
云计算下多属性信息交换安全漏洞识别仿真
2021-11-17 07:37赵男男
计算机仿真 2021年7期
赵男男,李 佳
(广东海洋大学寸金学院,广东 湛江 524094)
1 引言
云计算在近几年来一直作为新兴领域得以应用,该计算模式的关注热度逐年增加,云计算属于可配置计算,利用存储资源以及计算外包完成信息的交换、存储以及计算等操作,实现资源中心化。但是随着网络的日益发展,网络安全漏洞的事件发生数量也日益增多,一方面如果网络蠕虫 爆发、DDoS攻击等大规模的网络安全事件将占用大量的网络资源以及计算资源[1,2];另外一方面突发访问以及网络故障等非恶意行为也会导致流量发生突变,影响网络正常使用。云计算下多属性信息交换安全漏洞主要会影响到网络流量,而网络流量是保证网络正常运行的重要手段。信息交换安全漏洞识别是组建在网络流量的正常行为模式轮廓之上,假设得到网络流量信息轮廓值与正常值的差异超过设定范围,则进行入侵报警[3]。
现阶段信息安全越来越受到大家的广泛关注,现阶段对于安全的研究不仅仅出现在军事以及外交上,其中商业的发展也渗透着信息安全。对于信息交换安全漏洞识别是当前需要研究的热点话题,要想真正意义上提升整个系统的安全性能,需要对其展开具体的研究,目前在该研究领域也出现了一些研究成果。
文献[4]提出了一种基于有限状态机的多属性信息交换安全漏洞识别。提取多属性信息交换下的安全漏洞特征,以安全漏洞特征为迁移条件构建识别模型,并将模型状态转移过程抽象为多维向量,再利用余弦相似度公式进行相似度计算,结合设定的阈值,实现多属性信息交换安全漏洞识别,但是该方法在应用过程中存在识别准确度低的问题。文献[5]提出一种基于非线性规划的多属性信息交换安全漏洞识别方法,采用最优加权系数法构造目标函数,以及约束条件下的最小化目标函数,利用非线性规划法求出加权系数,构建多属性信息交换安全漏洞识别模型,实现多属性信息交换安全漏洞识别。该方法可以使单项识别优势互补,进而提高评估精度,但实际应用效果较差,所需时间较长。
针对传统方法存在的问题,提出云计算下多属性信息交换安全漏洞识别方法。仿真结果表明,所提方法能够准确识别信息交换过程中产生的安全漏洞,确保系统的稳定运行。
2 多属性信息交换安全漏洞识别方法
2.1 支持向量机(SVM)模型的构建
相关数据主要是由41个标记在连接仪器的特征与1个标记正常与否的标志所组成,所以利用X(t)={x1(t),x2(t),…,xn(t)}代表t时刻的一个连接,则有

