
基于半稠密COLMAP自监督单目内窥镜深度估计
2021-11-16 11:18:56曹政涛黄文丰宁志刚廖祥云熊雪颖
南华大学学报(自然科学版) 2021年5期
曹政涛,黄文丰,宁志刚,廖祥云,熊雪颖,王 琼
(1.南华大学 电气工程学院,湖南 衡阳 421001; 2.中国科学院人机智能协同系统重点实验室,中国科学院 深圳先进技术研究院,广东 深圳 518055; 3.武汉大学中南医院 医学影像科, 湖北 武汉 473001)
0 引 言
由于内窥镜微创手术具有伤口小、出血量少、好愈合、住院时间短等优点,已经被广泛应用于肝胆外科、耳鼻喉科等多种手术类型中[1-2]。然而内窥镜手术场景存在一些缺陷,如视野受限、深度信息丢失、手术自由度低等,对于其中一些问题可以通过训练医生手术技巧来解决,但对于内窥镜影像下深度的认识却很难通过经验判断来得到精确的位置,于是很多学者开始着手于内窥镜场景下深度估计方法研究[3-5],并在微创手术导航系统中得以应用[6-8]。内窥镜微创手术可以利用手术导航系统构建内窥镜手术场景信息,帮助医生快速定位病变组织,避免误触碰人体关键结构从而可以减少手术时间,降低手术风险。
人体微创手术的内窥镜类型分为:单目内窥镜[9]、双目内窥镜[10]、结构光内窥镜[11]。双目内窥镜和结构光内窥镜复杂度高、体积大,在人体内使用不便,因此,单目内窥镜仍是临床上最常用的内窥镜。目前在单目内窥镜场景下的深度估计方法可以分为传统的单目视觉算法和基于深度学习的方法。基于单目视觉算法,如同时定位与地图映射(simultaneous localization and mapping, SLAM)[12]和运动恢复结构(structure from motion, SFM)[13]等技术。SFM和SLAM将同一视频序列或不同角度的图像序列作为输入,然后利用特征匹配和三角测量方法计算图像深度和摄像机运动。由于不需要额外适配其他硬件设备且成本低廉,这些方法已经被广泛关注和研究,并且在胃镜、腹腔镜等多种内窥镜场景下实现了跟踪和三维重建[14-16],然而内窥镜图像中的特征缺乏会导致这些方法产生稀疏和不均匀的重建。为了解决稀疏重建的问题,文献[17]将视觉SLAM技术与激光扫描技术结合的方法用于稠密的人体组织重建,但是该方法重建的结果失去了很多细节信息,无法反应组织表面特性。
