
国产大数据平台在信息系统领域的应用研究
2021-11-11 08:32朱洪斌胡珊珊
电子元器件与信息技术 2021年7期
朱洪斌,胡珊珊
(1. 扬州万方电子技术有限责任公司,江苏 扬州 225000;2. 南京邮电大学通达学院,江苏 扬州 225000)
0 引言
随着信息化技术的迅猛发展,信息系统数据趋于多样化、多元化、海量化,且具备空间结构化特性,适用于关联分析。因此,需要有特殊架构的预处理、存储、管理、计算、服务等相应方法来解决大数据的有效使用问题。同时,随着国产化自主可控进程的深入推进,我国高度重视关乎国家命脉的关键领域的信息安全,要求涉及国家信息安全的核心领域信息系统采用国产化设备。面向信息系统应用需要研制的国产大数据机,符合国家信息安全政策导向,从CPU芯片、服务器硬件到操作系统、基础支撑软件和大数据软件都实现了完全国产化[1-2],推动了自主可控技术的发展,提高了大数据处理能力。
在采用自主可控软硬件搭建国产大数据平台,对信息系统中多源、异构、海量、递增的数据进行存储及处理时,亟待解决的问题如下:
(1)构建自主可控、高可靠、高性能、可扩展的大数据处理平台;
(2)建立统一、高效、协同、精确的查询机制,实现数据的快速查询与检索;
(3)设计简洁交互和直观可视化的管理系统,实现对大数据集群的监控与运维。
1 大数据在信息系统领域的应用需求
我国的信息系统经研究过多年发展和积累,已经从跟踪效仿国外技术,进入既引进吸收、又自主创新的复合型发展阶段,很多研究成果已经广泛运用于军事和民用诸多场景之中。而随着信息系统复杂度的日益提升,每天会产生大量的信息数据,给信息系统的运维管理带来困难。
信息系统中对数据处理的要求主要有:(1)针对情报、遥感、气象、指挥[3]等信息系统应用场景,需要处理复杂、多样、海量特点的数据,例如在遥感数据方面,高分辨率、高动态的新型卫星传感器具有波段数量多、光谱分辨率高、重访周期短、单位时间内获取的数据量庞大等特点。(2)针对办公、监测、指挥等信息系统应用场景,需要保证数据处理的实时性和可靠性,并结合数据挖掘与智能分析,提供高效存储与检索、可视化分析、推荐排序和按需弹性扩展等功能。
传统的数据存储管理架构已无法满足上述信息系统数据处理要求,需要根据实际业务、技术、定制、安全和自主可控等需求,依托云计算大数据应用成果,研究满足信息系统数据应用需要的大数据处理平台,提升应用效能。
2 国产大数据平台建设
当前国家对信息安全[4]有着迫切的形势要求,大数据处理技术的相关软硬件的国产化具有战略意义。
Hadoop、Spark等大数据技术作为典型大数据软件[5],目前已在国产申威平台完成了对应的生态系统源码编译、移植、适配及优化,为国产大数据平台打下支撑。利用申威虚拟化技术扩充集群规模,基于Ceph、HDFS构建分布式文件系统,实现海量存储,使用MapReduce、Spark框架实现分布式并行处理,使用Hbase、MongoDB实现数据文件存储[6],采用主从备份架构实现系统高可用,为国产申威大数据处理系统提供分布式计算、分布式存储能力以及内存计算,为上层应用系统提供数据库、数据仓库支撑。
2.1 国产大数据平台架构
国产大数据平台主要基于云计算虚拟化技术,充分发挥CPU能力,提升集群规模,实现底层的分布式存储和计算,使用户在开发大数据应用时无需关心底层硬件、虚拟化状态以及分布式计算的实现等细节。同时,在集群上进行了重要组件的适配和优化,将检索查询、图算、机器学习、数据挖掘、实时数据处理等模型统一到一个基础平台下,并以一致的接口API公开,提供各类业务应用信息引接,多源数据处理的国产大数据平台服务,并能提供各类大数据处理、分析工具,对各类业务信息、多源数据做分析、提取,为辅助决策系统提供有效支撑,如图1所示。
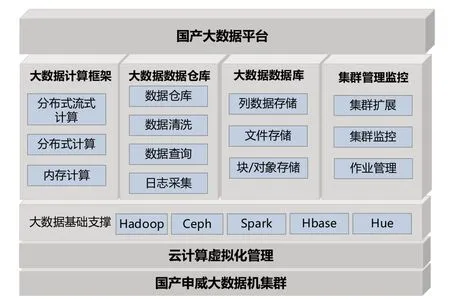
图1 大数据平台基础架构
国产大数据平台提供大数据计算框架、数据仓库、数据库、集群管理监控等功能模块,并提供API接口方便用户构建分布式计算应用。针对不同的应用场景,如存储、离线计算、分析挖掘等,能够有针对性地对配置进行优化,具备高度的可定制性和扩展性。
2.2 国产平台相关优化
根据行业应用特征对国产申威大数据机进行定制优化,如JVM优化、数据压缩传输、参数自动调优。要充分考虑申威机器特点,需尽量避免和Java、CPU交互过多等。
(1) 针对国产平台下Hadoop集群固有的任务级调度分配方法在运行中存在的负载分布不均的现象,以节点当前的负载状态作为参考标准,评价节点计算资源的利用程度,根据评价值再对节点运行任务的数量进行调整,使集群资源维持在一个高效利用的状态。
(2) 大数据系统中,好的压缩算法可以有效降低存储开销及传输时间,而分布式计算的场景各不相同(如存储、计算等),要注意选择最优的压缩算法。压缩比率大会导致性能下降,数据规模大会占用大量CPU资源。
(3) 将一台国产大数据机(宿主机+3虚拟机)视为一备份规模,避免数据块的备份在这四节点中多次备份而形成的数据丢失风险(节点宕机、电源故障等情况)。
3 平台性能测试对比
3.1 软硬件环境
国产申威大数据机设计用于云计算集群节点,基于面向服务器应用的16核国产高性能SW1610 CPU,支持扩展64GB内存,拥有全千兆互联网口,数据存储容量不低于20TB,具备高性能、高可靠性、高集成度和低功耗特性。
测试使用的硬件环境为1台国产大数据机服务器,虚拟机全开共4节点,单服务器配置如表1所示。
3.2 测试结果
测试2TB交通卡口数据,约1亿条,申威平台下的MySQL与大数据平台的查询时间如表2所示。

表2 测试结果
测试结果显示,在数据量达到亿级别时,在国产平台上,大数据平台的查询性能和稳定性远高于MySQL。同时,申威平台下的大数据平台在优化后,性能已经接近同等配置的X86服务器,能够满足实际应用中对海量数据的存取要求。
4 结语
国产大数据平台以申威大数据机作为基础硬件,通过虚拟化为大数据处理提供资源池,形成大数据处理集群,软件在集群上进行了充分的适配和优化,具有高集成度、高处理能力、高可靠和高安全等特性。基于国产大数据平台,现有的一些基于Hadoop和HBase开发的程序可以更加简单地迁移到国产服务器系统上,为解决信息系统数据的分布式存储与计算提供了自主可控的软硬件支撑。
猜你喜欢
哈尔滨轴承(2022年1期)2022-05-23
心理学报(2022年4期)2022-04-12
水泵技术(2021年3期)2021-08-14
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年11期)2018-08-04
电子制作(2018年11期)2018-08-04
消费导刊(2017年20期)2018-01-03
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
现代工业经济和信息化(2016年12期)2016-05-17
