
改进Faster R-CNN在两轮车辆载人检测中的应用
2021-11-12 03:37:44邝先验周亚龙欧阳鹏
河南科技大学学报(自然科学版) 2021年1期
邝先验,陈 涛,周亚龙,欧阳鹏
(江西理工大学 电气工程与自动化学院,江西 赣州 341000)
0 引言
两轮车在交通出行中越来越普及,又因其载人不规范,易引起交通事故,所以对两轮车辆载人的检测迫在眉睫。而两轮车辆载人检测的关键是对两轮车上乘客的检测,这与行人检测有许多相似之处,所以可以借鉴行人检测的研究成果。
文献[1]研究了人脸肤色和发色的差异,再聚类并建立人头模型,最后模板匹配检测人头,对行人检测精度高。文献[2]在图片中使用固定的滑动窗口提取特征,使用自适应提升算法训练分类器,通过筛选式级联把分类器衔接起来,进行目标分类识别。文献[3]先计算梯度方向直方图,再用支持向量机(support vector machine, SVM)训练得到物体的梯度模型,最后将模型与目标匹配,进行目标检测。文献[4]通过分离运动目标和背景,对背景使用融合区域匹配和特征匹配,可快速检测出人头。但上述传统算法提取的特征比较单一,受环境影响较大。近些年,深度学习技术已成为目标检测的主流方向[5-10],也被应用到行人检测中。文献[11]建立行人人头模型,提取头部特征,利用Faster R-CNN训练测试,具有优良的自适应性。文献[12]采用金字塔网络结构和特征融合技术来改进Faster R-CNN,提高了模型对煤矿井下行人检测的效果。文献[13]通过实验对比不同的特征提取网络和检测算法,发现以InceptionV2为特征提取网络的Faster R-CNN在车站行人检测中有较好的效果,算法的检测精度为81.08%,检测时间为0.576 5 s。
综上,Faster R-CNN算法具有良好的自适应性,且具有较高的检测精度和较快的检测速度,所以选择该算法进行两轮车辆载人的检测。但在真实图片中,人头尺寸偏小和乘客重叠,往往会导致两轮车上乘客的漏检,因此检测算法需要改进。