基于深度学习的方法按照监督形式可以分为完全监督型学习方法和无监督型学习方法。虽然完全监督型网络在一般场景可以得到较好的深度信息[18-20],然而在内窥镜场景下使用该方法是非常困难的。这是因为在人体内无法像一般场景一样通过额外的硬件设备来获取真实的深度图。文献[21]为了解决这个问题使用数字合成和电子计算机断层扫描(computed tomograph,CT)渲染的方式生成相应的真实深度图,然而这种方法需要提供病人的CT数据,此外模拟的图像可能会失去图像原有的细节纹理,这对于本来就纹理稀疏的人体组织并不适用。由于有监督学习方法的局限性,近几年,无监督学习方法也得到了广泛的关注。X.Liu等[4]根据传统SFM具有光照不变特性提出自监督方法很好地解决了缺乏真实深度标签和光照变化问题,并在鼻腔视频的实验中取得了很好的效果。然而对于腹腔镜场景下,一些较大肝脏器官,其组织表面纹理稀疏、深度变化不明显,SFM只能产生有限的监督数据。H.Luo等[22]提出了一种融合传统立体先验知识的无监督学习深度估计方法,以传统的立体方法生成深度标签,并结合卷积网络生成左右视差图,通过左右视差图构建视差一致性损失函数,但该方法只适用于双目内窥镜深度估计。岑仕杰[23]等使用位姿估计网络提供无监督数据结合双重注意力模块对自然场景进行单目深度估计,然而该方法在位姿估计方面的性能不佳,错误的位姿估计将导致三维重建不准确。
根据以上问题的分析,本文提出基于增量式SFM原理的半稠密COLMAP重建方法[24]来获取监督数据,采用具有动态卷积机制的SKNet (selective kernel networks,SKNet) 模型构建自监督单目内窥镜深度估计网络模型。该方法既可以很好地解决监督数据不足的问题,又可以增强训练网络对一些纹理稀疏和深度信息变化不明显的区域的特征提取能力。本文提出的创新点如下:
1)采用半稠密COLMAP方法解决监督数据不足的问题,同时引入加权可靠度抑制和丢弃一些离群的3D点,相比于稠密的COLMAP重建方法,该方法并没有引入过多的异常点,也不用手动对重建结果进行修饰;
2)在完全卷积网络(fully convolutional DenseNets,FC-DenseNet)中加入了具有注意力机制的SKNet模型,输入SKNet模型中的特征图根据不同大小的卷积核动态分配其输出的特征图的权值,实现动态提取不同感受野下的特征信息。
1 单目内窥镜深度估计模型
1.1 模型概述
本文提出的基于改进的半稠密COLMAP与卷积神经网络相结合的自监督单目估计方法,改进了自监督数据,不需要额外提供任何真实的深度标签。整个系统的内窥镜深度估计流程图如图1所示,首先进入图像预处理阶段,将同一视频序列图像送入COLMAP中进行图像预处理,将重建点云进行投影变换得到半稠密深度图,之后对半稠密深度图进行加权处理,去除和抑制一些离群的深度值。在网络训练阶段,加入SKNet模型,提高网络的特征提取能力,在应用阶段,只需单帧图像就可以得到对应图像的密集深度图。
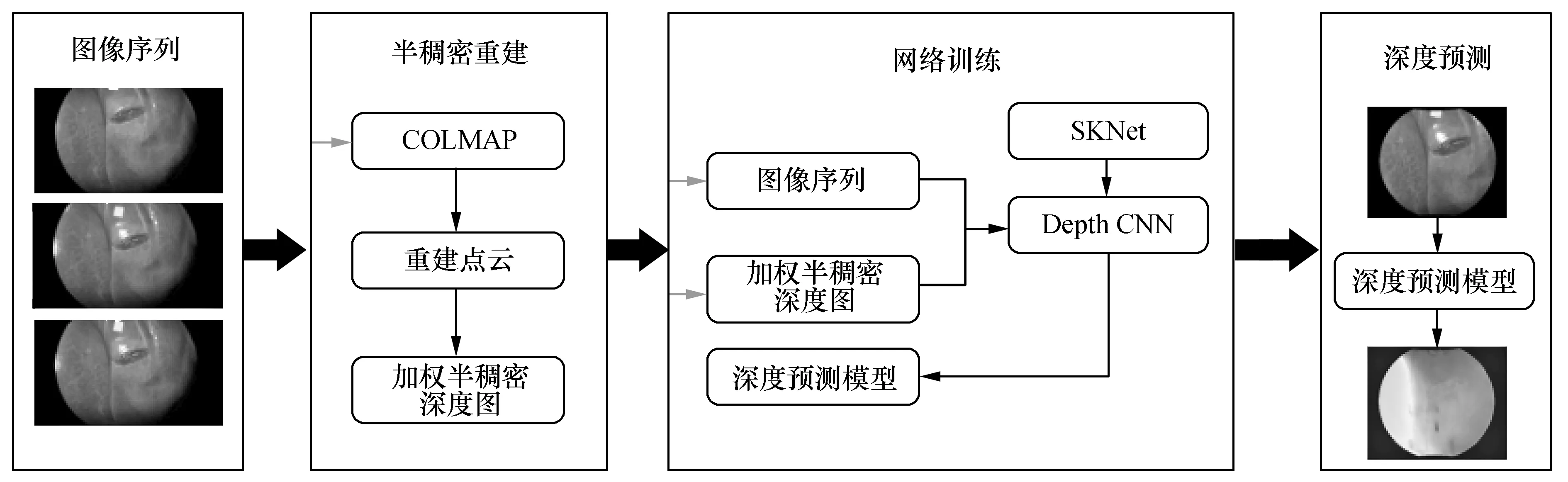