(1)
相似度计算公式为

(2)
其中:
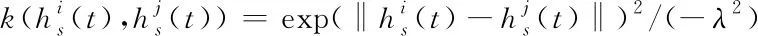
(3)
在上述基础上,则能够计算特征对于(xi(t),xj(t))的相似度,即
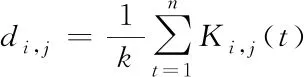
(4)
假设两个特征中的相似度阈值高于任意阈值,则需要删除其中的一个特征。
SVM主要适合处理利用一定数量的支持向量决定的超平面来进行数据分类,支持向量本质上就是一个训练数据的子集,该子集被设定为用于定义二类数据的边界。在无法利用SVM分类问题的情况下,通过核函数在高维特征空间中划分解决上述的分类问题。在高维特征空间中,能够利用线性超平面进行分离。
其中,线性边界能够表示为
ωTx+b=0
(5)
式中,b为边界校正参数,ωT为线性分量,x为边界变量。
线性边界主要通过训练数据进行函数值估计。假设训练数据是线性可分的,则存在一对(ω,b)∈Rn×R使得
ωTx+b≥+1,(x∈A)
(6)
ωTx+b≤-1,(x∈B)
(7)
A,B均为线性训练数据集合。
利用下式给出决策函数的表达式
fw,b(x)=sign(ωTx+g)
(8)
式中,ω代表权重向量;g代表偏离值。将式(6)和式(7)进行合并,则有
y(ωTx+b)≥1,(x∈A∪B)
(9)
将上述问题转化为优化问题,则有
minΦ(ω)=‖ω‖2/2
(10)
s.t.y(ωTx+b)≥1
(11)
在支持向量机算法中正规化参数与核宽度是两个能够调整的参数,其中参数的取值不同,分类器所对应的的泛化能力也就不同。在上述基础上,组建支持向量机模型:
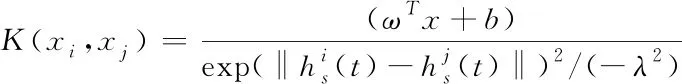
(12)
2.2 云计算下多属性信息交换安全漏洞识别优化
云计算的应用环境以及技术类型决定了其数据交换过程问题主要为数据安全、可靠以及效率几个方面。这其中,在云计算具有开放性的前提条件下,数据交换会面临非法存储、下载以及访问等不安全问题,这导致用户无法将核心数据的交换和处理托付给云计算平台。下面利用具体方法识别云计算下多属性信息交换安全漏洞。
设定云平台未识别序列为X={x1,x2,…,xn},其中该序列中的一部分数据为正常数据。
信息交换安全漏洞识别方法主要是组建正常的数据模型,通过云平台所组建的模型识别信息交互过程中出现的安全漏洞。
首先寻找正常数据的最优评价函数f:X→Y,针对设定的xi∈X,能够获取与之对应的输出yi∈Y。通过经验最小化原则[6],能够将上述优化问题描述为

(13)
式中,L代表损失函数;Ω代表函数f的取值范围;η代表调和参数。初始数据在经过转换后,需要将获取的最新特征映射到新的特征空间中[7]。其中设定c代表中心,R代表球面的半径,通过计算球面半径与球心在特征空间的长度获取数据样本的异常程度,则有
f(x)=‖φ(x)-c‖2-R2
(14)
如果实例在超平面内,则对应的评价函数值为f(x)<0,认定该点为正常点;如果实例在超平面外,则对应的评价函数为f(x)>0,认定该点为异常点,也就说明在进行信息交换的过程中存在异常数据以及恶意攻击。为了能够更好的抑制模型的过度拟合[8],需要在算法中加入ξi>0,并且样本需要满足以下的约束条件
‖φ(x)-c‖2≤R2+ξi
(15)
利用下式给出目标函数的表达式

(16)
式中,C代表平衡超平面半径以及松弛变量参数。将以上问题转化成优化问题,通过拉格朗日乘子方法对该问题进行求解,则有
(R2+ξi-‖φ(x)-c‖2)
(17)
式中,αi≥0,βi≥0;在上述基础上,分别对R、c、ξi进行求导,则能够获取
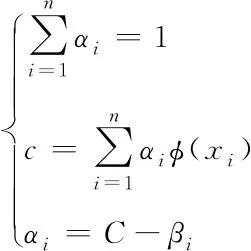
(18)
将式(17)分别代入式(18)中,则有

