
基于大数据理论的燃煤机组性能优化关键技术研究*
2021-11-16 08:25王涛吴强
数字技术与应用 2021年9期
王涛 吴强
(绍兴文理学院计算机科学与工程系,浙江绍兴 312000)
0 引言
极端天气频现表示地球环境已达到某种临界状态,环境污染和各方面的能耗是造成极端天气的主要原因。各个行业的节能减排迫在眉睫。大型燃煤机组的性能改善对节能减排具有十分重要的研究意义。
本文以某火电厂1000MW超超临界燃煤机组大量的运行数据为原始分析资源[1],该机组标准输入输出设计点近20000个,33000多个数据库标签,机组运转中的监测点6500多个,实时产生大量的数据。通过大数据分析技术,对燃煤机组运行过程中的众多参数指标进行分析挖掘,通过模糊粗糙集对各项能耗指标约简后[2-3],得到对燃煤性能有重要影响的多个指标。经过模糊C 均值聚类算法分析[4-5],准确将重要属性划分成不同的类别,同时计算各属性指标的模糊隶属度。这些数据挖掘分析处理能客观清晰、全面有效地描述燃煤机组能耗特性的指标数据,对优化改善燃煤机组的性能有重要的意义。
1 相关理论
聚类分析可将燃煤机组的各项性能指标分类成各个子集,每个性能指标子集作为一个单独的簇,这些性能指标对燃煤机组的影响程度近似。而不同子集对于燃煤机组性能影响较大。
1.1 模糊粗糙集应用于燃煤机组各项能耗指标属性的约简
模糊集是美国专家L.A Zadeh于1965年提出的数学理论[6]。该理论把方法与对象作为一种模糊集合,建立不同的隶属函数,采用相关运算对数据进行分析。粗糙集理论是波兰科学家Z.pawlak在1982年提出的解决不确定性问题的数学方法[7]。核心思想是在保证原有分类效率的条件下,借助知识约简,求解分类规则。属性约简是粗糙集理论的重要组成部分[8]。广泛应用于数据挖掘、智能决策等领域。
大型燃煤机组的运转时刻产生大量的各方面的指标数据,这些数据受到环境温度湿度的改变、煤质的变化甚至水温的变化而产生很多不确定性。因此,针对如此繁杂、不确定性的数据采用模糊粗糙集理论来处理从而提取相关重要指标参数就显得尤为重要[9-10]。
燃煤发电机组性能指标相关的数据项目非常繁杂,每一项指标对于节能优化的重要性不同,在节能分析时需要剔除部分不重要的指标,重点分析对燃煤发电性能影响较大的指标。这需要对属性进行约简。为了实现属性约简,本文尝试采用模糊粗糙集算法来实现并进行最终燃煤机组各项指标的对比。属性约简的目的是减少计算的复杂度,约简的原则是约简前后属性值所包含的燃煤信息不能丢失。要保持信息的贴近度。下面对贴近度的定义说明。
定义1:
设映射关系M:F(X)×F(X)→[0,1]满足如下这些约束:
(1)对属于F(X)的任意A,满足M(A,A)=1;
(2)对属于F(X)任意A,B,满足M(A,B)=M(B,A);
(3)如果对属于F(X)的任意A,B,C,属于X的任意x,满足:
|(A(x)-C(x))|≥|A(x)-B(x) |
那么存在M(A,C)≤M(A,B)。称呼映射M是F(X)上的近度,定义M(A,B)为A和B的贴近度。
定义2:
设(U,R)为一个模糊系统,即R属于U范围内的自反的模糊关系。
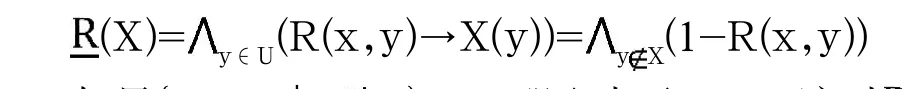
如果{x∈U│x X}= ,那么表示X=U,这时 (U)(x)≡1,即 (U)=U。
依据定义1和定义2,设计了如下模糊属性指标决策表的约简算法。
算法:首先,化简R= ,接着把使γR∪{ai}(d)取得最大值的指标ai添加到约简R之中,当γR(d)/γA(d)的值高于某个事先预设的阈值,此时输出这个决策表的一个约简项R。
算法输入:模糊决策表(U,A,d),其中A={a1,a2,…,an},阈值设定为λ。
算法输出:A的约简R。
(1)令R= ;(2)对于属于A-R的任意ai,计算当γR∪{ai}(d)取最大值时的ai,且让R=R∪{ai};(3)假如λAR=γR(d)/γA(d)≥λ,表示R就是所求。不然跳往第二步继续求解。
在燃煤机组各项能耗指标初步分析的基础上,建立能耗参数决策表。并对其进行简单的预处理,确定各项指标的模糊相似度,同时选择合理的模糊算子对下近似值进行求解。依据下近似求解参数贴近度,定量分析各指标的重要度。
根据模糊粗糙集的属性表项目约简算法,对大型燃煤机组影响能耗的重要指标参数进行分析,可用图表形式划分为如图1所示。
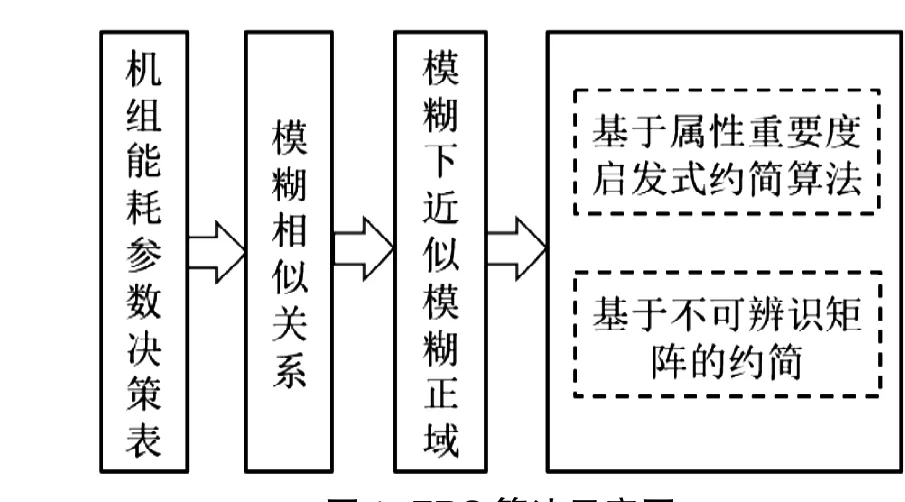
图1 FRS 算法示意图Fig.1 Schematic diagram of FRS algorithm
1.2 模糊C均值聚类应用于燃煤机组各项能耗指标属性的分类
FCM(Fuzzy C Mean,模糊C均值聚类)算法是由Bezkek于1981年提出的。是众多模糊聚类算法中算法效率较高且被广泛采用的算法之一。能实现各个样本对于各种聚类的隶属度。FCM算法是两个算法的精髓融合,由两部分构成: 一部分是模糊理论, 另一部分是算法C/Kmean。与硬聚类算法k-means相比较,模糊C均值聚类的结果更加灵活多变。可以在无监督环境中分析出数据的分布情况,根据众多样本相似度的不同,将其聚合到多个不同的集合,聚合为有限的几个集合。
FCM算法步骤如下:
(1)初始化U=[uij]矩阵,U(0);
(2)在k步:计算质心。

