
基于残差密集块和自编码网络的红外与可见光图像融合
2021-11-09 10:34王建中徐浩楠王洪枫于子博
北京理工大学学报 2021年10期
王建中, 徐浩楠, 王洪枫, 于子博
(北京理工大学 机电学院,北京100081)
红外图像是红外探测器通过捕捉物体的热辐射信息生成的一种图像,可在黑夜、烟雾、低照度、逆光、伪装等复杂环境下使用,但红外对目标的轮廓和纹理信息不敏感,其图像分辨率低、对比度低、噪声高. 可见光图像能够很好地保留轮廓和纹理信息,具有较高的清晰度和对比度,但容易受到环境因素的影响,不能全天候使用. 将二者进行融合是在复杂环境下获得高质量图像的一种有效手段,融合后的图像鲁棒性强,在目标检测、目标跟踪、图像增强、遥感、医疗等领域有着广泛的应用[1].
图像融合经过了多年的发展,目前主要有多尺度变换[2]、稀疏表示[3]、神经网络[4]、子空间[5]、混合模型[6]等融合方法. 近年来,随着深度学习技术及其在目标检测[7-8]、目标跟踪、图像分割等领域中的快速发展,基于深度学习的红外与可见光图像融合方法不断被提出,因此有学者将现有方法分为传统方法和基于深度学习的方法两种类型[9]. 基于深度学习的端到端方法避免了传统方法中需要手工设计融合算法和特征提取方法的问题,且在融合图像的质量上相较于传统算法也有所提升. 目前基于深度学习的红外与可见光图像融合方法主要包括基于生成对抗网络的方法和基于自编码网络的方法,基于生成对抗网络的方法利用生成器和鉴别器之间的不断对抗来生成尽可能保留有更多原图像信息的融合图像,而基于自编码网络的方法则沿用了传统方法中的分解、融合、重构的思想,通过设计和训练由卷积神经网络构成的编码器和解码器来得到融合图像. 基于生成对抗网络的代表性方法包括FusionGAN[10]、GANMcC[11]等. FusionGAN首次将生成对抗网络引入到图像融合中,是一种能够较好地保留行人、车辆等目标信息的端到端模型,但它只将融合后的图像与融合前的可见光图像进行对比,丢失了红外图像中的一些信息. GANMcC采用了具有多分类的生成对抗网络,相较于FusionGAN方法可以保留融合前图像的更多信息. 基于自编码网络的代表性方法有Densefuse[12]、DIDFuse[13]等. Densefuse首次引入了自编码网络进行图像分解和图像重构,但它只是简单地使用编码器生成红外图像特征图和可见光图像特征图,没有做进一步的分解. DIDFuse则分别将红外图像和可见光图像分解为背景特征图和细节特征图,但它的网络结构相对简单,不能有效地利用卷积神经网络提取的特征信息,生成的融合图像清晰度不高.
针对上述问题,本文提出一种基于残差密集块(residual dense block,RDB)和自编码网络的端到端融合方法,使用基于残差密集块设计的编码器进行特征提取和图像分解,并分别将红外图像和可见光图像分解为包含环境信息的背景特征图和包含目标信息的细节特征图,然后将这两种特征图分别进行融合,输入解码器进行重构,得到最终的融合图像. 实验结果表明,与目前红外与可见光图像融合领域内具有代表性的FusionGAN、GANMcC、Densefuse、DIDFuse 4种方法相比,本文的方法在衡量红外与可见光图像融合质量的空间频率(SF)、平均梯度(AG)、相关系数(CC)、差异相关和(SCD)、边缘信息保留度(Qabf)、结构相似度(SSIM)6个评估指标上有不同程度的提升.
1 基于残差密集块的自编码图像融合网络结构
在卷积神经网络中,大多数卷积层的输入都由上一层或上几层的输出构成,从而在上一层或上几层的基础上进行更深层次的卷积,提取出更深层次的特征. 然而,不同深度的卷积层提取出的特征图所表征的信息并不相同,某一个卷积层的输出并不能详尽地描述图像中各种尺度的特征,如果只是简单地逐层连接,再使用最后一层输出的特征图来进行后续处理,就会丢失中间层的大多数特征信息. 目前大多数基于深度学习的图像融合方法都只采用了几个简单的卷积层进行特征提取,过于简单的网络结构难以充分地提取图像中的特征,并且大多数网络选择的逐层连接结构不利于特征信息的充分利用,难以避免中间层信息丢失的问题,而这个问题随着网络层数的增加会体现得越来越明显.
