
区块链框架下基于优化决策树模型的大数据分类算法研究
2021-11-12 07:23杨薇薇曾凌静
沈阳工程学院学报(自然科学版) 2021年4期
杨薇薇,曾凌静
(福建船政交通职业学院 信息与智慧交通学院,福建 福州 350007)
在互联网、信息产业和通信技术的推动下,每天都会产生海量的数据,据国际权威大数据研究机构Statista 预测,到2020 年底全球的数据总量有望突破50 ZB 大关[1-2]。大数据是人类社会进步的主要推动力之一,大数据资源也是世界各国参与国际竞争所必备的最主要资源之一[3]。由于大数据的规模巨大、格式多样,且具有多源异构性,要深度挖掘出大数据内部蕴藏的关键信息具有较大的难度,需要借助大数据框架和云计算工具[4-5]。大数据分类是数据挖掘处理的基础步骤与核心任务之一,数据分类的精度将影响到最终的大数据处理效果。在当前商品经济的社会背景下,大数据分类还具有更多的商业价值和产业附加值。因此,大数据分类处理还需要面对各行各业中的数据垄断问题。区块链技术作为一种分布式的数据存储模式,能够在数据分类中兼容数据加密,并有效解决行业中的数据垄断问题,所以在区块链框架下的数据分类具有更多的实践意义和价值[6-7]。
区块链技术体系框架下现有的大数据分类算法,主要以人工智能和机器学习为基础。文献[8]提出基于朴素贝叶斯模型的大数据分类方案,该算法在处理多分类样本时具有较高效率,但算法的应用需要基于样本分布独立的假设条件,实用性较差;文献[9]提出基于k-means 的数据分类算法,该算法的复杂度较低且容易实现,但在实际应用过程中k值的找寻较为困难,且在迭代过程中容易陷入局部最优解,该算法的并行运算能力也较差;苗红等[10]提出一种基于LDA-SVM 的大数据分类算法,作为一种二值分类器,LDA-SVM 算法拥有较快的分类速度,但当样本规模扩大以后分类器的性能会快速衰减,导致总的数据训练时间和测试时间延长,分类准确率不断降低。本文根据区块链框架的特征,并针对现有大数据分类算法的不足,提出基于优化的决策树模型分类算法,通过梯度提升的方式提升经典决策树模型的性能,获取更好的数据分类效果。
1 区块链框架下的大数据加密处理
