
基于YOLO与图像处理的塔吊裂缝研究①
2021-11-10 02:56张神德陈国栋
佳木斯大学学报(自然科学版) 2021年4期
张神德, 陈国栋
(福州大学物理与信息工程学院,福建 福州 350108)
0 引 言
据统计仅仅2012-2014两年间塔式起重机安全事故就有162起,其中因为各种缺陷导致的事故占总事故的87.04%[1],近几年来的事故数目不减反增,塔式起重机由于其事故的多发性已经成为工地危险源之一。现有的针对塔式起重机的安全管理监督还是以人工检查为主,然而人工检查成本高,检查人员的人身安全得不到保障,且塔式起重机随着楼层的增高不断增加标准节,常常高达几十米,许多偏僻而又危险的角落难以被察觉。在日常的搬运、承重、转移作业中存在出现裂缝、开裂等潜在的安全隐患。
基于深度学习的目标检测技术研究一直是热门领域,算法已经逐渐成熟,识别捕捉能力也越来越好,以R-CNN为代表的两阶段检测方法检测精度良好,以YOLO[2]为代表的单阶段检测不依赖候选区的方法则拥有极佳的识别效率,两种方法都被广泛应用于缺陷检测领域,诸如钢板缺陷、路面裂缝、桥体缺陷、工件锈迹等等,都取得了良好的效果。针对塔式起重机存在的安全隐患与监督检查困难问题提出基于YOLO的裂缝识别方法,配合无人机等工具进行拍摄监督,识别出缺陷时从图像中提取缺陷并通过图像处理算法进行定量分析,最终得出数据为专业人员进行安全评估提供部分数据参考,帮助塔式起重机在拆装与工程作业过程中更好得安全维护与监督,为工程施工提供更好的保障。实验表明在塔式起重机的安全检查中具有很高的使用价值。
1 YOLO算法模型
YOLO算法将识别过程统一为一个回归过程,相对于两阶段检测方法更加轻量高效,在YOLO v1中通过前特征提取网络中卷积降维得到固定大小的特征图如图1所示。然而该种方法虽然速度非常快但是精度差强人意,特别是针对相互靠的很近的目标或很小的识别目标的捕捉较差。在YOLO的第二代算法中针对第一代出现的问题进行了改进,在上一代的基础上卷积层进行了批归一化,增加了多尺度和更高分辨率的图像做输入。在删除了全连接层的同时引入了Anchor Boxes的先验框机制,以Darknet-19 特征提取网络为基础,实现了更好的识别效果,同时网络也更容易训练[4]。
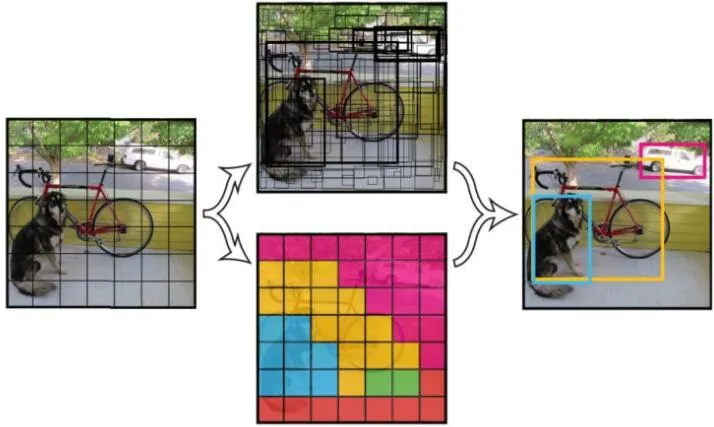
图1 YOLO
YOLOv3继承了YOLOv1,v2的优点,Darknet-53更深的网络结构可以获得更好的特征信息,同时YOLOv3增加了多尺度融合的特征预测目标,充分捕捉各种尺度下的信息特征,精度大大提高,最后再经过非极大抑制算法下得到最好的目标识别结果,如图2。

