
遗传优化的混合网格计算调度模型SCE部署研究
2021-11-17 08:38:14楚志刚陶永才
计算机仿真 2021年5期
楚志刚,陶永才
(1. 郑州师范学院信息科学与技术学院,河南 郑州 450044 ;2. 郑州大学信息工程学院,河南 郑州 450001)
1 引言
在基因科学、生物医药、金融分析、仿真模拟等科研领域中,往往涉及高通量、密集型数据的计算。要完成这类计算依赖于高性能服务器,由此增加了很多科研与分析机构的成本投入,甚至成为了一些实验室的研究障碍。为了实现高通密集数据的处理,网格计算成为了解决方案中的热点[1-2]。该技术可以将分布式计算资源采取整合,使其达到高性能计算要求[3]。在整合过程中,通常对于物理位置、异构资源没有特殊要求。网格计算的出现降低了高通密集数据处理的成本,也因为其任务的可拆分性,提高了数据处理的效率。当前对于网格计算的的研究主要集中在中间件和作业调度算法方面[4-5]。常用的中间件有Legion与Globus,目的都是提供资源访问的接口。它们具有信息传输、数据管理、定位和访问等功能,改善了网格计算的使用性。但是仍然存在不易拓展、不易部署,以及不支持作业调度等问题。而SCE[6]则是针对当前中间件应用缺陷设计的高性能计算网格软件。SCE基于OGSA架构,涵盖了网络、存储、数据库,以及作业编译、调试、查询等一系列功能。现有网格计算作业调度研究,大多基于单一型作业,不仅缺乏通用性,而且难以采用作业时间作为约束条件。本文研究则兼顾了数据与计算两类作业,建立混合网格模型,并对模型中作业与资源的时间约束进行分析,从而将调度转化为最优解问题。由于遗传算法的全局搜索性能突出,因此本文将其引入调度算法,并针对存在的无反馈、过早收敛[7]等问题进行了改进优化。
2 混合网格计算模型
网格计算的系统结构包括User、路由器、Portal和JobScheduler。系统中含有数据和计算两种密集Job[8],它们对应的概率分别表示成p和1-p。在数据Job中,按照数据的大小进一步划分成大小两种Job,它们对应的概率分别表示成p′和1-p′。从整体来看,大、小Job的概率分别为pp′和p(1-p′)。