
基于随机森林算法的路面状况指数预测
2021-11-11 01:33:24裴莉莉户媛姣
公路交通科技 2021年10期
余 婷,裴莉莉,李 伟,户媛姣,杨 明
(长安大学 信息工程学院,陕西 西安 710064)
0 引言
公路从正式开始运营后会受到各种交通工具的荷载及自然环境因素的干扰,其路面的使用性能将不断衰弱,倘若无法及时进行检测与养护,愈发严重的道路破损将使路面使用性能极速减弱[1]。为及时对破损路面采取相应的养护措施,需要利用收集的路面使用性能数据,研究并掌握路面使用性能[2]的衰变特点,以便公路管理部门作出最佳养护决策。而传统的道路路况调查以人工调查为主[3],耗时长、效率低,在各种损坏情况和程度的判断上很容易产生严重的主观偏差,且各种损坏的判别界限具有模糊性,无法达到当前公路养护管理要求。
人工智能技术在近几年强势崛起,并且逐渐应用于交通、医疗、国防等生产生活中[4]。2019年全国交通运输工作会议的主旨就是以智慧交通为主导,加大交通运输与互联网、大数据、人工智能等技术的深层次融合,使交通运输决策更加科学化[5]。随着对路面使用性能的深入研究,世界各国学者开始尝试使用人工智能算法对路面使用性能进行预测[6]。李波等[7]和张亮等[8]分别采用主成分分析法和灰色马尔可夫模型对路面破损状况进行了预测。颜可珍等[9]建立了参数优化的最小二乘支持向量机模型,能够可靠地对路面性能作出评价。樊旭英等[10]在发现稀浆封层技术可有效减缓沥青路面低温病害发生的基础上,对熵权-层次分析法进行改进,建立了沥青路面预养护评价模型。Sollazzo等[11]利用路面长期性能数据库,采用人工神经网络模型来建立沥青路面平整度与结构性能之间的关系,发现人工神经网络优于经典的线性回归方法。Abdelaziz等[12]从一般路面研究和特定路面研究收集原始和重叠柔性路面的数据建立了国际平整度指数(International Roughness Index,IRI)预测模型,同样得出ANNs模型比回归模型预测准确度更好。Zhang等[13]基于权重分布理论讨论了Pavement ME Design模型和改进的灰色预测模型预测多年冻土区沥青路面横向裂缝的互补优势,并开发了考虑区域特征的组合预测模型。Li等[14]开发一种创新的基于模糊趋势时间序列预测和粒子群优化(PSO)技术的IRI预测模型,且该方法优于多项式拟合、自回归积分移动平均法。李海莲等[15]通过研究传统路面性能预测方法,利用改进的萤火虫算法加快支持向量机模型的寻优过程,验证表明该模型收敛速度更快,精度更高。
以上研究表明,支持向量机、神经网络等机器学习方法已广泛应用于路面性能预测建模,且预测模型具有较高精度。本研究通过对加拿大安大略省某公路的路面特征和路面综合状况指标等数据进行调查分析研究,构建随机森林路面状况指数(PCI)预测模型,再对所构建的模型的拟合效果和预测精度进行优化和评价分析,最终得到具有较高效率、较高精度和较低误差的预测模型来解决PCI的预测问题。