图2 YOLOv3结构
YOLOv3牺牲了一部分识别速度改善了前两代算法对小目标识别捕捉不敏感的缺点[6]。识别精度虽比较Faster RCNN算法[7]等稍低但识别速度非常快满足实时快速捕捉的需求更适合针对塔式起重机缺陷识别中通过无人机等方式对裂缝等缺陷的快速识别。参考塔吊实际裂缝检测中出现的问题和需求,选择YOLOv3作为识别定位算法,通过定位获取的图像中裂缝所在位置,返回坐标,根据YOLOv3捕获的信息提取裂缝进行进一步的定量分析操作。由此来完成塔吊裂缝的定位、定量工作。
2 训练策略
2.1 数据集与数据扩展
数据集以各类塔式起重机承重裂缝、变形裂缝和断裂裂缝为基础,为了达到更好的识别效果加入了1202张与塔式起重机标准节材质类似或与塔式起重机裂缝纹路相似的经过筛选后获得的铁轨裂缝、工件裂缝、钢板裂缝和器材裂缝图片共计7206张。实际使用时以识别目标并为图像处理算法提取目标为主,故不对裂缝分类训练时统一命名为crack。
如果数据集不够大则模型效果差强人意,因此为了扩大数据集,在7206张塔式起重机裂缝和类似裂缝的数据集基础下为了检测效果对数据集进行数据增强:为提高检测效果,对现有的数据集进行数据扩展来增加数据集的基数,包括:将部分图片进行随机数值的随机旋转后,再进行90°的旋转;对部分图片的进行横向或者纵向随机方向的平移;以(0.9,1.1)的比例对部分图片进行水平或竖直方向拉伸或者压缩等。通过数据增强手段来扩充数据集的基数,帮助提高训练效果。如图3所示:

图3 数据增强
2.2 环境配置与参数设置
实验在64位Window 10操作系统上进行,CPU采用Inter Core i7-7700K,GPU采用NVIDIA GeForce GTX 1080Ti,内存16GB,显存11GB。
训练时参数设置如表1所示,其中初始化设置学习率为0.001,当迭代至损失表现收敛时可停止训练。根据比较保存损失最小的模型参数由此来完成训练。

表1 训练参数
3 裂缝缺陷识别与定量处理
3.1 效果与评价指标
为评价对塔式起重机进行定位的性能,针对训练后的网络进行测试,计算其对目标的召回率和准确率:
其中,TP为正确预测为塔吊裂缝的个数,FP为将未能预测个数,FN为错误预测的个数。mAP为平均精度。
训练好的模型识别效果如图4所示,实验结果表明mAP可达80.53%,且平均识别速度达到37f/s,基于YOLOv3算法的良好识别能力基本满足捕捉检查时裂缝的能力。在成功捕捉目标时,基于YOLOv3所提供的目标坐标等位置图片位置信息对目标区域进行提取。

图4 识别结果
3.2 图像处理
通过YOLOv3与区域图像提取我们可以得到目标区域图像。但是目标检测算法只能实现定位能力,具体几何参数需要针对提取的图像区域进行图像处理,如图5所示。

