
基于改进rcnn模型的多标签短文本自适应分类
2021-11-17 08:37夏梓渊
计算机仿真 2021年5期
王 东,夏梓渊
(重庆理工大学计算机科学与工程学院,重庆 400054;)
1 引言
电子商务以及社交网络的迅猛发展,促使人们网络生活的形式日益多样化,越来越多的人们积极主动加入社交网络中,在网络中进行交流以及发表自己的评论[1-2],以上行为大幅度增加了互联网的数据量。现阶段互联网已经日益渗透到人们的生活以及工作中,为了传统的经济结构以及商业模式带来了全新的转机。互联网的开放性、匿名性等优势,促使越来越多的人愿意将身边发生的事情进行分享,并且在网络中查询自己感兴趣的信息[3-4],整个社交平台为人们的生活带来了极大的便利,同时也有效促进了各个企业的发展。
互联网技术的普及以及飞速发展,促使互联网络中的多标签文本分类变得越来越迫切。本文主要结合经过改进的rcnn模型,提出一种基于改进rcnn模型的多标签短文本自适应分类方法。仿真结果表明,所提方法能够有效提升分类结果的准确性,同时具有较强的实用性。
2 方法
2.1 多标签短文本特征提取
多标签短文本是一种非结构化信息,它本身是无法使用计算机进行直接处理的,所以需要将非结构化的数据转换为结构化的数据,促使计算机能够快速、有效的进行应用。
多标签短文本预处理是文本分类的开始,也是文本分类的必要阶段。
在多标签短文本经过预处理之后,原始的多标签短文本有效删除了的噪声信息,同时以词汇为单位进行文本表述。但是,由于计算机只能够接受二进制编码,其中类似于词汇这种非结构化字符输入无法被处理。所以,将非结构化字符转换为二进制编码以方便计算机识别处理,整个转化过程被称为文本表示。文本表示是首先抽取出文本的特征词,再使用教学方法进行数字表示的过程,它能够转化为无结构信息,对多标签文本信息进行抽象表述。多标签短文本首先需要提取出人本的特征词,然后再使用数学方法进行数字表示的过程,它能够转化为无结构信息,同时对文本内容进行抽象表述。
