
基于深度学习的匿名协议流量识别技术研究
2021-11-17 06:53白惠文马雪婧刘伟伟刘光杰
计算机仿真 2021年7期
白惠文,马雪婧,刘伟伟,刘光杰
(1. 南京理工大学自动化学院,江苏 南京 210094;2. 中国船舶重工集团第八研究院,江苏 南京 211153)
1 引言
网络流量分类与识别技术是有效的网络规划、基于策略的流量管理、应用程序先验化和安全控制的前提和基础。近年来出现了一种新的混淆方式,该方式使用特殊的加密手段,隐藏自己的密钥协商和身份认证过程,无法获取其协议类型,把这种类型的流量称作全程加密流量,该流量在传输层就可以表现出近乎完全随机的字节特性,这种类型的协议无法通过类似于SSL的明文握手过程来进行识别,它们的TCP数据流是全密文的形式,普通的流量识别手段无法获取用户的任何行为信息,甚至协议类型都无从得知,称这一类型的协议为匿名协议,针对具有这种类型的典型应用,即Tor、Tunsafe和Psiphon3进行了研究,并使用深度神经网络对它们产生的流量类型进行了识别。
由于随机端口以及全程加密的手段,传统的基于端口[1-3]和深度包检测[4-7]的方法已经失效。ML(机器学习)的方法被已经广发的应用到网络流量分析中,但是其准确度依赖于所提取的特征,而基于深度学习的方法则不需要人为的提取特征,并且已经被陆续应用到加密流量的识别技术中并且取得了一定的研究成果。Aceto[8]等将许多深度学习方法与随机森林(RF)算法进行了比较,以显示性能上的差距。他们使用3个带有不同数量标签的移动数据集,这些深度学习方法在两个数据集上都优于RF。Wang[9]提出使用卷积神经网络(CNN)模型,他们将数据包中的字节进行标准化,使用前784个字节作为输入,并使用一个包含12种加密应用程序的数据集对模型进行了评估,并与使用时间和长度统计特特征的C4.5决策树方法作了比较,结果显示有较为明显的改进。Chen等[10]使用具有2个卷积、2个池和3个全连接层的CNN模型来完成协议和应用程序分类任务。他们利用核希尔伯特空间(RKHS)的重生成嵌入,将早期的时间序列数据转换为二维图像。他们的CNN模型在协议和应用分类任务上优于经典的机器学习方法。Rezaei[11]等使用时间序列结合基于一维CNN的半监督方法对5个应用程序进行分类。他们使用带有大量未标记数据包的数据集进行模型的训练,随后使用该模型对带有标记的数据集进行应用程序分类,实验表明该模型可以应用于高带宽业务网络。为了同时捕捉流的时空特征,Wang[12]和Lopez-Martin[13]分别使用了CNN和RNN进行应用的识别。除了微小的差异,两项研究都将前6-30个数据包的内容作为模型的输入。虽然输入特征、神经网络结构和数据集是不同的,但它们都具有较高的准确性。Lotfollahi[14]利用头部和载荷数据,在ISCX数据集中使用VPN和非VPN数据训练一维CNN和SAE模型。两种模型都显示出较高的精度,但CNN模型的性能略优于SAE模型。
由于以上研究成果主要集中在已知的标准加密协议或隧道中,对于传输层中使用了特有的协议进行加密的流量缺乏相应的研究工作,针对这种问题,提出一种基于卷积神经网络的传输层全程加密流量的识别方法,并与多种经典的机器学习方法做了对比实验,结果表明深度学习方法对于这种全程加密的流量具有较好的识别效果,该方法可以有效地对混淆为全密文的TCP流量进行识别。
2 匿名协议分析
几乎所有的加密协议都可以分为两个主要阶段:连接的初始化和加密数据的传输。第一阶段可以进一步划分为初始化握手、身份验证和共享加密秘密。在第一阶段,通常交换算法套件,验证通信方,并交换密钥。然后,这些密钥用于加密第二阶段传输的数据。图1描述了这种通用协议方案,比如加密网站最常使用的TLS协议,应用层的加密安全协议SSH,在VPN中常用的IPsec,以及BitTorrent和Skype等应用都具有类似的过程。私有加密协议一般也会有这些或者部分过程,匿名协议的产生一般有两种实现方法:1)通过加入一个混淆过程将常用加密协议(如SSL或SSH等)的初始化连接过程加密;2)使用静态密码省去密钥协商过程。这里将针对基于基于混淆SSH协议的Psiphon 、基于Ofbs4的Tor、基于加密TCP的Tundafe进行介绍。

