
融合相对密度与近邻关系的密度峰值聚类算法
2021-11-08 03:06代永杨张清华支学超
重庆邮电大学学报(自然科学版) 2021年5期
代永杨,张清华,支学超
(重庆邮电大学 计算智能重庆市重点实验室,重庆 400065)
0 引 言
作为一种无监督学习方法,聚类旨在发现数据之间潜在的数据结构[1]。目前国内外学者已经提出了许多不同类型的经典聚类算法。基于层次的聚类算法有CURE[2]和BIRCH[3]等; 基于划分的聚类算法有K-means[4]等; 基于网格的聚类算法有WaveCluster[5],STING[6]和CLIQUE[7]等; 基于密度的聚类算法有DBSCAN[8]和OPTICS[9]等。这些经典的聚类算法已经被广泛应用到数据挖掘[10-11]、图像分割[12-14]、数据压缩[15]等领域。
密度峰值聚类算法(density peaks cluster,DPC)是由A.Rodriguez等[16]于2014年发表在Science上的一种基于密度的聚类算法。样本的密度和相对距离是DPC中的2个重要概念。给定数据集中任意一个样本p,p的密度即在给定截断距离dc的条件下,以p为圆心,dc为半径的邻域中所包含的样本数量。p的相对距离即从密度比p大样本中找到距离p最近的样本q,p和q之间的距离为p的相对距离。在本文中,记q为p的父节点。DPC根据2个假设进行聚类:①类簇中心被周围密度更低的样本包围;②类簇中心与其父节点间的距离较远。基于以上2个假设,DPC首先计算样本的密度和相对距离,构建决策图; 然后,从决策图中选择具有较大密度和相对距离的样本作为聚类中心; 最后,将非中心点按照密度由高到低的顺序分配到各自父节点所在的类簇。
由于DPC算法思想简单且能够聚类任意形状的类簇,这使得DPC已经被广泛应用,然而,该算法仍然存在以下不足。
①DPC的非中心点的分配策略容易引起密度跳跃,从而导致连续错误,影响聚类结果[17]。
②DPC密度估计不能消除类簇间的密度差距,在选择聚类中心时倾向于选择密度更高的类簇中的样本作为聚类中心,进而影响算法聚类性能。
针对问题①,Xie等[17]提出FKNN-DPC算法,该算法基于k近邻思想设计2步分配策略用于分配非中心点。为了避免分配策略受到边界点的影响,FKNN-DPC基于样本与第k个近邻的距离检测边界点,边界点的阈值为所有样本与其第k个近邻的距离均值。然而,在面对类簇间有密度差距的数据集时,FKNN-DPC的边界点检测方法会将低密度类簇中大部分样本检测为边界点,导致聚类结果不理想。
针对问题②以及FKNN-DPC所存在的问题,本文基于FKNN-DPC中的非中心点分配框架,定义相对密度并结合近邻关系提出RN-DPC算法。RN-DPC算法的主要创新点在于以下几点。