1 数据获取和数据预处理
首先利用ARAN9000多功能检测车获取加拿大安大略省某公路检测数据,再在了解各项数据特征后对其进行数据预处理,使得最后建立模型的预测效果更好。整体技术路线如图1所示。
1.1 基于ARAN9000的道路三维数据获取
路面自动化快速检测技术从对路面平整度、车辙等单一性能指标检测逐渐发展到了模块化的多功能路面综合检测。ARAN9000多功能道路检测车是由加拿大Fugro-Roadware公司研发的用于在高速公路上即时收集公路信息资料并进行数据处理的多功能检测车,它把精确的硬件勘察系统和功能强大的软件系统集成在一起,可实现对任何公路的数据采集计划。硬件系统包括道路平整度测量系统、路面病害测量系统、车辙测量系统等。软件系统包括Vision(一体化数据处理和分析软件套件)、Ivision(基于网络的应用程序)、Surveyor(路产管理应用软件)等。
图1 路面破损状况指数预测技术路线Fig.1 Technical route of PCI prediction
通过ARAN9000多功能道路检测车对加拿大安大略省21号公路进行数据采集,获取到该公路路面特征数据集,具体分类与示例见表1。
1.2 数据预处理
数据纷杂繁复且大部分会存在缺失值,甚至包含许多错误或虚假数据,在数据分析前对数据进行预处理,不仅可提升数据分析的质量,而且可节省实际分析所用的时间。
专业人员对原始数据进行了分析,并采用方差选择法去除了IDSession和Status等无关辅助特征,之后采用皮尔逊相关系数对余下特征因子进行了相关性分析。变量X和变量Y的皮尔逊相关系数ρX,Y公式为:
表1 数据集分类与示例Tab.1 Data set classification and examples
(1)
式中,cov(X,Y)为X与Y之间的协方差;σX为X的标准差;σY为Y的标准差。
根据分析结果去除与预测目标PCI相关性低的特征,最终得到包含路面特征在内的3 000多组数据。
此时数据中有大量的裂缝数据缺失,但由于每段路面不一定包含所有裂缝特征,因此和专业技术人员沟通并对比均值填充、拉格朗日插值等数据修复效果后,采用填零的方法修复缺失数据。其次发现预测目标PCI有19行数据缺失,相对于整体数据量来说比例较小,所以选择直接删除。
经过特征筛选后,数据分布仍存在明显的不平衡性,此现象可由图2中原始特征变量数据的均值、方差看出,同时每个特征变量的极值之间差距较大。因此,为避免不同特征变量数据分布差异性导致的模型过拟合现象,必须对原始数据进行标准化操作。
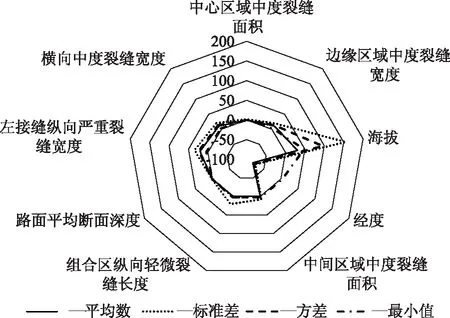