图1 加密协议通用过程
2.1 基于混淆SSH的Psiphon(Psi)
Psiphon产生的匿名流量是由混淆过的SSH协议产生的,它使用Obfuscated-OpenSSH加密了SSH协议加密初始化过程,使SSH流量变为匿名流量。Obfuscated-OpenSSH协议是著名的SSH混淆协议实现,开源代码托管于网站github。Obfuscated-OpenSSH协议基本实现原理如图2所示。

图2 Obfuscated-OpenSSH协议实现原理图
Obfuscated-OpenSSH在TCP连接建立以后,SSH连接建立以前,客户端和服务器交互若干个负载内容随机的数据包,交换混淆加密参数,用于推出两端的混淆加密密钥;然后,服务器和客户端分别对对方身份进行验证;随后,进行SSH协议连接建立过程,该过程使用混淆密钥进行加密。SSH协议数据交互阶段是加密的,Obfuscated-OpenSSH增加了混淆后使得整个SSH会话是加密的,难以通过DPI的方式进行解析分析。这种混淆方式一定程度上增加了通信的隐私效果。
2.2 基于Obfs4的Tor
Obfs4是Obfs系列的最新一代匿名插件,它仍然主要围绕为现有的经过身份验证的协议(如SSH或TLS)提供一层混淆来设计,但obfs4尝试提供身份验证和数据完整性。该协议有两个阶段:密钥交换和加密数据传输。Obfs4继承了Obfs的特点,抹除了Tor的数据包的标识,并通过随机椭圆加密算法对数据重新进行了加密。由于Obfs4并未使用常见的加密协议而是使用了私有的加密协议,这就使得其数据包看起来像是一般的携带数据负载的tcp协议,这样便给数据流过滤造成了一定的困难。同时,为了弥补Obfs3的不足,Obfs4沿用了ScreambleSuit的可以通过在负载部分进行随机填充,混淆了数据包的负载和间隔时间的特征的方式;同时,在数据通讯前,Obfs4进行了多重认证机制,一旦任何一次认证出现问题,Obfs4将立刻停止继续通信,这种多重认证使得其的匿名性和反探测能力得到了很大的提升。
2.3 Tunsafe(Tun)
Tunsafe是一款基于WireGuard协议的VPN应用。WireGuard是一个非常简单但快速和现代的VPN协议,利用了最先进的加密技术。它的目标是比IPsec更快、更简单、更精简、更有用,同时避免了大量的麻烦。它目前正在进行大量的开发,但它可能已经被认为是业界最安全、最容易使用和最简单的VPN解决方案。WireGuard是基于UDP协议设计的轻量级的安全VPN协议,官方并未支持TCP协议的混淆模式,但是已经被第三方进行开发,增加了无状态加密TCP和TLS的混淆方式。本文针对其TCP混淆模式进行了研究,发现其表现出了匿名协议的特性,整个会话过程不包含任何明文特征。
3 基于卷积神经网络的匿名流量识别方法
3.1 数据包序列到图像的转换
基于机器学习的网络流量识别需要借助人工分析适合的特征,特征的好坏决定了最终的识别效果。卷积神经网络识别技术绕过了特征提取,直接从训练数据中进行深度学习,自动得到不同网络流量的特征模型,实现对网络流量识别的目的。为了充分利用流量中的统计特征,提出了一种数据包序列转换为图像的方法,过程如图3所示。
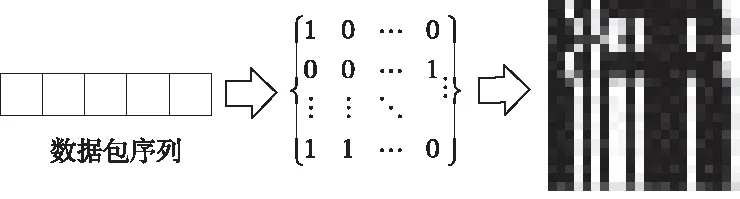
图3 数据包序列到图像的转换
本文设置了一个窗口,每个窗口中包含同一条流中连续的23个数据包,即可得到一个数据包序列,每个数据包序列可以表示为
Xn={x1,x2,…,xk}
(1)
其中,X表示数据包向量,x为数据包对象,k=23。用每个数据包的长度、方向以及TCP的6个标记位来代替数据包对象,则一个数据包可以表示为
xn={y1,y2,…,yk}T
(2)
其中1≤n≤23,y1…y16分别表示两字节数据包长度的每一位上面的值,y17…y23则表示方向以及数据包中TCP层的标记位,这23个元素取值均为0或1。最终,每个窗口中的数据包可以表示为:

(3)
这样,每个数据包序列对象就可以被表示为一个二维的向量,将这个向量的值放大255倍,转换为一个通道数为1的图像进行处理,作为卷积神经网络的训练数据。卷积神经网络通过局部感知和权值共享对原始流量灰度图进行卷积,将网络流量信息的特征提取出来,再用池化操作对特征值进行降维,经多层提取,最终抽取出对应网络流信息的多项抽象特征。本文卷积神经网络参考经典的卷积网络结构LeNet构造训练网络,各层卷积核个数分别为6,12和120,最终提取了网络流量灰度图的抽象特征,然后用多分类Softmax分类器实现网络流量的归类。
3.2 卷积神经网络结构介绍
本文构建了一个7层的卷积神经网络,如图4所示。
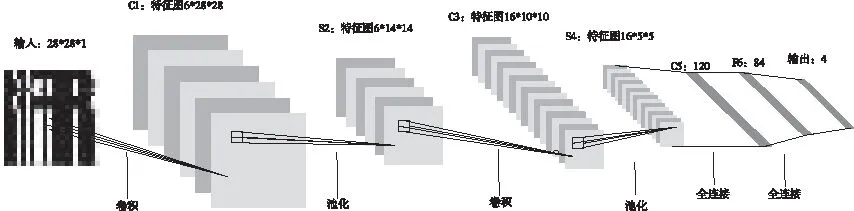
图4 卷积神经网络模型
模型由7层CNN(不包含输入层)组成,上图中输入的原始图像大小是28*28像素,卷积层用Ci表示,子采样层(pooling,即池化)用Si表示,全连接层用Fi表示。
C1层(卷积层):6*28*28,该层使用了6个卷积核,每个卷积核的大小为5*5,每个卷积核(5*5)与原始的输入图像(28*28)进行卷积,这样就得到了6个feature map(特征图)。由于参数(权值)共享的原因,对于同个卷积核每个神经元均使用相同的参数,因此,参数个数为(5*5+1)*6=156,其中5*5为卷积核参数,1为偏置参数。卷积后的图像大小为28*28,因此每个特征图有28*28个神经元,每个卷积核参数为(5*5+1)*6,该层的连接数为(5*5+1)*6*28*28=122304。
S2层(下采样层,也称池化层):6*14*14,这一层主要是做池化或者特征映射(特征降维),池化单元为2*2,因此,6个特征图的大小经池化后即变为14*14。S2层需要2*6=12个参数。下采样之后的图像大小为14*14,因此S2层的每个特征图有14*14个神经元,每个池化单元连接数为2*2+1(1为偏置量),因此,该层的连接数为(2*2+1)*14*14*6=5880。
C3层(卷积层):16*10*10,C3层有16个卷积核,卷积模板大小为5*5。与C1层的分析类似,C3层的特征图大小为(14-5+1)*(14-5+1)=10*10。此处,C3与S2并不是全连接而是部分连接,有些是C3连接到S2三层、有些四层、甚至达到6层,通过这种方式提取更多特征。C3层的参数数目为(5*5*3+1)*6+(5*5*4+1)*9+5*5*6+1=1516。卷积后的特征图大小为10*10,参数数量为1516,因此连接数为1516*10*10=151600。
S4(下采样层,也称池化层):16*5*5,池化单元大小为2*2,因此,该层与C3一样共有16个特征图,每个特征图的大小为5*5。所需要参数个数为16*2=32,连接数为(2*2+1)*5*5*16=2000
C5层(卷积层),该层有120个卷积核,每个卷积核的大小仍为5*5,因此有120个特征图。由于S4层的大小为5*5,而该层的卷积核大小也是5*5,因此特征图大小为(5-5+1)*(5-5+1)=1*1。这样该层就刚好变成了全连接。本层的参数数目为120*(5*5*16+1)=48120。由于该层的特征图大小刚好为1*1,因此连接数为48120*1*1=48120。
F6层(全连接层), F6层有84个单元,该层有84个特征图,特征图大小与C5一样都是1*1,与C5层全连接。参数数量为(120+1)*84=10164, 由于是全连接,连接数与参数数量一样,也是10164。
Output层也是全连接层,共有4个节点,代表四种类型的流量,分别为0-背景流量(Ground,Gnd)、1-Tor、2-Psi、3-Tun流量。由于是全连接,参数个数为84*10=840,连接数与参数个数一样,也是840。
4 实验结果分析
为了评估本文提出的针对匿名协议的加密流量识别模型的准确率,在实际网络环境中分别使用Tor、Psiphon和Wireguard软件产生实际的网络流量,并使用WireShark捕获数据包。为了符合实际网络环境中的流量情况,使用大量的正常流量作为背景流量进行实验,数据集的情况如表1所示。