本文中,将1500MB作为大、小Job的区分门限,数据大小在门限值以下的为小Job,数据大小在门限值以上(包含门限)的为大Job。系统中关于作业的描述是job(iniCount,fSize,deadline,arrive),当是计算Job时,不涉及IO数据,参数fSize=0。系统中关于资源描述为r(speed,bw,free)。Job和资源的各项参数描述如表1所示。
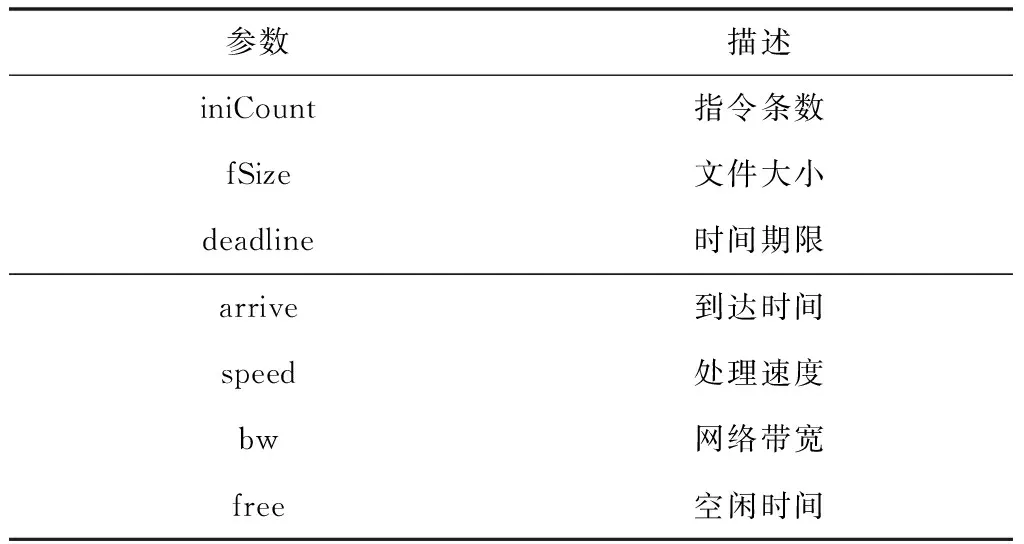
表1 Job与资源参数描述
网格对作业进行调度过程中,在任意时间点,作业对资源的占用具有原子性。假定jobi占用了资源rj,则jobi对rj的操作时间表示为
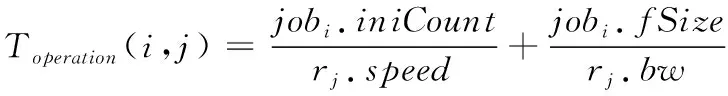
(1)
根据操作时间Toperation(i,j)和free参数,得到jobi对rj的完成时间如下
Tfinish(i,j)=Toperation(i,j)+rj.free
(2)
考虑到作业时间不能超过deadline参数,所以对作业和资源的操作采取如下限定
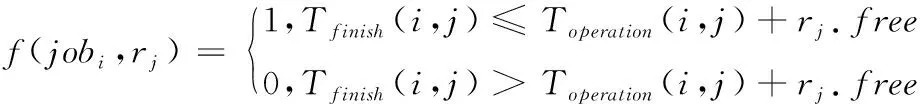
(3)
当作业完成时间不超过期限参数时,jobi能够正常处理;反之jobi不被处理。当资源rj已经被jobi占用过,则rj下一次能够被使用的时间应为
rj.free=Toperation(i,j)+rj.free
(4)
假定网格系统中的作业集是J={job1,job2,…,jobn},其中任意元素均由k个属性构成。于是,作业集对应的属性描述如下

(5)
网格中的资源集是R={r1,r2,…,rm},与作业一致,也包含k个属性。其对应的属性描述如下
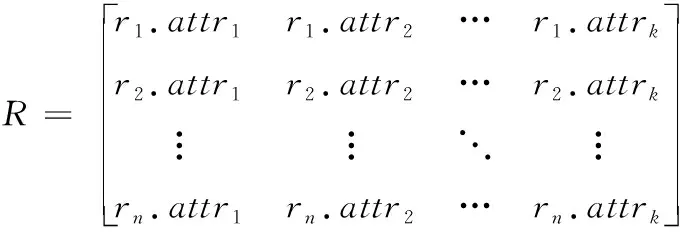
(6)
根据作业和资源的属性集描述可知,它们的集合之积RJ为k×k阶矩阵。如果rj中全部属性都符合jobi需求,便令RJ(j,i)=1;否则令RJ(j,i)=0。此时,也可以得到作业与资源的关系RJ(j,i)=f(jobi,rj)。