衡量单词权重最为有效的一种算法就是TD-IDF算法,使用该算法通常情况下会将较为常见的词语过滤掉,保留其中较为重要的词语。整个算法主要是由以下两个部分组成,分别为:
1)词频
2)逆向文件频率
针对于特定文件里面的词语ti而言,以下给出词频的具体计算方法
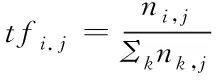
(1)
逆向文件频率也是衡量一个词语普遍重要性的度量[6],具体的计算式如下所示
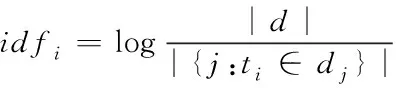
(2)
结合式(1)以及式(2)则能够完成TD-IDF算法,即
tf-idfi,j=tfi,j×idfi
(3)
以下给出互信息的基本定义
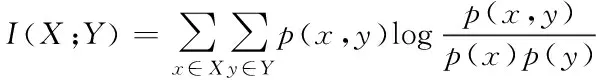
(4)
针对已有多标签文本特征集
T={tk,k=1,2,…,m}
(5)
类别集能够表示为以下的形式
C={cj,j=1,2,…,r}
(6)
其中特征词tk和类别cj的互信息计算方式能够表示为以下的形式

(7)
综合上述分析可知,假设使用分词以及词频作为特征词和对应的权值进行空间向量模型的文本表示。当数据集过大时且包含词汇过多时会出现维度爆炸的情况。同时,仅使用词汇进行表示是无法描述各个词汇之间的关系的,而且还会导致大部分语义信息的丢失。
为了更好地将自然语言交给rcnn模型完成处理任务,人们将词汇转换为数字向量形式的人本表达方式,以上方式即为词向量表示方法。
信息熵以及信息增益是现阶段使用最为广泛的最优属性划分方法。在整个算法应用的过程中,文本分类任务能够有效解决特征提取过程中的非线性问题,所以其在语言处理中占据十分重要的作用。在现实使用的过程中,需要设定对应的参数。其中后验概率计算式能够表示为以下的形式

(8)
