
基于局部注意力机制的中文短文本实体链接
2021-11-18 02:18张晟旗王元龙王笑月王晓晖闫智超
计算机工程 2021年11期
张晟旗,王元龙,李 茹,2,王笑月,王晓晖,闫智超
(1.山西大学计算机与信息技术学院,太原 030006;2.山西大学计算机智能与中文信息处理教育部重点实验室,太原 030006)
0 概述
自然语言处理任务中的文本深度语义理解是一项热门研究课题。自然语言自身存在着模糊性、复杂性、多义性等多重特点,实体链接则是文本深度语义理解的有效解决方法。实体链接是将文本中实体与知识库的相应实体信息进行链接的过程,即通过实体指称项及其所在的上下文的文本信息,借助目标知识图谱将文本实体链接到知识图谱中正确的映射实体上,从而丰富文本的语义信息[1]。实体链接任务可分为实体识别和实体消歧2 个部分。在实体识别过程中,识别实体指称项,是指源于待链接文本中的实体。在实体消歧过程中,先根据识别出的实体指称项从知识库中选择待消歧实体信息,以生成该实体指称项的候选实体集,再以实体指称项的上下文信息为依据对候选实体集中的实体进行消歧。
传统的实体链接任务主要对长文本进行处理,长文本中有更多更丰富的上下文信息,因而也更有利于链接[2]。相比长文本,短文本的实体链接则更具挑战性,加之中文自身的灵活性、表达会意性、语法结构多样性等特点,使得对中文短文本的深度理解变得更为困难。传统的方法主要基于特征工程,这使得模型复杂、缺乏灵活性,弱化了模型的泛化能力并伴随产生特征稀疏等问题。
本文针对中文短文本实体链接中的实体识别与实体消歧任务,构建一个基于局部注意力机制的中文短文本实体链接模型。在实体消歧过程中引入局部注意力机制,以增强实体邻近上下文的语义信息,并在实体识别过程中使用半结构半指针的“01”标注方式代替传统的BIO 标注方式对实体进行标注。此外,根据数据集的特点采用容错机制以提升链接结果的准确率与容错性。
1 相关工作
实体链接旨在通过查找出文本中的实体并根据该实体所在的上下文与知识库中实体的语义关系来完成文本与知识库的链接,在此过程中需要对每一个实体适当地消除其引用知识库中的实体的歧义[3]。现有的实体链接方法大体可划分为2 类:一类是级联地对2 个任务进行独立学习;另一类则是对2 个任务采用联合学习的方法。
在早期的实体链接研究中,多数工作都是基于特征工程的,并且对实体识别与实体消歧这2 个任务是独立处理的,即从每个子任务入手,根据任务的特点分别处理2 个任务。此类方法的实现基于以下2 个假设条件:1)前1 个任务的结果完全正确,并可以直接用于后续任务中;2)2 个任务之间没有任何依赖关系。实体识别的方法是根据命名实体识别方法改进,再对不同类型的文本及实体特征加入特征选择,如文献[4-6]都是基于自己定义的实体特征与线性链条件随机场结合的方法实现的。随着深度学习的广泛使用,文献[7]使用具有长短时记忆特点的Bi-LSTM 来学习实体语义的特征并用于识别其范围,文献[8]使用自注意力机制来获取输入文本的全局信息,并最终证明自注意力机制在命名实体识别任务中的有效性。实体链接是一个相对下游的任务,其性能受限于命名实体识别任务的准确性,对于中文的实体链接任务而言,还会受到中文分词任务的影响,上游任务的错误会对实体链接任务带来不可避免的噪音[9]。实体消歧任务的主要目标是计算识别出的实体与候选实体间的相似度,在早期也是以特征过程以及各种相似度计算方法为主,如文献[10]对实体流行度、语义关联度等多种特征进行特征组合,提出半监督算法。在深度学习方法以其能够代替手工定义特征等优势被广泛使用之后,文献[11]提出使用实体表示和局部注意力机制来减少手工设置特征并加强实体的语义表示。但是这类方法有着明显的弊端。首先,2 个任务是级联进行的,第2 个任务的准确率很大程度上依赖于第1 个任务的准确率,这样会导致训练过程中存在着错误传递的问题;其次,早期研究人员忽略了2 个子任务之间存在着依赖关系,不应当看成单独训练的任务进行处理。