图2 部分特征变量的描述性统计Fig.2 Descriptive statistics of some feature variables
采用离差标准化方法把数据映射到0~1范围之内,用式(2)转换:
(2)
式中,x*为标准化后的值;x为数据原始值;min为最小值;max为最大值。
经归一化处理后,无论是模型的收敛速度还是模型的预测速度都有了大幅度提升。
2 基于机器学习的PCI预测
2.1 随机森林
随机森林(Random Forest,RF)[16]是bagging集成学习算法演变而来的基于决策树的机器学习算法。用随机方式构建一个由多棵互相独立决策树组成的森林。通过对特征划分结果的优劣进行不纯性度量,并计算信息增益来选择分裂特征。从根节点按照特征划分条件和节点纯度最小原则,向下分裂直到满足规则时停止,最终的预测结果是对每棵决策树结果的加权平均值。基本原理见图3。
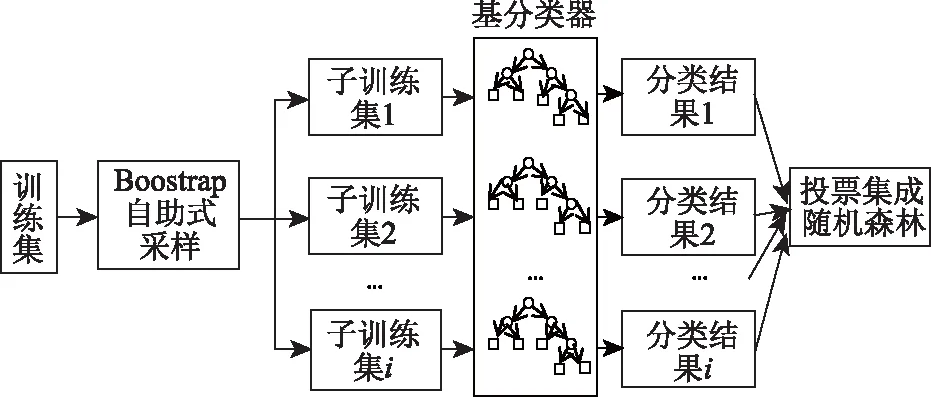
图3 随机森林算法基本原理Fig.3 Basic principle of random forest algorithm
通常用信息熵[17]作为衡量数据集纯度的一种指标。设第k类数据占所有数据集X的比例为pk(k=1,2,…,n),则定义数据集X的信息熵为:
(3)
若H(X)的值越小,那么数据集X的混乱程度越低,纯度越高。
假设使用离散特征a来对数据集X进行划分,就会产生V个分类结果,其中第V个分类结果包含的所有数据,记为XV。根据式(3)计算出XV的信息熵,再考虑到不同的分类结果所包含的数据量不同,因此给每个分类结果给予1个权重|XV|/|X|,表明数据量越多的分类结果作用越大,于是计算利用特征a对数据集X进行分裂所获得的信息增益:
(4)
通常来说,Gain(D,a)值越大,就说明利用特征a来进行分裂后,数据集的复杂度减小得越多,分类的结果越明显。
随机森林在有放回地从原始的数据集上随机抽取m个子样本的基础上,在训练单个决策树时,再随机选取k个特征,并从这k个特征中选择最优特征来分裂节点,这使得随机森林模型不会轻易过度学习训练集的特征,且降低了模型的方差。实现流程图如图4所示。
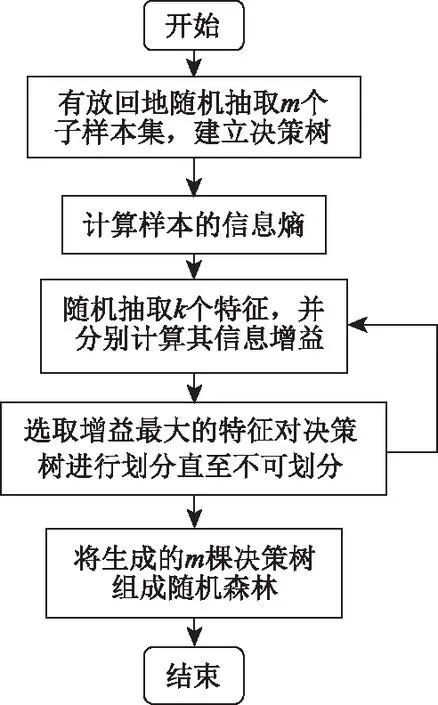
图4 随机森林算法实现流程Fig.4 Implementation process of random forest algorithm
2.2 其他模型
2.2.1 多元线性回归
多元线性回归算法是利用最小二乘法来拟合回归方程,主要用于处理多变量间的关系,即建立因变量y与多个自变量x之间的统计关系。其数学模型为:
y=β0+β1x1+β2x2+…+βpxp+ε,
(5)
式中,y为因变量;x为自变量;β为自变量x的系数;p为自变量的个数;ε为预测值与真实值之间的残差。
2.2.2 BP神经网络