改进的Faster R-CNN算法调整了区域生成网络(region proposal network,RPN)中的候选框(anchor)尺寸和特征融合结构,以增强对小尺寸目标和多尺度目标的检测。改进的算法还使用了柔和的非极大值抑制(soft non-maximum suppression,Soft-NMS)[14]替换非极大值抑制(non-maximum suppression, NMS),以提高重叠目标的检测效果。
1 两轮车辆载人检测模型设计
两轮车辆载人检测模型流程图如图1所示。检测模型的流程:先检测出图片中的两轮车和人头;再根据人头检测框的中心点是否在两轮车区域内,找出所有乘客;最后,在图片上标出两轮车上的乘客。
1.1 Faster R-CNN算法
Faster R-CNN的结构如图2所示,其中,特征提取网络采用的是GoogLeNet,用于提取目标的特征信息。将实验数据集输入到GoogLeNet的卷积层中进行目标特征的提取并产生特征图,将生成的特征图送入到RPN生成候选区域;再将提取的候选区域的特征送入到感兴趣区域池化(ROI pooling)层处理成固定大小的特征向量;最后送入全连接层实现分类和边框的回归。
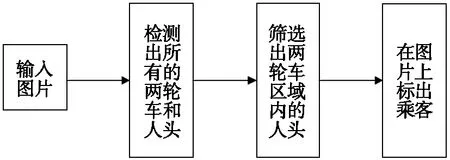
图1 两轮车辆载人检测模型流程图>
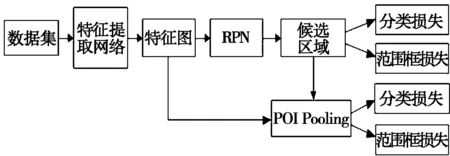
图2 Faster R-CNN结构图
1.2 特征提取网络GoogLeNet
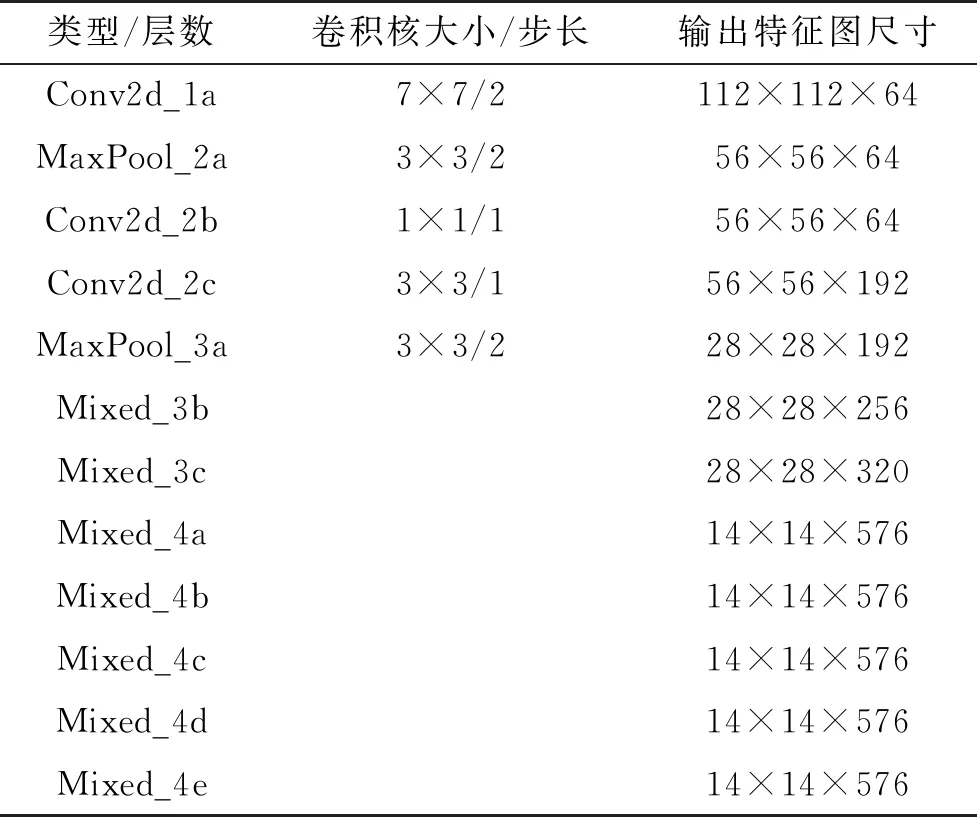
表1 特征提取网络的结构参数
GoogLeNet相比于VGG网络有更深和更宽的网络框架,可以提取两轮车和人头更丰富的特征,从而提升训练结果。Inception模块是GoogLeNet组成的基本单元,有4个版本,即Inception V1~V4[15-18]。通过阅读文献,本文选择比较常见的Inception V2来构建GoogLeNet。特征提取网络的结构参数如表1所示,其有3个卷积层、2个最大池化层和7个Mixed模块。Mixed模块等同于Inception V2模块,结构如图3所示,先通过1×1卷积降低通道数聚合信息,再融合不同尺度的卷积以及池化操作,进行多维特征的融合,有效地提升了检测效果。
