
基于神经网络和模式识别的中长期风速及发电量预测
2021-11-18 07:05:26李建林张海军庞俊强
环境技术 2021年5期
李建林,张海军,庞俊强
(国华(河北)新能源有限公司, 张家口 07500)
引言
大力发展可再生能源,增加可再生能源发电量是实现能源安全和环境保护可持续发展的根本途径。2020年全国风电新能装机达到111 GW,伴随着国家3060任务目标的提出,“十四五”期间风电装机规模将进一步提升,预计到2030年风电装机容量达12亿千瓦时,2050年达24亿千瓦时[1]。电力系统新能源接入进入中高比例后,系统在稳定控制、运行、规划等不同时间尺度将面临多重挑战,准确预报风电场的送出功率对于高比例可再生能源的电力系统经济调度和安全运行具有重要意义[2]。因此,在多尺度上提供高精度的风速及功率预测方法是必需的。由于风力发电机的输出功率与风速的立方成正比,准确估计风力发电机的输出功率至关重要。近年来,许多研究文献提出了功率预测模型,以期在实际应用中找到一种有效的方法。这些模型大多依赖于复杂的统计和人工智能技术,以及大量的气象和地形数据[3]。理想情况下,这些方法能够将能源系统内的故障风险降至最低,并通过建模或模拟未来情景来预测其可靠性。但是,其可靠性取决于所用预测技术的准确性,目前这一领域的研究和开发工作仍在继续。
风速预测是一项非常复杂的任务,因为精度与不断增加的预测时间帧之间存在负相关,风速时间序列数据的混沌特性导致预测精度在很大程度上依赖于时间间隔。根据气象资料和应用的时间尺度,文献[4-6]总结了多种风及功率预测方法,风速预测一般分为短期、中期和长期预测三类。风速预测模型常规包含物理方法、统计方法、人工智能方法和混合方法。物理方法由一些基于物理的方程组成,将某一时刻的气象数据转换为某一地点的预报风速,是一种有效的长期预测方法[7]。统计方法是一种基于模式的短期预测技术,其多利用曲线拟合等参数设计风速预测模型,然后将近期实际数据与预测数据进行比较,对设计模型进行修正[8]。然而,统计方法不能单独用于长期预测。相反,其他方法,如数值天气预报、人工智能技术和混合方法,应予以考虑。人工智能方法也是预测风速数据的一种有效方法,优点是不需要任何预定义的数学模型就可以预测未来的时间序列数据,当满足相同或相似的模式时,可以达到最小的错误概率,缺点是随着时间范围扩大,精确度显著下降[9]。近年来人工神经网络作为一种非线性系统的预测和函数逼近方法得到了广泛的应用[10-15],由于其处理噪声和不完全数据的能力,许多研究人员将人工神经网络应用于不同时间尺度的气候变量时间序列预测,结果表明预测效果优于传统方法,一经训练,可以以更高的速度执行预测任务[16]。混合方法在预测过程中使用一种或多种模型,以获得最佳的预测性能并可减小误差,与其他方法相比,混合方法看起来更准确,常被用来预测未来一年的每小时风速。