图5 裂缝区域提取
算法操作基于灰度图像进行所以首先将图像转换为灰度图像并针对转化后的图像进行图像增强,选择分段式线性变换[8]提高图像的对比度与品质,对于提取的裂缝图像光度较暗的区域需要灰度拉伸,设置K值进行灰度扩展;相对应的光度较强的区域灰度压缩如图6:
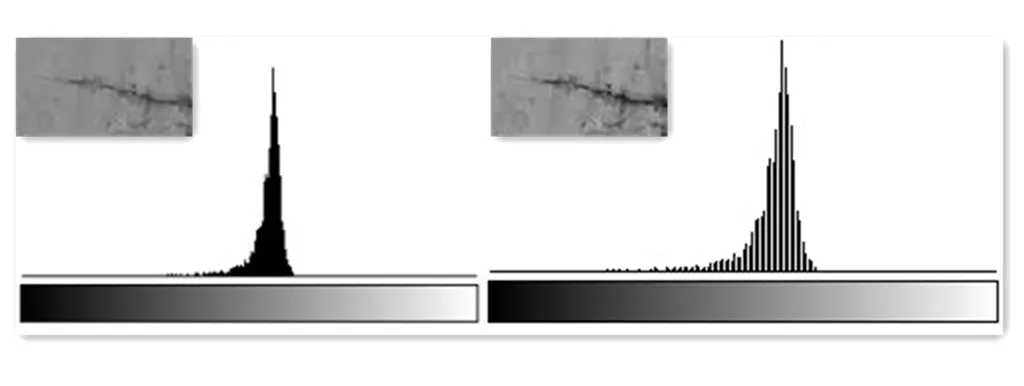
图6 分段式线性变换与灰度直方图
为了消除图像中离散的噪点,需要对处理后的图像滤波处理,中值滤波相对于均值滤波等算法针对椒盐和脉冲噪声处理效果良好。经过实验3×3为模板的中值滤波降噪效果良好,消除噪点的同时不会对裂缝的细节过分模糊化。实现降噪后的图像可以阀值分割处理提取裂缝语义模型,如图7所示实验通过比较最小误差法和Otsu最大类间方差法的处理效果可以明显看出Otsu的处理效果更好,从图中捕捉裂缝轮廓,排除了大量干扰信息。类间方差核心公式如图8所示。

图7 最小误差法与Otsu
获取的图像进行膨胀腐蚀处理。膨胀腐蚀相当于给与图像一个滤波处理窗口,膨胀后腐蚀即消除一些无用的噪点同时保持裂缝区域的完整性、连续性轮廓。膨胀与腐蚀核心公式与效果如图8所示。最后消除孤立噪声并优化处理,就此目标区域图像裂缝以二值图像的形式并提取了较为完整的裂缝。

图8 图像处理流程
根据获取的像素图像遍历像素后经过轮廓跟踪和区域面积测量可以很快得到面积、宽度、长度、周长等数据。本例中面积为379pixel,周长156pixel,纵深74pixel。上述数据都是基于像素值计算的,实际应用时获取拍摄距离d即可换算实际尺寸。由d换算出单位像素R(mm/pixel)、R1(mm2/pixel)。即可计算实际尺寸[9]。实验与实际数据对比得方法数据误差在5%~18%区间。
4 结 论
实验表明识别精度mAP达80.53%基本满足需求。针对捕捉后拍摄的图像进行一系列图像处理算法获取裂缝基于像素值的面积、周长、纵深等数据,帮助专业人员对塔式起重机存在的危险进行评估和判断,针对裂缝严重程度做出相应的处理方案。取代传统的人工检查,保障检查人员的人身安全又提高了检测效率。具有广泛的应用前景和实际价值。
提出的方案具有极大的实用价值和应用前景。但是也存在一些待解决问题:
1)YOLOv3牺牲了部分速度换取更好的识别精度,但识别精度仍有改善的空间,特别是应用于工地复杂环境下仍然存在误识别和漏识别等
2)针对图像处理算法处理捕捉区域获取裂缝参数仍有改进的空间,处理后的裂缝图像有时会出现不连续等问题,计算参数与实际值误差还有提升的空间。
3)完成定量定位工作的同时还需引入定性工作,针对裂缝要有危险等级的评定和提供相应的处理意见,才能建立一个完整的检测体系。针对上述问题下一步工作可通过改进YOLOv3的网络结构,针对损失函数进行加权,对识别框采用k-means等聚类算法进行维度聚类等方法改善模型的性能。针对图像处理尝试更多区域分割算法等让处理后的图像更加贴近原始裂缝。而针对塔吊裂缝的危险定级国内还没有相关的标准,可以参考其他裂缝领域的定级评价指标,同时结合实际工程中处理经验,建立一个完整的裂缝定性体系。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
现代临床医学(2022年2期)2022-04-19
计算技术与自动化(2022年1期)2022-04-15
建材发展导向(2021年15期)2021-11-05
集装箱化(2021年1期)2021-04-12
天津医科大学学报(2021年1期)2021-01-26
中国信息技术教育(2020年2期)2020-02-02
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
意林·全彩Color(2018年7期)2018-08-13