表1 匿名协议和背景流量数据集
将以8:1:1的比将数据集分为3各部分,分别为训练集(train set)、验证集(validation set)和测试集(test set)。训练集用于学习样本数据,通过匹配一些参数来建立一个分类器;验证集用于调整分类器的参数;测试集用来测试训练好的模型的分辨能力(识别率等)。
使用测试集的数据一般会得到四类结果,分别是:
1)真正类(True Positive,TP):正确肯定的匹配数目(自身属于类别A被分类成类别A)。
2)假正类(False Positive,FP):误分,给出的匹配是不正确的(自身不属于类别A被分类为类别A)。
3)假负类(False Negative,FN):漏分,没有正确找到的匹配的数目(自身属于类别A却被分类为非类别A)。
4)真负类(True Negative,TN):正确拒绝的非匹配数目(自身不属于类别A被分类为非类别A)。
使用机器分类中的一般评价指标对实验结果进行评估,它们分别是:准确率(Accuracy)、精确率(Precision)和查全率(Recall)。
准确率代表被正确分类的样本占样本总数的比例,如式(4)所示。精确率代表被正确分类的本类样本占所有被分到该类样本数量的比例,如式(5)所示。查全率代表被正确分类的样本占所有应该被正确分类的样本的比例,如式(6)所示

(4)
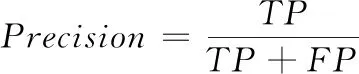
(5)
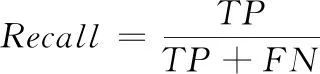
(6)
可以看出,精确率和查全率反映了分类器性能的两个方面,单一依靠某个指标并不能较为全面地评估分类器的性能。因此还需要精确率和查全率的综合指标F-score来评估性能,F-score的计算方法如式(7)所示
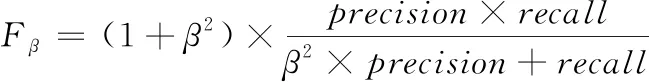
(7)
可以看出F-score是精确率和查全率的加权调和平均,当F-score较高时可以说明分类性能较好。取参数β=1,即认为精确率和查全率同等重要。
设置步长为16,即每次取出训练集中的16组数据并将顺序进行置乱,然后进行模型参数的训练,迭代200次以后,使用验证集的全部数据对得到的模型进行验证,随着迭代次数的不断增加,模型的准确率会不断增加并趋于稳定,同时,交叉熵损失(Loss,用来表示目标与预测值之间的差距)会逐渐变小并趋于稳定。为了得到最优的模型,将迭代次数设置为10000。训练过程的模型Loss值和Accuracy的变化过程如图4所示。
最终,使用训练过程得到的最优模型对测试集进行分类,得到图7所示的混淆矩阵。

图6 混淆矩阵
使用混淆矩阵可以计算得到如图7所示的各项评价指标。

图7 模型性能评估
其中,模型对于Wgd的识别效果最好,准确率达到了99.63%,F-score为98.87%,精确率和召回率分别为99.59%和98.16%;对于Psi,识别准确率为99.27%,F-score为95.42%,精确率和召回率分别为97.10%和93.80%;对于Tor,准确率为96.82%,F-score为89.11%,精确率和召回率分别为87.15%和91.17%,各项指标在三种流量中是最差的,说明Tor在背景流量中更不容易被识别出来。模型的总体准确率使用式(8)进行计算,最终得到总体的准确率为96.16%。

(8)
为了充分体现本文所提使用卷积神经网络的优越性,同样以23为窗口,提取了窗口内数据包的统计特征(如表3所示),利用决策树、SVM和随机森林的机器学习方法与本文得到的结果进行对比。

表2 统计特征
表3所示为各种识别方法的平均评价指标,从对比实验的结果可以看出,本文提出的将数据包序列转换为序列,结合卷积神经网络的方法,对匿名协议的加密流量具有很好的识别效果。无论从准确率,还是漏检率和误检率,性能都要优于普通的机器学习方法的检测结果。

表3 对比实验结果
5 结论
本文针对网络中的特殊加密流量——基于匿名协议的加密流量进行检测和识别,首先提出一种将数据包序列转为图像的方法,并利用卷积神经网络在图像识别方面的优势,自动提取窗口中数据包的特征,并进行模型的训练。经过实验证明,这种方法可以有效地从大的背景流量中有效的检测出匿名协议的加密流量。本文在较为理想的情况下讨论了在一个固定窗口中对流量进行检测的方法,但在真实环境中存在数据包缺失、乱序、单向数据流等多种复杂环境,窗口机制可能效果会有所下降,后续的工作将以单个数据包为单位进行加密流量的分析。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
计算机与数字工程(2022年3期)2022-04-07
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
电脑爱好者(2020年6期)2020-05-26
物联网技术(2018年8期)2018-12-06
中国计算机报(2018年30期)2018-11-12
课堂内外(小学版)(2017年5期)2017-06-07
中国新通信(2016年2期)2016-03-11