在通信、金融、电商等领域,大数据具有明显的碎片化分布特征。数据碎片化一方面增加了大数据分类处理的难度,另一方面碎片化数据中更容易隐藏具有恶意攻击性数据,危及用户的隐私安全。在区块链框架下对数据明文采用同态加密的方式处理,并将密钥分别存储于各利益相关者数据节点,同时将信息同步到云端服务器,在联盟供应链网络中选取记账节点,使每个节点都有属于自己的ID、公钥与私钥。区块链框架下不仅可以实现数据的加密功能,节点之间还能够互相监督,避免出现行业数据垄断的现象,区块链架构下的大数据加密过程如图1所示。
区块链采用一种分布式方式和密码学技术原理,将不同的服务器连接起来,每一个区块记录不同的对应信息。分布式记账方式有效地去除了过度依赖特定服务器的弊端,去中心化的思想可以有效避免出现行业数据垄断的现象。区块链的账本中存储了全部企业的相关信息、下载地址及数据共享的路径,使用哈希函数和哈希值加密数据的完整性。在数据存储方面,云端存储是主流的存储方式,具有安全性和容量大的双重优势,云存储降低了用户数据存储成本,保护更多普通用户数据的安全和隐私。由于采用了分布式的记账方式,区块链中的每个个体都被视为一个节点,节点分布式排布能够起到相互监督的作用。此外,去中心化的方式也使整个系统框架具有更强的分类计算能力。
2 决策树模型的构建及优化
在大数据分类计算过程中,如何在全局寻优的基础上兼顾数据分类效率、分类精度,是需要解决的核心问题。决策树算法是人工智能和机器学习最基础、最有效的算法之一。决策树算法先通过对无规则、无次序样本数据的训练和规则挖掘,构建数学分析模型,并得到基础的分类规则,再对目标数据集做预测分类。区块链框架下可以根据节点的分布特征,构建多个决策树模型同步分类以提高数据分类处理的效率。决策树模型的构建首先要生成候选分裂点,并选择每个节点的最佳分裂时机;其次,以最佳分裂点为基础进行大数据分类;最后,通过不断迭代更新分类模型的性能。节点的分裂以大数据样本属性的信息熵和信息增益率为基础,节点分裂及决策树模型的构建过程如图2所示。
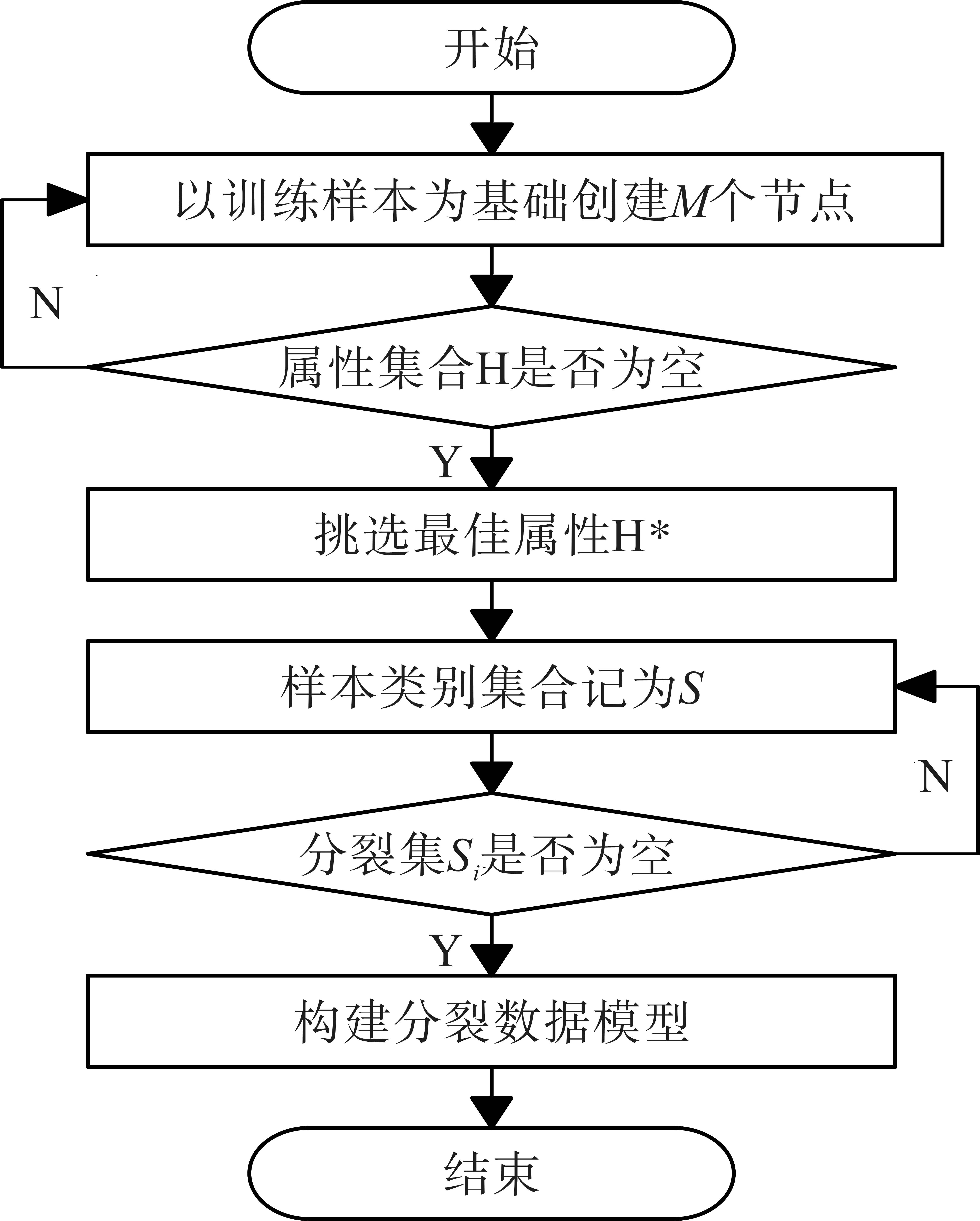
图2 决策树模型构建过程
待分类的大数据集训练样本总数为M,与区块链创建的节点数量一致,训练集的类别总数为S,各样本集记作M1、M2、…、Ms。设训练集中所包含的任意一个属性为τ,该属性包含p个属性值,记作τ1、τ2、…、τp,与属性值为τi对应的样本数量为,属性取值为j的样本数量为,i的取值区间为[1,p]。区块链框架下大数据集中的训练样本集的信息熵H(P)可以表示为