图1 单目内窥镜深度估计框架图Fig.1 Monocular endoscope depth estimation frame diagram
1.2 加权半稠密深度图
COLMAP是基于增量式SFM方法的全局重建方法,该方法只需输入图像、相机内参、匹配方法便可生成3D点云。COLMAP可以进行稀疏重建和稠密重建,但这两种方法产生的深度图都无法较好地用于深度估计。稀疏重建产生的点云数据较少,只能得到稀疏深度图。COLMAP稠密重建是在SFM稀疏重建的基础上进行了深度图的融合,虽然得到的是稠密重建,但是也引入了大量的干扰点和错误点,并且丢失了每个3D点与图像帧的对应关系。根据肝脏表面特征稀疏的特点,对COLMAP稀疏重建进行了改进,在特征提取和匹配时降低了特征提取和匹配的阈值,使其匹配到的特征点多于之前的N倍,再对引入的干扰点进行丢弃和抑制操作。加权半稠密深度图生成过程如图2所示,首先调整COLMAP稀疏重建在特征提取和匹配时的阈值,再将内窥镜视频帧送入COLMAP中进行特征提取与匹配,然后利用已知的相机内参和匹配的特征点进行半稠密重建即可得到点云数据、相机位姿、3D点与2D图像的对应关系。最后对3D点进行可靠度评估,对干扰点进行抑制或丢弃,并投影映射得到加权半稠密深度图,3D点与2D图像的对应关系是指3D点可以由哪些图像帧重建出来。

图2 生成加权半稠密深度图流程图Fig.2 Generate weighted semi-dense depth map generation pipeline

(1)
其中,Wj是表示加权可靠度,为了减少半稠密重建中的异常点对有效区域的深度值的影响,对每个有效区域的深度值进行了加权处理,帧j的深度值加权可靠度Wj定义为:
(2)
其中,α表示用于重建的3D点的平均帧数,w表示每个点用于重建的帧数,∂1,∂2是给定的超参数。当w∈(∂2,+∞)时,则认为该点绝对可靠。当w∈(∂1,∂2)时,mn是用于表示重建3D点n投影到2D位置的累积视差的权重,mn越大,反映可靠度越高。当w∈(0,∂1)时,表示使用COLMAP得到的3D点云中,存在一些3D点与其相关的图像帧过少,认为该点是离群点,需要对其进行丢弃。
1.3 网络结构
1.3.1 自监督方法


图3 网络训练总体流程图Fig.3 Overall flowchart of network training
1.3.2 SK-FCDenseNet网络