3 改进遗传算法作业调度
根据混合网格计算模型的分析,可以将混合网格作业调度看做是如何最优化的利用m数量的资源完成n数量的作业,其中还要考虑作业与资源之间的各种关系约束。由于可以转化成最优解问题,所以本文引入改进遗传算法来实现混合网格作业的调度。
在遗传算法的编码阶段,考虑到网格作业调度需要把作业集J={job1,job2,…,jobn}映射至资源集R={r1,r2,…,rm}中,同时还要保证资源属性与作业的符合程度,以及时间约束,这里选择实数编码[9],让每一个资源对应一个染色体,每一个染色体对应一个作业。在初始化种群时,为提高初始种群的有效性,利用随机方式得到2m数量的样本,用于保证种群样本的多样性。同时利用Min-min得到单个样本,并通过该单个样本的变异得到l-1个样本,用于保证种群中部分样本的质量。从这2m+l数量的种群内经过适应性筛选出m数量样本构成初始种群。这样获得的初始种群能够更好的利用高质量样本启发寻优,降低迭代数量,加速寻优过程。假定进化过程种群中有ns个样本,作业总数是nt,基因数量受限于资源数量,范围是[1,m],染色体i对应的资源j表示是rij,染色体i作业执行时间是Tfinish(rij)。在适应性筛选时,需要确保作业的完成速度快,时间短。于是,将适应度函数设计为
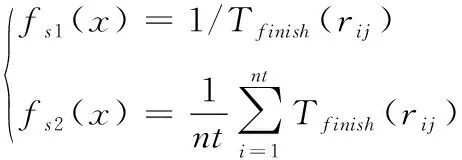
(7)
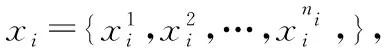
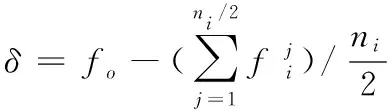
(8)
其中,fo表示样本的最佳适应性。每次迭代进化应保证δ值尽可能小,这样表明样本的相似性较高。在每轮迭代对样本进行选择时,采用如下规则为样本分配选中概率
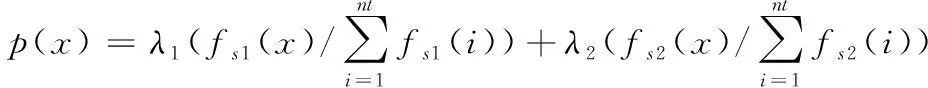
(9)
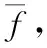
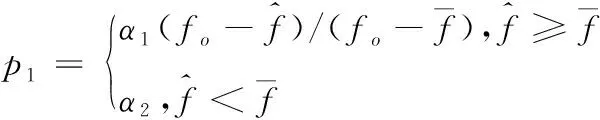
(10)