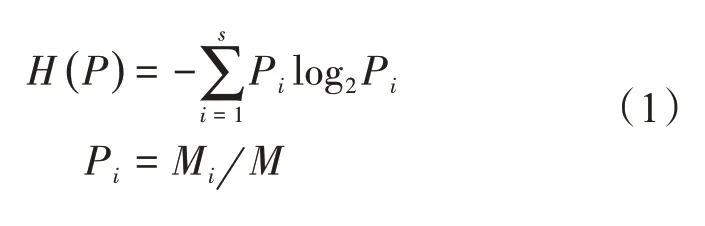
将属性τ融入特征数据集:
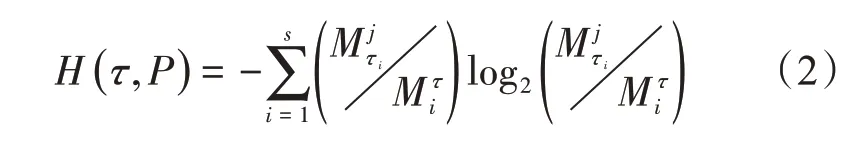
融入特征属性τ之后,信息增益率κ(τ,P)表示为
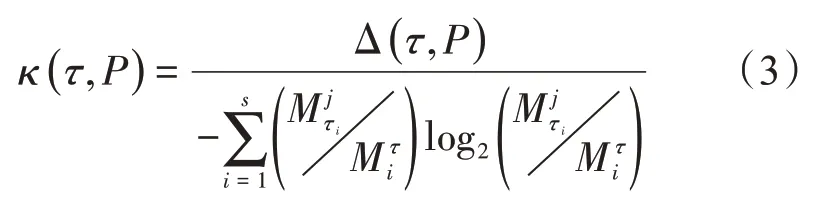
分类属性的选择问题是决定决策树模型效率的核心要素,如果在利用信息熵和信息增益效率构建模型过程中出现了属性缺失的情况,会直接增加分类的错误率,决策树算法原有的泛化能力强的优势也无法充分发挥出来。为保证在局部节点分裂受阻的情况下不影响其他节点的分裂工作,对经典的决策树算法进行优化,在区块链体系内预留出用于缓冲的空节点。如果在当前的决策树模型中,可以用于分裂的节点属性个数为k,那么优化后的当前节点可以分裂为k+1个子节点。当属性缺失时,该子节点可以基于已知属性进入空节点,避免分裂终止的情况发生。算法改进后的部分伪代码如下所示:


信息熵放大了系统的混淆层尺度,而信息增益值可用于度量信息熵在概率分布上的差异。在区块链框架体系下,采用分布式的计算方式能够进一步提升决策树模型的分类能力。由于区块链体系内预留出了用于分裂缓冲的空节点,在分类过程中应先计算每个信息特征值节点的增益值,并将信息增益值做排序处理。决策树的深度dj及非子叶节点数IN,都依据待分类数据的规模指定,两者之间的关系表示为
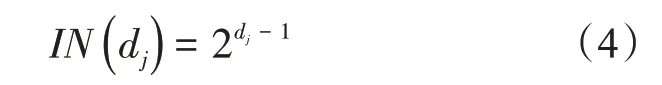
由于预留了至少一个备选节点,即使在信息增益中出现了个别特征缺失的情况,也能够避免节点分裂停止的情况发生。
3 基于优化决策树模型大数据分类的实现
区块链框架体系下按照预设好的树形结构训练数据集,经过优化后的决策树模型在分裂处理样本目标值、预测值时,可以采用批量处理的方式,分类计算过程中的损失函数模型L(H,κ)表示为
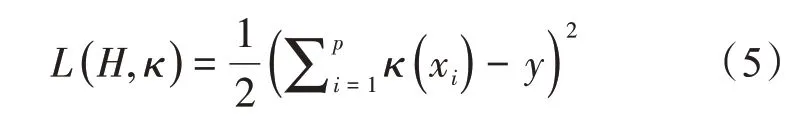
在类似于优化决策树分类模型的后馈网络学习系统中,每一次分裂仅会修改一个叶子节点权重,此时第t颗树的分类损失函数Lt表示为