1)在估计样本密度时,根据反向k近邻关系定义相对密度以消除类簇间的密度差距,解决DPC倾向于选择高密度类簇中的样本作为聚类中心的问题。
2)在检测边界点时,根据反向k近邻数作为检测边界点的指标,解决FKNN-DPC的边界点检测方法会导致密度较小的类簇中大部分样本被检测为边界点的问题。
3)在分配非中心点时,引入共享最近邻相似度设计2步分配策略对非中心点进行分配,提高非中心点分配的准确率。
1 相关工作
本节将简要介绍DPC的主要思想、DPC的相关改进工作以及近邻关系的基本定义和概念。
1.1 DPC聚类算法
DPC需要计算样本密度和相对距离以选择聚类中心。在本文中,记数据集为X={x1,x2,…,xn},基于数据集X,DPC的密度和相对距离定义如下。
定义1[16]给定数据集X,截断距离dc,对于∀xi∈X,xi的密度定义为
(1)
(1)式中:d(xi,xj)表示xi和xj之间的距离,当x<0时,χ(x)=1;反之,χ(x)=0。
定义2[16]给定数据集X,ρi和ρj分别表示xi和xj的密度,对于∀xi∈X,xi的相对距离定义为
(2)
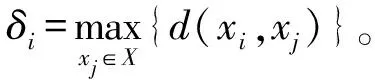
通过样本的密度和相对距离2个特征可以构建决策图,从决策图中选择有较大密度和较大相对距离的样本作为聚类中心。对于非中心点,DPC将它们分配到各自的父节点所在的类簇得到最终的聚类结果。
1.2 改进的DPC算法
近年来,有许多学者针对DPC的不同问题对其进行改进。这些改进的DPC算法可以分为2类:①针对DPC的聚类性能进行改进[17-21];②针对DPC的聚类效率进行改进[22-25]。
为了提高DPC的聚类性能,一些学者从不同角度对DPC算法进行改进。为了加强DPC算法对于流形簇的聚类能力并减少算法对于参数的依赖,Cheng等[18]提出了DLORE-DP算法,该算法基于局部代表点的思想,通过共享最近邻关系连接代表点,对每一个代表点进行聚类,最后将非代表点分配到各自的代表点所在的类簇。为了更好地度量样本的密度,Du等[19]基于k近邻思想并结合主成分分析法提出DPC-KNN-PCA算法,该算法使用k近邻的概念并且充分考虑数据集的全局分布重新定义局部密度,并结合PCA算法对数据集进行聚类以达到更好的聚类效果。为了避免DPC算法发生密度跳跃而引起连续错误,Xie等[17]基于k近邻的思想设计2步分配策略用于分配非中心点,首先,该算法对边界点进行剔除,然后,在第一步分配策略中对非边界点进行分配,最后,基于k近邻分类的思想对所有没有标签的样本进行分配。为了消除类簇间密度差距对DPC中心点选择的影响,Hou等[20]定义直接下属和间接下属的概念,以样本的直接下属数量作为样本的相对密度,根据相对密度和相对距离选择聚类中心。由于DPC使用样本间的欧氏距离作为样本的相似度度量,这一度量方法无法反映样本的真实分布。因此,Du等[21]引入测地距离的概念,使用k近邻图中样本间的最短路径作为样本的相似度度量以及相对距离度量。
