
基于R-VGG和多分支注意力的无人机图像配准模型
2021-11-15 08:25赵亚丽蔺素珍张海松李大威雷海卫
中北大学学报(自然科学版) 2021年5期
赵亚丽,蔺素珍,张海松,李大威,雷海卫
(中北大学 大数据学院,山西 太原 030051)
0 引 言
目前,利用多台无人机协作或单台无人机多次拍摄已经成为地质勘测[1]和安全巡检等大视场成像的新兴手段,其中图像配准是必不可少的关键技术之一.图像配准方法包括基于灰度的配准方法和基于特征的配准方法两大类[2].其中,基于灰度的方法通过灰度值计算完成图像配准,该方法简单直观,但计算量较大且对图像灰度值敏感,图像的光照变化、尺度变化和旋转变化等都会造成较大的匹配误差;基于特征的配准方法通过提取并匹配图像间共有的特征来解算变换参数得到配准结果,该类方法鲁棒性好且效率较高.不同无人机图像间的光照、倾角等往往大相径庭,因而使用基于特征的配准方法更合适.
基于特征的图像配准方法可细分为传统方法和基于学习的方法.典型的传统方法是D.G.Lower等[3]提出的SIFT(Scale Invariant Feature Transform)算法.该算法通过提取尺度、缩放和旋转不变性特征进行配准,性能稳定但算法复杂度高,对错误匹配数据较敏感.虽然之后产生了一系列针对该算法的优化算法[4-5],但总体都有一定的场景约束且计算效率不高.
近年来,深度学习方法在图像领域显示出卓越的性能[6-8],许多研究人员使用卷积神经网络(Convolutional Neural Networks,CNN)等深度学习方法来解决图像配准问题[9-11].为解决深度学习中的标签图像缺乏问题,有学者探索了无监督学习配准方法.VoxelMorph[12]方法在脑部数据集上取得了不错的效果;VTN(Volume Tweening Network)[13]采用了集成仿射变换模块和网络块级联方式,在存在较大变形的医学图像配准方面取得了成功;文献[14]利用光度损失的无监督学习来进行单应性估计;文献[15]在特征提取之后增加掩膜结构来学习图像的深度信息,从而进行更精确的单应性估计,等等.综合看来,基于深度学习方法配准图像渐成主流.不过,由于无人机航拍的图像通常分辨率较大且存在大面积的弱纹理区域,容易导致特征误匹配,从而使配准精度下降,因此,目前将深度学习模型用于无人机图像配准的研究还较少.
本文提出一种基于无监督学习的无人机图像配准方法,该方法在训练过程中仅需要待配准的图像对,不需要任何的真实变换参数.与其他方法研究相比,本文的主要工作有三点:1)提出一种R-VGG的特征提取网络结构,在VGG结构中加入Resnet的思想,充分利用深度学习的高性能有效地把图像的低层轮廓特征和高级语义特征结合起来,提取到更加鲁棒的特征.2)提出在初步特征匹配之后加入以残差单元为单位的多分支注意力模块,滤除误匹配,增加匹配的精确度.3)复合使用均方误差损失和感知损失,确保配准的精度和配准结果图像的质量.
1 无监督配准网络模型
1.1 框架综述
本文提出的完全无监督无人机图像配准方法流程如图1 所示.首先,将经过预处理的参考图像和运动图像分别输入到两个网络结构相同且共享参数的特征提取模块(R-VGG)中进行深度特征提取;其次,将提取到的特征完成初步匹配,再采用具有两个平行分支的注意力模块(MBA)滤除特征误匹配;然后将经过加权约束的匹配相关图传输到单应性矩阵估计模块中,进行神经网络回归运算得到空间变换参数;最后,通过空间转换网络(Spatial Transform Network,STN)[16]得到配准结果图像.网络模型的损失函数使用配准结果图像和参考图像的相似性来构建.
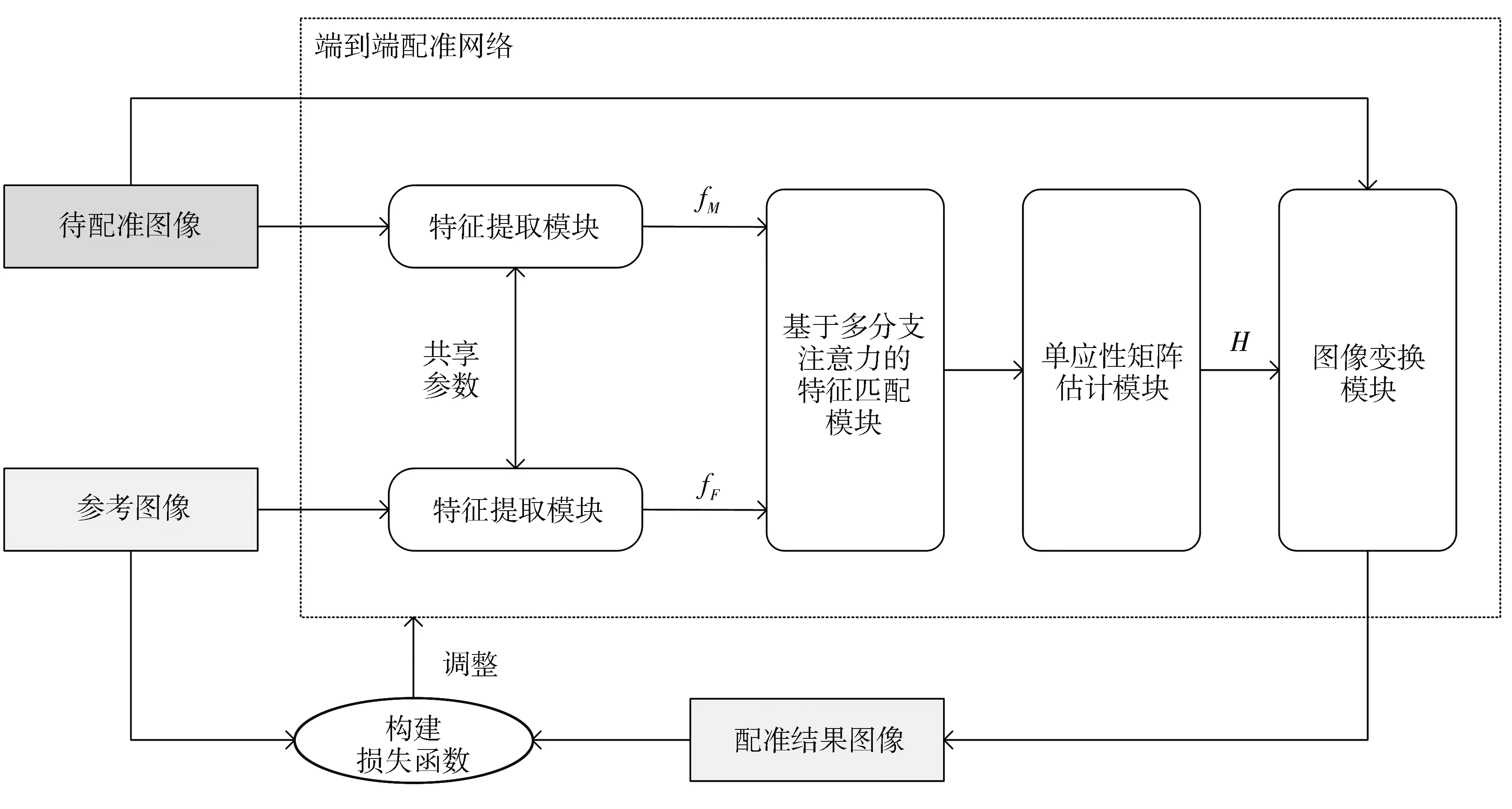
图1 本文方法的整体框架图Fig.1 The overall framework of the proposed method
1.2 网络设计
1.2.1 特征提取模块设计
特征提取模块设计作为本文配准模型设计的第一步,主要是利用深度学习的高性能来提取待配准图像对的高级特征信息,从而进行稳健高效的特征对齐.鉴于VGG-16网络在ImageNet上表现出的卓越性能,这里使用VGG-16网络结构的前面部分来提取特征.但VGG结构没有分支结构,在浅层网络部分提取的是图像的低层轮廓特征,而在深层网络部分筛选出高级的细节信息,只是简单地堆叠网络不能把低、高层特征结合起来,因此,使用简单的VGG网络结构不能有效地提取到利于图像配准的特征.而ResNet结构能把上一层的输出作用于下一层,可以将低层的轮廓特征和高层的语义特征融合,但ResNet系列的网络深度较深,结构复杂,而无人机图像的配准任务需要较为简单的模型来保证运算效率.因此,本文把ResNet思想和VGG网络结构结合起来,既能筛选出配准需要的低、高级融合特征,又能保证网络结构相对简单,具体网络结构如图2 所示.