针对上述问题,国内外研究者提出了联合学习的方法。联合学习方法能充分利用多个任务间的内在依赖关系,有助于修复上阶段传播的错误[12]。文献[13]根据中文分词任务与中文命名实体识别任务之间的共同特性(即都需要进行实体边界识别),使用对抗学习方法来联合训练命名实体识别任务和中文分词任务,抽取共享的词边界信息。文献[14]使用一个流行的命名实体识别模型以尽可能全地识别出实体,避免实体识别的效果对链接结果造成影响,对于剩余无需连接的实体则直接通过链接过程删除。文献[15]将待消歧实体和待消歧实体上下文语境映射到同一个空间,基于概率空间模型并根据实体的空间向量进行消歧。文献[16]利用半条件随机场对2 个任务进行联合学习。文献[17]提出对全局实体链接的动态上下文增强模型(Dynamic Context Augmentation,DCA),将已链接的实体知识作为动态上下文加入之后消歧过程的决策之中。文献[18]提出端到端的实体链接模型RRWEL(Recurrent Random Walk based EL),通过使用卷积神经网络(Convolutional Neural Network,CNN)学习局部上下文、实体指称项、实体以及实体类型信息的语义表征,并使用随机游走网络对文档信息进行学习,结合局部信息和全局信息得到文档中每个实体指称项对应的正确实体。文献[19]提出一个基于深度语义匹配模型和CNN 的实体链接模型,在候选实体生成阶段采用构造同名字典的方法,并基于上下文进行字典扩充,通过匹配来选择候选实体集。
自ELMO 模型[20]提出之后,大规模预训练语言模型迅速成为主流方法,而文献[21]提出的注意力机制更是奠定了BERT 预训练语言模型[22]在自然语言处理领域的重要地位。此后,研究者针对不同任务对BERT 模型进行了改进,并取得了较好的效果。文献[23]将BERT 预训练语言模型引入实体链接任务,对实体指称项的上下文以及候选实体的相关信息进行关联度分析,通过提升语义分析的效果来优化实体链接性能,并采用TextRank 关键词提取技术增强目标实体综合描述信息的主题信息,从而提高文本相似度度量的准确性,优化模型效果。文献[24]提出结合全局注意力机制与局部注意力机制的思想,前者在每次计算上下文向量时需要计算文本中的所有隐状态,而后者则仅考虑输入序列子序列的隐状态。本文将局部注意力机制应用到中文短文本的实体链接中,对待消歧文本与实体的知识描述文本进行拼接,然后利用局部注意力机制强化实体的上下文信息,从而增强短文本的语义信息。
2 本文模型
本文针对中文短文本的实体链接任务,提出基于局部注意力机制的中文短文本实体链接模型,通过完成实体识别与实体消歧来实现待消歧文本与知识库信息链接的管道模型。为缓解管道模型上游任务结果对下游任务结果产生的级联影响,在实体识别与实体消歧任务的训练过程中使用共享参数的方法实现联合学习,在上游任务与下游任务之间利用其内在联系提升模型效果,减少上游任务的错误结果在下游任务中的传播。本文中实体识别和实体消歧的模型都是基于BERT 模型进行改进的:实体识别使用BERT+条件随机场(Conditional Random Field,CRF)模型,并以半结构半指针的“01”标注方法代替传统的BIO 标注方法,通过“0”和“1”来获取实体表示以及实体的位置信息;实体消歧则是在BERT 模型基础上加入局部注意力层来重点强化与实体邻近的上下文信息并优化消歧结果的容错机制。
2.1 实体识别