(19)
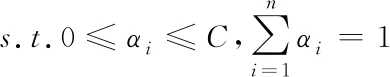
(20)
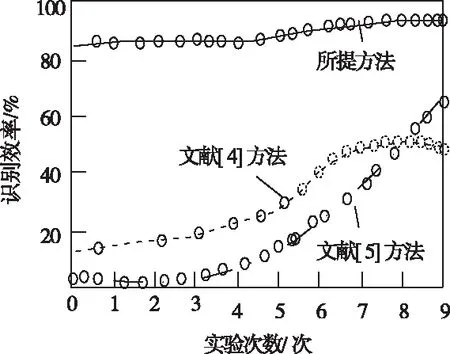
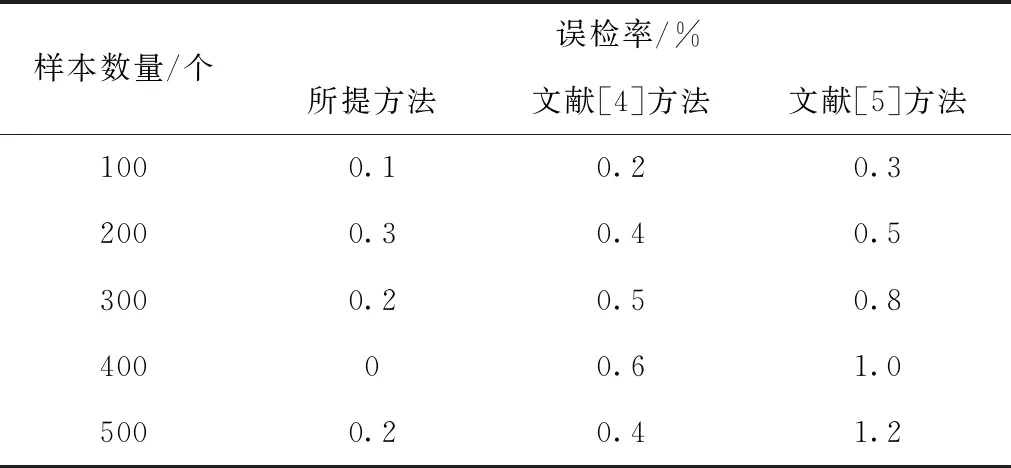
通过αi的取值能够样本划分成三类,如果αi=0,则说明样本在球体的内部,该样本为正常数据样例;如果0<αi 在模型获取标记数据后,通过半监督的学习方式实现模型的优化以及拓展[9-10],其中数据的标记方式选用主动学习方式。半监督学习方式对应的数据模型如下,其中给定数据集为 X=(x1,x2,…,xn,xn+1,…,xn+m) (21) 式中,前n个数据代表没有进行标记的数据,后面m个代表标记数据,其中标记类别表示为 Y={+1,-1} (22) 式中,+1代表正常数据,-1代表异常数据。如果其中含有m1个正例,m2个负例,且满足m1+m2=m=n,则优化目标函数为 (23) 式中,γ≥0代表二类标记数据边缘之间的长度;C1代表没有进行标记的数据权衡参数;C2代表正例数据的权衡参数;C3代表负例数据的权重参数;ξi、ξj、ξk分别代表不同的松弛变量,实质就是距离球心较远的样本被错误分类的机率较大。其中C1、C2、C3取值的大小会影响模型的构建速度。C1全面说明了未标记数据的约束作用[11];C2、C3全面说明已经进行标记数据的引导作用。在上述基础上,将以上问题转化成无约束最优化问题,则有 ξi=1(R2-‖φ(xi)-c‖2) (24) ξj=1(R2-‖φ(xj)-c‖2-γ) (25) ξk=1(R2-‖φ(xk)-c‖2-R2-γ) (26) 如果风险函数的取值为I(t)=max(-t,0),则有 (T-‖φ(xi)‖2+2φ(xi)′c) (27) 在上式的基础上,设定样本类型的取值为+1或者-1,则有 (28) 通过式(28)可知,球心c的大小是通过以上两种不同的数据共同决定的,根据其能够得到分类精度更高的分类模型。以下需要引入损失函数进行求解,则有 (29) 利用下式对不同的变量进行求导,则有 (30) 通过求导链式法则并且结合相关理论,能够获取λi和λj的偏微分,则有 (31) (32) 在上述基础上,对其中的部分数据进行识别标记,得到多属性信息交换安全漏洞识别公式 (33) 在以上分析的基础上,选取系统中的部分数据进行标记,并且通过半监督的方式对最新标记的数据进行二次优化[12]。针对本文的性能指标而言,通常情况下有检测性能以及变化程度两种指标,本文选用半监督的的形式,综上需要将两种指标相结合获取终止条件,则有 con=b1MSE(f(x,y)+b2var(f(x,y))) (34) 其中,公式的前部分代表模型对于标记样本的预测值和真实值之间的误差,取值为前部标记样本的预测分类以及实际分类结果之间的差异;后部分的取值为全部没有进行标记样本预测分类差异程度。如果上述模型符合约束条件,则终止条件,反之则继续进行主动学习。 综上所述,完成了云计算下多属性信息交换安全漏洞识别。 为了验证所提云计算下多属性信息交换安全漏洞识别方法的有效性,需要进行一次全面仿真。实验环境为:DELL台式机,Windows XP系统,1G内存,3.2GHz Pentium(R)4处理器,Matlab R2008b集成环境,Mysql5.1数据库。 1)识别效率(%)对比 在本次实验中,主要针对不同方法的识别效率(%)进行对比,其中选取文献[4]方法、文献[5]方法作为对比方法进行仿真,具体的对比结果如图1所示。 