1.3 RPN网络及其改进
1.3.1 RPN网络
RPN网络输入的是特征提取网络的特征图,输出的是目标候选区域矩形框集合,其结构如图4所示。GoogLeNet提取的特征图输入到RPN,先经过一个3×3的滑动窗口在特征图上滑动,每次滑动可产生一个576维的特征向量,再将576维的特征向量送入两个全连接层。通过2k个1×1的卷积核将576维的特征向量映射到分类层,判别候选区域是前景还是背景。通过4k个1×1的卷积核将576维的特征向量映射到位置回归层,用来输出对候选区域坐标位置的回归。
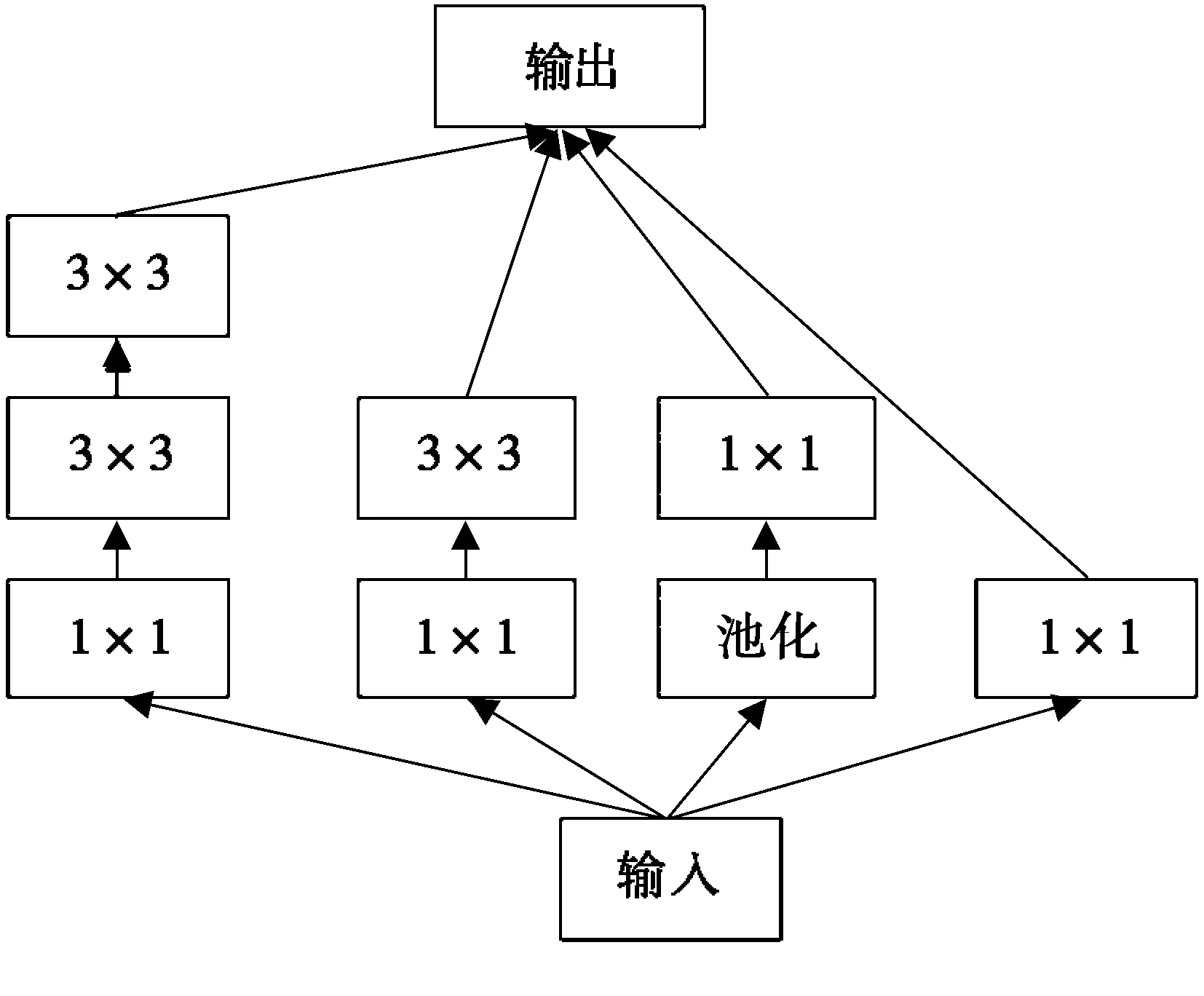
图3 Inception V2模块结构
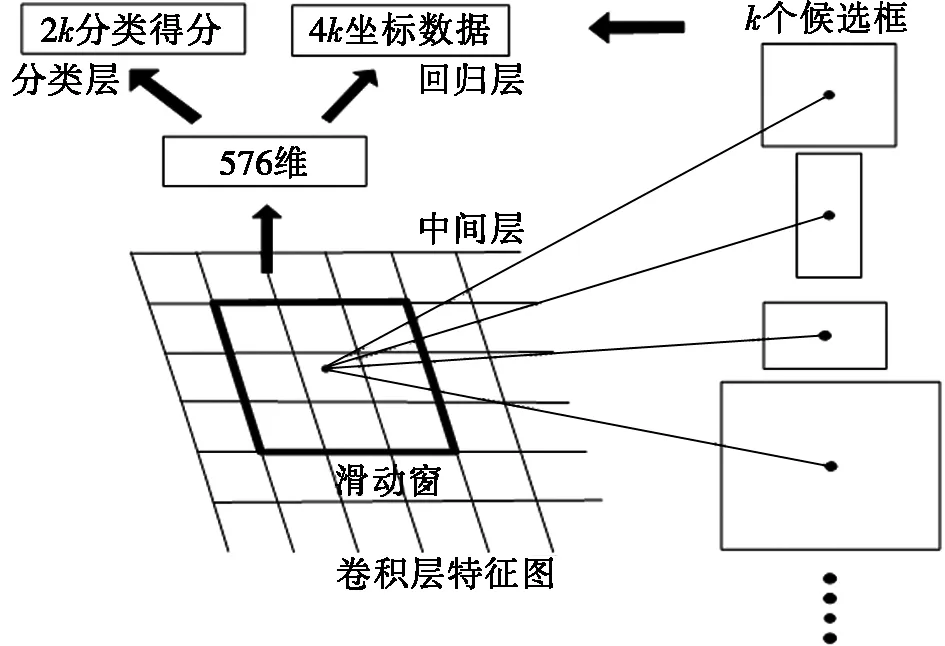
图4 RPN网络结构
图4中特征图在经过3×3卷积之后每个像素点上产生k个候选框(anchor),而这些anchor是后续目标定位的关键。原始的anchor有9种型号(即k=9),是由3种面积尺寸为{128^2,256^2,512^2}和3种长宽比为{1∶1,1∶2,2∶1}组合构成的。
1.3.2 RPN网络的改进
RPN网络中anchor的尺寸设置直接影响候选框的生成,进而影响后续目标定位的精度,所以这是一个重要参数。原始anchor的尺寸是根据PASCAL VOC2007数据集设计的,具有普适性。但是,本文数据集中人头尺寸偏小,若使用原始的anchor,会导致候选框无法检测出小尺寸人头,导致目标漏检,影响检测效果。因此,调整anchor的尺寸以符合本文数据集是有意义的。