ZHANG等[14]提出了图1所示的残差密集块网络,其每一层都与前面的所有卷积层相连接,使得每一层提取的特征信息都能得到充分利用,在输入和输出端采用了跳层连接的方式进行密集特征融合(dense feature fusion, DFF),加快了网络在训练中的收敛速度. 同时,密集连接和跳层连接的特点可以有效地改善网络梯度弥散和梯度爆炸的问题,也有着减少过拟合的作用. 如果将多个残差密集块结构级联起来,可以通过全局特征融合(global feature fusion, GFF)将各个残差密集块的输入结合起来,使得网络能够更加充分、有效地提取特征.
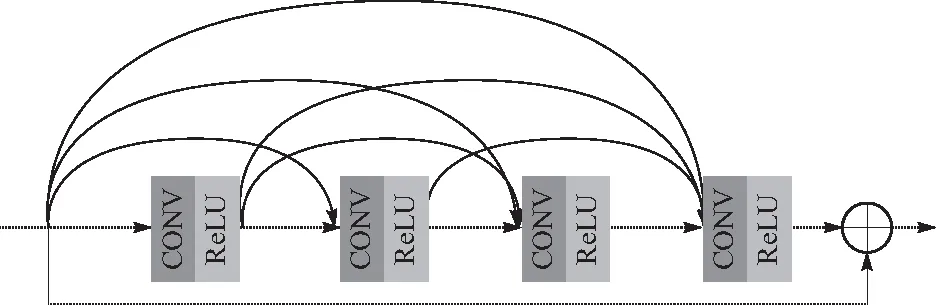
图1 残差密集块网络结构Fig.1 Residual dense block network structure
本文基于上述残差密集块构建了一种自编码图像融合网络结构,考虑到红外图像分辨率低、噪声高,采用较深层的卷积容易引入噪声,影响特征提取的效果,网络中只采用了一个残差密集块. 网络含有一个编码器、一个解码器以及一个融合层,如图2所示. 其中,编码器由一个包含4个卷积层的残差密集块,以及一个用于密集特征融合的1×1卷积层和2个用于将特征图分解为背景特征图和细节特征图的卷积层组成,一共包含有7个卷积层;解码器由4个卷积层组成. 所有卷积层的步长都为1,除了DFF层以外,其余所有卷积层的卷积核大小都为3×3、填充都为1,并且在每个卷积层后面会有一个BN层以优化网络梯度和防止过拟合. 每个卷积层中的卷积核大小、输入、输出通道数以及激活函数等参数如表1所示.
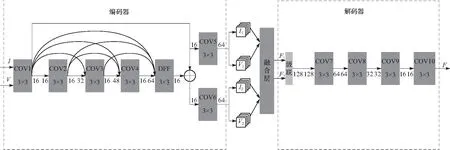
图2 基于残差密集块的自编码图像融合网络结构Fig.2 Self-encoding image fusion network structure based on residual dense block
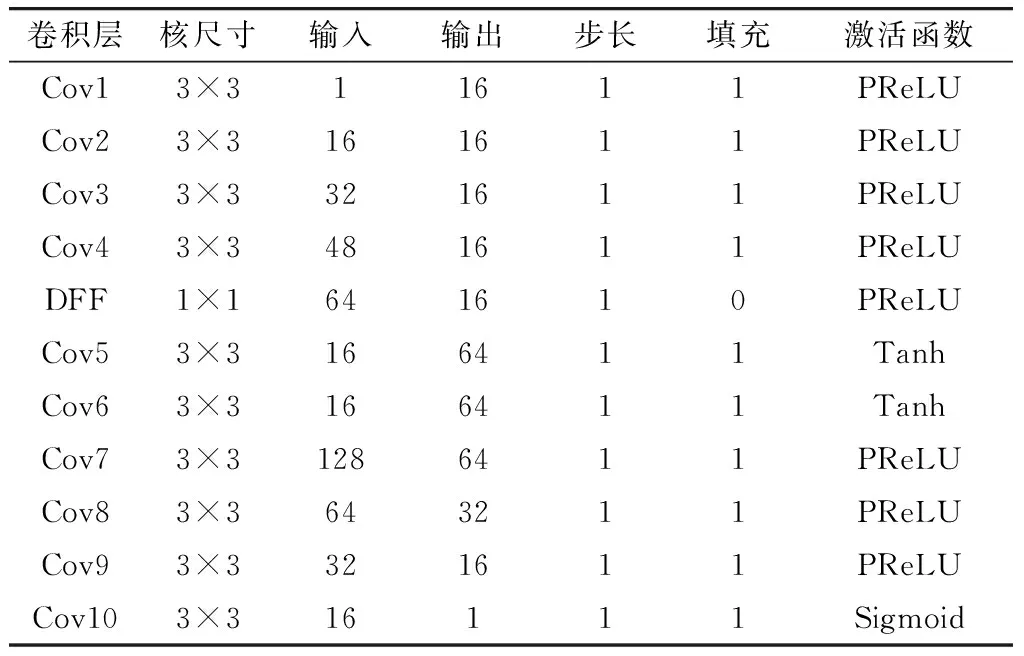
表1 网络结构参数
当红外图像I和可见光图像V被输入到网络中,编码器中的卷积层1到卷积层4会对它们进行一系列的密集特征提取,然后经由DFF层进行密集特征融合,融合后生成的特征图会分别被卷积层5和卷积层6分解为含有环境信息的背景特征图I1、V1和含有目标信息的细节特征图I2、V2,之后再通过融合层将I1、V1和I2、V2进行融合. 融合后得到的特征图F1和F2被输入到编码器中,先通过逐通道级联的方式生成一个128通道的张量,再经过卷积层7到卷积层10的重构,生成最终的融合图像F.
