
基于BERT-BiGRU模型的文本分类研究
2021-11-10 08:10:14王紫音
天津理工大学学报 2021年4期
王紫音,于 青*
(天津理工大学a.天津市智能计算与网络安全重点实验室,b.计算机科学与工程学院,天津300384)
近年来互联网和数字化技术高速发展,电子文本的数量呈现爆炸式的增长。如何从海量电子文本中提取有效信息并进行文本分类是本课题主要研究的内容。
现有的文本分类方法主要有两种:基于知识工程的方法和基于机器学习的方法。基于知识工程的方法是指依靠专家经验和人工提取规则进行分类的方法。基于机器学习的方法是指通过计算机学习,自主提取规则进行分类的方法[1]。常用的机器学习的方法有支持向量机、朴素贝叶斯、最近邻法、决策树法等,这些方法在分类效果和灵活性上都取得了一定的进步,但其泛化能力较差。目前最常使用的方法为深度学习的方法。深度学习是一种使用多个非线性转换结构的高阶抽象的算法。它使用词向量的表示方式,将文本表示为连续且稠密的形式,以更好地对文本进行表征。再利用卷积神经网络(convolutional neural network,CNN)、循环神经网络(recurrent neural network,RNN)等神经网络自动获取特征表达能力。与传统的机器学习模型相比,深度学习具有更好的泛化能力和可移植性,因此也更适用于文本分类任务。
1 相关研究
当前,对于中文文本的分类已经有了许多研究。刘学敬等[2]利用支持向量机分类中各种特征和资源,结合概率输出加权,提高分类精度。KIM[3]将CNN用于文本分类,使得文本分类的准确度得到了一定程度的提高。王煜涵等[4]提出了利用CNN进行推特文本情感分析的模型。虽然CNN可以很好地学习到文本的局部特征,但是会忽略文本的上下文语境。因此,又出现了RNN[5]。该网络能学习任意时长序列的输入,要想学习到文本中上下语句的关系,可以采用双向神经循环网络(bidirectional recurrent neural network,BiRNN)。