图2 特征提取网络结构图Fig.2 Feature extraction network structure diagram
输入分辨率为H×W的图像,首先经过两次卷积核大小为3,通道数为64的卷积得到conv1;对conv1进行池化操作使图像分辨率成为原图像的1/2,以降低维度;对池化结果pool1使用1×1卷积增加通道数到128得到r1;对r1进行两次卷积核大小为3,步长为1,通道数为128的卷积得到conv2;将r1与conv2在通道维度上相加,这样便将上一层的输出作用到下一层,达到特征融合的效果.之后的网络结构依此类推,卷积的通道数分别为256,512,分辨率分别为原图像的1/4,1/8,每个卷积层之后跟随修正线性单元(Relu),在每一次池化后都进行1×1卷积,将结果作用于下一层,网络截止至pool4,最后对特征图进行L2标准化.
1.2.2 基于多分支注意力的特征匹配模块设计
特征匹配层用来计算运动图像特征图fM和参考图像特征图fF的局部描述符之间的所有相似性对.利用相关层可以实现初步的特征匹配[7],但由于无人机图像中存在大面积的弱纹理区域(如水域,天空等),在特征匹配阶段容易造成错误的特征匹配,因此,本文加入多分支注意力模块来过滤错误的特征匹配,以增强对模型异常值的鲁棒性.
初始匹配部分相关层以两张特征图fM和fF为输入,并输出三维的相关图CFM∈RH×W×(H×W),将位置(i,j,k)上的每个元素定义为对应位置一对描述符的标量积,其数学描述为
CFM(i,j,k)=fM(i,j)TfF(ik,jk),
(1)
式中:i∈{1,…,W},j∈{1,…,H},k∈{1,…,W×H};(i,j)和(ik,jk)指在H×W的密集特征图中的单个特征位置;k=H(jk-1)+ik是(ik,jk)的辅助索引变量,即每个长度为W×H的相关向量;CFM(i,j,k)表示fM中坐标为(i,j)的局部描述符与fF中各局部描述符之间的相似度.
多分支注意力模块滤除误匹配的设计思路为:以相关图CFM为输入,并输出与CFM相同分辨率的权重矩阵W,其中正确匹配的对应位置权重值较大,错误匹配的对应位置权重较小.经此,原相关图CFM通过权重矩阵W加权,正确匹配处的值则被增大,而错误匹配处的值将减小.在此基础上,本文设计了一种由两个平行分支组成的注意力网络,分别生成两个权重图W1和W2,如图3 所示.图3 中,每个分支都由编码和解码两部分组成,使用残差单元作为基本单位,残差单元的基本结构如图4 所示.
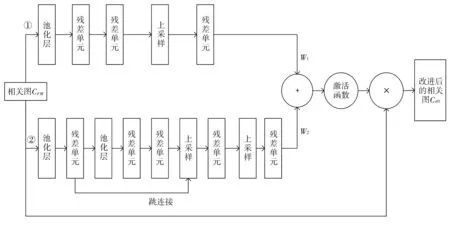
图3 多分支注意力模块结构图Fig.3 Multi-branch attention module structure diagram