本研究应用统计和神经网络组合方法,通过研究特定区域的风速特征以期找到风速变化的模式来预测下一年的每小时风速数据,长期预测区域内的平均小时风速及发电量。为了识别风速趋势,将一组识别子模式应用于月平均预测,将神经网络应用于与位置的识别模式相关联的时间序列数据,以优化预测。
1 风电场址风资源
使用河北省张家口地区张北某风电场数据和内蒙乌兰察布地区某风电场数据测试,两风电场差距约300 km。河北省风能资源丰富区主要分布在张家口、承德坝上地区和沿海秦皇岛、唐山、沧州地区。张家口地区10 m高年平均风速可达5.4~8 m/s,主风向为西北风,风能资源十分丰富。张北风电场安装33台1.5 MW风机,轮毂高度70 m,叶轮直径82 m,功率曲线如图1所示。乌兰察布风电场一期同样安装33台1.5 MW风机,叶轮直径87 m。图2为张北风电场2010~2020年间的70 m高度风资源数据,该图显示了月平均风行为和风速模式的季节性因素,通过研究风场的风速特征来预测下一年的风速走势,然后预测每小时风速,继而考虑电网等各种损失,预测风电场发电量。
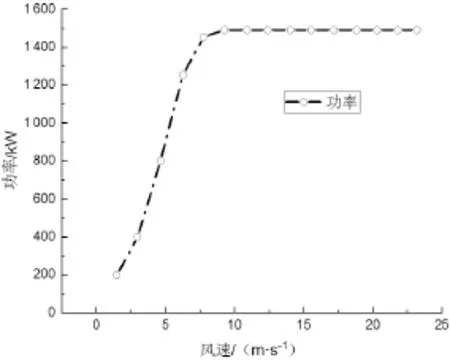
图1 功率曲线
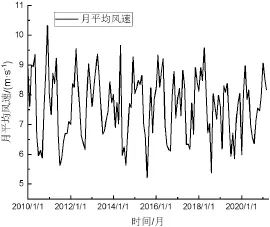
图2 场址多年风资源
2 理论方法
2.1 预测误差指标
对误差进行综合评价是风速及风电功率预测理论研究的一项重要内容。评价指标能够从各方面反映预测算法的运行情况,本文选取平均绝对误差来评价模型性能。平均绝对误差是绝对误差的平均值(MAE-mean absolute error)。它被用作衡量预测误差的常用指标。

式中:
N—数据个数;
Pf—预测值;
Pa—实际值。
2.2 人工神经网络模型的设计
模型预测流程如图3所示,主要是通过研究特定区域的风速特征并找到风速变化的模式来预测下一年的每小时风速数据,继而预测发电量。上一年的总体趋势作为输入,实际小时数为目标,以训练网络并更新神经网络中神经元的权重,然后使用神经网络模拟预测数据。模型详细预测过程如下:
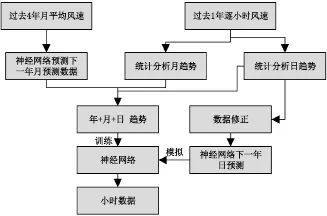
图3 模型设计过程