随着输入信息的增多,要求RNN记住的信息太多,由此出现信息冗余、梯度消失的现象,因此HOCHREITER等[6]提出了长短时记忆网络(long short-term memory,LSTM)和HUANG等[7]提出了利用双向长短时记忆网络(bidirectional long short-term me mory,BiLSTM)进行中文文本情感分析的模型。由于LSTM的结构比较复杂,后来基于LSTM又提出了一种新的RNN,称为门控制循环单元(gate recurrent unit,GRU)[8]。为综合文章的上下文语境,曹宇等[9]使用双向门控制循环单元(bidirectional gate recurrent unit,BiGRU)模型进行中文文本分类,该模型更加简单,参数更少,收敛速度更快,在自然语言处理任务中表现出了良好的效果。
针对混合网络模型,国显达等[10]提出使用CNNBiLSTM模型进行情感分析,与使用单一的神经网络方法相比,有更好的准确性。
以上模型均使用传统的词汇表示方法。Word-2vec模型用词向量表示。该模型使用唯一的词向量来表示词,无法体现出词在不同语境中的多义性。2018年,预训练模型开始兴起,自然语言处理(natural language processing,NLP)领域有了重大突破,先后出现了基于语言模型的词向量表达(embeddings from language models,ELMO)[11]、基于编码器-解码器的双向编码表示法(bidirectional encoder representations from transformers,BERT)模型[12],尤其是BERT模型,刷新了NLP任务之前的11项最优性能记录。於张闲等[13]提出了基于BERT-BiLSTM模型的分类研究,通过实验证明,与基于Word2vec的BiLSTM模型相比,BERT-BiLSTM模型的准确率更高。
为优化文本的特征提取与表示方法,本文提出使用基于BERT模型进行中文文本的特征表示,并在此基础上提出双向GRU的中文文本分类模型,使最终的文本分类更加精确,并通过设置对比实验证明了本文方法的有效性。
2 BERT-BiGRU模型
BERT-BiGRU模型如图1所示,主要分为3部分:先通过BERT模型训练获取每条文本的语义表示,得到字的向量表示;之后再将字的向量表示输入到BiGRU神经网络中,对语义进行进一步的分析和提取;最后将得到的词向量连接Softmax层,进行文本分类。
