
对等网络环境下多目标任务容错调度方法研究
2021-11-17 07:18秦轶翚
计算机仿真 2021年8期
秦轶翚,马 涛
(北京联合大学,北京 100011)
1 引言
容错技术在安全系统中具有较为重要的地位,会直接影响网络系统的可靠性,而容错调度方法可以将多目标任务划分为多个版本来实现目标容错调度,这是目前比较流行的容错方法。有效的容错调度可以最大程度地提升网络系统性能,使其具有灵活性、可靠性与可调度性等优点。但是研究表明,对等网络环境下多目标任务容错调度方法是一种NP(非确定性完全问题),即在对等网络环境下对任务调度是没有最优线性时间的复杂调度方法,因此在现实应用中,通常会利用接近最优方法来完成这类调度问题。但由于处理器数量的实时变换,网络系统内会随时出现一些故障,这些故障不仅是硬件故障,还包括软件故障,而任务在任何情况下都要在其时限到达前完成,因此,需要为对等网络环境提供一种存在容错能力的任务调度方法。
针对上述问题,本文通过PB(软件容错)方法划分任务的主、副版本,使后期的任务分配能够更加清晰、安全,随后通过拟定任务模型与故障模型,来确定时限与任务开始的时间,最后依靠自适应策略拟定启发式多目标任务容错分配策略,对对等网络环境下的多目标任务进行容错调度。
2 对等网络环境下多目标任务容错调度
2.1 任务模型构建
对等网络环境是通过多种有限带宽网络经过处理器互连组成的,其需要多种控制回路一起运行,每一种控制回路都会以固定频率输出,能够实现很多功能,例如空集运算、数据收集或控制输出等。这些功能之间都存在一定的关联,也相互干扰,因此,可以将一种控制回路描述成一个回路任务,为了实现对等网络的多种控制功能,就需要使用多种不同类型的处理器进行任务调度,对等网络系统描述如下所示:
1)一种对等网络系统能够表示成一种处理器的集合
Ω={Pr1,Pr2,…,PrM}(M≥2)
(1)
由于系统中[1]处理器类型不同,同种任务在不同处理器中的运行时间也各不相同,因此,需要引入运行时间向量
τiC={τiC(1),τiC(2),…,τiC(M)}
(2)
其中,τiC为τi在Prj内的运行时间。
2)处理器Prj的工作能力系数表明同种任务在处理器Prj中的运行速度,运算结果如下式所示
(3)
其中,τi·C(nor)与τi·C(Prj)分别代表τi在普通处理器内的运行时间与在Prj内的运行时间,普通处理器即在每一种处理器内挑选一种处理器进行处理,挑选出的处理器其处理效率被拟定成1。
使用PB方法进行容错处理[2],每一种任务都需要拥有各自独立的主、副版本,同时这些版本会分配到不同的处理器内运行,因为系统故障出现的概率较小,一般都是先运行主版本[3],所以任务主版本就起到了决定系统控制性能的作用。通过IC方式对任务主版本进行处理,任务主版本能够完成很多功能,例如精准度控制运算、更新显示、数据收集、输出控制或优化等,其存在运行时间长和结构复杂的特性,任务副版本只需要完成一些必要的功能,例如控制运算、数据收集或[4]输出控制等,其有着运行时间短和架构简单的特性。
3)对等网络系统内的任务集是S={τ1,τ2,…,τN}(N≥2),τi代表第i个回路任务,将其描述成一种四元组:
τi=(T,d,tp,tb)
(4)
其中,T代表收集样本的周期;d代表任务的时间限制;tp代表主版本;tb代表副版本。tp与tb能够表示成三元组即
tp=tb(C,A,Pr)
(5)
其中,C与A分别代表相应版本的运行时间和所在处理器的运行时间。设定τi·tp·C(Prj)与τi·tb·C(Prj)分别代表τi的主版本与副版本在Prj内的运行时间,由于τi·tp的结构较为复杂且运行时间较长,因此更容易产生软件故障[5],而τi·tb结构简单且运行时间较短,因此拟定其能正确运行任务。本文主要针对对等网络环境,将系统的样本收集周期控制在一定的取值范围,将满足系统控制要求的最大采样周期表示为Tmax。
实际上,每一种控制回路之间不会出现孤立问题[6],但为了实现先进控制,需要在控制回路之间添加优点约束,比如串级系统的外回路需要在内回路运行之前实现,所以就需要添加有限关联矩阵[7]R=(ri,j)N×N,其中,ri,j代表τi与τj之间存在的优先约束关联,τi,j的取值为1或0,如果τi需要在τj开始之前完成,则ri,j=1,反之ri,j=0。