上式中,d代表属性的总数;xi代表第i个属性上的取值。
其中最小化分类错误率计算式能够表示为以下的形式:
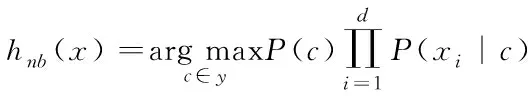
(9)
在现实应用的过程中,为了更加高效的使用rcnn模型,需要结合对应的数据集以及分类任务特点进行对应的改进以及调整。假设任务数据更新较为频繁,则采用懒惰学习的方式,也就是首先不进行训练,在收到预测请求后再对当前的数据集进行概率估计;假设数据随着系统采集不断增加,则通常对新增样本的属性值以及所涉及到的概率估计值进行修正,以确保增量学习的实现。
其中模型联合概率能够表示为以下的形式:
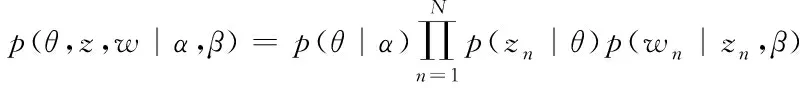
(10)
式中,α代表文档中主题分布信息;β代表主题中特征词分布信息;N代表文档中的特征词数量;θ代表文档所对应的主体向量。
多标签短文本输入层的任务就是讲词向量拼接为文本矩阵,同时将其传递给下一层,方便进行卷积操作。
多标签短文本处理需要考虑文本中各个词语之间的关系[7-8],这样才能够获取一个较为完整的语义特征。
设定特征向量ai是在词汇aixi:i+h-1中形成的,则有
ai=f(xi:i+h-1+b)
(11)
特征向量能够表示为以下的形式
a=[a1,a2,…,an-h+1]
(12)
为了有效避免训练过程中出现拟合的情况,需要结合相关操作来禁止隐层节点参与到前项传播过程,这些神经元将不再参与此次更新,进一步促使权值的更新不再依赖于固定节点的作用。
在上述分析的基础上,提取多标签短文本数据集中多标签短文本的不同特征,同时将其作为传统机器学习模型以及深度模型的输入。
2.2 基于改进rcnn模型的多标签短文本自适应分类
在rcnn模型中,所谓的特征融合主要是指在各个角度进行多标签文本提取,同时结合相关理论将得到的特征放入到rcnn模型中,以有效提升模型的综合性能。
