
基于YOLOv4神经网络的红外图像道路行人检测*
2021-11-19 02:46:40刘怡帆王旭飞周鹏谭飞焦登宁
数字技术与应用 2021年10期
刘怡帆 王旭飞,2 周鹏 谭飞 焦登宁
1.陕西理工大学机械工程学院;2.陕西理工大学陕西省工业自动化重点实验室
针对不良光照道路目标检测任务中识别行人目标精度不高的问题,提出用行人特征先验框的YOLOv4神经网络模型和增强型红外图像数据集来提高行人目标检测的精度。具体通过提取KAIST红外视频图像作为数据集,利用CLAHE方法对图像进行增强处理,然后使用KMeans++算法对行人特征进行先验框聚类。通过训练和测试,检测到mAP和mIoU分别达到98.42%和81.95%,具有良好的效果。
0 引言
在众多的公共交通参与者中,行人作为最广泛的群体是交通安全领域中重要的关注对象之一。目标检测是指利用计算机视觉技术在输入的图像或视频中检测是否含有目标,并输出目标的位置,其广泛应用于汽车辅助驾驶、智能安防等领域。
可见光成像设备可以捕获丰富的色彩信息和纹理细节,所以常见目标检测算法均基于可见光成像设备拍摄的图像和视频进行检测。但可见光成像设备在夜间、雨雾等光照条件复杂的情况下成像效果较差,难以保证成像清晰。红外成像设备可以很好的解决可见光设备遇到的问题[1]。人体体温在37℃时辐射的波长约为9.3μm[2],所以使用长波红外摄像机更容易捕捉到行人等目标,并且在面对强光、弱光等光照条件时鲁棒性也更好。这为全天候的目标检测和处理提供了良好的数据源。
近年来,深度学习的方法受到多数学者的青睐。基于深度学习的方法通过构建卷积运算的神经网络,输入大量训练样本对其进行训练,并自动学习目标的特征,相较于传统算法提高了泛化能力和识别率。A.krizhevsky等人利用卷积神经网络[3]在行人检测上取得了较好效果,之后又出现了R-CNN[4]、Fast R-CNN[5]、Faster R-CNN[6]等改进算法,但这些算法运算量大、运行速度慢,实时性低。
1 YOLOv4网络模型
Redmon等人提出YOLO系列算法[7-8],Bochkovskiy等人在此基础上提出了YOLOv4[9]模型,主干网络借鉴CSPNet的网络结构,构建了基础网络模型CSPDarknet 53,引入了Mish激活函数、SPP、PANet等结构增强了网络的学习能力,同时在数据增强、损失函数等方面进行了优化,降低了计算量,在检测精度和检测速度之间达到最佳平衡。本文使用的YOLOv4网络模型结构如图1所示。
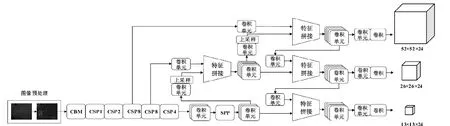
图1 YOLOv4网络模型结构Fig.1 YOLOv4 network model structure
2 数据集处理
2.1 数据集
KAIST数据集[10]是采用载有远红外摄像机的汽车在不同路况和不同时间段(白天、夜间)的道路上所采集的红外视频,包括Person、Cyclist和People三类目标,适合道路行人检测研究。但是KAIST视频中相邻帧场景相似度较高,我们从视频中每隔两帧提取一张图像,进行清洗,最终得到7600张图片作为本次实验的红外数据集,其中随机选取760张图片作为测试集,其余6840张图片作为训练集。
2.2 图像增强预处理
原始KAIST数据集中红外图像的直方图分布较为集中,图像中行人目标与背景区分不明显,目标轮廓模糊。采用限制对比度自适应直方图均衡化(CLAHE)的方法对图像进行增强处理,使直方图分布更加均匀,提升图像对比度,从而获取更多行人目标特征,弱化不需要的背景信息[11]。原图与增强后图像对比如图2所示。

图2 图像增强效果对比Fig.2 Comparison of image enhancement effects
2.3 K-Means++聚类
KAIST数据集图像中行人目标大部分是静态站立和动态行走状态,所以行人对象特征的高宽比数值比较集中,利用这个特点,对图像目标采用聚类算法进行行人特征的先验框聚类,可以提高行人目标的检测速度和精度。K-Means算法在先验框的聚类中得到了广泛的应用,但其结果受制于初始点的选择,采用K-Means++算法[12]可以有效防止K-Means算法因病态初始点而影响最终的聚类结果。聚类过程一般不使用欧氏距离,而采用先验框与目标框的交并比(IoU)计算距离,如公式(1)所示:
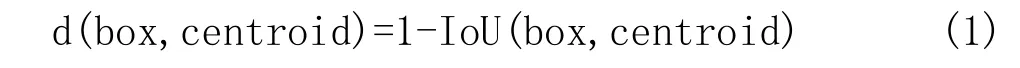
通过K-Means++算法对KAIST数据中的3类目标进行聚类,如图3所示,在权衡交并比和先验框数量的关系后最终取9组先验框参数,分别为:[15,42,20,55,30,38,25,71,29,90,37,106,127,44,47,142,59,189]。