神经网络模型是一种分布式并行运算的模型[18-19]。输入信号首先经过加权到隐藏节点,再通过激活函数,从隐藏节点输出并经过加权传播到输出层节点,最后输出层处理得到输出结果,结构见图5。
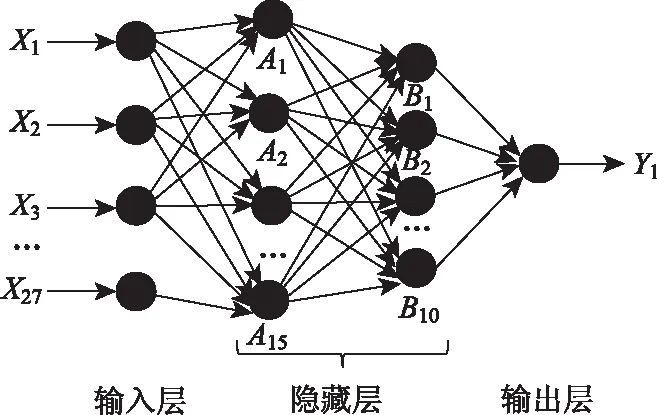
图5 多层前向神经网络的结构Fig.5 Structure of multilayer forward neural network
(6)
网络训练要使J的值最小,其权值的训练算法可描述为:
(7)
式中,w(t)为t时刻的权值;η为学习率[21]。
在进行模型构建时,首先需要确定BP神经网络模型的结构,其次根据BP算法进行训练,具体流程如图6所示。
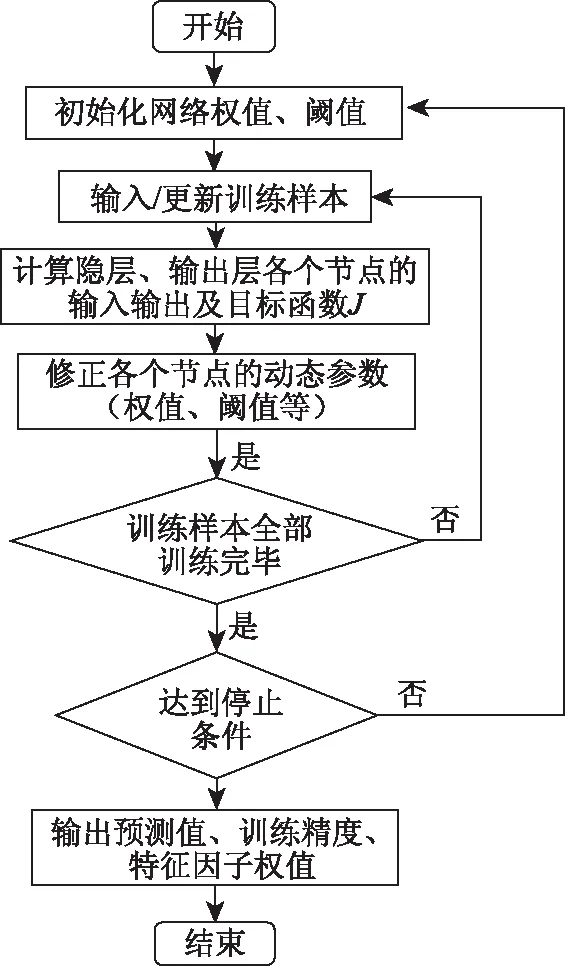
图6 BP神经网络模型的流程Fig.6 Flowchart of BP neural network model
3 模型预测结果与对比
3.1 模型评判标准
为了对模型的预测结果进行定量分析与比较,采用复相关系数R2、均方根误差(Root Mean Square Error,RMSE)和平均绝对误差(Mean Absolute Error,MAE)作为评价模型性能的指标。如果数据点大多分布在拟合回归线附近,则表明模型预测精度较高,误差相对较小。计算公式如下:
(8)
(9)
(10)
式中,x为变量的值(本研究指PCI);xi(i=1,2,…,n)为真实值;x′0为xi的平均值;xp为xi的预测值;n为测量值的总个数。
3.2 模型预测结果
3.2.1 多元线性回归预测结果
将路面检测状况和往年路面评价指标作为自变量,PCI为因变量,得到表2所示的多元线性回归性能结果。可以看出,该模型的精度较低,而误差较大。

表2 多元线性回归性能结果Tab.2 Multiple linear regression performance result
3.2.2 BP神经网络预测结果
构建神经网络模型首先选择1层隐藏层,再根据预测精度高低,增加隐藏层层数,从而提升预测精度,神经网络性能结果如表3所示。

表3 BP神经网络性能结果Tab.3 BP neural network performance result
从以上预测结果可以看出,当只有1层隐藏层时,隐藏神经元个数为14的R2为0.670,RMSE为4.542,MAE为3.035,此时预测结果最好。因此选择在第1层隐藏层神经元为14,并在此基础上增加网络层数来提高模型预测精度。
第2层隐藏层设置神经元个数5和10进行对比分析。由表2可知,BP神经网络模型预测PCI的R2从0.669增加到0.711,预测结果得到显著提升。
3.2.3 随机森林预测结果
同样选取27个路面特征作为输入样本,默认参数设置如表4所示,采用随机森林算法进行训练,得到默认参数的情况下随机森林模型的预测结果,如表5所示。