图5是数据集中人头真实标注框面积的直方图。由图5可以看出:图片中人头尺寸相对偏小,人头标注框面积的平均值为14 963≈120×120,四分位数分别为Q1=7 801≈85×85,Q2=15 274≈120×120,Q3=56 792≈240×240,这些参数与原始anchor的面积尺寸有较大的差异,所以原始anchor的设置不适合本文数据集。而四分位数是对所有数据升序处理后,选取第25%、第50%和第75%的数据作为Q1、Q2和Q3。所以四分位数的选取不受极大值数据或极小值数据的影响,对数据的扰动具有一定的鲁棒性。为了提高两轮车辆上人头检测的精度,结合本文采用的数据集,将anchor的面积尺寸修改为{85^2,120^2,256^2,512^2}。
人头真实标注框长宽比的直方图如图6所示。由图6可知:人头的长宽尺寸比主要集中在0.5和0.8附近,所以anchor的长宽比修改为{2∶1,1∶1,1∶1.25,1∶2}。
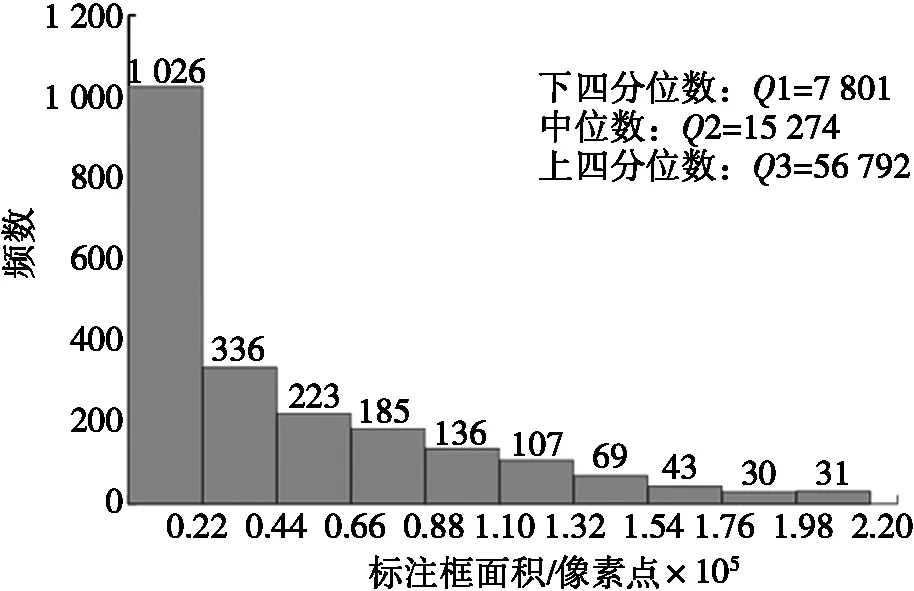
图5 人头真实标注框面积的直方图
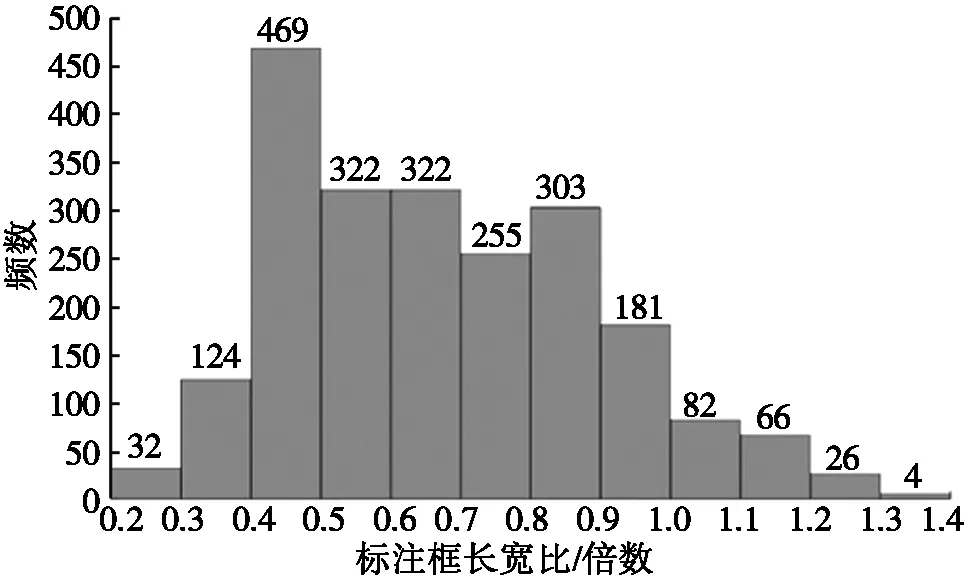
图6 人头真实标注框长宽比的直方图
实际中,人头在图片上显示的尺寸与拍摄的距离成反比,因此拍摄图片中人头的尺寸具有多样性。但原始的RPN只用了一个3×3 的卷积核对特征图进行候选区域提取,感受野有限,不能满足实际情况,所以本文构建了一种多尺度特征融合的RPN结构,如图7所示。多尺度特征融合的RPN结构在GoogLeNet提取的特征图上,采用多分支结构来进行候选区域提取,可得到不同尺度的目标。该结构有3个分支,第1个分支采用一个1×1的卷积核对特征图进行候选区域提取;第2个分支采用一个3×3的卷积核对特征图进行候选区域提取;第3个分支采用将两个3×3的卷积核串联在一起的方式对特征图进行候选区域提取,其感受野效果等同于一个5×5的卷积核。两个3×3的卷积核串联不仅可以提升网络的深度,同时还可以减少参数量。
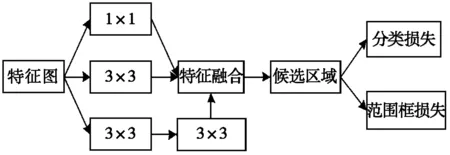
图7 多尺度特征融合RPN结构
实验证明,修改后的RPN可以增强模型对目标多尺度的鲁棒性,使模型对小尺寸人头更加敏感,提高了模型对人头检测的性能。
1.4 Soft-NMS替换NMS