图4 残差单元结构信息图Fig.4 Residual unit structure information graph
编码部分通过卷积提取高级语义对相关图进行编码,解码部分则通过卷积和上采样恢复像素.两个分支的主要区别在解码部分.分支①简单地使用上采样操作来生成权重图W1;更精细的分支②在编码和解码部分之间加入了跳连接,将低级信息与高级语义信息结合,生成精确的注意力权重图W2;将W1和W2元素相加起来,生成更精确的权重图W;使用双曲正切函数(tanh)激活W使权重值在[-1,1]区间,其中(-1,0)和(0,1)分别表示相关图的抑制和增强;最后,使用权重图W对输入的相关图CFM进行加权,生成改进的相关图Catt.
1.2.3 单应性矩阵估计模块设计
单应性矩阵估计模块利用相关图中的信息来估计两幅图像之间的转换参数.本模块网络由两个卷积层构成,在每个卷积层后进行批量标准化(Batch Normalization,BN)和修正线性单元(Relu),然后使用一个全连接层(Fully Connected Layer)得到维度为8的特征向量,即自由度为8的单应性矩阵,最后采用空间变换网络(STN)完成对运动图像的Warp操作.此模块的详细参数信息如表1 所示.

表1 单应性矩阵估计模块网络结构Tab.1 Network structure of homography matrix estimation module
1.3 损失函数构建

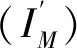

(2)
式中:N为图像的总像素数.