FC-DenseNet网络[25]是由一条下采样路径、一条上采样路径和跳跃连接组成,跳跃连接通过重用特征图来帮助上采样路径恢复空间细节信息。SKNet考虑到了分路卷积的权重,能够使产生不同感受野的卷积核进行动态卷积。本文结合两者的优点提出了SK-FCDenseNet网络,该网络结构如图4所示。使用了FC-DenseNet57层网络架构,在下采样阶段和上采样阶段都加入了SKNet模块,SKNet可以根据不同的特征图大小动态的分配卷积分路的权重,实现了让网络自己选择合适的卷积核的操作。下采样包含5个DB+TD+SK阶段层,上采样同样也包含5个TU+SK+DB阶段层,为了使网络输出适合深度预测任务,上采样阶段,将最后一卷积层通道数改为1,激活函数改为线性激活函数。
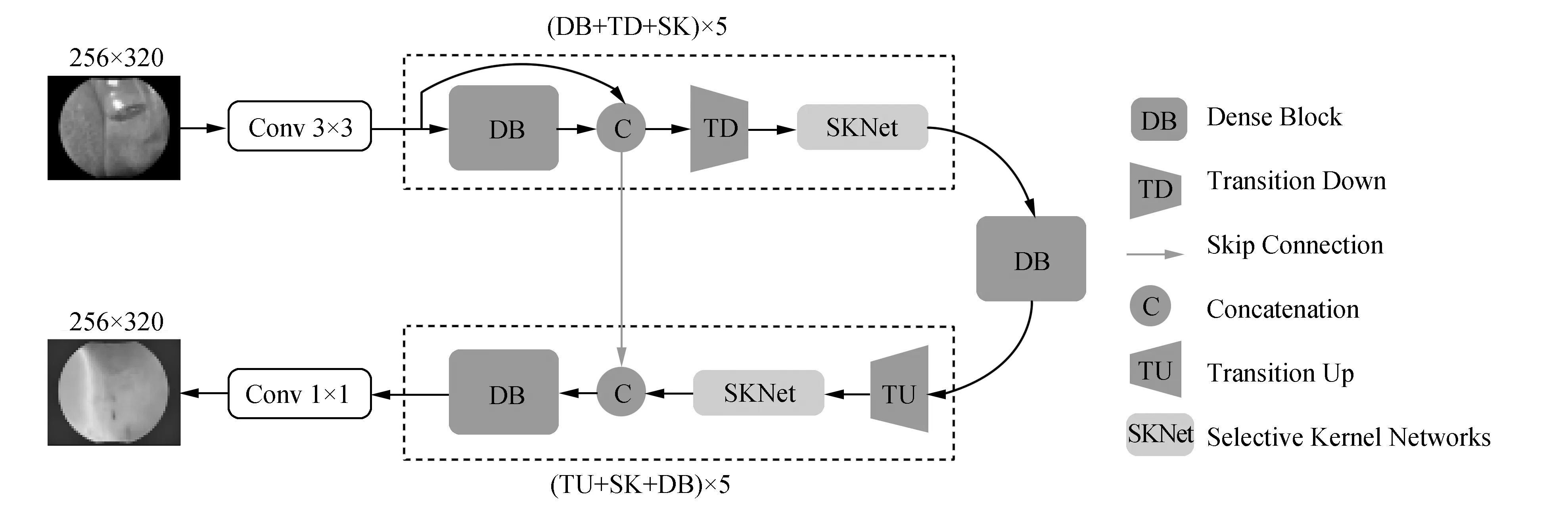
图4 SK-FCDenseNet网络图Fig.4 SK-FCDenseNet network
1.3.3 双分支SKNet模型
本文引入双分支SKNet模型[26],如图5所示,首先将下采样的特征图X分别通过3×3的卷积和3×3的空洞的卷积(空洞卷积的感受野是5×5)得到U1和U2特征图,然后将两特征图相加得U。U通过全局池化操作和全连接操作相继得到c×1×1和z×1×1的特征向量,c×1×1维的特征向量表示特征通道的重要程度。输出的是两个矩阵a和b,其中矩阵b是冗余矩阵,在两分支的情况下b=1-a,经过softmax变换得到f1和f2,将这两个值与U1、U2对应相乘得到A1、A2模块,最后将两模块相加进行信息融合得到A模块,模块A相比于最初的X经过了信息的提炼,融合了多个感受野的信息。由于f1和f2相加等于1,因此能够实现对分支中的特征图设置权重,因为不同的分支卷积核尺寸不同,因此实现了让网络自己选择合适的卷积核,此外使用空洞卷积实现了在不增加参数量的情况下增大了卷积核的感受野。这种增加多个感受野的方法可以增加提取有效信息的方式,对一些纹理稀疏的肝脏表面有很好的特征提取效果。

图5 双分支SKNet模型Fig.5 Two-branch SKNet model
1.4 损失函数
本文采用了两种损失函数,首先选用类似于L2范数的函数作为网络的损失函数,用以约束加权半稠密深度图和预测深度图之间的像素差异来监督训练,由于只计算半稠密深度图中的有效深度值,所以该损失函数叫有效深度损失函数,该损失函数定义如下:
(3)
其中,Mx是稀疏掩膜,用来忽略训练数据中没有深度的区域,N表示有效的像素总数。Mx定义为:
(4)
其中,x表示图像帧j或图像帧k。
由于使用半稠密深度图存在一些无效的像素点,为了得到稠密的深度图,使用了与文献[4]相似的深度差值损失函数。在同一视频序列,有足够重叠的帧j和帧k,利用两帧之间的几何约束性可以补偿两个深度图之间的差异性。深度差值损失的定义为:
(5)
总体损失,网络的总损失函数如下图所示,是两种损失函数的加权组合:
L=λ1Ledl+λ2Ldcl
(6)
2 实验结果与分析
2.1 实验环境与数据集采集