通过模型融合的方法能够完成词汇特征以及语义特征的融合,在2.1小节中提取到的多标签短文本特征设定为输入,然后对模型进行训练,同时将语义特征设定为输入,再对模型进行训练,这样就能够获取多个不同的多标签短文本分类模型,最后结合Stacking技术对rcnn模型模型进行改进,通过改进的rcnn模型对多个基分类器的分类结果进行融合处理,获取多标签短文本自适应分类的最终结果。
为了确保重要的信息能够被保留,以下采用Sigmoid函数对上一时间阶段输出的权重进行保留,具体的计算式如下所示
ft=δ(Wf·[ht-1,xt]+bf)
(13)
结合以上函数对系统中的输入信息进行更新,同时形成对应的候选值,则有
it=δ(Wi·[ht-1,xt]+bi)
(14)
Ct=tanh(WC·[ht-1,xt]+bC)
(15)
结合文本数据的信息特征,网络层利用卷积模块设定为卷积策略,由于多标签短文本中的数据存在一定的差异性,这会导致卷积层内形成的特征图也存在差异。为了能够使用循环网络对特征图进行统一的处理[9],需要采用池化模块对其进行处理,将其长度进行统一。
为了对传统的rcnn模型进行改进,以下采用参数优化的方式实现,则有
ui=tanh(Whht+bw)
(16)
以下计算中间向量和文本上下向量的相似度,具体如式(17)所示
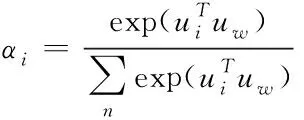
(17)
将原始向量矩阵以及加权两者相加,则能够获取经过优化后的特征向量,则有
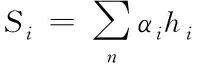
(18)
在多标签短文本处理任务中,文本向量能够采用词向量进行表示。从语义的角度出发可知,字和词两者都能够为人类任务提供十分有价值的信息。实际上就是,多标签短文本中的字和词是进行分类的决定性因素,如果只选取其中任意一种,都会导致信息的丢失。
