
基于YOLOv3算法和深度特征的地点识别方法
2021-11-10 11:39卜雄洙
江苏大学学报(自然科学版) 2021年6期
牛 杰, 钱 堃, 卜雄洙
(1. 常州信息职业技术学院 电子工程学院, 江苏 常州 213164; 2. 南京理工大学 机械工程学院, 江苏 南京 210094; 3. 东南大学 自动化学院, 江苏 南京 210096)
视觉地点识别是移动机器人场景认知与导航的前提.传统识别方法主要依赖手工特征,结合精心设计的分类器进行场景类别判断,取得了较好的识别效果.但是,当机器人在现实世界的环境中运行更长的时间,特别是周围环境条件发生较大变化时,传统方法的识别效果明显下降.近年来,随着深度学习技术的发展,以卷积神经网络为代表的算法在诸如物体检测、物体识别和场景识别等方面应用十分广泛.深度特征在视角变化、环境外观变化等方面具有显著优势.LI Q.等[1]根据图像深度特征构造相似矩阵,完成了地点识别任务.P. NEUBERT等[2]针对场景季节变化所带来的外观变化问题,设计了卷积神经网络(convolutional neural networks,CNN)特征用于图像匹配,取得了较好的试验效果.以上方法至少存在一个问题,即由于深度网络的训练过程费时,需要高性能的硬件设备和调优参数,研究人员倾向于使用预训练CNN网络模型作为特征提取工具,模型的训练数据集都是以物体识别为目标的数据集[3].而地点识别应用往往受到视角、光照和动态对象等因素影响,因此,直接使用预训练模型在整个图像上提取特征是不合适的.
为了解决上述局限问题,研究人员试图在图像中智能地选择有用信息来识别位置.N. SÜNDERHAUF等[4]将似物性检测技术引入地点识别应用中,对深度特征的效用和视点不变特性进行了深入地研究.考虑到并非图像中所有内容都对表示地点的信息起到正向作用[5-6],XIN Z.等[7]提出了1种基于CNNs特征和语义信息的多尺度地标来完成地点识别任务.CHEN Z.等[8]首先利用图像显著性检测技术筛选出显著物体,并提取CNN特征,系列试验表明该方法对于视角和环境的外观变化具有一定的鲁棒性.然而,上述方法在图像区域筛选时缺乏自上而下的过滤机制.例如,在识别停车场地点时,如果误用汽车或行人等时变对象的特征,就会将错误信息引入地点识别.
为此,笔者提出1种基于YOLOv3算法和深度特征的地点识别方法,用以解决图像区域筛选时的过滤机制问题,从而更好地提高视觉地点的识别效果.
1 算法整体流程
算法整体流程图如图1所示.首先利用先进的显著目标检测算法分割出候选路标信息,然后采用改进的YOLOv3算法,将不适合环境建模的区域去除,最后提取筛选后的路标深度特征,降维后实施图像匹配.不同于对整个图像进行特征提取和匹配,本方法仅在经过2次筛选的图像显著区域提取深度特征,能够为后续图像匹配提供更加有效的信息.

图1 算法整体流程图
2 候选显著路标提取与筛选
在移动机器人环境建模与定位应用中,可以将环境中的显著物体作为路标来表示环境,该策略在未知自然环境相关机器人应用中有着良好的应用前景[8].HOU Q.B.等[9]通过在深度网络架构内引入跳层结构的捷径连接,提出了1种显著目标检测方法,该方法利用全卷积神经网络提取的多级和多尺度特征,为每一层提供更高级的表征.综合考虑准确率和执行效率等因素,笔者选择该方法作为初始显著路标的检测算法.
获得一系列初始候选路标之后,不同于直接在这些图像上提取特征的常规做法,笔者加入了对于候选路标区域的筛选操作,以滤除掉不适合环境建模的物体类别区域.该方法基于YOLOv3算法构建物体分类模型.YOLOv3算法采用了Darknet-53网络结构,利用多尺度特征进行对象检测,提供了9种尺度的先验框,预测对象类别时使用logistic回归方法中的输出模型进行预测,以便支持多标签对象.具体实施过程中,对原始YOLOv3算法做了修改,以提升模型性能.
首先,为了适合平均准确率指标,修改YOLOv3算法中的损失函数smoothL1 Loss为损失函数IOULoss,用以对检测框做回归.其次,针对输入图像,运用YOLOv3算法将其映射到3个尺度的输出张量.在输入尺度为416×416的情况下,特征图的尺度分别为13×13、 26×26和52×52.然而,原始YOLOv3算法网络中用到的上采样操作本身就是1种相对比较耗时的过程,由于本研究中的输入图像已经经过显著目标检测算法分割,可以认为在小尺度上不存在其他物体.因此,在不损失网络精度和网络思想的前提下去掉网络的上采样过程,只选择13×13的单一尺度进行计算.为此,聚类出的先验框数量可以从10 647个(即13×13×3+26×26×3+52×52×3个)减少到了507个(即13×13×3个),从而提升了处理速度.
根据KOH P. W.等[10]的研究,迁移学习训练时,即使训练集中的单个样本也会影响最终测试损失.受此启发,笔者采用WANG T.Y.等[11]提出的针对训练数据的提纯方案,选取在ImageNet数据集上预训练的Darknet-53作为主干网络提取图像特征数据,并在COCO检测数据集上预训练,得到初始模型权重参数.然后根据该模型计算实际数据集中每个样本的影响,并删除减少验证集损失的样本.
遵循上述数据集提纯步骤获得新优化的训练集后,根据预先人为指定的不适于环境建模的物体类别数量,修改相应配置文件参数,进行物体分类模型训练.随后将显著图像送入模型,再将不适合环境建模的特定目标类别图像删除,从而完成对于显著路标区域的二次筛选.
3 相似性计算