为了提高DPC的聚类效率,一些学者通过不同策略来减少距离计算次数对DPC进行改进。Chen等[22]基于k近邻思想提出一种快速DPC算法,该算法将非密度峰值的父节点搜索范围锁定在其k近邻中,在搜索密度峰值的父节点时,使用三角不等式进行样本过滤,从而减少大量不必要的计算。Xu等[23]将数据点映射到网格中,将位于同一网格中的样本视为一个新的样本,进而提出DPCG算法,该算法对于低维数据有比较明显的速度提升,但是无法应用于高维数据。Gong等[24]基于分布式计算策略提出EDDPC算法,该算法减少了大量的距离计算次数和数据洗牌、数据复制和数据过滤的成本。Bai等[25]使用k-means算法来提高DPC的效率,该算法在计算相对距离之前使用k-means算法对数据集进行一次划分,这样在计算样本相对距离时可以将搜索范围缩小到单个类簇或者样本相邻的类簇,不必搜索整个数据集,这样可以减少距离的计算次数。
1.3 近邻关系
样本近邻关系的选择是许多数据挖掘算法的基础,选择合理的近邻关系可以提高算法的性能[26]。常用的近邻关系有k近邻[27],反向k近邻[28],相互k近邻[29]以及共享最近邻[30]。本文用到的k近邻、反向k近邻和共享最近邻3种关系的定义如下。

(3)
定义4[28]给定数据集X,knn(xj)表示xj的k近邻集合,对于∀xi∈X,xi的反向k近邻集合定义为
rnn(xi)={∀xj∈X|xi∈knn(xj)}
(4)
定义5[30]给定数据集X,knn(xi)和knn(xj)分别表示xi和xj的k近邻集合,对于∀xi,xj∈X,xi和xj的共享最近邻集合定义为
snn(xi,xj)=knn(xi)∩knn(xj)
(5)
定义6[30]给定数据集X,xi和xj的共享最近邻集合snn(xi,xj)以及近邻数k,对于∀xi,xj∈X,xi和xj的共享近邻相似度定义为
sim(xi,xj)=|snn(xi,xj)|/k
(6)
2 RN-DPC聚类算法
针对DPC算法和FKNN-DPC算法所存在的问题,即①DPC的密度估计不能消除不同类簇间的密度差距,导致该算法的中心点选择方案倾向于选择高密度类簇中的样本作为聚类中心;②sFKNN-DPC的边界点检测方法对类簇密度变化十分敏感,容易将低密度类簇中大量样本检测为边界点。本节将定义相对密度和边界点并进一步提出本文的RN-DPC算法。