(3)
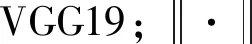
综上,训练模型的损失函数定义为
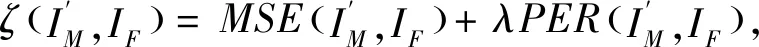
(4)
式中:λ为感知损失的权重.
2 实验结果与分析
2.1 实验参数设置
使用TensorFlow框架设计整体网络,采用无人机图像公开数据集UAV-123[17]组成2k对待配准图像对,包含建筑物、道路、汽车、帆船等不同类别.将所有待配准图像对分成三部分,即训练集、验证集和测试集,划分比例为0.75∶0.05∶0.2.借助NVIDIA TITAN X GPU服务器训练网络,训练中选择的初始学习率为0.000 1,每10轮衰减10%,批处理量大小设置为4,一共训练50轮.经过几次实验,最终把损失函数中感知损失的权重λ置为10,使用Adam优化器进行神经网络训练直至收敛.
2.2 评价指标
在图像配准领域中,因配准算法使用场景不同,其对应的质量评价指标也未统一.本文选用目前最常见且具有评价参考意义的评价指标来客观评估本文方法和对比方法的性能[2].
2.2.1 结构相似性SSIM
结构相似性SSIM(Structural Similarity)基于图像亮度、对比度和结构三个指标衡量图像的相似性.SSIM值在0到1之间,越接近于1,代表配准效果越好.其对应的计算公式为

(5)
式中:μx,μy分别为配准结果图像和参考图像中所有像素灰度的均值;σx,σy表示灰度值的标准差;σxy表示图像协方差;c1,c2为常量,避免分母为0所带来的公式错误.
2.2.2 互信息量MI
两幅图像的互信息量MI(Mutual Information)可以通过二者各自的熵和其联合熵来反映他们之间的相互关联程度.两幅图像的互信息越大,相似度越高,配准效果越好.其计算公式定义为
MI(x,y)=H(x)+H(y)-H(x,y),
(6)
式中:x,y分别表示配准结果图像和参考图像;H(·)表示熵的计算函数;H(x,y)为图像对x,y的联合熵计算函数.
2.2.3 平均绝对误差MAE
平均绝对误差MAE(Mean Absolute Error)表示像素位置的绝对误差平均值,是一种一般形式的误差平均值.其在做模型评估时,对离群点有较好的鲁棒性.MAE的值越小,说明两幅图像越相似,即配准效果越好.其计算公式为

(7)
式中:xi,yi分别表示配准结果图像和参考图像在i位置上的像素值;N代表总像素数.
2.3 对比实验
2.3.1 主观视觉评价分析
以待配准图像对为输入,以参考图像作为基准,通过优化运动图像与参考图像之间的相似性来训练网络.训练完成后,在整个测试集(包括400对待配准无人机图像)测试该模型,并与经典的传统算法SIFT[3]、ORB[18]和基于深度学习的算法UDHE[14]和CAU-DHE[15]方法的配准结果进行比较.从测试图像中选择不同类别的3组待配准图像对进行比较,并通过图像拼接来展示配准效果,如图5 所示.