4)一般情况下,处理器的控制平均值是通过主版本所在处理器的运行时间与总时间的平均值选取的,其计算方式如下式所示
(6)
拟定的调度方法基于以下假设:拟定对等网络环境内处理器总量与[8]回路任务的总量是固定的;设定回路任务的周期和时限是同等的。
2.2 故障模型构建
对等网络内处理器都可能产生故障,同时由于系统的漏洞,每一种任务也都可能出现运行失败的问题,所以本文在处理容错问题之前,先构建故障模型,提升任务调度的成功率。
1)软件故障与硬件故障是不会同时出现的,即在某时刻,网络系统中只会产生一个处理器出现故障或一种软件出现故障,每一种处理器在某时刻最多会产生一种软件故障,在下一个故障出现之前,主版本运行失败的任务,都会使用它们的副版本成功运行[9]。
2)由于硬件冗余策略可以实现对永久硬件故障的容错,所以设定硬件与软件的故障都存在一定的持续时间,这些故障只会影响到相应处理任务,每一种故障都是独立存在的。
3)处理器故障即fail-stop模式,能够描述成处理器的正常运行或故障运行状态。
4)一个处理器出现故障,这个故障能够被其它处理器检测,软件的故障也能够实时被处理器检测出来。
2.3 任务的主版本与副版本容错可调度条件
对等网络环境下任务调度需要先确定一种任务何时在哪一个处理器上运行。为了让系统也具有容错能力,所有实时任务都会拟定主版本与副版本,它们会分配到不同的处理器内,网络系统会先运行主版本,假如主版本正确运行,那么副版本就不需要运行,但如果主版本所处的处理器产生故障时,那么该任务在其它处理器内的副版本就会运行,实时任务与[10]调度方法应满足以下条件:
1)任务主版本与副版本运行时间的总和不能超过其时限,即:
max{τi·tp,C(j)+τitb·C(m)}
≤τi·P(j≠m),∀τi∈Sh
(7)
2)一个任务的主版本与副版本分配在不同的处理器内,同时它们的运行时间不可以重叠,即
{τi·tρ·Pr≠τi·tb·Pr}(τi·tρ·Tstart+τi·tρ·C(τi·tρ·Pr))≤τi·tb·Tstart,∀τi∈Sh
(8)
3)主版本的实现需要满足下式
τi·tρ·C(τi·tρ·Pr)≤τi·tρ·D
≤τi·P-τi·tb·C(τi·tb·Pr),∀τi∈Sh
(9)
为了使任务满足容错条件,通过拟定实时任务主版本与副版本不同的开始时间与时限方法[11],对于∀τi∈Sh,其主版本τhi·tp任务开始时间拟定成任务τhi的到达时间,其时限拟定成τhi·tp·D≤τhi·P-τhi·tb·C(τhi·tb·Pr)。通常来说,任务τhi在τhi·tp·D中完成,假如处理器τhi·tb·Pr出现故障,同时τhi·tp没有在其时限前完成,那么系统会通知处理器τhi·tb·Pr调度相应的副版本。针对任务的副版本,拟定其开始运行的时间为处理器τhi·tb·Pr被通知调度τhi·tp的时间,同时其时限拟定成τhi·P-τhi·tp·D,这能够确保τhi在其时限之前完成。假如主版本运行正确,那么通知处理器τhi·tb·Pr取消对τhi·tp的调度。
针对上述构建的任务模型,拟定每一种实时任务的主版本和任务时限的比例是同等的,即
τhi·tp·D=Δτhi·d=τhi·P
(10)
其中,Δ代表一种常数,0<Δ<1,则存在
τhi·tp·D=τhi·d-τhi·tb·D=(1-Δ)τhi·P
(11)
基于上式,可以得到任务集Sh与Ss在处理器集Ω内容错可调度的充分条件。
2.4 多目标任务的容错调度算法实现
多目标任务容错调度即NP难题,一般会通过启发式方法对其进行解次优解,本文使用自适应策略构建多目标任务容错调度策略,调度的原则即:任务调度到该任务完成最早的处理器中,并将同一多目标任务的主、副版本分配到不同的处理器内。
估算任务在处理器上需要消耗的时间,具体分成两种情况:
1)针对τi·tp,假如rk,i=0(k=1,…,n且k≠i),其在处理器Prj内的完成时间通过式(12)进行运算
τi·tp·F(Prj)=τi·F(Prj)+τi·tp·C(Prj)
(12)
其中,τi代表分配至Prj内,同时在调度序列内位于τi·tp前方的任务;τi·F(Prj)代表τi在Prj内完成的时间。假如rk,i=1(k=1,…,n且k≠i),那么其在Prj内完成的时间通过式(13)进行计算。
τi·tρ·F(Prj)=t+τi·tρ·C(Prj),t