步骤1:年风速预测。使用ANN网络架构预测下一年月平均风速。通过存储获得的输出值作为反馈和输入来预测序列。预测流程如图4所示。本研究中的模型以过去10年(2010~2020年)的月平均月风速数据为训练网络(4年为输入,2年为延迟,4年为目标),输出预测未来4年的月平均风速。为了找到最佳的预测,对结果进行检验,如果过去3年的误差小于0.6 m/s,则接受第4年的预测值;否则,将重复训练,直到达到预期输出。图5为年预测风速与实际数据的对比。
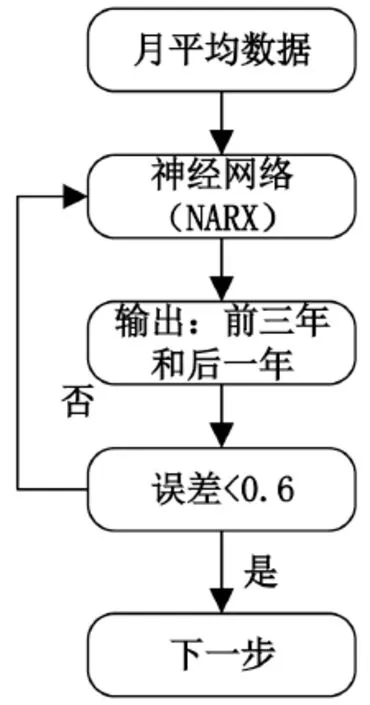
图4 年度风速预测
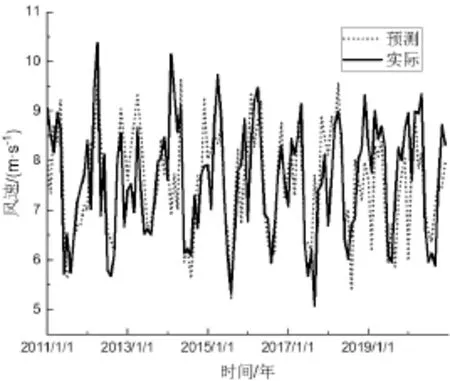
图5 预测风速与实际数据
步骤2:月风速预测。由于风速模式可能与上一年的风速有很大的差异,统计方法无法帮助发现或预测风速模式。由图6月平均速度曲线可以发现每个月风速存在周期性特征。鉴于模式存在一定的周期性变化,因此可以应用神经网络对每个月的模式进行预测。图7是两种网络架构示意图,具体根据预测结果精度选择使用,本例中,选用两个前馈反向传播网络来预测每月的风速形态,两层分别有7个和16个神经元。选择之前需要测试训练数据集数量对ANN预测结果精度的影响。用于训练模型的数据越多,获得的准确度就越高。两层网络情况下,第一个网络利用上一年前6个月的平均风速值训练后预测下一年前6个月的平均风速值,同理,第二个网络利用上一年后6个月的平均风速值训练后预测下一年后6个月的平均风速值示。仅单层网络时,与其他训练数据集(一个月数据、两个月数据等)相比,十一个月的数据给出了更准确的预测。
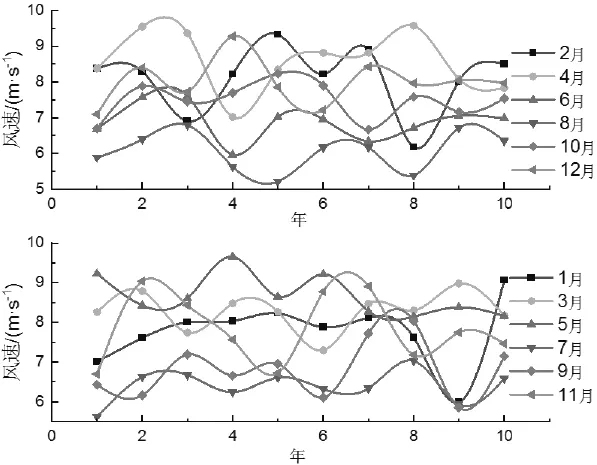
图6 每月风速特征
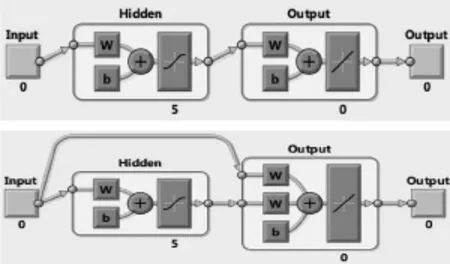
图7 ANN神经网络的架构(级联和反馈)
研究过程中同时需要观察特征设计的效果以及隐藏层和隐藏神经元的数量,并找出哪种模式的准确率最高。测试流程与训练数据量测试流程相同,使用经过测试的最佳数据集数量,本次使用11个月数据集合,不同的是在第二步中每个模型创建不同的 ANN 层架构,设置多种 层 架 构(Layer_5_5,Layer_5_5_5,Layer_5_5_5_5,L a y e r_5_5_5_5_5,L a y e r_1 0_1 0_1 0_1 0_1 0,Layer_20_20,Layer_20_20_20,Layer_20_20_20_20,Layer_20_20_20_20_20等),然后使用训练数据集训练所有 ANN 模型,最后使用经过训练的 ANN 模型的输出作为能量估算应用程序的输入来获得预测的发电量。对于给定的模式,ANN 层架构越复杂,结果就越好。对于三种模式,与其余层(layer_5、layer_10、Layer_20 等)相比,layer 20_20_20_20_20 显示出更好的结果。模式 3与layer_20_20_20_20_20组合对四个变量(风速、温度、风向和功率)的预测吻合度最高,同时也说明输入特征设计的复杂性越多,ANN 模型的准确性就越高。