2 损失函数与网络训练
训练的目的是让编码器拥有充分提取特征和分解图像的能力、解码器拥有尽可能完整地重构图像的能力. 训练过程中不采用融合层,融合层会在测试阶段加入网络,完成图像融合. 训练过程包括图像分解和图像重构两个阶段,图像分解使用的损失函数为
L1=tanh(φ(V1-I1))-α1tanh(φ(V2-I2))
(1)
式中:I1,I2分别为红外图像的背景特征图和细节特征图;V1,V2分别为可见光图像的背景特征图和细节特征图;φ为smoothL1函数;α1为自由参数. 使用tanh函数的目的是将输出限制在-1到1之间,而smoothL1函数的作用是表征特征图之间的差异.
图像重构使用的损失函数为
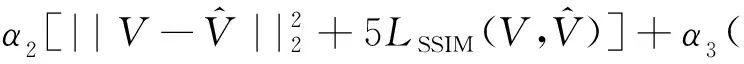
(2)
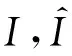
融合层采用简单有效、在自编码网络中能够达到较好效果的相加策略[12],即
(3)
式中:F1,F2分别为融合后的背景特征图和融合后的细节特征图;⊕表示将2种特征图逐元素相加.
采用RoadScene数据集[15]中的图像进行训练,该数据集从FLIR数据集中挑选了221对具有代表性的图像进行了预处理和配准,包括道路、建筑、树木、车辆、行人等目标和场景,训练过程中所有图像的尺寸都被调整到128×128[13],并且转化为灰度图,如图3所示.

图3 经过预处理和配准的图像 Fig 3 Preprocessed and registered images
训练在GeForce RTX 2080和Intel(R) Core(TM) i7-10700 CPU@2.90 GHz硬件上进行,软件环境为pytorch1.8.1和CUDA11. 训练中批尺寸设置为24,迭代次数设置为120,初始学习率为0.001,并分别在迭代的第41次和第81次开始调整为0.000 1和0 000 01. 损失函数中的α1设置为0.5,α2设置为2,α3设置为10. 从训练得到的图4
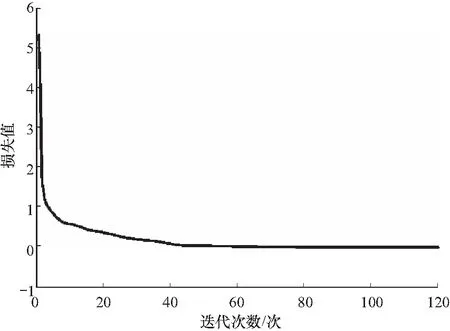
图4 损失曲线Fig.4 Loss curve
所示损失曲线可以看出,损失函数的收敛比较平稳,在迭代40次之后损失已十分接近0,在之后下降幅度很小,说明网络已经得到了充分训练.