(1-ε)‖u-v‖2≤‖f(u)-f(v)‖2≤
(1+ε)‖u-v‖2,
(1)
式中:u和v为原始高维空间的向量,u,v∈Rd;f为映射函数,可以用投影的方法获得,定义矩阵A∈Rk×d,f(u)-f(v)就转化为Au-Av.根据上述引理,笔者应用经典的高斯随机投影[15],将原始特征转移到低维度的空间,试验中将64 986维降到1 024维进行后续图像匹配计算.
经过上述步骤的图像匹配环节后,为确定当前图像a和候选地点图像b的相似度,提取经过筛选的对应图像候选路标,并设计式(2)进行相似度计算,即
(2)
式中:Sab为相似度;dij为经过处理后的当前图像显著区域描述向量与数据库中地点的区域描述向量的余弦距离;na和nb分别为从图像a和b中提取出的显著路标数量,最终选取相似度得分最高的数据库图像所在地点标签作为结果输出.
4 试验及结果
为验证算法性能,笔者选取地点识别应用中公开的3个数据集进行算法对比测试.3个数据集名称及各自特点如表1所示.

表1 测试数据集描述
对比方法包括FAB-MAP[16]、SeqSLAM[17]和Place-CNN[14]等3个先进方法.其中,FAB-MAP是基于人工特征进行地点识别和建图的经典方法.SeqSLAM是基于视频序列的方法,它使用全局HOG描述符,被认为是最成功的地点识别算法之一.Place-CNN是在Places205数据集上训练的基于深度学习的识别模型.
图2为Garden Point数据集准确率-召回率(precision-recall,PR)关系的拟合曲线.根据测试方法在Garden Point数据集上的表现可知:本研究方法明显优于其他方法,平均准确率为74.54%;在该数据集上,FAB-MAP方法的平均准确率仅为10.40%,原因是FAB-MAP是专注于在地图和定位应用程序中使用的位置识别方法,FAB-MAP的人工特征在处理环境变化方面没有深度特征的优势;在该数据集上SeqSLAM方法的性能优于Place-CNN方法,这主要是因为SeqSLAM方法采用序列匹配代替单个图像匹配来进行位置识别,这与当前数据集的图像特征非常吻合.

图2 Garden Point数据集PR曲线
在St.Lucia数据集上的PR曲线如图3所示.由图3可知:由于该数据集中的图像在亮度和外观上变化较大,基于人工特征的FAB-MAP方法和SeqSLAM方法均表现不佳;当基于深度特征时,可以观察到Place-CNN方法的准确率提升明显;在该数据集上,本研究方法表现最好,平均准确率达到73.36%,比Place-CNN平均准确率提高约5.00%,这主要得益于相较在整幅图像上的特征提取,本研究方法使用了筛选后的显著路标深度特征,应对环境变化更加具有鲁棒性.
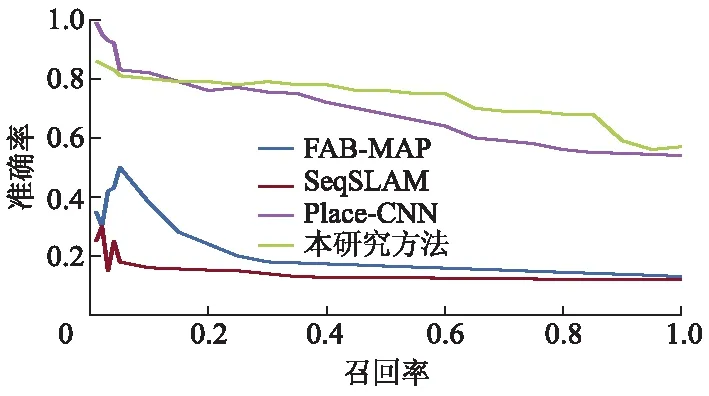
图3 St. Lucia数据集PR曲线
Nordland数据集上的PR曲线如图4所示.由图4可知,本研究方法相较于其他方法依然具有较大性能优势,平均准确率达到了65.76%,相比于SeqSLAM(平均准确率为30.30%),提高了35.00%以上.此外,值得注意的是,Place-CNN方法在Nordland数据集上的效果较差,这主要是因为数据集中序列的外观发生了巨大变化,并且每个季节仅记录1次.由于Place-CNN方法从整个图像中提取特征,因此存在很多冗余特征.当环境外观发生巨大变化时,模型的性能会严重下降.因此,采用本研究方法,3个数据集上平均识别准确率达到71.22%.

图4 Nordland数据集PR曲线
5 结 论
1) 笔者提出1种利用YOLOv3算法和深度特征进行地点识别的方法.与在整个图像上提取特征相比,本研究方法可以自动选择图像中的显著物体作为候选路标区域.
2) 为获得更准确的路标信息,笔者设计了改进的YOLOv3算法网络,有效地删除不适合建模的特定物体类别.
3) 多个数据集上的对比试验结果显示,该方法的平均识别准确率最高,达到71.22%,在PR曲线指标上也取得了最佳结果.
此外,本方法也存在未考虑动态物体对环境建模的影响,以及模型相对比较复杂等问题.后续的研究中,将尝试以端到端的方式优化网络结构,在建模过程中去除动态物体干扰,引入暹罗网络判断相似性等策略,进一步提升模型地点识别性能.
猜你喜欢
读写月报(初中版)(2021年12期)2021-05-25
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中国交通信息化(2018年5期)2018-08-21
数学小灵通·3-4年级(2017年9期)2017-10-13