=max{τi·F(Prj),τk·tρ·F(Prj)}
(13)
2)针对τi·tρ,在Prj内完成的时间通过式(14)进行计算。
τi·tρ·F(Prj)=t+τi·tb·C(Prj),t
=max{τl·F(Prj),τk·tρ·F(Prj)}
(14)
其中,τl代表在Prj内,且在调度序列中处于τi·tρ前方的最后一个任务。
多目标任务容错分配:
1)设定任务的固定数量,每一个任务的主、副版本在正常处理器中运行的时间,处理器数量,每一个处理器的运行效率系数,设定任务调度的序列。
2)使k=1。
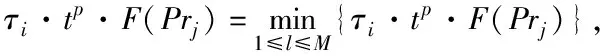
4)如果k=2N,使k=k+1,同时迭代(3)、(4),反之结束。
如果R≤Tmax,那么多目标任务的所有版本都可以在Tmax运行之前完成,而回路任务的周期与时限是相同的,所以回路任务的主、副版本都能够在时限结束之前完成运行,因此任务是可调度可容错的。
3 仿真研究
为了证明本文方法的实用性,拟定仿真来测试本文方法的性能。
3.1 实验环境
本文使用CloudSim模拟对等网络,所有网络主机存在一个CPU,为了体现处理能力的异构性,参数能够分成1000、1500或2000MIPS。所有对等网络都安装一个性能为200、300或400MIPS的核心。本文拟定对等网络开始运行与创造一个虚拟对等网络的时间分别是:90s与15s。实验内存在10000个多目标任务到达对等网络内,拟定其到达服从平均间隔的时间是1/λ的泊松分布,1/λ代表[1/λ0,1/λ0+2]之间的均衡分布。任务的运算量在1×105,2×105范围内均匀分布。截止期是di=ai+deadlineTime,deadlineTime服从均匀分布,U(baseDeadline,4baseDeadline)。
3.2 实验结果分析
通过一组实验来表明节点数对本文方法的影响,实验结果如图1所示。

图1 不同节点数量下的任务调度成功率
通过图1能够看出,在节点数量增加之后,本文方法的调度成功率会随之升高,这是因为,在节点总量上升之后,对等网络的运行能力也会逐渐上升,其会添加更多的节点,这些节点可以存储更多的回路任务,从图1还能够看出,除了节点为4的这种低资源情况外,普遍调度成功率都是随着每一节点数量增加而迅速上升,这是因为本文方法能够通过降低任务的等级来提升任务调度的成功率。
通过一组实验来表明节点数对本文方法性能的影响,实验结果如图2所示。
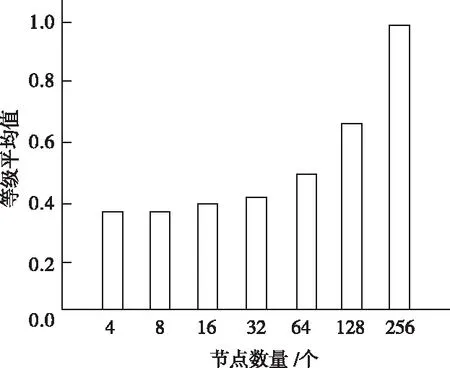
图2 不同节点数量下任务等级平均值
通过图2能够看出,在节点总量较低的情况下,本文方法会降低多目标任务的处理等级,这是因为在节点总量较低时,系统会出现负载过重的问题,这时方法就会通过降低任务级别来提高任务的调度成功率,而在节点总量逐渐上升之后,也会逐渐提升多目标任务的等级,这就证明节点数量增加之后,系统的处理能力也会随之增强,为任务提供更高的处理级别,因此得出结论,本文方法具有很强的自适应性,不会因为节点数量较低,而出现停滞运行的问题。
4 结论
为了使任务调度不被系统故障所影响,本文提出对等网络环境下多目标任务容错调度方法,通过拟定启发式多目标任务容错分配策略对任务进行容错调度。但是本文方法存在一定的针对性,只能单一地针对任务容错进行调度,虽然能够顺利完成调度任务,但也增加了调度过程的计算量,因此下一步需要研究的课题为:在本文方法的基础上添加故障检测系统,依靠检测系统提前获取精确的故障区域同时进行处理,从而节省大量的任务调度时间与计算量。
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
吉林大学学报(信息科学版)(2022年2期)2022-08-15
北京航空航天大学学报(2022年5期)2022-06-06
南方农业·下旬(2022年4期)2022-05-24
计算机测量与控制(2022年2期)2022-03-30
家庭影院技术(2021年6期)2021-07-28
北京航空航天大学学报(2021年6期)2021-07-20
科技与管理(2014年5期)2015-01-06
计算技术与自动化(2014年1期)2014-12-12
微型计算机(2009年17期)2009-05-19