其中,α1和α2为交叉因子,它们的取值过大,会引发局部最优解;取值过小,会引发进化速度降低。假定待变异样本适应值为f,则样本执行变异处理的概率如下
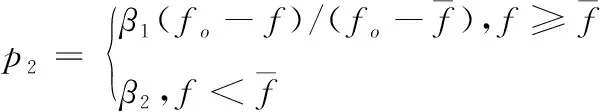
(11)
其中,β1和β2为变异因子。与交叉操作一致,当变异因子取值过大,会陷入局部收敛;当变异因子取值过小,会导致进化速度变慢。
4 SCE作业调度模型
基于SCE实现作业调度时,为辨别网格服务身份,将SaltStack独立部署于Master上,将Client、CenterServer、FrontServer部署于Minion上,部署模型如图1所示。根据SCE部署模型,将网格作业的调度过程分成四个阶段。第一阶段是Client处理Request,由Client解析作业,并对解析后的变量采取校验。校验通过的作业将被执行XML_Make,输出具有JobName、AppName、RunName、等信息的XML文件。第二阶段利用提交函数获取全局作业的gid,由CenterServer服务器接收gid,并将其持久化至SCEDB中,同时根据gid建立用户作业的ujid。第三阶段通过执行do_upload,将作业相关文件集合由Client向CenterServer、CenterServer向FrontServer、FrontServer向计算Node,一级一级传输。第四阶段CenterServer会从SCEDB中查找XML,解析出Job有关的信息与资源情况,经过FrontServer通知Node,由Node完成计算。
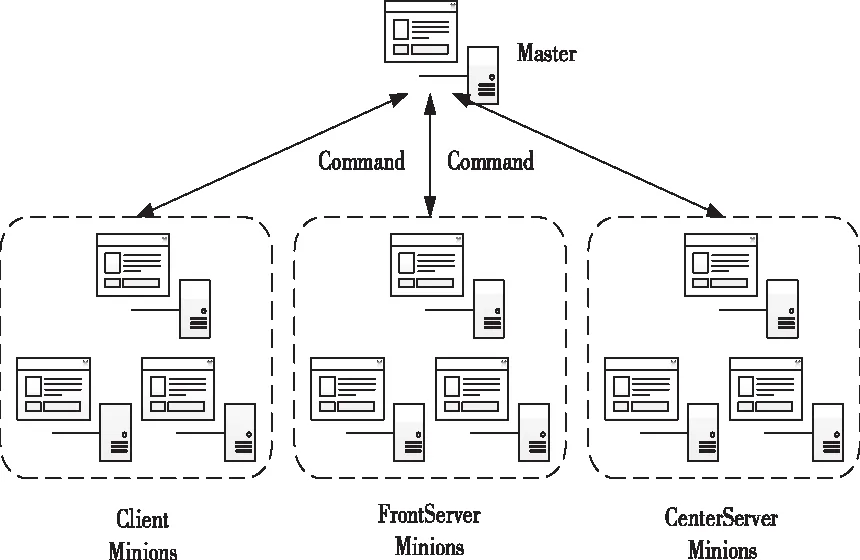
图1 部署模型
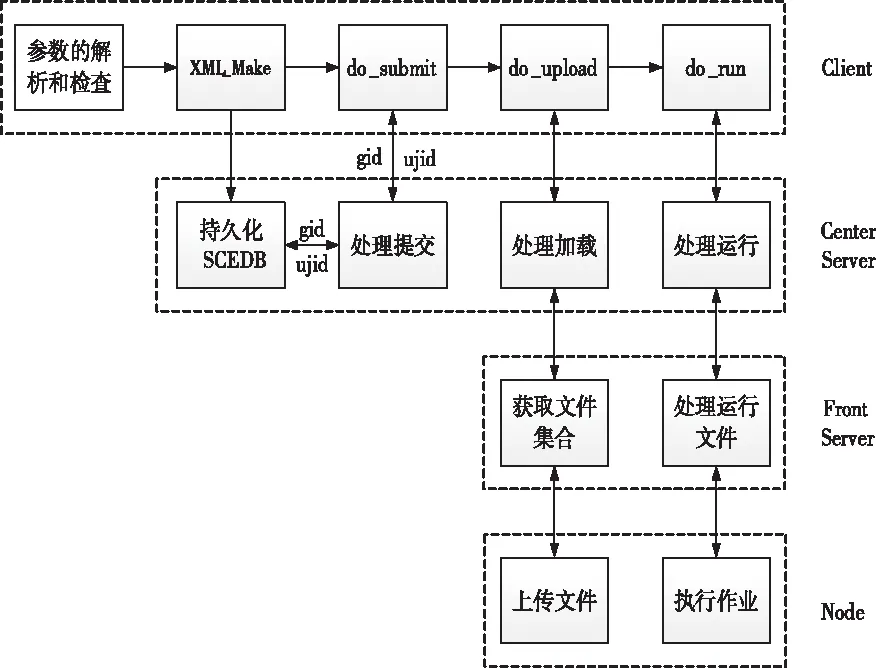
图2 网格作业执行模型
5 混合网格作业调度性能验证
5.1 实验设置
基于SCE部署网格作业调度平台,计算Node采用的是小型集群,Node集群部署五个队列,用于将资源接入SCE。混合网格的实验参数设置如表2所示,其中设置了作业和资源的相关参数。初始化改进GA算法种群大小是100;最大进化代数是100;适应度加权系数λ1=λ2=0.5;交叉因子α1=0.25,α2=0.91;变异因子β2=0.035,β2=0.015。