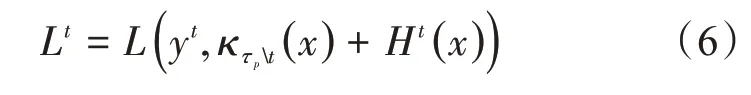
其中,τp 表示优化决策树分类模型第t棵树之外的决策树,模型通过不断更新信息熵H(P)的值来确保损失函数保持最小化趋势。数据训练中要获得更准确的数据分类效果,需要计算损失函数Lt的偏导数,计算结果表示为

式中,λ是损失函数Lt的一阶导数。
从第t棵树到第t+1 棵树的分裂和更新过程,描述如下:
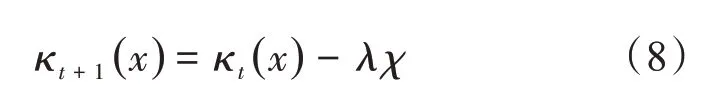
式中,χ是优化决策树模型的学习率。
当均方根误差最小时,λ的推倒过程可以描述为
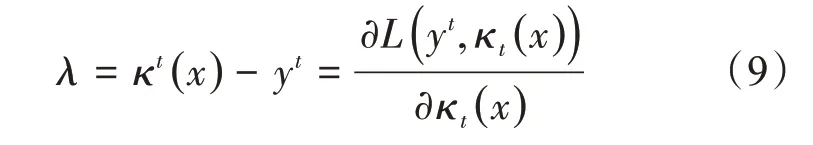
式中,yt是分类结果输出的累加值。
从决策树整体最优化的角度来考虑,样本分类输出目标值的拟合程度越高,大数据的分类效果越好。由于区块链框架下每个节点都单独匹配一组服务器,所以优化决策树算法还要考虑到复合样本的情况,即将优化决策树模型从一个节点复制到整个区块链体系。这样,一方面能够发挥出区块链框架体系并行计算的优势,同时数据分类过程中各节点之间互相监督,避免出现数据垄断的现象。对于任意一个区块在更新叶子节点时,依据被划分到上一级叶子节点的样本索引,训练和更新本批次梯度,损失函数的更新过程可以描述为
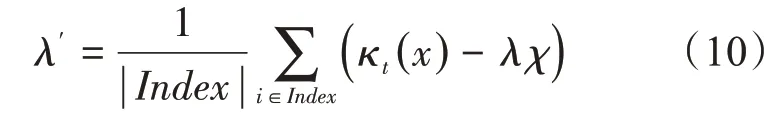
在不断地迭代更新中,以批次训练的方式更新决策树结构的网络权重值,引入网络化的分层运算方式,并用全部样本的平均梯度更新子节点权重比例,就能够在整个区块链范围内大规模地分类处理原始数据集,提升了整个算法的效率,全局的训练过程步骤如下:
step1:输入样本集并设定迭代次数,初始化模型框架并以区块链的节点为基础划分数据的批次。
step2:统计原始数据中特征元素的个数、长度等基础信息,形成训练样本。
step3:计算损失函数值及决策树函数模型的梯度值,并预测下一层次的叶子节点,优化后的决策树模型已经预留出了用于缓冲的空节点,避免了节点分裂情况的发生。
step4:最后更新网络权重值,在区块链全局范围内更新分类数据。
在优化决策树模型训练过程中,确保目标函数值始终处于最优状态,并保证损失函数降到最低,这样既能保证叶子节点之间相互独立,也能够确保模型函数具有良好的收敛性能。