实验的软件环境为Ubuntu18.04操作系统,该方法是PyTorch实现的。实验的硬件配置主要包括GPU GeForce GTX1080Ti和Intel Xeon CPU E5-2637。COLMAP稀疏重建阶段是在CPU上进行的,网络训练阶段是在图形处理器(graphics processing unit,GPU)上进行的。
本文通过离体猪肝的内窥镜视频数据集验证算法的有效性和可行性。为了模拟人体环境,在数据采集时通过封箱模拟腹部黑暗环境,将内窥镜摄像头插入箱中拍摄视频,数据采集环境如图6(a)、(b)所示。猪肝脏可分为尾状叶、右叶、中右叶、中左叶和左叶,为了证明本算法的通用性,对不同区域的猪肝脏都进行了数据的采集,为了区分不同部位的猪肝脏影像,在数据采集时对猪肝脏的每个区域都进了标记。本文对4个猪肝脏进行了猪肝脏影像采集,经过后期筛选,每个猪肝脏每个区域有5到10组视频,每组视频长度为20 s左右,每秒帧数为60帧,其中1到2组用于测试,其余用于实验,经将采用处理的视频帧大约共采集64 000张图像。
如图6所示,(c)、(d)展示了猪肝脏的左叶区域的COLMAP重建,为增大相机移动位姿,减轻COLMAP重建压力,将视频帧降采样为每秒20帧。图中展示的图像序列为423张,在稀疏重建时,特征匹配点约为19万个,3D点约为1.5万个,进行半稠密重建时特征匹配点约为80万个,3D点约为6万个。COLMAP重建和生成加权半稠密深度图阶段每次只能处理一组视频,网络训练阶段,将预处理得到的监督数据按分组一同参与训练。
2.2 实验参数设置
为了检测算法的鲁棒性,在训练过程中,采用了一些数据增强的方法,其中包括高斯噪声、高斯模糊、随机伽马、随机HSV(hue,saturation,value)偏移、随机亮度、随机对比度等。网络参数采用K.He等[27]提出的初始化方法。损失函数采用随机梯度下降法来收敛损失函数,并且动态设置学习率从1×10-3到1×10-4。两帧之间的范围是2到20,训练送入视频帧的批次大小是 4。控制加权可靠度的参数∂1,∂2为5和20。有效深度损失函数权值设置为5,深度差值损失函数在前20批次中权值设置为0.1,后80个批次权值设置为5,这样做的目的是先使用有效深度快速拟合加权半稠密深度图与预测深度图之间的有效深度值,待函数收敛到一定程度,再对一定范围内两帧之间深度图进行约束,互相弥补一些缺失的像素点。
2.3 实验结果与对比分析