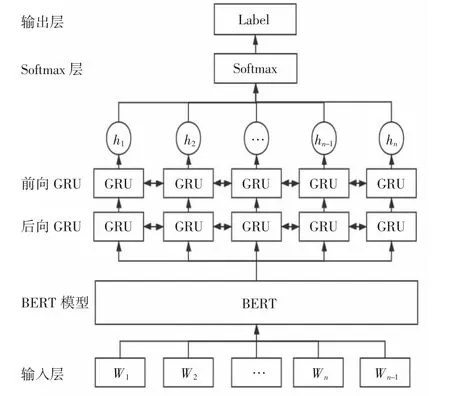
图1 BERT-BiGRU模型Fig.1 BERT-BiGRU model
2.1 BERT模型
文本的语义表示最初使用的是One-hot的表示方法,但是使用这种编码方式无法表示出词之间的相似性,无法表示未出现过的词,还会造成维数灾难的问题。后来出现了Word2vec、Glove等基于神经网络的方法,在一定程度上解决了语义鸿沟和维数灾难的问题,但是这类方法使用唯一不变的词向量表示词语,无法解决在不同语境中词语含义不同的问题。因此,本文提出利用BERT作为语义提取和特征表示的模型,在不同的语义环境中,使用不同的词向量对词语进行表示,在提取文本语义特征的同时又能解决词语一词多义的问题。
BERT模型内部由编码器-解码器模型(Transformer)的编码器(Encoder)端构成,其编码器端如图2所示,Transformer采用的是Encoder-Decoder(编码器-解码器)结构,对于输入文本主要使用Transformer的Encoder端中的自注意力(Self-attention)机制将全文的信息融入每个字中,得到的输出就是每一个字的增强语义向量表示。将文本的向量表示作为输入,向量表示为字向量、段向量、位置向量3种向量的加和,使用多头自注意力机制将全文的信息融入文本中的每一个字中,使用多头,可以通过不同的头得到多个特征表示。由于经过多层处理之后的数据并不一定比原来的效果好,因此,采用残差连接的方式进行连接。层归一化(Layer normalization)把神经网络中的隐藏层归一化为标准的正态分布,加快训练速度。最后连接前馈神经网络,进行两次线性映射后再使用激活函数,最终得到向量表示。本文使用的BERT-Base模型是由12层Encoder堆叠而成。
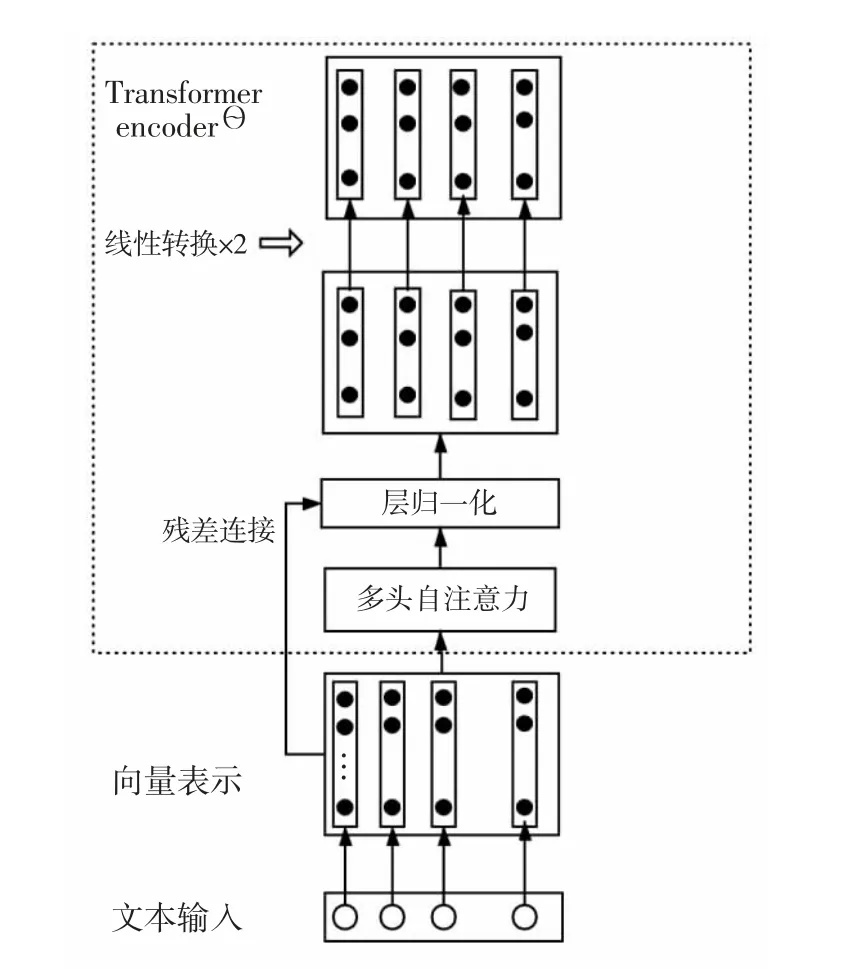
图2 编码器-解码器模型的编码器端Fig.2 Encoder of transformer