整个模型主要能够划分为三层,分别为:
1)编码层;
2)特征提取层;
3)全连接层。
编码层通过相应的词向量以及字向量模型,将输入文本解析为词向量序列以及字向量序列,则有
S=[Sw⊕Sc]
(19)
全连接层主要是由线性转换层以及Softmax层组成,其中线性转换层将特征向量转换为一个维度和分类类别相当的实值向量[10],则
P=softmax(WsS+bs)
(20)
其中损失函数能够表示为以下的形式
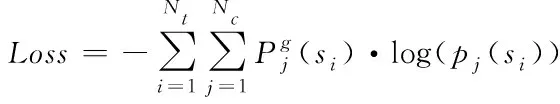
(21)
在上述操作的基础上,结合Stacking技术对rcnn模型模型进行改进,通过改进的rcnn模型对多个基分类器的分类结果进行融合处理,以达到多标签短文本自适应分类,利用图1给出具体的操作流程图。
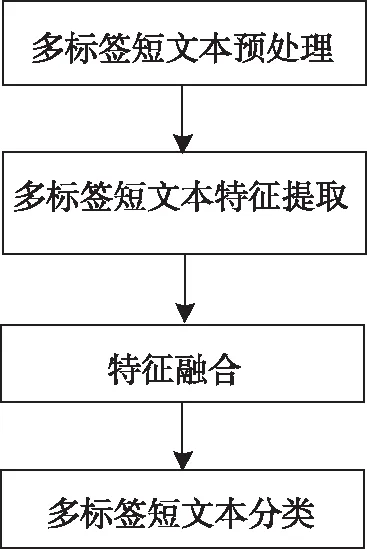
图1 多标签短文本自适应分类流程图
3 仿真研究
为了验证所提基于改进rcnn模型的多标签短文本自适应分类方法的综合有效性,需要进行仿真测试,实验平台为64位Win7操作系统的PC机,CPU主频3.2GHz,内存为8G,在matlab2012b软件平台下使巧M语言进行软件编程。
1)查全率/(%)
以下选取两种传统的多标签短文本自适应分类方法作为对比方法,对比三种方法的查全率,对比结果如表1至表3所示。
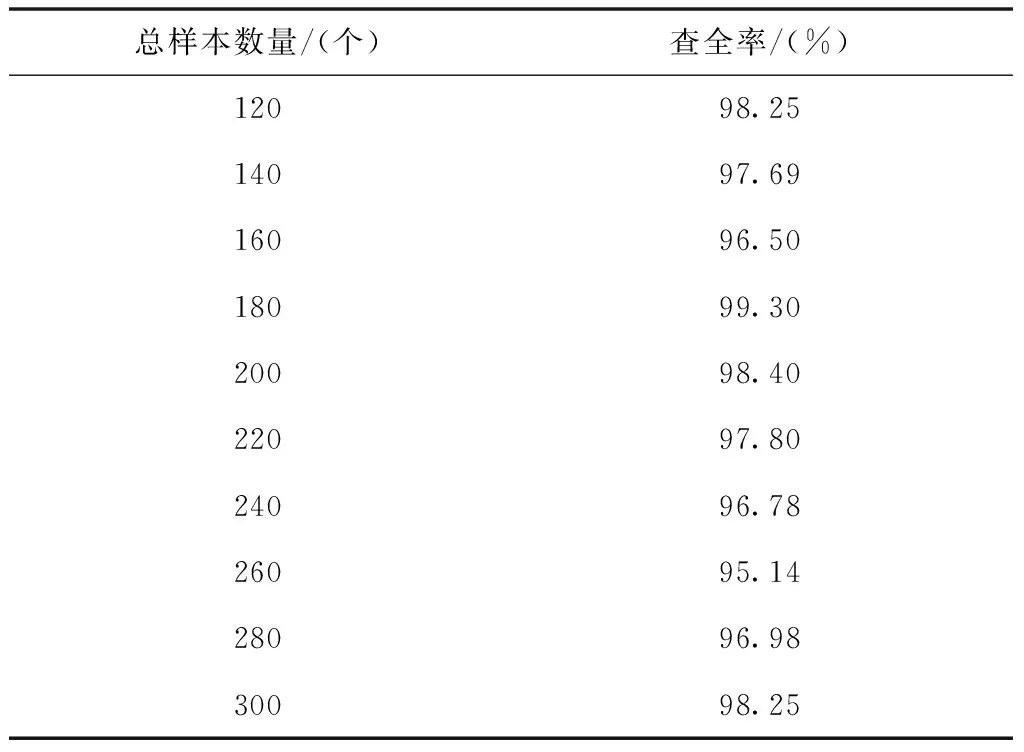
表1 所提方法的查全率变化情况
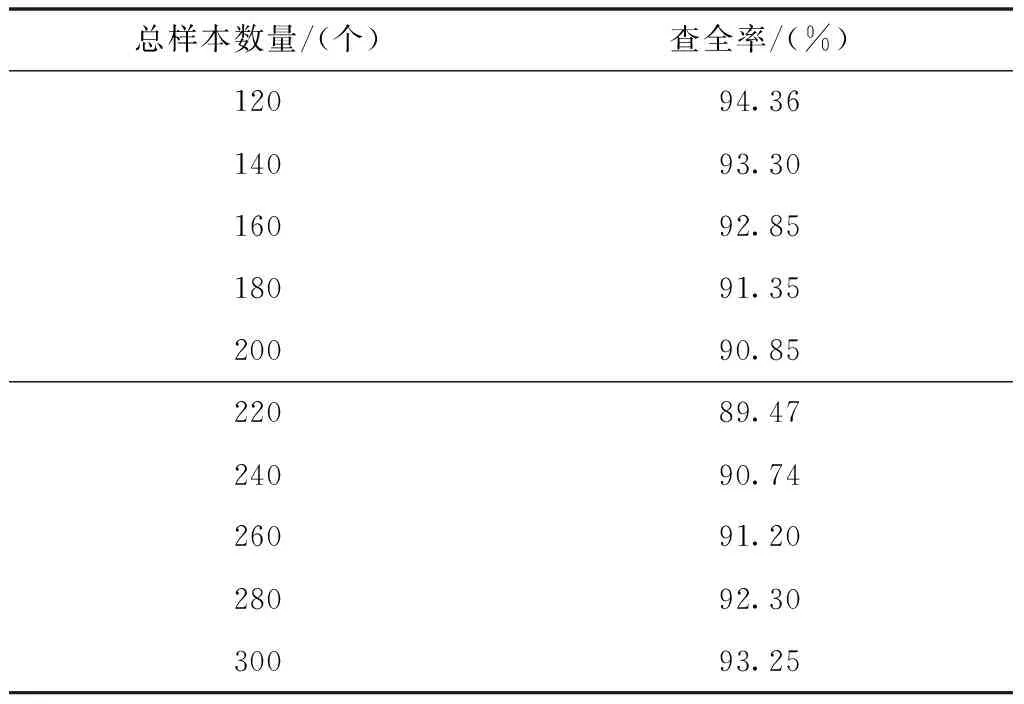
表2 文献[4]方法的查全率变化情况
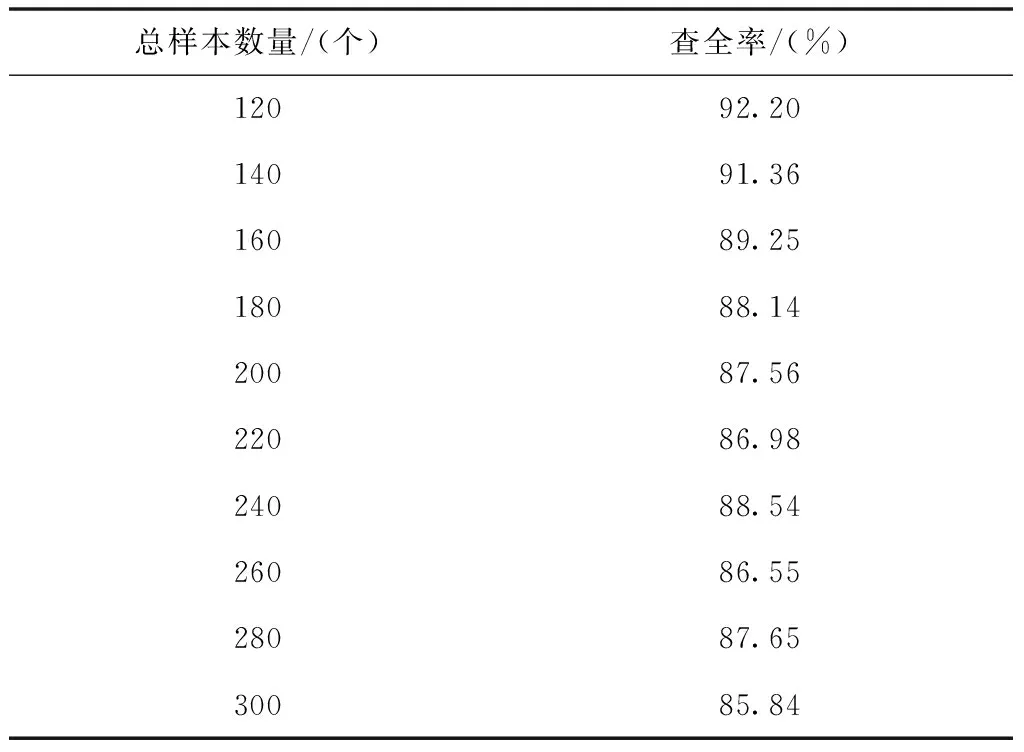
表3 文献[5]方法的查全率变化情况