本文将实体识别任务作为一个序列标注任务进行处理,使用BERT+CRF 模型对文本序列中的实体进行位置标注。本文模型架构如图1 所示。由于在本部分中考虑到模型训练与预测的时间复杂度,因此未在模型内部架构进行大规模调整改进,而是选择使用更高效的半结构半指针的“01”标注方法替换传统的BIO 标注方法,半结构半指针的“01”标注方法通过“0”与“1”这2 个标签作为文本中的实体首尾位置的标记信息,以区分实体在文本中的范围,相较于BIO 标注方法更简洁更高效。

图1 实体识别模型架构Fig.1 Framework of entity recognition model
首先,对输入文本的长度进行标准化处理,所有文本长度以35个字符为界设限,少于35个字符的进行零填充,多于35个字符则将其截断。在进行“01”标注时,创建2个与文本长度一致的序列并用“0”对其进行初始化,这2个序列则分别用来表示实体位置的首字符的位置与尾字符的位置,并将识别出的实体的首尾位置的“0”标记改为“1”,通过对2个序列中“1”标记的配对来识别实体。BIO标记法与“01”标记法的标注过程示例如图2所示。此前考虑并尝试其他标注方法,如将首尾标记序列合为一个序列,又可分为2种方法:一种是将识别出的实体位置全部标“1”,其余位置全部标“0”;另一种则是将识别出的实体的首尾位置标“1”,其余位置标“0”。这2种方法无法解决单字实体的标注问题,使得单字实体难以被识别与表示。BIO标注方法需要标记出整个实体的全部信息,而“01”标注方法只需标记实体的首尾位置,有利于降低标注实体错误的概率,因此,本文采用“01”标注方法对实体位置进行标注。

图2 “01”标注与BIO 标注示例Fig.2 Example of‘01’annotation and BIO annotation
其次,对输入文本中的字向量Ci与每个字所对应的位置向量Pi进行拼接得到文本的向量表示Ti,在Ti组成的输入序列的相应位置加入CLS 与SEP 标记并以此序列作为模型输入,其中:i表示字在句中的位置;n为文本长度。

经过BERT 模型的编码后,加入CRF 层用于得到实体标签预测,使用CRF 对整个序列进行全局归一化处理,得到概率最大的最优序列作为最终结果。
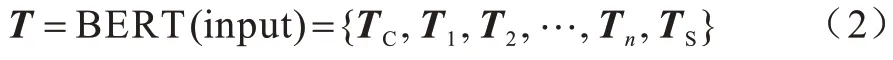
输入序列为X=(x1,x2,…,xn),输出序列为Y=(y1,y2,…,yn),对输出序列Y中所有的标签序列的概率通过softmax 计算。解码时使用argmax 函数对输出序列的结果进行预测,以Yx表示输入序列X的所有标注结果的序列集合。

实体识别结果中存在特殊符号以及错别字,造成识别出的实体与知识库中实体无法匹配,从而导致候选实体集中实体缺失。因此,本文引入容错机制(Fault Tolerance Mechanism,FTM),将识别出的实体与数据预处理时构建的id_entity 字典中的实体进行比对,当识别出的实体与字典中实体只有f个字符不同时,将两者认为是同一实体,并作为候选实体加入待消歧序列中。容错机制可以避免因错别字或某些语言差异导致的实体中某个字的不匹配而影响实体消歧的效果,但也会为实体消歧增加不少的时间成本。
2.2 实体消歧
本文采用管道模型来处理整个实体链接任务,为能利用实体识别以及实体消歧2 子任务的内在关系,通过共享参数的方法进行联合学习。本文将实体消歧任务直接看作一个对文本中实体与知识库中实体的相关性排序问题,选择使用BERT 模型来对文本进行编码。考虑到待消歧文本的长度较短,所包含的供支撑上下文信息的内容也大幅减少,将候选实体的知识三元组中的所有属性(predicate)与属性值(object)进行拼接,构成该实体的一条知识描述文本,并使用知识描述文本与待消歧文本拼接后作为模型的输入序列,以丰富词语的向量表示,也为后续的消歧工作提供更多的上下文信息。此外,经统计得出知识描述文本的长度总体偏长。因此,考虑时间复杂度对大量过长的文本进行处理,对过长文本进行截断,其中截断阈值根据对知识描述文本的长度统计设为42 个字符,对文本长度大于42 个字符的文本按比例截断。