BERT的本质为一个语言生成模型,其目标是生成预训练语言模型。预训练可以理解为使用大量的数据对模型进行训练以生成一个通用的语言模型,然后针对不同的下游任务,再对该模型进行微调。对模型进行训练就是训练出合适的参数,从而保证模型可以正确地理解语义。BERT模型将两种无监督的方法——Masked LM和Next Sentence Prediction相结合进行预训练。Masked LM的任务具体为:如同完形填空,给定一句话,随机遮盖这句话中的一个或几个词,要求模型可以凭借余下的词汇预测被遮盖的几个词分别是什么。Next Sentence Prediction的具体任务为:下一句话预测,即给出一篇文章中的两句话,判断在文本中第二句话是否在第一句话之后。图3为BERT模型,其中Ei为单个字,Ti为最终的输出隐藏层。BERT利用Transformer结构构造了一个多层双向的Encoder网络,设计为深度双向模型,使神经网络可以更有效地从第一层到最后一层捕获来自左右上下文的信息。
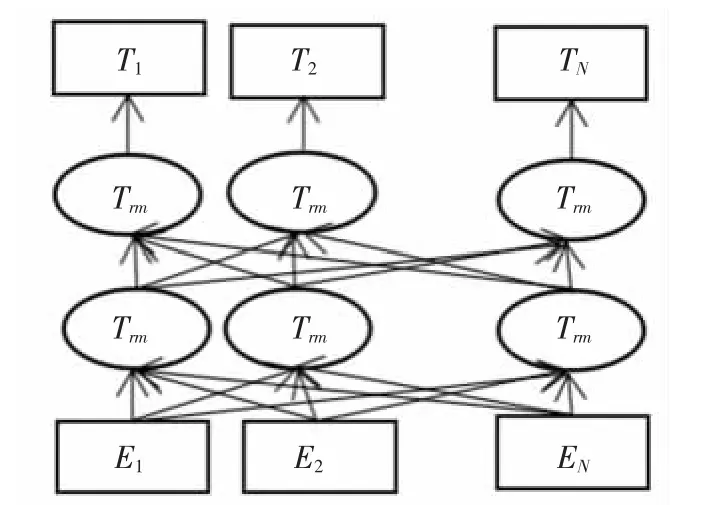
图3 BERT模型Fig.3 BERT model
2.2 BiGRU模型结构
GRU是长短时记忆神经网络的一种变体,和LSTM同属于RNN的改进模型。由于RNN在处理序列时具有严重的梯度消失问题,当节点越来越靠后时,对在前面的节点感知程度越来越低。为了解决梯度消失问题,提出了长短时记忆神经网络(LSTM),但是LSTM网络有参数多、训练时间长的问题,因此又提出了GRU。GRU作为LSTM的变体,同样适用于处理序列数据,通过“门机制”来记忆前面节点的信息,解决梯度消失问题。对比于LSTM模型,GRU模型只有两个门,分别为更新门和重置门,因此参数更少,在与LSTM可以达到同样效果的同时减少了训练时间。图4所示为GRU模型。表1为图4中的参数说明表。

图4 GRU模型Fig.4 GRU model

表1 参数说明表Tab.1 Parameter specification table
zt和rt共同控制了从ht-1隐藏状态到ht隐藏状态的计算,更新门同时控制当前输入数据和先前记忆信息ht-1,输出一个在0~1之间的数值zt。zt决定以多大程度将ht-1向下一个状态传递。具体的门单元计算为:
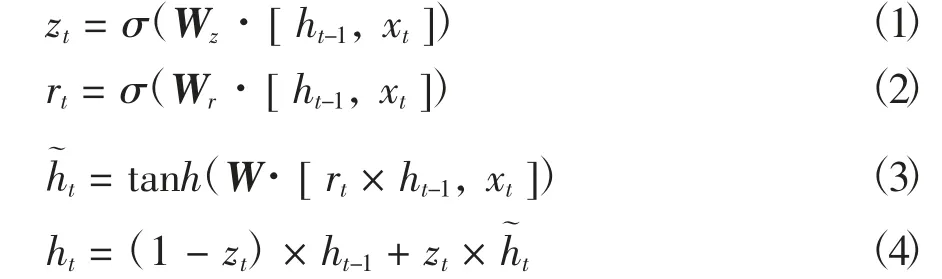
式中,σ是Sigmoid函数,可以将数据变为0~1范围内的数值,充当门控制信号。Wz、Wr、W分别为更新门、重置门以及候选隐含状态的权重矩阵。
当rt为0时,上一刻的候选隐状态对当前的候选隐状态不起作用,则ht只与当前的输入xt有关,因此重置门有助于捕捉短期依赖关系。当zt=1时,ht=ht-1,上一时刻的隐状态完全给了当前的隐状态,若有较长的依赖关系,则ht-1完全保留下来,因此更新门有助于捕捉长期的依赖关系。根据重置门、更新门和隐含状态的计算结果可以通过公式得到当前时刻的输出ht。在循环神经网络中,状态的传输是从前往后进行传输的,但是当前的输出状态不仅和之前的状态有关,还和之后的状态有关,此时需要双向GRU来解决该问题。双向GRU是由两个GRU上下叠加在一起组成的,输出是由这两个GRU的状态共同决定的。最后得到的输出信息为:

式中,ht(i)为表示第i则文本的BiGRU信息,h→t(i)表示第i则文本的前向GRU信息,h←t(i)表示第i则文本的后向GRU信息。
双向GRU(BiGRU)模型可以从前向和后向同时获取文章的信息,并且具有复杂度低、响应时间短的优点。本文中BiGRU模型的输入为BERT预训练语言模型得到的词向量,将BiGRU模型得到的输出结果输入到Softmax层进行文本分类。
3 实验与分析
3.1 实验数据的选取
为验证文本模型的有效性,选取THUCNews数据集进行验证。THUCNews是根据新浪新闻简易信息聚合(really simple syndication,RSS)订阅频道2005—2011年间的历史数据筛选过滤生成的,均为UTF-8纯文本格式。本文选取50 000条数据作为训练集,5 000条作为验证集,10 000条作为测试集。数据长度大部分在5 000以下,内容分为:体育、财经、房产、家居、教育、科技、时尚、时政、游戏和娱乐共10个类别,Label设置为0~9。