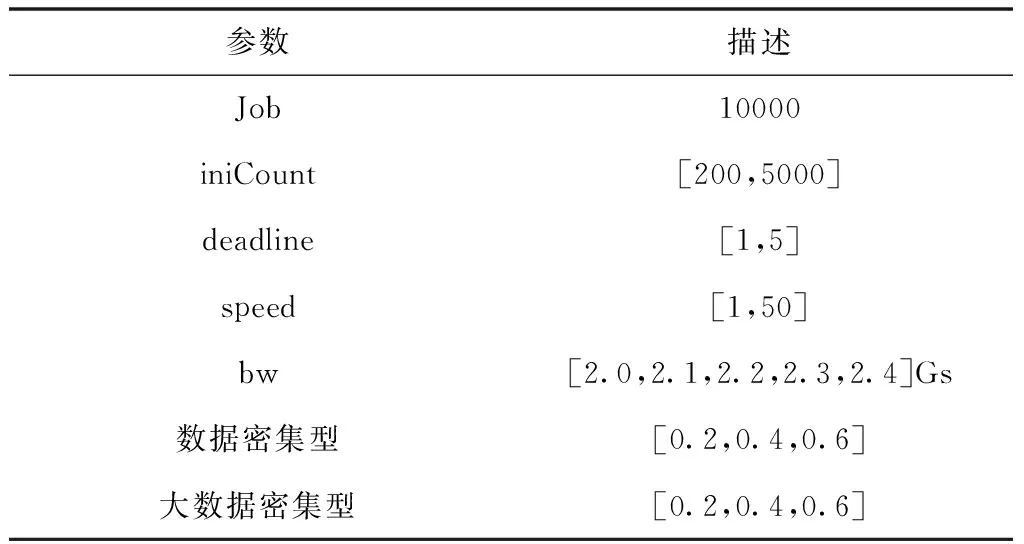
表2 混合网格参数设置
5.2 结果分析
首先对本文设计的改进遗传算法性能进行分析。通过仿真得到进化过程中,遗传算法的收敛曲线,结果如图3所示,横坐标为迭代次数,纵坐标为适应值。经过与经典遗传算法性能对比,改进算法明显降低了进化迭代次数,且收敛曲线整体平滑,没有明显振荡,大约在70代时适应值便趋于稳定,近似收敛,而经典遗传算法在100代的时候还未达到收敛。同时,改进算法的适应值也明显优于经典算法,具有更优的作业执行时间。说明改进算法在种群初始化时采取适应性筛选出一部分样本作为初始种群,利用高质量样本启发寻优,降低了迭代数量。在适应性计算时,分别对每个染色体的作业执行速度和染色体内每个作业的执行速度进行考虑,加快了收敛速度。另外,适应性修正、交叉和变异操作,有效防止了种群出现过早或者局部收敛。
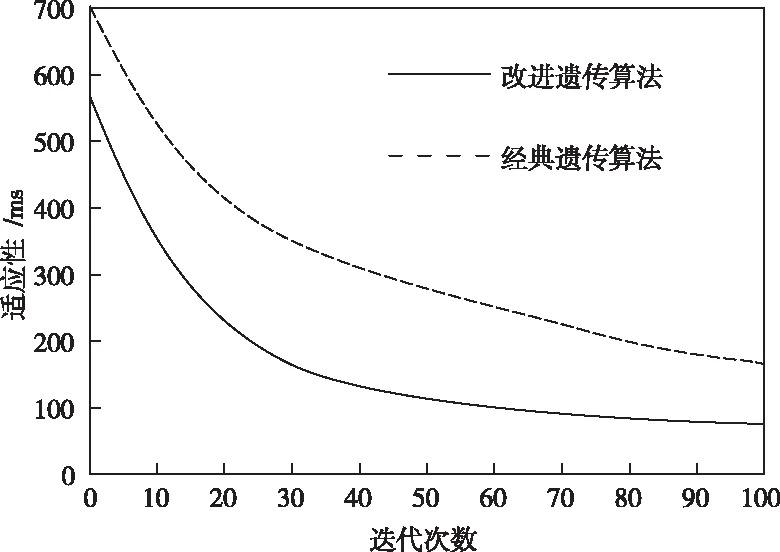
图3 遗传算法优化性能对比
然后对整体算法的响应性能进行验证,实验中10000个作业调度的响应时间结果如图4所示。过程中没有发现作业提交出现错误的情况。根据响应时间结果统计,所有Job中,有3894个Job的响应时间低于100ms,占比为38.49%;9164个Job的响应时间低于110ms,占比为91.64%。从结果可以看出,本文调度算法对混合网格具有良好的适应性和响应时间。
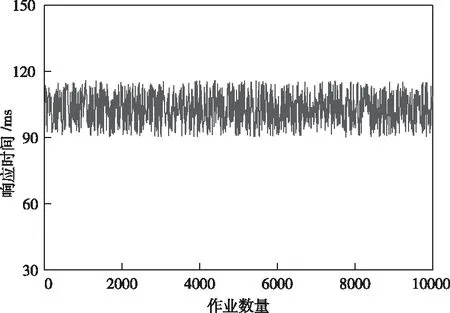
图4 作业响应时间结果
最后,考虑到作业调度出现问题时带来的影响。这里通过调整故障间隔来模拟异常情况的影响程度,在故障间隔改变的过程中,得到Job响应时间曲线,如图5所示。实验中引入文献[4]的算法进行对比。故障间隔变大,表明故障出现的频率降低,固定时间内出现的故障次数变少。根据结果曲线分析,故障的出现会令作业服务断开,从而拖延平均响应速度,故障出现的频次越高,对响应时间的拖延越严重,如果作业量较大,还可能导致计算服务阻塞,所以可以看到,随着故障间隔的变大,各方法的响应时间都在下降。而本文算法显然受故障影响较小,表明具有比文献方法更好的网格计算效率。