文本拼接操作使得原来的短文本的长度大幅增加,而文本过长会使模型在训练过程中带来长距离依赖的问题,又考虑到模型训练与预测的效率,因此,在模型表示层之后加入局部注意力机制,旨在对实体的邻近上下文信息重点关注,强化实体邻近信息,减弱较远无关信息的影响,进而提升链接的准确率。实体消歧模型架构如图3 所示。

图3 实体消歧模型架构Fig.3 Framework of entity disambiguation model
根据识别出的实体的位置信息,将实体的隐状态拼接作为实体的向量表示Tv,同时对序列中对应的隐状态进行局部注意力机制计算得到Av。

其中:a和b分别表示该实体在句中的首尾位置;j表示滑动窗口区间内字符所对应的位置。取CLS 位置的向量表示、候选实体的向量表示以及实体的局部注意力计算后的向量表示进行拼接得到Cv,在全连接层利用Sigmoid 激活函数得到候选实体的概率得分,最终对所有候选实体的概率得分进行排序,选择概率得分最高的实体作为正确链接实体。
3 实验与结果分析
3.1 数据集
使用CCKS2019 和CCKS2020 数据集作为实验对本文象对模型进行评估。CCKS2019 数据集适用于实体识别与实体消歧模型,而CCKS2020 数据集则适用于短文本场景下的多歧义实体消歧研究,可通过对数据集的相关操作,使其也适用于实体识别与实体消歧模型。2 个数据集中的文本内容主要来源于搜索Query、微博、新闻标题、视频标题、文章标题、用户对话内容等,主要特征是文本长度都较短,待链接文本的平均长度分别为25.7 个和39.8 个字符。CCKS2020 数据集中增加了多模任务场景下的文本源,同时调整了多歧义实体比例,大幅提升了实体消歧的难度。CCKS2019 数据集中包含90 000 条标注数据,本文随机抽取生成70 000 条训练集、10 000 条验证集以及10 000 条测试集,知识库中包含39 925 条实体知识信息;CCKS2020 数据集中包含70 000 条训练集、10 000 条验证集以及10 000 条测试集,知识库中包含324 418 条实体知识信息。
3.2 数据预处理
本文任务是文本与知识库中实体的链接,笔者通过对数据集中文本的分析发现,源自文本与知识库的同名实体由于其中存在的某些特殊符号(如标点符号、英文字母的大小写等)或者错别字而无法匹配,最终会对实体消歧的结果产生影响。因此,先对文本以及知识库中实体中包含的特殊符号进行标准化处理。
为方便实体消歧对实体识别结果的利用,根据数据集中的信息创建4 个字典,分别是id_text(知识库中实体的id 与该实体的描述文本)、id_entity_type(知识库中实体的id、实体名与实体类型)、id_entity(知识库中实体id 与实体名)和entity_id(知识库中实体名与对应的实体id)。
3.3 参数设置
为避免错误传递带来的影响,在进行实体识别与实体消歧的训练过程中使用相同的超参数设置。模型中的表示层使用预训练语言模型BERT 模型对文本进行编码,在训练过程中实体识别与实体消歧使用9 折交叉验证法,并用生成的模型进行预测,最终对实体的结果以及链接的结果进行投票选择。在模型中设置初始学习率为0.000 1,学习率缩减步长为0.000 5,dropout 为0.3,局部注意力层中的窗口大小为7,容错度为1。