本实验选取的数据集类别标签多,相比于只包含消极与积极情感标签的短文本数据集,更可以体现本文提出的模型的分类效果的优良特性。语料序列可视化图如图5所示,数据集中的文本大多为长文本,因此需要对长文本进行处理。因为BERT模型支持的最长序列长度为512,所以使用Pooling方法对文章进行处理,将一个整段的文本拆分为多个Segment,每一个Segment的长度小于512,每一个Segment都通过BERT。
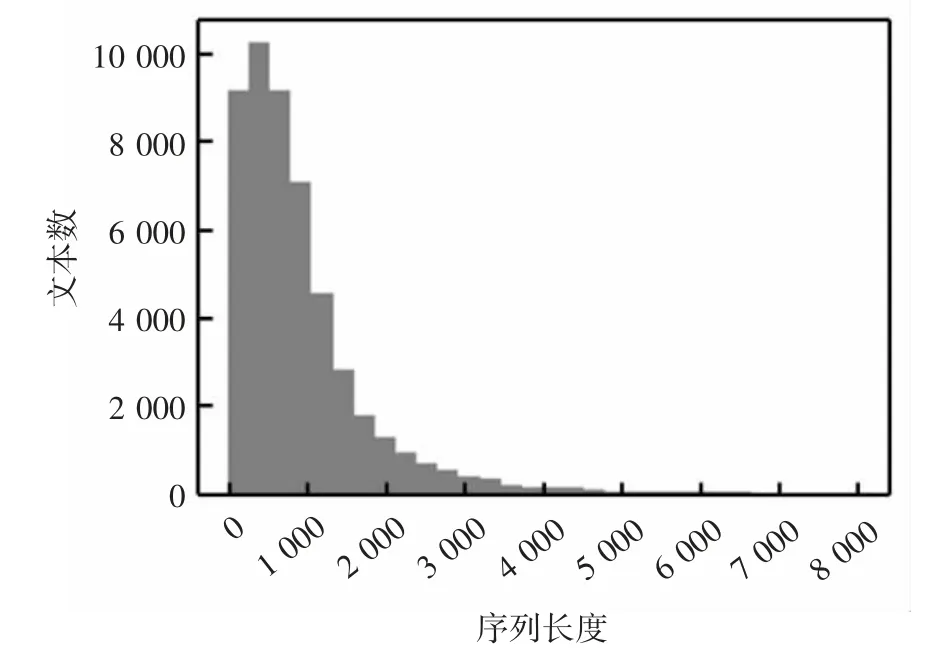
图5 语料序列可视化图Fig.5 Visualization of corpus sequence
3.2 对比实验设置
试验需要对基于BERT模型进行词语表征的有效性进行验证,同时也需要对使用BiGRU模型进行进一步特征提取和分类的有效性进行验证。在进行实验设计时参考了谌志群等[14]提出的实验模型。
1)Word2vec-BiGRU:输入的文本利用Word2vec模型训练后得到的词向量进行表示,用这些词向量作为词嵌入层接入BiGRU神经网络之后进行特征提取和分类。
2)ELMO-BiGRU:输入的文本利用ELMO模型训练后得到的词向量进行表示,用这些词向量作为词嵌入层接入BiGRU神经网络之后进行特征提取和分类。
3)BERT-CNN:输入的文本使用BERT模型训练后得到的词向量进行表示,将其作为输入,使用CNN神经网络进行特征提取和分类。
4)BERT-RNN:输入的文本使用BERT模型训练后得到的词向量进行表示,将其作为输入,使用RNN神经网络进行特征提取和分类。
5)Word2vec-CNN:输入的文本使用Word2vec模型进行词向量的表示,将其作为输入,使用CNN神经网络进行特征提取和分类。
6)Word2vec-RNN:输入的文本使用Word2vec模型进行词向量的表示,将其作为输入,使用RNN神经网络进行特征提取和分类。
3.3 模型参数设置
使用TensorFlow深度学习框架进行开发试验,在官网上下载谷歌开源的预训练好的BERT模型(Chinese_L-12_H-748_A-12),表2为模型参数配置。
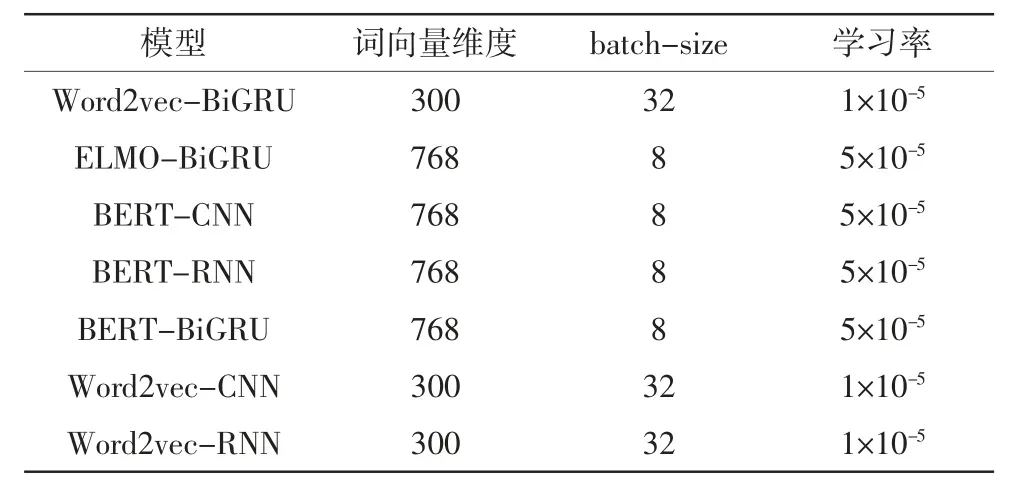
表2 模型参数配置Tab.2 Parameter configuration of model