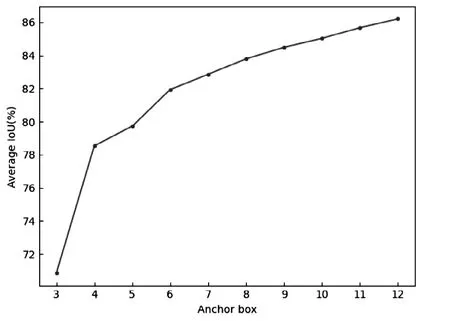
图3 先验框个数与平均交并比关系Fig.3 Relationship between the number of a priori frames and the average intersection union ratio
在KAIST数据集中计算K-Means++聚类后的先验框与YOLOv4中原先验框的平均交并比,结果如表1所示。

表1 不同先验框的平均交并比Tab.1 Average intersection union ratio of different a priori frames
从表1看出,使用K-Means++算法聚类后的先验框,可以使得平均交并比由65.59%提高到了84.49%,从而让网络模型对目标的识别能力增强,提高检测精度。
3 实验与结果
3.1 实验环境
实验所使用处理器为i9 10900X、内存64GB、操作系统为Windows 10并采用两张NVIDIA RTX 3080 10G显卡配合CUDA 11.1和CUDNN 8.0.4加速环境进行训练。
3.2 网络训练
网络训练以深度学习架构Darknet为基础,为了保证较快的训练速度以及防止局部最优的出现,设置网络超参数中的冲量常数为0.9,初始学习率为0.001,设置网络最大迭代次数为12000次。网络训练过程中的平均损失函数随迭代次数的变化如图4所示。
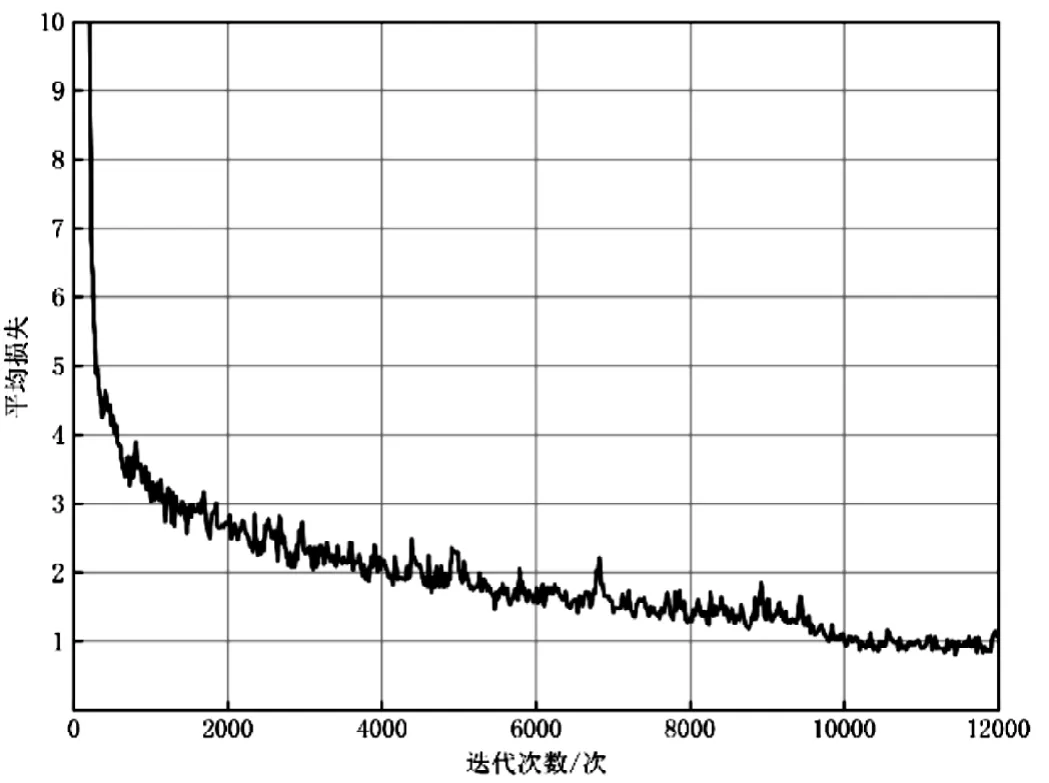
图4 平均损失随迭代次数的变化关系Fig.4 Variation of average loss with iteration times
图4显示,在网络12000次迭代中,0到6000次迭代平均损失函数下降明显,迭代次数超过10000次后平均损失函数值逐步稳定,随着训练的进行,最终平均损失函数收敛到1.0附近。
3.3 检测结果
为了准确评价网络模型的性能,选取准确率P、召回率R、F1分数、平均精度均值mAP、平均交并比mIoU、每秒传输帧数FPS作为评价指标对模型进行评价。用行人特征先验框的YOLOv4神经网络模型和增强型红外图像数据集进行训练后的权重文件,在建立的测试集上进行检测,测试结果列于表2,其中平均精度均值mAP和平均交并比mIoU分别达到98.42%和81.95%。
为了进一步验证本文方法的有效性,将YOLOv3、YOLOv4-tiny、原YOLOv4网络也进行训练、测试,得到各项评价指标也列于表2中。
由表2看出,YOLOv3、YOLOv4-tiny、原YOLOv4网络的检测结果中平均精度均值mAP和平均交并比mIoU均低于替换先验框后的YOLOv4网络。其他性能参数,包括准确率P、召回率R、F1分数,替换先验框后的YOLOv4网络也大于或等于其他3种网络模型。在检测速度方面,YOLOv4-tiny网络模型的每秒传输帧数是121.2FPS,几乎是其他3种模型的2倍,本文方法的每秒传输帧数为63.4FPS。说明本文方法进一步提高了YOLOv4网络模型的目标检测精度,也满足目标实时检测的需求。

表2 多种神经网络模型检测结果对比Tab.2 Comparison of test results of various neural network models
4 结语
通过使用YOLOv4网络模型,选择KAIST红外视频图像作为数据集,以数据集中的行人、人群和骑车人为3类目标对象。用CLAHE方法对红外图像数据集进行图像增强,使用K-Means++算法对数据集图像中的目标对象进行先验框聚类,并用具有行人特征的先验框替换YOLOv4中原先验框。实验结果表明,YOLOv4网络模型与其他3种网络模型相比,在红外图像数据集中具有较好的检测结果,在测试集上检测到mAP和mIoU分别达到98.42%和81.95%。说明通过以上方法可以有效提高夜间等不良光照条件下目标检测精度及检测速度,也可以用于实时的目标检测任务,为汽车辅助驾驶提供帮助。
引用
[1] GengiK,Yin G.Using Deep Learning in Infrared Images to Enable Human Gesture Recognition for Autonomous Vehicles[J].IEEE Access,2020(99):1.
[2] St-Laurent L,Maldague X,Prévost D.Combination of colour and thermal sensors for enhanced object detection[C].2007 10thInternational Conference on Information Fusion.IEEE,2007:1-8.