(4)如果||U(k+1)-Uk||<ε则终止;否则执行第2步。
模糊C 均值聚类算法在将样本数据分成有限数量部分的同时,还可以依据上述定义2中计算出的隶属度定量计算出各个样本属于不同类别的数量上的指标。从而保证燃煤机组的性能指标在分类后保证类内的相似性比较大,而类之间的耦合度相对较低。
2 实验结果及分析
本文选取某火电厂6号的1000MW超临界燃煤机组2020年10月5日至2020年12月5日合计60天的发电运转数据。该大型燃煤机组的主要参数如表1所示[11]:

表1 燃煤机组参数表Tab.1 Parameter table of coal-fired unit
将采集的大量稳态性质的数据项分为6组数据集。如表2所示。具体包含数据项的采用时间、负荷段、样本数量和特征变量数。

表2 采集数据集描述Tab.2 Collection dataset description
表3 所示中的优化前后的数据对比分析:本次优化前、后额定负荷下的高压缸效率为89.78%、89.88%,中压缸效率为92.95%、93.11%,从数据上看该文选择的算法对于燃煤机组性能的优化还是具有一定的提示效果。

表3 各项指标对比Tab.3 Comparison of various indicators
3 结语
本文首先介绍了研究的背景及借助的燃煤机组状况,接着分析了模糊粗糙集算法和模糊C均值聚类算法的算法思路及应用方法。采用模糊粗糙集算法对燃煤机组的各项指标数据进行数据指标的约简,同时保证数据的信息量不变,以保证数据分析的正确性和高效率。然后采用模糊C均值聚类算法对样本所属的类别进行分门别类的处理。根据得出的模糊隶属度数据详细描述各个样本所属类别程度的大小。因此能最大限度的保证获取具备相似度最大的各种簇内样本,且各个不一样的簇间存在最小的相似度。最后,采用基于模糊粗糙集和模糊C均值聚类算法对大型燃煤机组的各项指标数据进行分析挖掘,在燃煤机组各项指标数据信息完整保存的条件下,针对大型燃煤机组的性能有重要影响的指标数据进行了高效率压缩处理。通过某火电厂1000MW超临界机组的数据验证分析,该算法组合具备高效、动态优化等优点。
猜你喜欢
成都信息工程大学学报(2019年2期)2019-08-28
自动化学报(2018年2期)2018-04-12
上海大中型电机(2017年3期)2017-11-13
成都信息工程大学学报(2017年1期)2017-07-21
厦门理工学院学报(2016年3期)2016-11-10
广东石油化工学院学报(2016年3期)2016-05-17
通信电源技术(2016年3期)2016-03-26
中国资源综合利用(2016年1期)2016-02-03
上海节能(2015年10期)2015-12-20
四川师范大学学报(自然科学版)(2015年1期)2015-02-28