检测器对图像中的目标进行检测时,最后选定的候选框必然会有一定的重叠现象,当重叠度大于某一阈值时,将置信度最高的作为输出,而将其他的预测结果直接去掉,这种方法称为非极大值抑制(NMS)。实际中,两轮车上乘客坐得比较紧凑,车载人员之间会出现遮挡,因此特征不完整的后排乘客的候选框得分较低。如果用传统的NMS来筛选候选框,后排乘客的候选框由于重叠的原因,会被得分高的前排人员的候选框过滤掉,导致后排乘客的漏检。针对这个问题,本文将采用柔和的非极大值抑制(Soft-NMS)替换NMS。NMS过于简单直接,而Soft-NMS对函数进行了平滑。文献[14]提出两种平滑函数,一种是线性加权函数,另一种是高斯加权函数。
NMS的表达式[8]为:
(1)
Soft-NMS线性加权的表达式[14]为:
(2)
Soft-NMS高斯加权的表达式[14]为:
(3)
其中:ci为bi的得分;M为当前得分最高的候选框;bi为待处理的候选框;D为所有待处理候选框的集合;iou(M,bi)为M和bi之间的重叠率。当iou(M,bi)越大,ci下降越厉害。实验证明:Soft-NMS检测重叠目标的效果要优于传统的NMS,且Soft-NMS高斯加权函数的性能比Soft-NMS线性加权函数的更好,证明了改进后网络的有效性。
2 实验结果与分析
2.1 数据集
两轮车辆载人检测实验的数据集包含2 800张训练集和662张测试集。训练集由两轮车的图片和人头的图片组成。两轮车的图片通过拍摄和录像选取得到,包含多个场景、多个角度两轮车的图片。人头图片是从公共集Hollywood heads dataset中选取部分图片做实验。测试集是真实场景下两轮车辆载人的图片,通过网上爬虫和拍摄得到。
2.2 模型训练
模型采用以GoogLeNet为特征提取网络的Faster R-CNN检测方法,选择利用公共COCO数据集上训练好的模型作为初始网络。为减少训练时间,降低训练难度,对模型进行微调。实验平台是谷歌公司开发的深度学习框架TensorFlow,在该平台进行相关代码和参数训练,网络的训练过程采用随机梯度下降法(stochastic gradient descent,SGD)来优化整个网络模型。