3.4 评价指标
本文的实体识别及实体消歧模型均使用准确率P、召回率R和F1 值F1作为评价指标。具体计算方法如下:

其中:CT表示模型得出的正确结果的总量;PT表示模型得出的所有结果的总量;DT表示数据集中的数据的总量。
3.5 结果分析
在CCKS2019 和CCKS2020 数据集上各方法的实体识别结果如表1 所示,主要包括使用BIO 标注方法以及“01”标注方法的实体识别的结果、模型在不同数据集上的效果以及模型在相同参数设置下完成一轮训练的平均耗时。

表1 实体识别结果Table 1 Entity recognition results
表1 所示的实验结果表明:
1)BIO 标注与“01”标注所最终识别出的实体结果相近,而“01”标注对较长实体的识别率更高,这是由于“01”标注只标注实体的首尾位置,比起BIO 需要对整个实体进行标注,标注过程中出错的概率更大,也就导致其对较长实体的识别效果较差,相反“01”标注只判断某一位置是否为实体的首尾位置,这样判断错误的概率就相对减小。
2)在相同的训练参数设置下,无论在哪个数据集下,“01”标注方法的训练时长都较BIO 标注方法的训练时长明显缩短,这也验证了“01”标注在模型训练时的高效性。
3)在2 个数据集中,使用“01”标注方法的实体识别的准确率都比BIO 标注方法的准确率要高,说明“01”标注方法识别出的实体更加准确;而使用BIO 标注的实体识别的召回率都比“01”标注的召回率高,说明BIO 标注方法能识别出的实体数量更多。但对比F1 值则得出,BIO 标注虽然识别出的实体数量较“01”标注得多,但准确率却偏低,因此,“01”标注方法的总体效果优于BIO 标注方法。
4)通过对相同标记方法下不同数据集的对比也发现,CCKS2020 中实体识别出的结果较CCKS2019 的结果更好,造成这一结果的原因是CCKS2020 数据集中的错别字较少,并且数据更加规范且特殊符号相对统一。
5)对比2 个数据集平均耗时可知,由于CCKS2020数据量比CCKS2019 的数据量大,因此CCKS2020 的数据集在一轮训练中耗时较长。
本文方法实体识别的结果在目前方法的实体识别结果中并不算突出,主要原因是其并未在实体识别部分加入过于复杂的方法,而是更注重实体识别模型的效率。此外,数据集中的实体定义不够明确,标注结果很大程度上依赖于标注人员的主观性,并且数据集中有较多的错别字、简写以及符号书写不统一等问题,都限制了最终的识别效果。
实体消歧模型在不同滑动窗口下的实验结果如表2 所示。为了确定适当的滑动窗口参数,在消歧模型中对不同大小的滑动窗口进行实验对比,结果表明:当滑动窗口大小为7 时,模型在CCKS2019 数据集中的F1 值最大,而在CCKS2020 数据集中滑动窗口为9 时F1 值最大。在实体识别完成后,对实体的长度进行统计,发现识别出的实体的平均长度为4.76,结合不同的滑动窗口实验结果,考虑到运行效率,最终滑动窗口设为7 个字符。
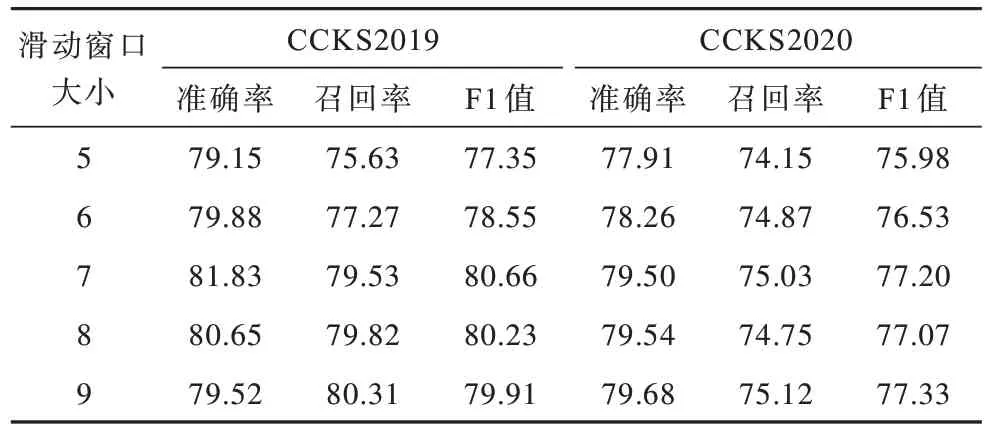
表2 消岐模型在不同滑动窗口下的实验结果Table 2 Experimental results of disambiguation model under different sliding windows %
实体消歧模型中不同容错度下的实验结果如表3 所示,其中:BIO 与01 代表标注方法;LA 表示局部注意力机制;FTM 表示容错机制。由于错别字、特殊符号的不一致性,导致实体识别后的实体无法与知识库中的实体完全匹配,造成候选实体缺失。为解决这一问题,本文引入容错机制,并针对不同的容错度进行实验并对比。实验结果表明:当容错度设置为1 时模型的效果达到最佳,并且随着容错度增大使得候选实体集扩大,导致消歧模型运行时间过长。当容错度过大时,会使得候选实体过多,对消歧效率造成干扰,因此,1 个容错度能最大程度上扩充候选实体集又不加入过多的无关实体信息,有助于缓解无法匹配导致的实体缺失问题。