图8 为网络训练回归结果,通常,经过更多次训练后,误差会减少,但随着网络开始过度拟合训练数据,验证数据集上的误差可能会开始增加,训练在验证错误连续6 次增加后停止,最佳性能取自验证错误最低的时期。
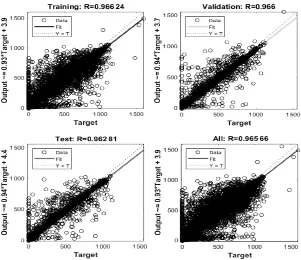
图8 网络训练回归结果
为了更好地预测,需要对数据进行一些修改。在本研究中,训练网络之前使用了两种数据修正方法。研究表明,在时间序列数据中,当满足相同或相似的模式时,可以实现最小的错误概率[14]。因此,将下半年的数据颠倒,用于训练和模拟的网络输入将变得几乎相似,降低错误概率。样本关联函数可以识别神经网络中输入和目标之间的偏移量,使时间序列更加对称。通过对不同时间段的数据迁移和不同神经网络的测试,发现该方法与镜像函数(逆函数)相结合,可使时间序列数据的误差降低50 %。训练中时间序列数据移动约1个月,使时间序列数据对称1年,在训练和模拟之后,将原点移回原始位置。
步骤3:每日风速预测。从上一年的每小时风速数据中提取每日风速模式,如图9所示。利用往年的气象资料计算出每天每小时的平均小时风速。然后,使用等式(2)对数据集进行归一化处理。式中,Vh,p计算每小时风速,Va为平均小时风速,Vh为逐小时风速。
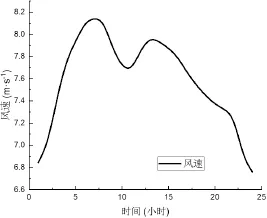
图9 每月风速特征

步骤4:模式识别。如图10所示,一整年的一般趋势是使用以上1~3步骤识别,用于从上一年每小时的风速数据中提取日风速的一般趋势特征。
图10 趋势识别流程
步骤5:每小时风速预测。如图11所示,将去年的每小时的实际数据用作输入和目标来训练网络并更新神经元的权重。
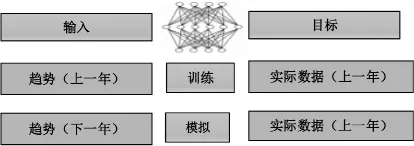
图11 日风速预测
3 案例分析
使用张北地区某风电场和乌兰察布某风电场数据进行测试,并与前馈,时延,分层递归和非线性自回归神经网络进行了比较。使用MAE作为不确定性度量指标评估模型性能。通过使用带有外部输入的非线性自回归网络来预测年风速,使用两层前馈反向传播网络(中间层和输出层具有8和30个神经元)预测风速的月度模式。
对于长期预测,前馈反向传播网络的性能要优于时间序列神经网络[17]。从过去的数据中提取风速的每日模式,两层前馈反向传播网络分别具有30和12个神经元,使用6~8年的平均每月风速数据和仅1年的每小时数据来开发和优化神经网络。对于MAE,本测试获得的最佳配置精度约为0.6~0.8 m/s。