两轮车辆载人的训练模型参数配置:学习率初始值为0.002,6×104次迭代后降为0.000 2,momentum值为0.9,数据集训练迭代12×104次。实验用到的设备:联想工作站C30,处理器E5-2609,内存16 G,显卡GeForce RTX 2080,运行环境ubuntu16.04。
2.3 实验检测及结果
原始算法和改进后Faster R-CNN算法对相同图片的检测效果对比图,如图8所示。由图8a可以看出:第1幅图中两轮车上被遮挡的后排乘客被漏检,第2幅图和第3幅图中视觉远端尺寸小的乘客被漏检,说明原始算法检测人头的效果不佳。图8b可以检测出被遮挡住的人头和小尺寸的人头,反映出改进后算法检测人头的效果较好。

(a) 原始的Faster R-CNN算法检测效果图

(b) 改进后Faster R-CNN算法检测效果图
图9是在不同场景下,改进后Faster R-CNN算法的检测效果图。从图9中可以看出:在不同路况、不同拍摄视角和不同光照下,改进后算法能精准地检测出两轮车上的乘客。

(a) 场景1 (b) 场景2

(c) 场景3 (d) 场景4
为了评估改进后算法对两轮车上乘客检测的有效性,采用精度P、召回率R和F1值对算法进行衡量。精度P、召回率R和F1值可按下式计算:
(4)
(5)
(6)
其中:NTP为正检数,表示目标中被正确检测出来的数量;NFP为误检数,表示把非目标检测为目标的数量;NFN为漏检数,表示目标中没有被检测出的数量。
改进前后算法对比如表2所示。由表2可知:实际人头共1 056个,改进后算法中有35个目标被漏检,原因是这些乘客的头部被严重遮挡,特征非常不明显。误检数有97个,其中有些是两轮车的后备箱被误检为人头,但主要是两轮车附近的行人被误检为车载人员。改进后算法的检测精度为91.33%,召回率为96.76%,相比于原始算法,精度提高了2.68%,召回率提高了6.67%,说明改进后算法检测效果优异。
2.4 影响因素分析