[3] Alex Krizhevsky,Ilya Sutskever,Geoffrey E Hinton.ImageNet classification with deep convolutional neural networks[C].Proceedings of the 25thInternational Conference on Neural Information Processing Systems,2012:1097-1105.
[4] Girshick R,Donahue J,Darrell T,et al.Rich feature hierarchies for accurate object detection and semantic segmentation[C].IEEE Conference on Computer Vision and Pattern Recognition(CVPR),2014:580-588.
[5] Girshick R.Fast r-cnn[C].Proceedings of the IEEE international conference on computer vision,2015:1440-1448.
[6] Ren S,He K,Girshick R,et al.Faster r-cnn:Towards realtime object detection with region proposal networks[J].Advances in neural information processing systems,2015(28):91-99.
[7] Redmon J,Farhadi A.YOLO9000: Better,Faster,Stronger[C].Proceedings of the IEEE conference on Computer Vision and Pattern Recognition Washington D.C.,USA:IEEE Computer Society,2017:6517-6525.
[8] Redmon J,Farhadi A.Yolov3:An Incremental Improvement[C].IEEE Conference on Computer Vision and Pattern Recognition,2018.
[9] Bochkovskiy A,Wang C Y,Liao H Y M.YOLOv4:optimal speed and accuracy of object detection[J].Computer Vision and Pattern Recognition,2020,17(9):198-215.
[10] Hwang S,Park J,Kim N,et al.Multispectral pedestrian detection: Benchmark dataset and baseline[C].Proceedings of the IEEE conference on computer vision and pattern recognition,2015:1037-1045.
[11] 刘玉婷,陈峥,付占方,等.基于CLAHE的红外图像增强算法[J].激光与红外,2016,46(10):1290-1294.
[12] Vassilvitskii S,Arthur D.k-means++:The advantages of careful seeding[C].Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms,2006:1027-1035.
猜你喜欢
环球时报(2022-05-23)2022-05-23 11:28:37
金桥(2021年4期)2021-05-21 08:19:20
意林(2021年5期)2021-04-18 12:21:17
成都信息工程大学学报(2019年3期)2019-09-25 08:31:14
电子制作(2019年7期)2019-04-25 13:17:14
扬子江(2019年1期)2019-03-08 02:52:34
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
自动化学报(2017年5期)2017-05-14 06:20:44
光学精密工程(2016年3期)2016-11-07 09:03:43
探测与控制学报(2015年4期)2015-12-15 15:00:56