分析表1至表4的实验数据可知,所提方法的查全率在三种分类方法中为最高;文献[4]方法的查全率次之;文献[5]方法的查全率最低。以上实验数据充分说明,所提方法具有较好的分类效果。

表4 所提方法的耗时变化情况
2)分类准确率/(%)
为了更进一步验证所提分类方法的有效性,以下需要对比三种方法的分类准确率,具体的对比结果如下图所示。
分析图2中的实验数据可知,随着节点数量的持续增加,各种多标签短文本自适应分类方法的准确率也在不断发生变化。其中所提方法的分类准确率明显高于其它两种方法,这充分说明了所提方法的优越性。
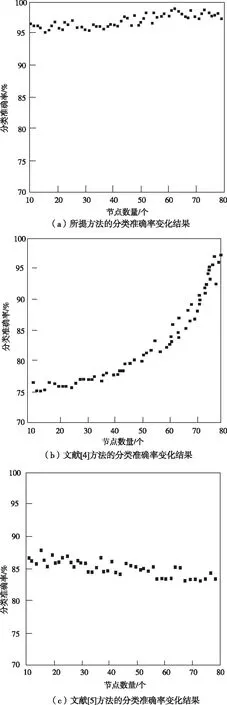
图2 不同分类方法的分类准确率对比结果
3)耗时/(min)
在上述实验环境的基础上,以下需要对比三种方法的耗时,具体的对比结果如下表所示。
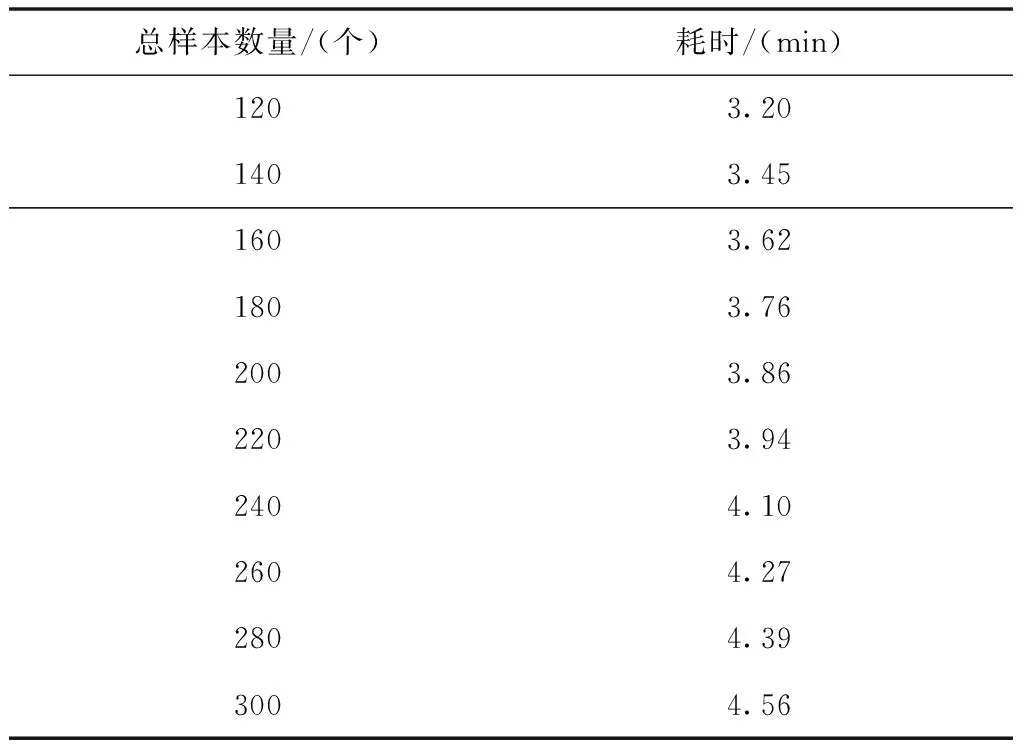
表5 文献[4]方法的耗时变化情况
分析表4至表6的实验数据可知,相比传统方法,所提方法的耗时有了较为明显的下降趋势。
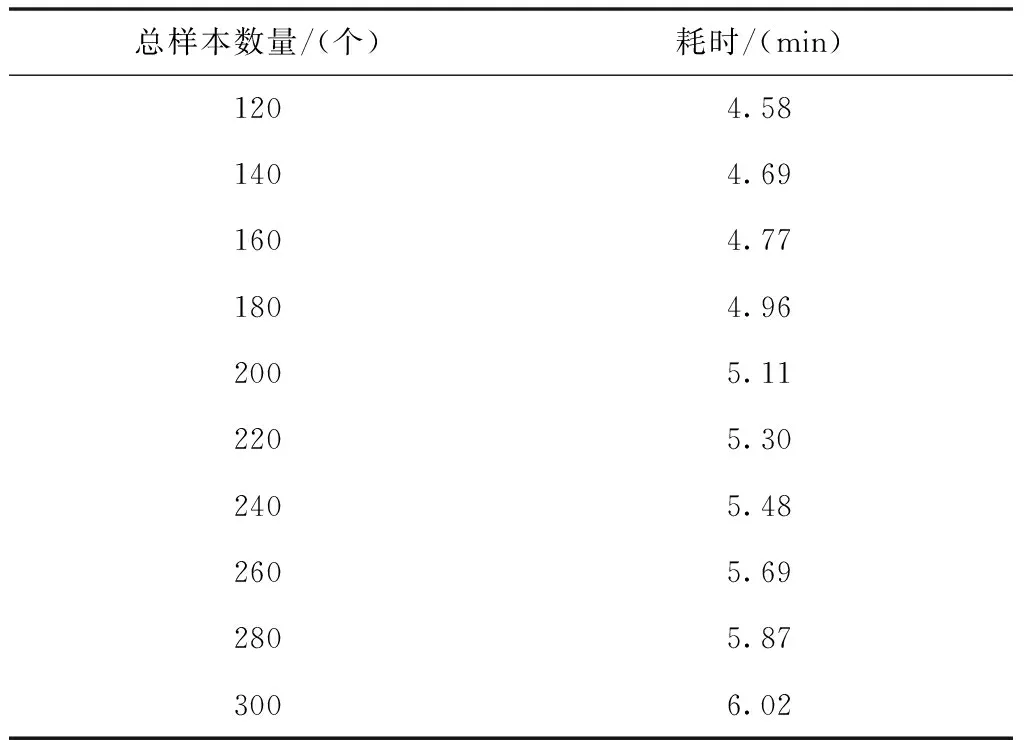
表6 文献[5]方法的耗时变化情况
4 结束语
针对传统的多标签短文本自适应分类方法存在耗时较长、查全率以及分类准确率较低等问题,提出基于改进rcnn模型的多标签短文本自适应分类方法。仿真结果表明,所提方法能够有效提升查全率以及分类准确率,同时有效减少耗时。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
时代英语·高二(2018年7期)2018-12-03
时代英语·高二(2018年3期)2018-06-06
海峡姐妹(2018年3期)2018-05-09
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
少儿科学周刊·儿童版(2015年2期)2015-07-07