为了展示算法的可行性与实验结果的可靠性,采用了三种实验对比方法。第一种,通过深度预测模型对测试图像进行深度预测,生成预测深度图和点云数据,之后将点云数据进行三维可视化,并通过不同角度展示重建结果。第二种,和已经在该内窥镜深度估计领域取得较好结果的算法[4]进行实验对比,通过对比深度图、三维重建图来说明本算法的可行性及优越性。第三种,通过进行消融实验,来判断半稠密重建、加权半稠密深度图以及SKNet模块的有效性。由于本文算法没有使用到任何标记过的深度标签,所以在评估预测深度与真实深度之间的差异时,以稀疏深度图和加权半稠密深度图为真实深度图,并仅在有效的像素位置和深度预测中的对应位置上进行评估度量。在误差分析方面采用绝对相对误差(absolute relative error):
(7)
准确率是满足如下不同阈值条件下的百分比:
(8)

本文通过深度预测模型对2个猪肝脏的四个不同的部分进行了深度预测,并对预测结果进行了三维可视化,其中可视化结果如图7所示。图中第一列是原图,第二列到第五列表示重建结果不同角度的展示,从图中可以看出,除边缘和个别区域外,重建结果基本上还原了图像的三维信息。
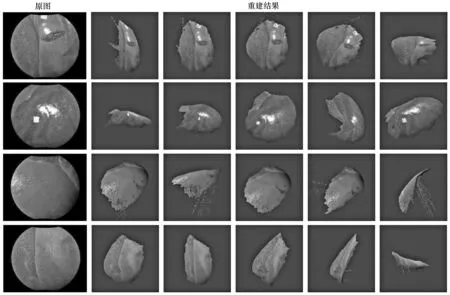
图7 从不同角度展示猪肝脏的重建结果Fig.7 The reconstruction results of pig liver showed from different angles
与X.Liu等[4]从预测深度图和三维重建进行对比研究,如图8所示,采用来自同一视频序列的图像对深度预测模型进行测试。为了评估本文训练方法的有效性,跟X.Liu等人使用了相同的预处理方法,并且对稀疏COLMAP和半稠密COLMAP的方式都做了实验,图中第一列由训练图像组成,第二列和第三列是X.Liu等人以稀疏深度图为监督信号预测的深度图和三维重建结果,第四列和第五列是X.Liu等人以半稠密深度图为监督信号预测的深度图和三维重建结果,第六列和第七列是通过本方法提出的加权半稠密深度图作为监督信号得到的预测深度图和三维重建结果。

图8 本方法与X.Liu等人的实验结果对比Fig.8 Comparison of this method with the experimental results of X.Liu et al
由图8中(a)~(d)组可知对于表面稀疏、深度变化不明显的肝脏区域,稀疏COLMAP提取到的特征点不足以达到深度预测的要求,预测深度图不能很好地表现出深度变化的情况,对应的三维重建会有明显的压缩和呈现二维平面的情况。X.Liu等人的方法和本文的方法在使用半稠密COLMAP方式都取得了不错的效果。由图8中(e)~(g)组可知,X.Liu等人的方法从半稠密COLMAP方式中虽然可以获取更多有效的监督数据,但是对引入而来的干扰点控制不足,在深度图的右下角区域出现了深度过低的情况,造成了三维重建结果右下角拉伸和凹陷,此外,对于左边区域出现了深度值过高并且延伸的情况,最终导致三维重建结果畸变严重。而本文使用的SKNet模块拥有不同的感受野,可以获取更多特征信息,避免了过渡关注某一区域的信息,此外本文提出的加权可靠度可以有效的减少COLMAP重建中离群的3D点对预测深度图的影响。