本文通过实验来分析RPN的优化、Soft-NMS的使用这两个因素对模型性能的影响。为此,本文通过4种不同的方案进行对比实验,基准方案为Faster R-CNN+Inception V2,结果如表3所示。
从表3中可以看出:方案②和方案③相比于未改进的方案①,在召回率上有明显的提升。方案②使用了Soft-NMS,可以检测出重叠度高而得分低的候选框,这类候选框在图片中通常指的是被遮挡的后排乘客,从而有效减少了重叠乘客的漏检。方案③优化了RPN,使得模型对小尺寸人头更敏感,增强了对小尺寸目标的检测。可见,优化RPN或使用Soft-NMS可以有效地减少乘客的漏检,提高检测效果。方案④融合了方案②和方案③,故其精度和召回率都是最高的,所以方案④为最佳方案。
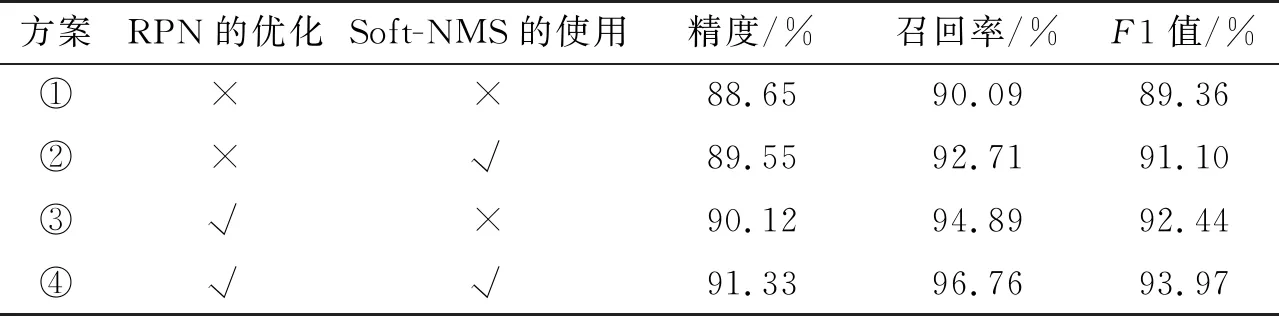
表3 4种不同方案性能对比
3 结束语
提出了一种基于改进的Faster R-CNN算法检测模型,通过优化RPN和使用Soft-NMS来提高模型的检测性能。改进后的算法提高了两轮车辆载人检测的精度和召回率,模型的性能也得到了有效地改善。下一步将围绕两轮车附近行人干扰和严重遮挡问题进行研究,以进一步提高两轮车辆载人检测的性能。
猜你喜欢
光学精密工程(2022年13期)2022-08-02 08:53:30
小雪花·初中高分作文(2022年5期)2022-07-23 15:00:44
中学生数理化·八年级物理人教版(2022年3期)2022-03-16 05:55:10
计算机工程与应用(2022年1期)2022-01-22 07:46:48
计算机工程与科学(2021年4期)2021-05-11 01:59:36
知识窗(2019年4期)2019-04-26 03:16:02
今日农业(2019年16期)2019-01-03 11:39:20
火力与指挥控制(2018年3期)2018-04-19 11:43:39
百花洲(2018年1期)2018-02-07 16:33:02
数学小灵通(1-2年级)(2016年3期)2016-11-15 08:56:16