4 实验与仿真
为了验证所提出的基于优化决策树模型在大数据分类方面的效果,在实验室环境下,模拟区块链工作情况构建了一个拥有10 个节点的Hadoop集群。各节点硬件配备intel core i7处理器,工作主频为3.6 GHz,各节点主机配备16 G 运行内存和2 TB 的固态闪存存储器。软件系统部分运行win‐dow10 专业版系统和Hadoop2.6.5 版本。Hadoop集群中包含9 个slave 节点和1 个master节点:slave节点负责对每个区块的数据进行采集、归类和存储;master 节点负责对整个区块链网络进行数据综合管理和调度。首先验证算法的数据分类处理能力,具体考核指标包括数据的吞吐能力和并行计算能力。经过优化的决策树算法能够连续地选择最佳的分裂节点,并保持算法对输入大数据的分类性能。
实验中以相对复杂的Nursery 数据集和Mush‐room 数据集为研究对象,对比文中提出的优化决策树算法及文献[8]、文献[9]和文献[10]3 种传统算法在数据吞吐量方面的差异,数据统计结果如图3和图4所示。
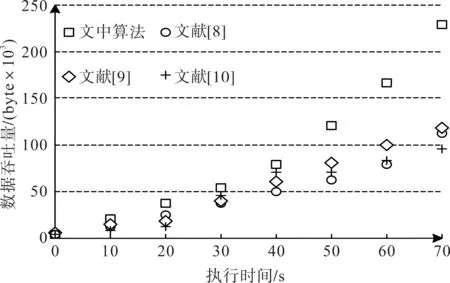
图3 Nursery数据集各算法数据吞吐量变化
图4 Mushroom数据集各算法数据吞吐量变化
数据仿真结果显示,无论是针对Nursery 数据集还是Mushroom 数据集,文中算法经过优化后的数据吞吐量在统计执行时间点上都要优于3 种传统分类算法。数据吞吐量是验证分类算法绝对性能的重要指标,统计结果表明,经过优化后的决策树模型具有更强的算法连续性、泛化能力和全局迭代寻优能力。
在区块链框架下,由于各节点都采取了分布式的网络结构设计,算法的并行计算能力会影响到大数据分类的总体效率。仍以Nursery 数据集和Mush‐room数据集为研究对象,判断各算法随线程数增加并行度的变化情况,仿真结果如图5和图6所示。
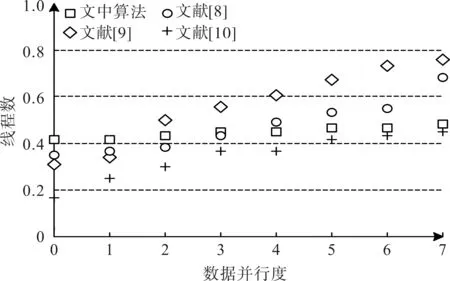
图6 Mushroom数据集并行计算能力结果统计