如表1所示,对本文方法有无SKNet模型的情况以及X.Liu等[4]的方法都做了评估度量实验,从表中可以看出,不管是稀疏COLMAP重建还是半稠密COLMAP重建,引入SKNet模型深度估计效果都会有所提升,并且本方法的误差率和准确率都要好于X.Liu等[4]的方法。
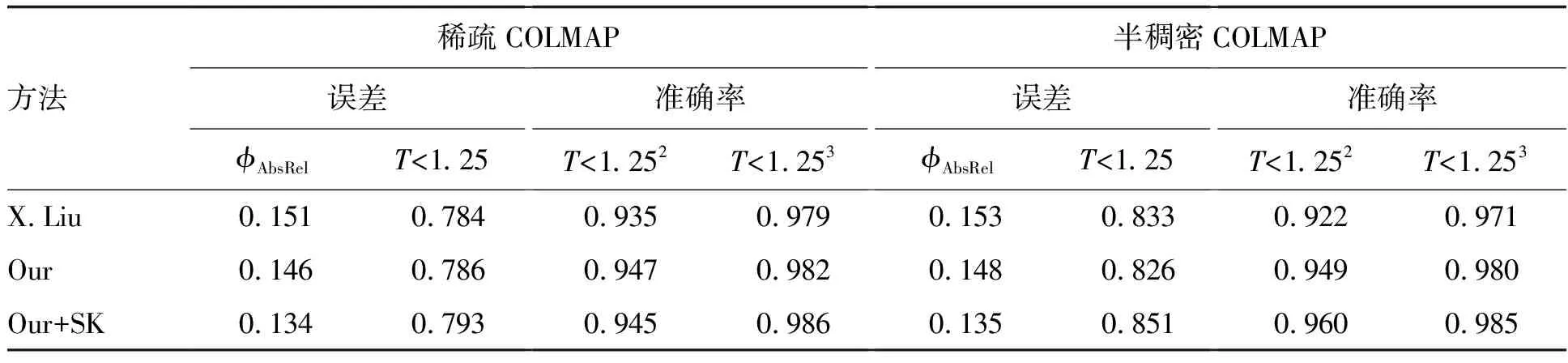
表1 实验误差和准确率对比Table 1 Comparison of experimental error and accuracy
为了证明加权可靠度去除干扰点的有效性,对加权可靠度进行消融实验,在控制其他实验条件不变的情况下仅改变加权可靠度Wj的有无。实验结果如图9所示,由于COLMAP处理阶段放宽了特征提取和匹配的限制,引入了一些离群点,造成了某些区域深度预测出错,如图第二列和第三列标注所示,在加入加权可靠度的情况下丢弃了这些异常点,预测深度图和三维重建结果得到了明显的改善。

图9 加权可靠度实验结果对比Fig.9 Comparison of weighted reliability experiment results
3 结 论
本文提出了一种基于半稠密COLMAP及动态注意力机制的单目内窥镜自监督深度估计方法。以COLMAP产生的半稠密深度图作为监督信号,解决监督数据不足的问题,加入了加权可靠度抑制干扰点对结果的影响干扰点。在特征提取阶段引入SKNet模型,在增加了少许参数量的前提下,增强了一些低纹理区域特征提取的能力。实验结果表明,对肝脏数据集实验中,本方法取得了较好结果,并通过消融实验证明了各个模块的有效性。在下一步工作中,将本方法应用于内窥镜手术导航系统中,实现实时的3D重建。
猜你喜欢
现代仪器与医疗(2022年1期)2022-04-19 13:52:04
现代仪器与医疗(2021年6期)2022-01-18 03:22:50
现代仪器与医疗(2021年4期)2021-11-05 08:25:30
计算机应用(2019年3期)2019-07-31 12:14:01
中国惯性技术学报(2019年1期)2019-05-21 00:58:30
北京航空航天大学学报(2017年4期)2017-11-23 05:48:16
软件导刊(2016年9期)2016-11-07 22:22:57
光学精密工程(2016年4期)2016-11-07 09:05:11
科技视界(2016年2期)2016-03-30 11:17:03
机械工程师(2015年10期)2015-02-02 01:13:47