图1 不同方法识别效率对比结果 分析上述可知,不同识别方法的识别效率随着实验次数的变化而变化。在实验初期,各个识别方法的识别效率都呈直线上升趋势,当实验次数为5次时,文献[4]方法的识别效率开始呈下降趋势,但是其它两种方法的识别效率呈稳定趋势。通过具体的实验数据分析可知,所提方法的识别效率相比传统方法有了明显的提升,充分验证了所提方法的优越性。 2)识别效果全面对比 为了更加全面验证所提方法的优越性, 以下分别对比不同方法的识别率(%)、误检率(%)以及漏检率(%),具体的对比结果如下表所示。 分析表1可知,不同方法的识别率随着样本数量的变化而变化,所提方法的识别率最高为100%,这说明所提方法能够更为准确识别信息交换过程的安全漏洞,其它两种方法的识别效率明显低于所提方法,说明其它两种方法还需要进一步进行完善。 表1 不同方法识别率对比结果 分析表2可知,所提方法的误检率在3种方法中为最低,文献[4]方法次之,文献[5]方法的误检率最高。在样本数量为400个时,所提方法的误检率为0%,其它两种方法的误检率分别为0.6%、1.0%。其它两种方法相比方法高出了很多,由此可见,所提方法能够准确识别信息交互过程中的安全漏洞,确保网络的正常运行。 表2 不同方法误检率对比结果 分析表3可知,所提方法的漏检率明显低于其它两种方法,所提方法最低漏检率为0%,而文献[4]方法的最低漏检率为0.4%,文献[5]方法的最低漏检率为0.5%,由此可见,所提方法的漏检率相比传统方法有了明显的下降,且所提方法的漏检率可以一直维持在较低数值,这也更加充分验证了所提方法的综合有效性。 表3 不同方法漏检率对比结果 综上可知,所提方法各个方面的性能都明显优于其它两种识别方法,其中最为主要的原因在所提方法引用SVM方法对数据进行分类,这促使所提方法能够更加准确的识别信息交互过程中产生的安全漏洞,提升所提方法的稳定性,相比传统方法所提方法的综合性能也得到了一定程度的提升。 针对传统的信息交换安全漏洞识别方法存在的缺陷,本文提出云计算下多属性信息交换安全漏洞识别方法。通过仿真,充分验证了所提方法的综合有效性。目前针对安全漏洞识别方面的研究较多,但是具体针对云计算下多属性信息交换安全漏洞识别方面的研究需要进一步的完善以及发展,虽然所提方法获取了一定的成就,但是需要进一步研究的内容还有很多,具体如下: 1)未来阶段需要对识别的应用特征数据集进行进一步完善,例如数据的扩充等。 2)进一步提升支持向量机的抗噪性以及泛化性,它是提升识别算法准确性的重要因素。 3)所提方法的识别率、误检率、漏检率仍然存在进一步完善的空间,未来阶段也将深入研究,进一步提升识别准确性。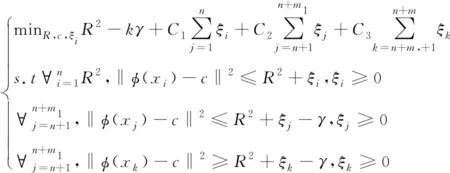

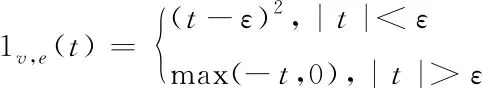



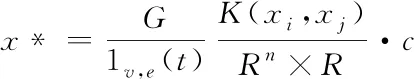
3 仿真研究


4 结束语
猜你喜欢
上海人大月刊(2022年4期)2022-04-14
作文通讯·初中版(2022年2期)2022-02-05
消费电子(2021年7期)2021-08-10
人大建设(2020年5期)2020-09-25
人大建设(2020年5期)2020-09-25
瞭望东方周刊(2018年47期)2018-12-11
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
电子技术与软件工程(2016年20期)2016-12-21
计算技术与自动化(2014年1期)2014-12-12