表3 消歧模型在不同容错度下的实验结果Table 3 Experimental results of disambiguation model under different fault tolerance %
实体消歧在CCKS2019 和CCKS2020 数据集上的实验结果如表4 所示,主要包括消歧模型在不同数据集中的效果、相同数据集下BIO 标注方法和“01”标注方法识别出的实体对消歧的影响,以及相同数据集下使用相同标注方法时加入局部注意力机制(LA)和容错机制(FTM)的效果。

表4 实体消歧结果Table 4 Entity disambiguation results %
由以上实验结果可以得到以下结论:
1)对比实验1 和4 与实验2 和5 可以发现,同在CCKS2019 数据集中,使用相同的消歧模型和不同的标注方法,“01”标注方法由于识别出的实体更准确,因此其消歧的结果优于使用BIO 标注方法识别出的实体进行消歧后的结果,同时还表明管道模型中上游任务的结果对下游任务结果有影响。
2)对比实验1 和2、实验5、6 和实验8、9 可以发现,在数据集相同且标注方法相同的条件下,加入局部注意力机制的效果明显优于未加入的效果,所有评价指标的提升都说明局部注意力机制的加入可使消歧结果得到明显提高,这主要因为注意力机制对长文本的处理能力以及局部上下文信息对文本语义理解的重要性,即能强化邻近文本信息的语义关联,弱化无关信息带来的噪声干扰。
3)实验4、7、实验5、8 和实验6、9 的结果验证了相同方法在不同数据集中消歧模型的有效性,此外也再次表明了局部注意力机制对文本语义理解的重要性。
4)对比实验2、3、实验5、6 和实验8、9 发现,加入容错机制确实使得模型的召回率得到较明显提升,最终结果也有提升,这也证明数据集中的特殊符号以及错别字等无法匹配的问题较严重,解决这一问题能对最终结果带来不小的提升,从而验证了加入容错机制的有效性。
5)CCKS2020 的效果提升没有CCKS2019 的结果明显,这是因为CCKS2020 数据集更加规范严谨。
4 结束语
本文面向中文短文本构建一个基于局部注意力机制的实体链接模型,并在CCKS2019 和CCKS2020数据集上进行验证。实验结果表明,局部注意力机制有助于在实体消歧过程中强化实体上下文信息和减弱无关字词的干扰,并能提升链接的效果,也说明了局部上下文信息对语义理解与辨析的重要性。此外,“01”标注方法较BIO 标注方法对实体位置的标注有助于提升模型的运行速度。后续将在其他公开的实体链接数据集上验证本文模型的有效性,同时优化实体识别与实体消歧的方法,进一步提高中文短文本实体链接的准确率。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
计算机与数字工程(2021年12期)2022-01-15
哈尔滨工程大学学报(2020年8期)2020-11-13
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
传媒评论(2017年3期)2017-06-13
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
第二课堂(课外活动版)(2016年2期)2016-10-21
中文信息学报(2014年1期)2014-02-27