测试结果同时与文献[18]中开发的几种风速预测方法进行了比较。前馈网络可以使用隐藏层中的神经元来拟合输入和输出,具有外部输入的非线性自回归神经网络是一种递归动态网络,使用输出作为输入的反馈[19]。循环层网络在除最后一层之外的每层均具有一个单个延迟的反馈环路,该环路可用于建模和过滤应用程序,可以用于长期风速预测[20]。
隐藏神经单元数据采用反复实验法确定,由少到多,逐渐增加到26个神经元,同时训练网络,直到达到最低的误差。经测试,本次前馈网络的最佳神经元数在输入层和隐藏层分别为5和9,时间延迟和自回归网络则为11。由表1可以看出,与其他预测方法比较,本方法的最小绝对误差最小,说明通过该方法可以获得较好的预测结果。但同时,该方法有一定的局限性,根据获得的数据,风速变化与相关性误差增加之间存在正相关,仍然需要继续改进以提高预测的准确性。
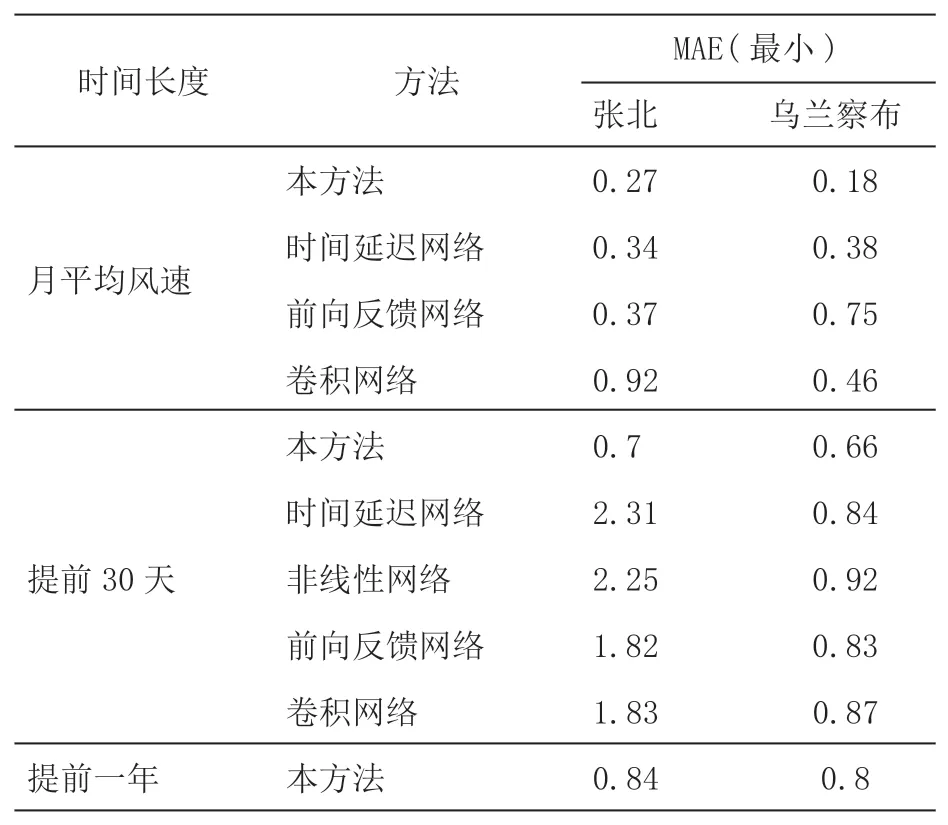
表1 平均绝对误差结果
图12 是风速预测值与实际值比较曲线,大部分误差在0.5 m/s之内。神经网络得出的性能在不同的运行情况下会略有不同,张北风电场的平均每月风速的MAE结果约为0.27~0.37 m/s,内蒙风电场的平均每月风速的MAE结果约为0.18~0.34 m/s,表明与现有工程相比有所改善。两个场址皆超过50 %的估计值显示误差小于1 m/s,但是在某些情况下,两风电场的最大误差接近2 m/s,这不是我们希望看到的,并且会严重影响风电功率的预测。为了尽可能的避免此类错误,使用目标年份相近的预测风速值与实际风速值之间的差值来定期更新预测模型,以提高长期时间序列预测的准确性,目前正在研究测试中。
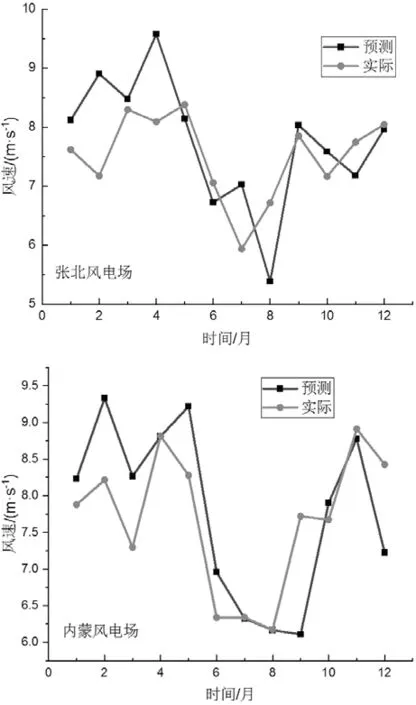
图12 典型月风速预测曲线和实际曲线对比
图13 显示了风电场发电量功率预测,如图所示,预测值与有功功率的吻合趋与风速预测相似,说明模型提供了有效的预测能力。功率预测基本流程:首先将数据集划分为多月组合的训练数据集合和单月的对比测试数据集,其次使用 ANN 预测应用程序创建 ANN 模型,继而使用相同的 ANN 层架构训练创建ANN 模型,使用经过训练的 ANN 模型为测试数据集创建预测,最后使用经过训练的 ANN 模型的预测输出作为能量估算应用程序的输入来获得预测的发电量。能量估算需要考虑电网、风电场、设备等过程中能量损失,模型中嵌入相应损失因子,包括欧姆损耗、变压器损耗、尾迹损耗、地形特征摩擦系数等,其中尾流损耗使用Jensen Wake模型,考虑风机间布置及距离,为便于比较,两风电场能量估算使用相同的损失系数。