数据统计结果显示,当数据并行度发生改变时,文中算法的线程数波动要更小、更为稳定,这表明提出的优化决策树算法具有更强的数据并行计算能力,在区块链框架体系内能够帮助各节点完成区块范围内大数据的分类处理。
最后验证各分类算法在区块链框架体系内,针对大数据分类的准确率,在Nursery 数据集和Mushroom 数据集的基础上扩充测试样本集,引入MINST、CIFAR10、Oxford-IIIT Pet、Food-101、Wiki‐text-2、Amazon reviews、DBPedia ontology、Yelp re‐views 等不同类别的故障数据集,验证在多种不同数据集条件下各算法的性能。准确率指标Acc的计算公式为

最终的统计分析结果如表1所示。
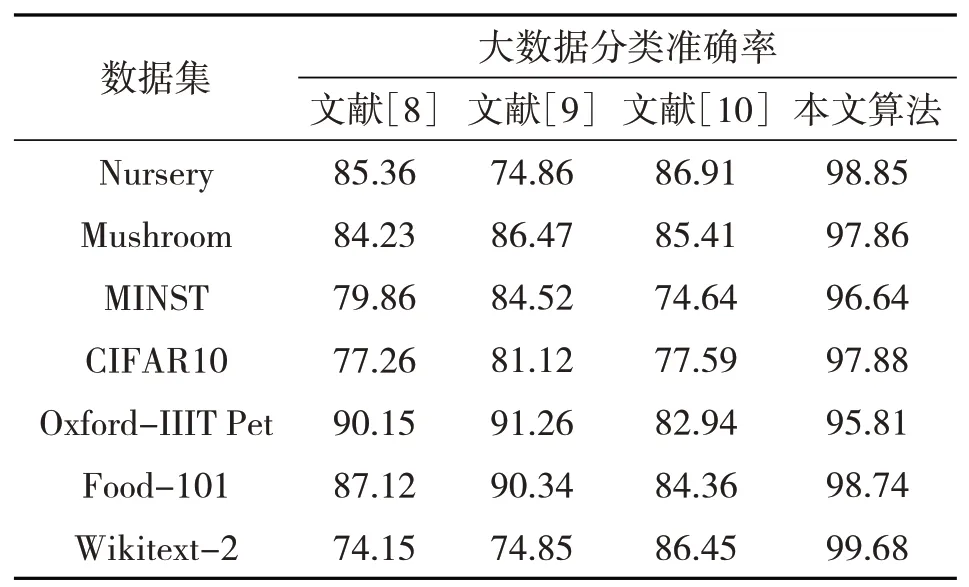
表1 各算法的大数据分类准确率对比 %
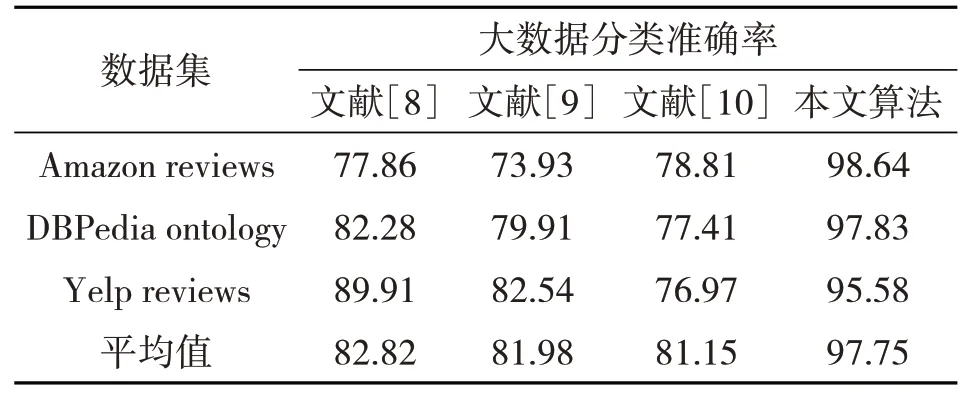
表1 (续)
针对不同的大数据集,3种传统算法在分类准确率上出现明显波动:文献[9]算法在Oxford-IIIT Pet数据集上的分类准确率可达到91.26%,但在Wiki‐text-2数据集上的分类准确率仅为74.85%。从对各大数据集分类的平均值来看,文中算法达到了97.75%,3种传统算法的平均准确率均未达到85%。
5 结论
区块链框架的优势在于采用了分布式、去中心化的结构设计,避免在大数据分类中发生数据垄断情况。本文在区块链框架下对经典的决策树模型进行优化,提升了节点分裂性能,仿真实验结果也表明提出算法具有更高的数据分类准确率,相对于传统大数据分类算法优势较为明显。
猜你喜欢
黑龙江大学自然科学学报(2022年1期)2022-03-29
小资CHIC!ELEGANCE(2022年1期)2022-01-11
数学物理学报(2021年1期)2021-03-29
科学(2020年5期)2020-11-26
科学(2020年6期)2020-02-06
电子制作(2018年16期)2018-09-26
传媒评论(2018年4期)2018-06-27
传媒评论(2018年4期)2018-06-27
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
智能系统学报(2015年4期)2015-12-27