3.4 评价指标
自然语言处理的评价指标是多种多样的,本文采用适用于文本分类的评测标准,其中包括精确率P(precision)、召回率R(recall)和综合评价数值(F1),具体的计算公式为:

式中,TP为当正类被判断为正类时的数据数量,FP为当负类被判断为正类时的数据数量,FN为当正类被判断为负类时的数据数量,F1的值由P和R共同决定。
3.5 实验结果与分析
使用BERT-BiGRU模型首先在验证集上进行训练,得到的验证集实验结果如图6所示。在验证集上的准确率最终稳定在94.2%,取得了较好的成绩。
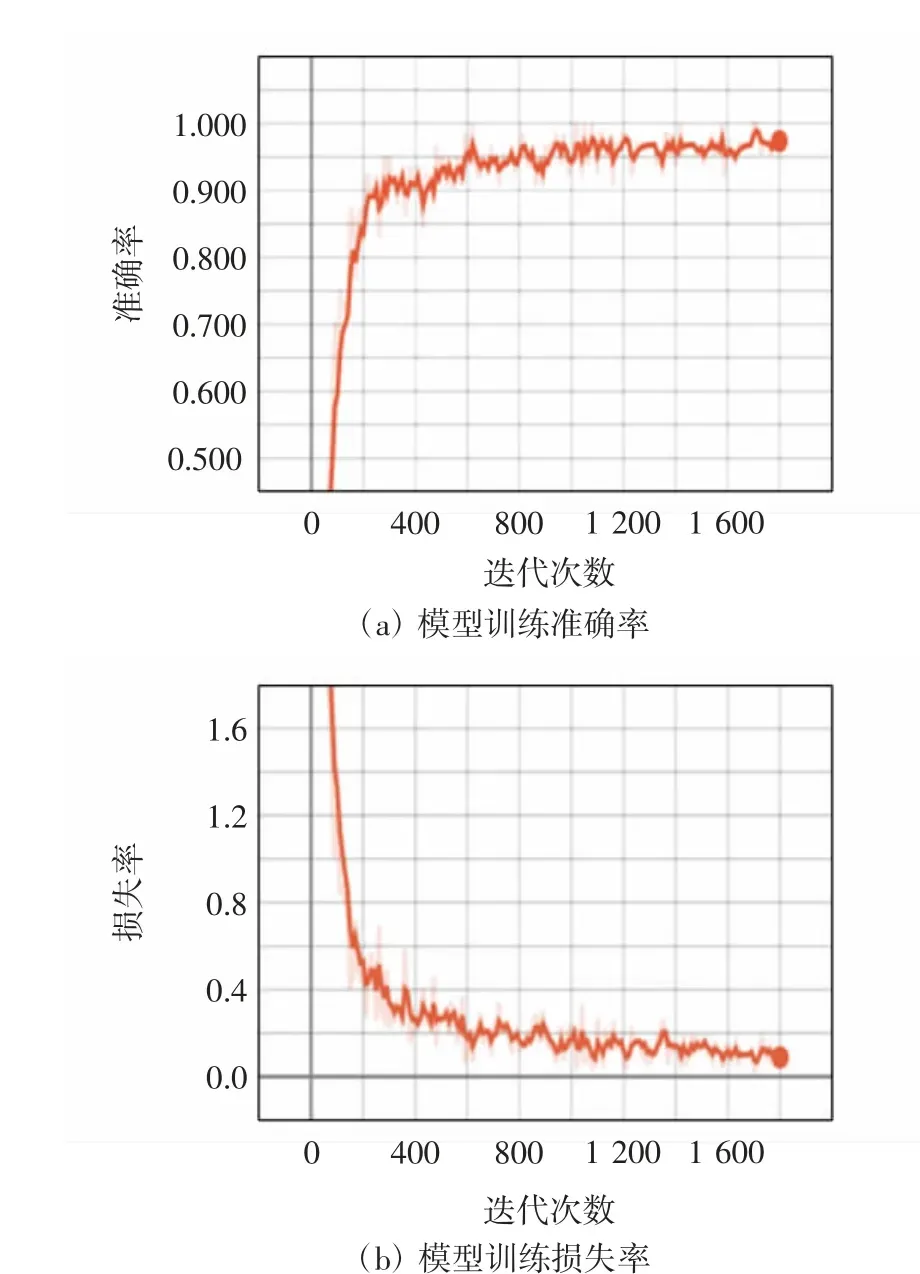
图6 验证集实验结果Fig.6 Verification set experiment results
在测试集上对每一种分类进行测试,得到的BERT-BiGRU模型实验结果如表3所示,各类别的准确率、召回率、F1值大部分都达到了0.9以上。由此可见,该模型在文本分类中表现良好。
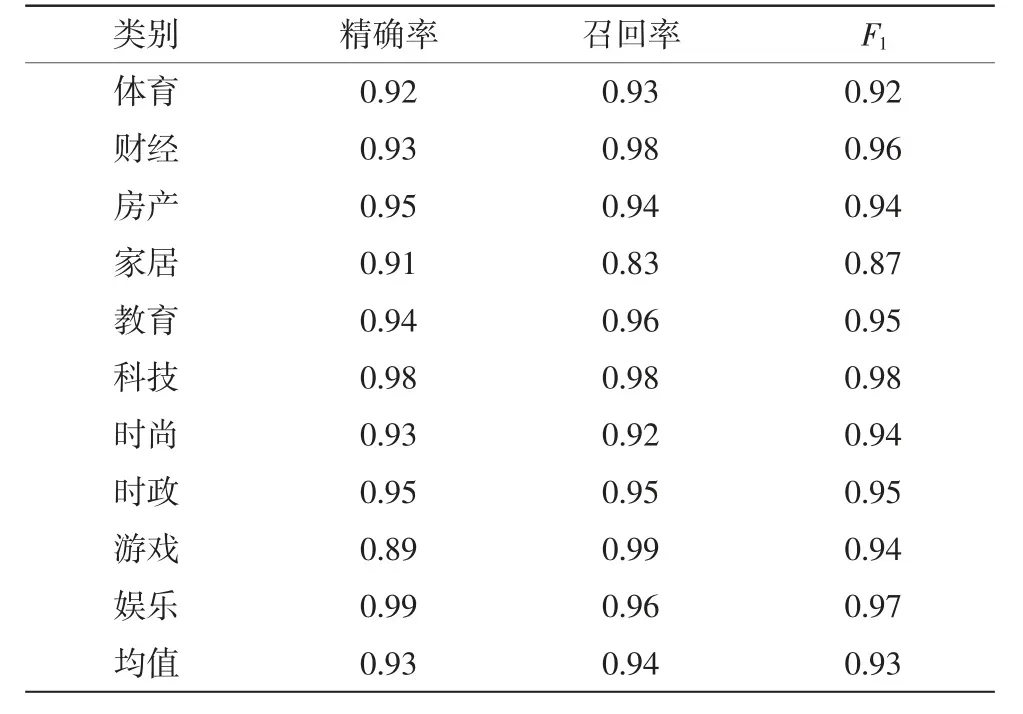
表3 BERT-BiGRU模型实验结果Tab.3 Experiment results of BERT-BiGRU model
设置的BERT-BiGRU模型与其他模型对比实验结果如表4所示,由表4可知,设置的对比模型的准确率均低于本文提出的模型所达到的准确率。图7为各模型效果对比图,分析可知,使用设计的对比实验模型进行中文文本分类,其效果均没有本文中提出的模型分类效果好。
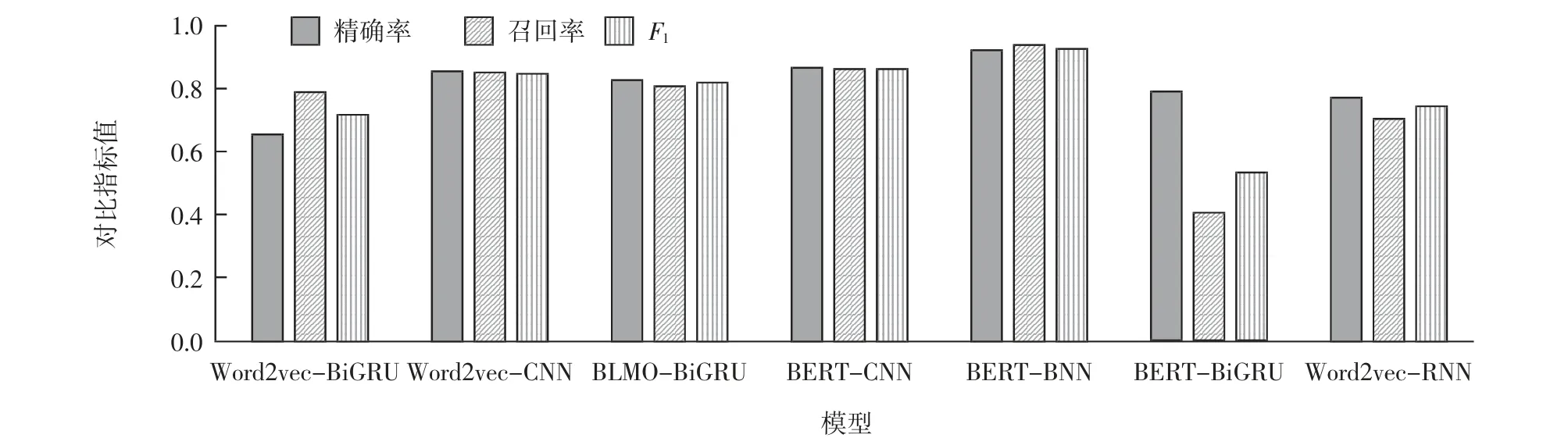
图7 各模型效果对比图Fig.7 Model performance comparison diagram
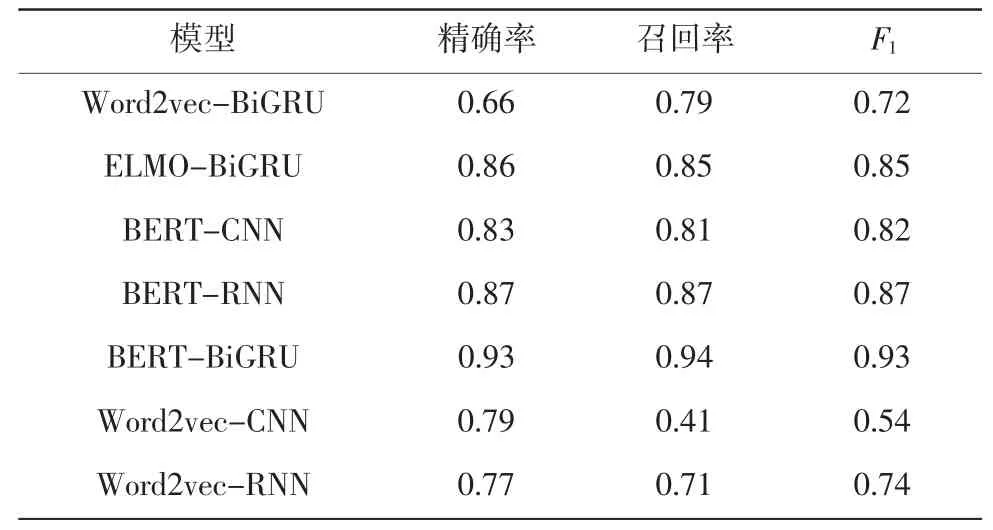
表4 BERT-BiGRU模型与其他模型对比实验结果Tab.4 Comparison of BE R T-BiG R U model and other models