由图可以看出,超过50 %的预测误差在10 %以内,乌兰察布风电场超过70 %误差在10 %以内,乌兰察布风电场2~4月预测趋势与风速趋势相比存在不一致,主要考虑风电场的风向因素,其中可能存在设备利用率问题导致数据有误,需要进一步排查。鉴于风速预测使用的是风电场中测风塔单点数据,而风电场功率或发电量预测需要综合考虑风电场地形、风电机组间的排布、设备等众多因素,后续需要建立更为全面的预测模型,提高模型预测精度。同时,研究中 发现训练样本参数多少和周期对预测精度影响较大,需要更多的数据训练以寻找建立工程可用的通用数据标准范围,及开发基于神经网络的时间序列预测模型及通用预测平台。
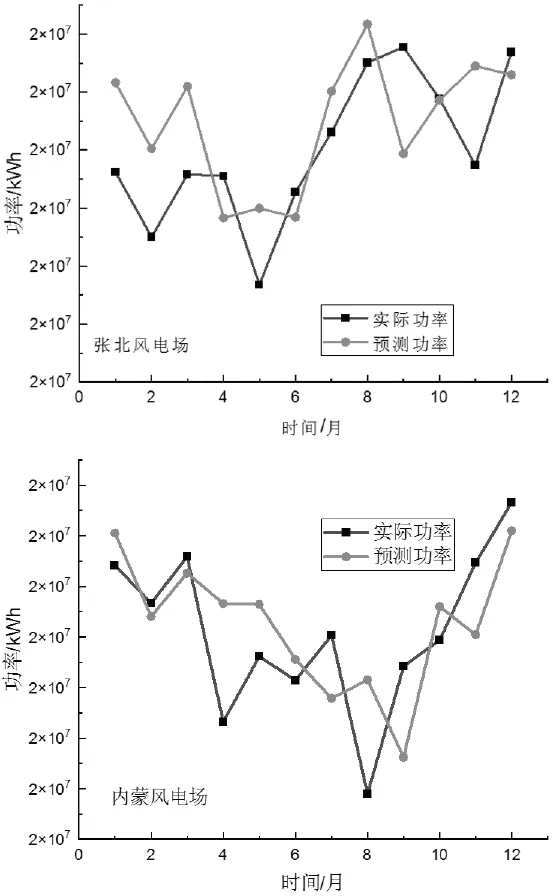
图13 典型风电场发电量预测曲线和实际曲线对比
4 结论
基于统计方法和神经网络方法,通过设计一个多神经网络的数据融合算法识别过去的风速特征来预测下一年的每小时风速及发电量。为了确定来年的风速趋势,识别数据模式特征并将其相应地应用于年/月/日平均风速预测,同时将时间序列数据应用于与位置识别模式相关联的神经网络,以订正预测。利用张北和乌兰察布地区某风电场的风速及功率测量样本对数据集进行训练和测试,结果显示平均绝对误差(MAE)很小,预测效果较好。研究结果表明,风速及功率预测值与实际值比较趋势较一致,所采用的模型方法提升了长期风速及功率预测结果,说明混合技术可以很好的预测实际的数据序列,鉴于其较好的预测了整体趋势,可以用于长期风速预测任务的替代模型,后评估预测结果可作为中长期发电量预测的依据,未来可以进一步结合气象数据建立中长期电量预测模型,为风电中长期交易提供参考及风电场制定检修计划提供辅助决策。
猜你喜欢
电机与控制应用(2021年12期)2021-02-28 07:55:52
海洋通报(2020年5期)2021-01-14 09:26:54
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2018年17期)2018-09-28 01:56:44
西南交通大学学报(2016年4期)2016-06-15 20:29:37
通信电源技术(2016年4期)2016-04-04 02:57:38
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
电网与清洁能源(2015年3期)2015-02-28 16:03:31
海军航空大学学报(2015年4期)2015-02-27 13:45:47