3 测试与结果分析
在图像融合领域广泛用于测试对比的TN0数据集和VOT2019-rgbtir数据集中挑选图5所示的8对红外和可见光图像,利用已训练好的网络进行融合测试. 其中,1~4列为包含行人、车辆、建筑等正常场景的图像,5~8列为模糊、遮挡、逆光和烟雾等特殊场景的图像. 测试结果与Densefuse、DIDFuse、FusionGAN和GANMcC 4种方法对比,图像融合效果如图5所示,衡量融合质量的SF,AG,CC,SCD,Qabf,SSIM 6个评估指标如图6所示.

图5 图像融合效果对比Fig.5 Comparison of image fusion effects
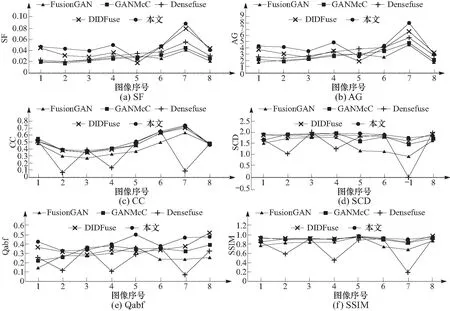
图6 图像融合质量评估指标对比Fig.6 Comparison of image fusion quality evaluation indicators
测试结果可以看出,本文方法得到的融合图像清晰度和对比度较高,物体的轮廓较为明显,对街道、建筑、车辆等目标能将红外热辐射信息和可见光的细节、纹理信息有效地融合起来,融合图像有较高的清晰度和对比度. 对可见光图像中不明显的飞机、行人等目标也能有效地引入红外信息,并且不会像其他算法那样刻意地突出红外目标,而是得到更加自然、符合人类视觉感受的融合图像. 对于模糊、遮挡、逆光、烟雾等复杂环境图像有良好的融合效果. 对于衡量融合质量的评估指标,SF和AG越高表示图像的梯度、边缘和纹理信息越多,图像越清晰;CC和SCD越高表示融合图像与原图像的相关程度越高,即融合图像引入了原图像越多细节信息;Qabf越高表示融合图像保留的原图像中的边缘信息越多;SSIM则是一个综合指标,从图像的亮度、对比度和与原图像的相似度3个角度进行评价,SSIM越高意味着融合图像的质量越高. 本文方法的融合质量评估指标均有不同程度的提升,具体表现为在SF、AG和Qabf 3个指标上明显好于其他方法,在CC、SCD、SSIM 3个指标上略好于其他方法,特别是在表征图像清晰度的SF、AG指标上都提升明显,说明本文方法在融合图像的清晰度上有着很大的优势.
4 结 论
提出了一种基于残差密集块和自编码网络的端到端的红外与可见光图像融合方法,将残差密集块引入自编码网络中的编码器中,使得编码器能够充分地提取、利用特征信息,并按照图像分解、特征融合、图像重构的步骤来得到融合图像,解决了传统方法和目前大多数基于深度学习的图像融合中存在的特征提取不充分、特征信息利用不完全和融合图像清晰度低的问题. 在TNO和VOT2019-rgbtir公开数据集上的测试结果表明,本文方法能够得到清晰度高、目标突出、轮廓明显、符合人类视觉感受的融合图像;与目前代表性融合方法相比,在SF、AG、CC、SCD、Qabf、SSIM 6个融合质量评估指标上均有不同程度的提升,特别是在融合图像的清晰度上有明显优势;对于模糊、遮挡、逆光、烟雾等复杂环境下的图像均有良好的融合效果,具有较高的实用性.
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
环球时报(2022-05-23)2022-05-23
心理学报(2022年4期)2022-04-12
航天返回与遥感(2022年1期)2022-03-09
北京大学学报(自然科学版)(2022年1期)2022-02-21
今日农业(2021年9期)2021-11-26
英语文摘(2021年2期)2021-07-22
金桥(2021年4期)2021-05-21
北京航空航天大学学报(2020年10期)2020-11-14
华人时刊(2020年23期)2020-04-13