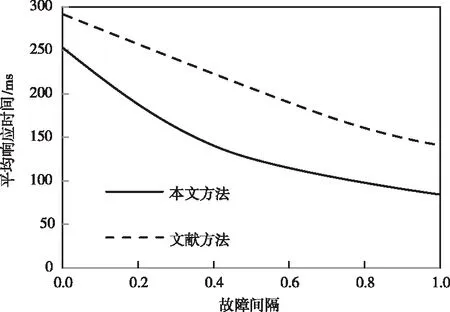
图5 作业响应时间受故障间隔的影响
6 结束语
为提高混合网格作业调度的效能,本文提出了基于SCE的遗传优化调度算法。在对混合网格计算模型分析的基础上,得到网格作业集与资源集的属性描述,同时得到作业与资源间的约束关系。考虑到作业调度可以转化成最优解搜索,于是针对混合网格作业调度设计了改进遗传算法,从初始化种群、适应性计算、适应性修正、样本选择、交叉和变异多方面进行了优化。考虑到拓展、部署和对作业调度的支持,引入SCE中间件提供完善的访问接口,并基于SCE作业调度的部署进行算法性能验证。结果表明本文改进的遗传算法具有良好的启发寻优效果,降低了迭代次数与进化时间,有效防止了种群出现过早或者局部收敛;经过10000次Job执行没有出现故障情况,显著提高了混合网格计算作业调度的稳定性与响应速度;通过人为调整故障间隔发现,即便在出现异常情况时,本文所提的作业调度方法也能获得较好的响应时间。
猜你喜欢
今日农业(2022年15期)2022-09-20 06:54:16
铁道通信信号(2020年10期)2020-02-07 01:01:32
成都信息工程大学学报(2019年3期)2019-09-25 08:31:10
三门峡职业技术学院学报(2019年1期)2019-06-27 07:32:58
红土地(2018年7期)2018-09-26 03:07:38
石油地球物理勘探(2017年2期)2017-11-23 06:02:04
中央民族大学学报(自然科学版)(2017年1期)2017-06-11 07:13:32
统计与决策(2017年2期)2017-03-20 15:25:24
智能系统学报(2015年4期)2015-12-27 09:38:39
当代畜禽养殖业(2014年10期)2014-02-27 07:59:49