图5 测试集上各方法的配准拼接结果Fig.5 The registration and stitching results of each method on the test set
在图5 中,第1行和第2行分别为运动图像和参考基准图像,剩下的5行从上到下分别展示了SIFT,ORB,UHDE,CAU-DHE和本文方法的配准结果图像和参考图像的拼接结果.从图中可以看出,传统的SIFT算法在UAV数据集上达到了较好的配准效果,但计算量大,耗时长;ORB算法是在FAST关键点检测和BRIEF特征上进行的,虽然比SIFT算法具有更快的匹配速度,但在图像配准中对于大的单应性变换性能较差,无法满足本文无人机图像的配准拼接要求;UHDE算法是一种基于无监督的深度单应性估计模型,其在第3组待配准图像对上性能较差,鲁棒性不强,而且经过大的扭曲之后图像变得模糊,出现了一定的失真现象;CAU-DHE也是一种无监督的深度单应性估计算法,在特征提取之后添加了掩膜结构来滤除离群值,从结果图来看,变换后的图像仍然存在重影;明显可以看出,本文方法具有最好的配准拼接效果,变换后的图像和参考图像边缘连接较好,图像清晰没有重影.
2.3.2 客观指标评价分析
通过主观视觉感知分析得出,本文所提方法具有较高的配准性能,但仍然需要详细的指标数据对配准结果进行客观评价.本文在测试集上计算配准结果图像和参考图像的结构相似性(SSIM)、互信息量(MI)、平均绝对误差(MAE)并进行记录,将对应的指标数据对测试集图像进行平均,得到最终的评价指标均值,结果如表2 所示.为了测试各算法的实时性,表中还给出了在测试集上各算法的平均配准速度.
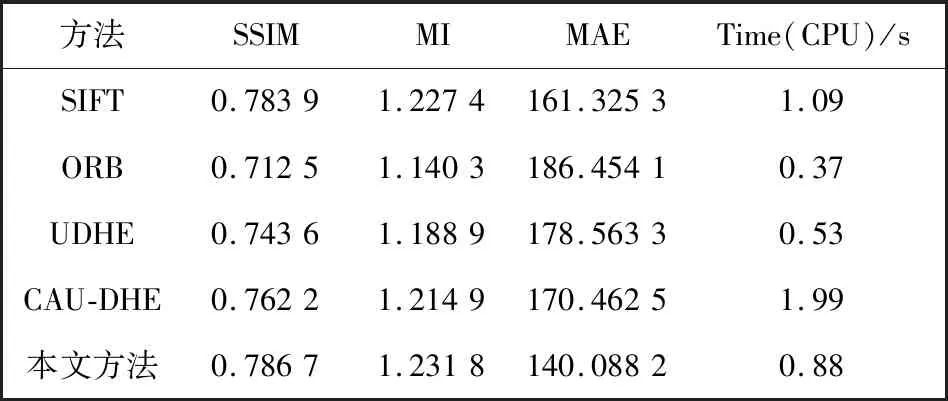
表2 测试集上不同方法评价指标统计表Tab.2 Statistics of evaluation indicators of different methods on the test set
从表2 可以看出,本文方法在SSIM,MI和MAE指标中均取得最佳效果,SIFT算法次之,而ORB算法的指标最低,与主观观察的结果一致.另外,表中所有方法的各项指标均处于较低数值,主要是由于待配准图像对之间的差异较大,参考图像和运动图像的可重叠范围较小,配准结果图像存在大面积黑边.本文方法的整体评价指标偏高,且计算时间较短,证明了本文方法在无人机图像配准任务上的有效性.
2.4 消融实验
为了验证本文无监督配准模型的合理性和有效性,进行了消融对比实验,所有实验训练设置均相同.针对本文设计的深度特征提取模块(R-VGG)、多分支注意力模块(MBA)和复合损失数进行消融对比实验,结果如表3 所示,实验设计了5种不同的模型:①在初步特征匹配后直接进行单应性估计,没有添加多分支注意力(MBA);②仅使用感知损失作为网络训练的损失函数;③损失函数只使用均方误差损失;④采用预训练的VGG16替代本文设计的R-VGG模块来提取深度特征;⑤本文方法的完全体.表中三个客观指标分别为测试集上配准结果图像和参考图像的结构相似性(SSIM)、互信息量(MI)和平均绝对误差(MAE)的平均值.

表3 消融实验结果Tab.3 The results of ablation experiments
对表3 所示结果进行分析:方法④与方法⑤的对比证明了本文所提的R-VGG特征提取网络的有效性,在特征提取阶段采用本文提出的R-VGG网络结构能够融合图像的低、高层特征信息,提取到更有利于后续特征匹配及空间变换参数回归的特征.方法②,方法③与方法⑤的对比表明,使用均方误差损失和感知损失加权的复合损失函数来训练模型,性能会更好,这是由于缺少感知损失的约束时,无法考虑到图像深层的相似性,当进行大的单应性变换后,图像容易变得模糊;在只使用感知损失时,忽略了图像本身的相似性,图像不能精确对齐.方法①和方法⑤的差异在于方法⑤加入了多分支注意力模块来滤除误匹配,在无人机图像配准过程中,由于弱纹理带来的特征误匹配不可避免,直接进行单应性估计会受到错误匹配的影响,从而使配准精度下降.在单应性估计之前加入多分支的注意力模块来滤除错误的特征匹配,则配准精度得到显著提升.
对比表3 中各项指标也验证了设置多分支注意力模块的必要性和有效性.总的来说,本文所设计的各模块能有效提高无人机图像的配准精度和配准结果图像的质量.
3 结 论
本文提出了一种基于无监督学习的无人机图像配准模型.首先,充分利用深度学习的高性能,设计了R-VGG特征提取模块,筛选出具有鲁棒特性的低、高层融合特征;其次,在特征匹配模块加入了多分支注意力(MBA)约束,滤除错误匹配,从而提高了配准精度;此外,使用内容损失和感知损失加权的复合损失函数,提高了网络性能.通过视觉感知分析和客观指标分析,验证了本文方法在无人机航拍图像配准领域的有效性和稳定性.在今后的工作中,将研究分析无人机图像的深度信息并对本文方法进行改进以充分利用图像信息来提高配准精度.
猜你喜欢
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机系统应用(2021年10期)2022-01-06
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
学生天地(2019年28期)2019-08-25
电子制作(2019年11期)2019-07-04