与模型Word2vec-BiGRU和ELMO-BiGRU对比,验证了BERT模型的有效性。Word2vec的词向量表示方法,无法解决不同环境下词语多义的问题。ELMO模型是用来解决词语多义的模型,由实验结果可知,该模型性能与Word2vec相比有了一定的提升,但是各项指标仍然不如BERT,说明在解决词语多义性、理解文本含义的问题上BERT模型的优势突出。
与模型BERT-CNN和BERT-RNN的对比实验,证明了基于BiGRU文本分类的有效性。这几个模型均采用了BERT模型进行文本表示。在全都基于BERT方法时,对比采用CNN和RNN神经网络的方法,BiGRU模型的各项性能指标均有不同程度的提升,说明BiGRU模型在获取文本前向和后向两个方面语义特征的效果更好。最终的实验表明,基于BERT的文本特征表示结合基于BiGRU的中文文本分类方法在数据集上的表现更好,证明了本文模型的有效性。
4 结论
文本分类是自然语言处理的重要部分。自然语言处理作为人工智能领域研究的热点,复杂多变的语言特点是该领域研究的难点。本文针对文本表示模型中的词向量无法处理不同语境下的词语多义问题,提出使用BERT模型获取文本的特征表示,将得到的特征表示输入到BiGRU神经网络中进一步进行特征提取从而进行更加精准的文本分类。本文中提出的模型在数据集的验证实验中取得了良好的效果,与提出的其他模型相比BERT-BiGRU模型的实验效果更好。本实验中仍存在一些问题,如BERT模型的深度较深,参数多,因此训练BERT模型对硬件和时间的消耗较大,本实验只能依赖Google公司发布的预训练模型。希望在未来的工作中可以针对这些问题进行改进。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
开放教育研究(2020年2期)2020-03-31 01:54:14
电子制作(2018年19期)2018-11-14 02:37:08
自动化学报(2017年11期)2017-04-04 02:52:58
现代语文(2016年21期)2016-05-25 13:13:44
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
噪声与振动控制(2015年4期)2015-01-01 07:08:21
