中, m表示数据分流选择的信道,md表示信道所处维度;mY表示信道中分流的大数据信息。
综合上述计算过程,选择大数据信息分流信道,依据选择的信道,聚类大数据信息,将聚类的大数据信息,按照选择的信道分流。
2 系统测试
将云计算平台下的大数据分流系统,作为此次设计对比测试对象,在仿真平台上,测试两组系统的大数据信息分流算法,验证此次设计的大数据信息分流系统。比较两组系统,分流大数据信息效率。
2.1 实验准备
此次实验,选择ONE平台作为两组系统分流算法的运行平台,在平台上,设置的仿真参数,如表1所示。
基于表1所示的ONE平台仿真参数,选择宗教、文化、经济、政治、体育五种类型的大数据信息,每种信息10000条,作为此次系统测试实验验证对象。
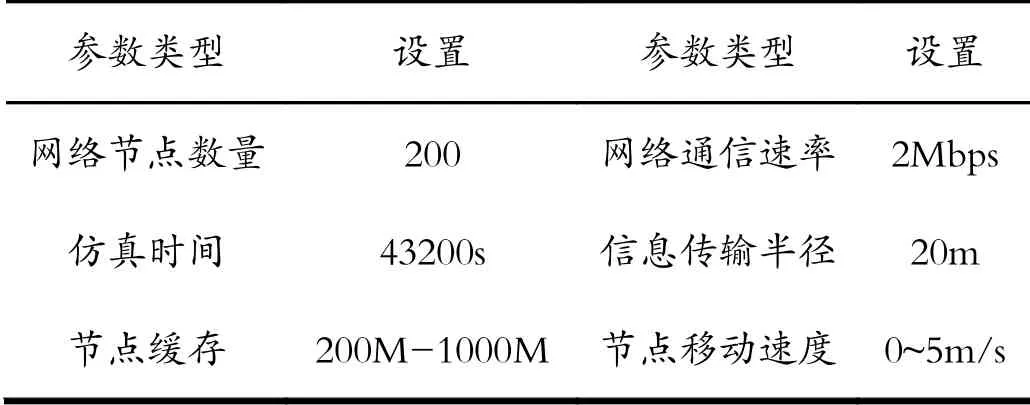
表1 仿真参数Tab.1 Simulation parameters
2.2 实验结果
采用两组系统,分别分流五种类型的大数据信息,计算两组系统划分每种类型大数据信息的分流效率η,其计算公式如下式所示:(10)式中, N表示分流的数据量; M表示每种类型大数据信息的总数量。根据(10)式所示的分流效率计算公 式,得到两组系统,分流五种类型大数据信息的分流效率,如表2所示。

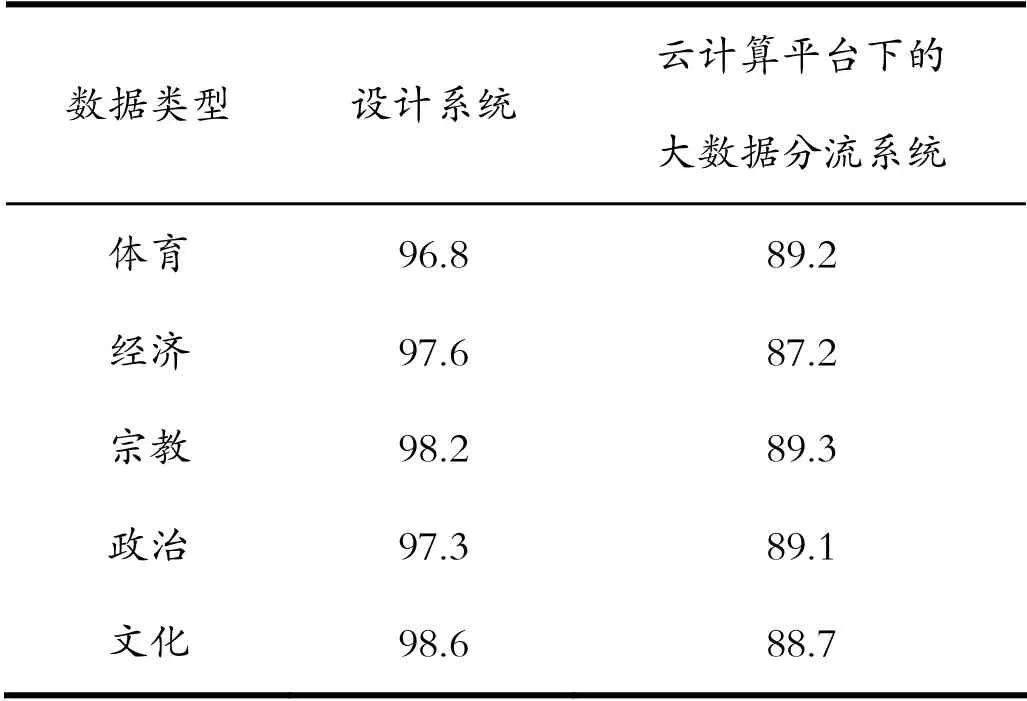
表2 两组系统信息分流效率对比表(%)Tab.2 Comparison table of information shunt efficiency between two groups of systems (%)
从表2中可以看出,云计算平台下的大数据分流系统的平均信息分流效率为88.7%;设计系统的平均信息分流效率为97.7%,较云计算平台下的大数据分流系统的平均信息分流效率高了9%。可见,此次设计系统,具有较高的大数据信息分流效率。
3 结语
综上所述,此次设计,充分利用优化聚类算法,聚类大数据信息,让其可以根据选择的分流信道,进行信息分流。经实验验证,此次设计的系统,提高了信息分流效率。
引用
[1] 郭威,廖丹,王建永,等.双链接无线网络海量电力大数据合理分流方法[J].电子设计工程,2019,27(21):112-116.
[2] 解艳.云计算平台下的大数据分流系统的设计研究[J].电子设计工程,2019,27(9):119-122.
[3] 赵旭,李艳梅,罗建,等.基于Docker容器动态迁移数据分流框架[J].西华师范大学学报(自然科学版),2019,40(2):210-216.
猜你喜欢
预防青少年犯罪研究(2022年1期)2022-08-15
电子测试(2017年15期)2017-12-18
电信科学(2017年6期)2017-07-01
雷达学报(2017年6期)2017-03-26
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
华东理工大学学报(自然科学版)(2015年4期)2015-12-01
电子设计工程(2015年8期)2015-02-27
电子设计工程(2015年6期)2015-02-27
肝胆胰外科杂志(2015年1期)2015-02-27
现代防御技术(2014年6期)2014-02-28