表4 随机森林默认参数值Tab.4 Random forest default parameter values

表5 随机森林模型的预测结果Tab.5 Evaluation result of random forest model
为了使随机森林模型能够更准确地预测PCI,采用5折交叉验证结果调整随机森林模型参数,使随机森林模型预测精度提升。5折交叉验证的具体过程如图7所示。
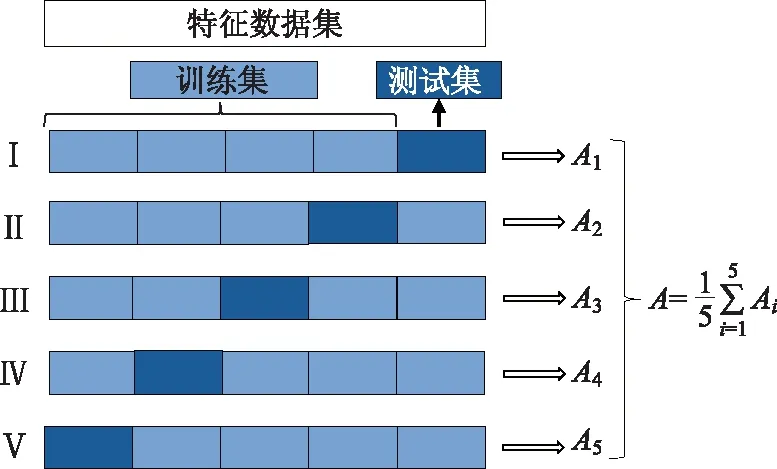
图7 五折交叉验证Fig.7 Five-fold cross-validation
在默认参数情况下,采用网格搜索法固定其他参数,依次调节任一参数在不同范围内的参数值,然后找到在该范围内的最优值,以该值为中心逐步缩小调节范围,直至逼近最终的最优参数值。
由表5可得,在默认参数的情况下,随机森林模型的R2为0.895,RMSE为2.710,MAE为1.958,预测效果较好,但仍存在一定误差。而改进后的模型拟合效果更好,并且R2也从0.895提升到0.898,误差也相应地减小。因此,改进后的模型更适合本研究的数据预测,预测精度更高。
在调参试验中发现,由于本研究数据集样本量较小,调节节点分枝最小样本数和叶子节点最少样本数对模型性能影响较小。因此使用默认值,即节点分枝最小样本数为2,叶子节点最少样本数为1。各参数值与对应精度变化曲线如图8所示,最优参数设置如表6所示。

图8 各参数最优值与对应精度变化曲线Fig.8 Optimal parameter values and corresponding accuracy variation curves
同时,由于输入变量较多,无法通过简单的统计分析确定应修正或删除的异常数据,因此选择在完成模型构建并预测后,通过预测值与真实值的拟合效果确定异常值。由拟合效果知远离拟合直线的异常点仅有13个,相对于整体数据来说比例较小,所以选择直接删除这些异常值。最后使用去除异常值后的数据重新作为训练集对模型进行循环训练,使之达到当前模型训练最优。
3.3 结果对比与分析
通过调整输入参数,选择预测结果最优的模型进行结果输出,4种模型对PCI预测的拟合效果如图9所示,散点在直线周围分布越紧凑,预测效果越好。相应地,表7展示了4种模型预测结果与实际值之间的复相关系数、均方根误差和平均绝对值误差。由式(8)~(10)可知,复相关系数越接近于1,误差越接近于0,预测性能越好。从图9中可以看到,与PCI的真实值相比,基于传统的多元线性回归的预测结果性能最差,而基于BP神经网络模型的预测结果获得了较大的提升。

表6 随机森林模型最优参数值Tab.6 Optimal parameter values of random forest model
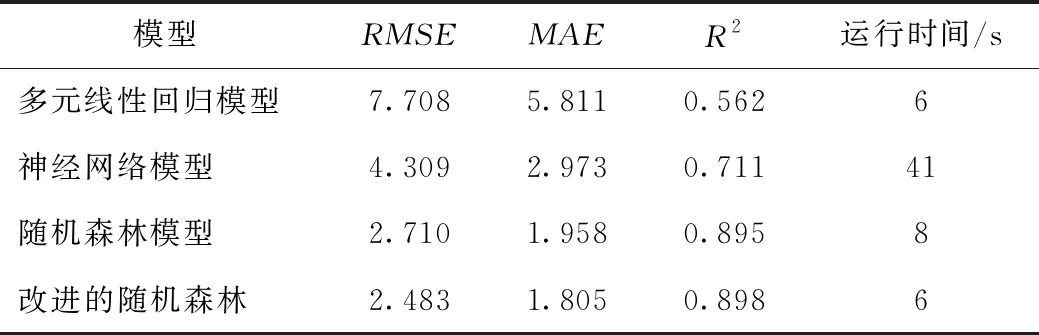
表7 四种模型的性能结果Tab.7 Performance results of 4 models
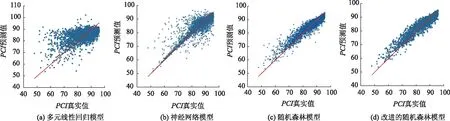
图9 四种模型的拟合效果Fig.9 Fitting effects of 4 models
然而图9(b)中仍有部分数据远离线性回归直线,而图9(c)中远离回归线的异常点明显减少。由于随机森林模型对处理高维度数据(特征较多)和抗过拟合能力较优,使得该模型不仅获得了较好的预测结果,而且训练速度提升了33 s。最后改进后的随机森林模型解决了图9(c)中仍有部分数据距回归直线较远这一情况。
由表7得,改进的随机森林模型的R2值为0.898,RMSE为2.483,MAE为1.805,训练时间缩短了2 s。由图10也可看出,改进后模型的随机森林预测误差整体较小,不仅优于多元线性回归和神经网络预测模型,而且更适于本研究的数据预测。
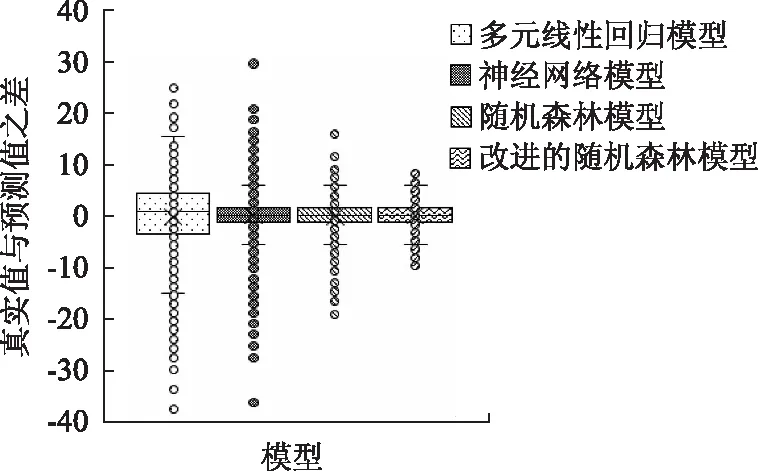
图10 四种模型的预测误差Fig.10 Prediction errors of 4 models
4 结论
本研究通过对从ARAN9000多功能道路检测车采集到的相关数据进行数据处理与统计分析,选择主要的路面特征和往年路面评价指标作为输入变量,路面状况指数PCI作为输出变量,构建基于随机森林、神经网络和多元线性回归的PCI预测模型。对比结果表明,随机森林模型预测PCI的精度最高,误差最低,且训练速度提升了近33 s;其次采用去除离异项和交叉验证对模型进行优化,得到R2为0.898,提高了0.003。改进后的随机森林模型能够有效地对PCI进行预测。
本研究提出的随机森林预测模型能够有效解决路面状况的预测问题,为养护决策的制订提供科学的数据支持和理论依据。精确的预测结果可帮助公路养护管理部门及时采取养护措施,从而保证路面良好的使用性能,降低养护成本。
猜你喜欢
疯狂英语·新悦读(2019年11期)2019-12-18 05:14:16
电子制作(2019年19期)2019-11-23 08:42:00
作文大王·笑话大王(2017年1期)2017-02-21 16:08:53
作文大王·笑话大王(2016年10期)2016-10-18 14:58:58
作文大王·笑话大王(2016年7期)2016-08-08 11:28:43
重型机械(2016年1期)2016-03-01 03:42:04
作文大王·笑话大王(2016年2期)2016-02-24 11:27:15
大连工业大学学报(2015年4期)2015-12-11 04:06:52
专用汽车(2015年4期)2015-03-01 04:10:02
浙江大学学报(工学版)(2015年1期)2015-03-01 01:17:31