RN-DPC算法的聚类过程可以分为中心点选择和非中心点分配2个部分。在中心点选择过程中,RN-DPC算法定义相对密度解决DPC在面对有密度差距的类簇时无法正确选择聚类中心的问题。在非中心点分配过程中,RN-DPC算法引入反向k近邻关系进行边界点检测,并且根据样本的共享最近邻相似度分配非中心点。选择聚类中心的过程可以分为3个步骤:①根据反向k近邻关系计算样本的相对密度;②基于样本的相对密度计算相对距离;③根据相对密度和相对距离构造决策图以选择聚类中心。非中心点分配过程也可以分为3个步骤:①根据样本反向k近邻数检测边界点;②分配非边界点中样本间共享最近邻相似度较大的样本;③根据已经被分配样本的类簇信息,采用k近邻分类的思想对剩余样本进行分配。
2.1 中心点选择策略
针对DPC的中心点选择策略的问题,RN-DPC算法基于相对密度提出一种新的中心点选择策略。为了更直观地说明DPC的中心点选择策略存在的问题,接下来以Jain数据集[20]为例来展示说明,如图1。图1a中,横坐标x和纵坐标y分别表示二维数据集中样本点2个属性的坐标值。从图1b中可以看出,在DPC的密度定义下,2个类簇的样本密度差距十分明显。由于DPC的中心点选择策略是从决策图中选择同时有较大密度和较大相对距离的样本作为聚类中心,所以,2个类簇的密度差距会导致紫色类簇中有3个样本,即位于图1c中红色圈内的样本,在中心点选择的优先级上都大于黄色类簇中的样本A。样本A的密度太小导致其没有被选作聚类中心,这会使得DPC无法得到正确的聚类结果。最终的聚类结果如图1d,红色五角星表示聚类中心。
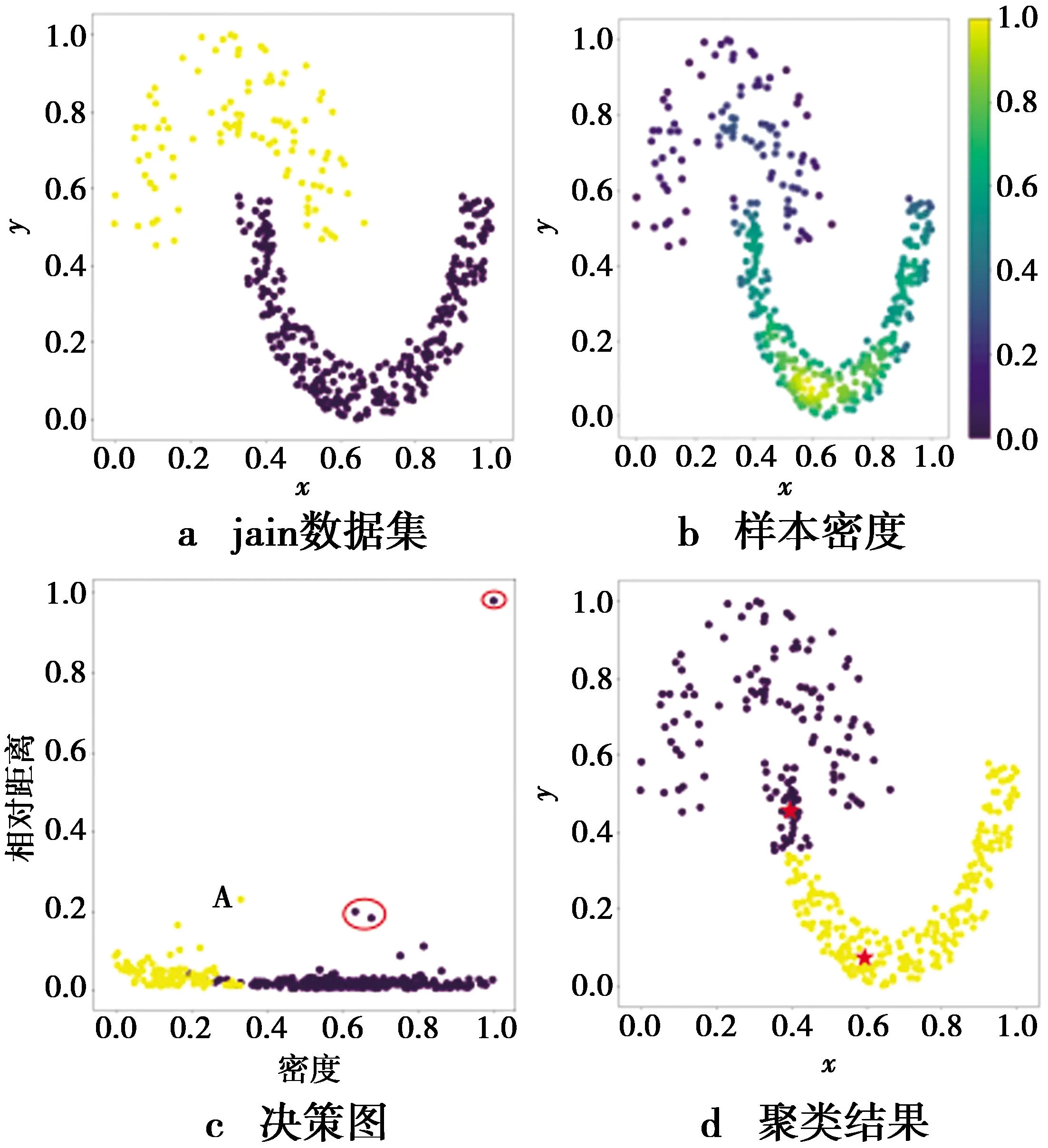
图1 DPC密度估计的问题
RN-DPC算法的密度定义旨在消除不同类簇间的密度差距,文献[30]指出在类簇的核心区域的样本相比类簇边界区域的样本有更多的反向k近邻,并且样本的反向k近邻数目对类簇密度变化不敏感。基于上述结论,RN-DPC根据样本的反向k近邻关系对样本的密度给出了新的定义,如下所示。
定义7给定数据集X,rnn(xi)表示xi的反向k近邻集合,对于∀xi∈X,xi的相对密度定义为
(7)
(7)式中:|·|表示集合的势;d(xi,xj)表示xi和xj的距离。
根据定义7对Jain中样本的密度计算结果如图2a。对比图1b和图2a可以看出,使用定义7所计算得到的2个类簇的样本密度更均衡,没有明显的密度差距。这说明了RN-DPC算法中的相对密度定义可以消除不同类簇中样本的密度差距。其原因在于反向k近邻关系对类簇密度变化不敏感,只与样本近邻的分布有关。根据样本的相对密度和相对距离可以构建新的决策图,如图2b。由图2b可知,本文提出的RN-DPC算法可以选择到2个正确的聚类中心,即位于图2b中红色圈内的样本,最终的聚类结果如图2c。
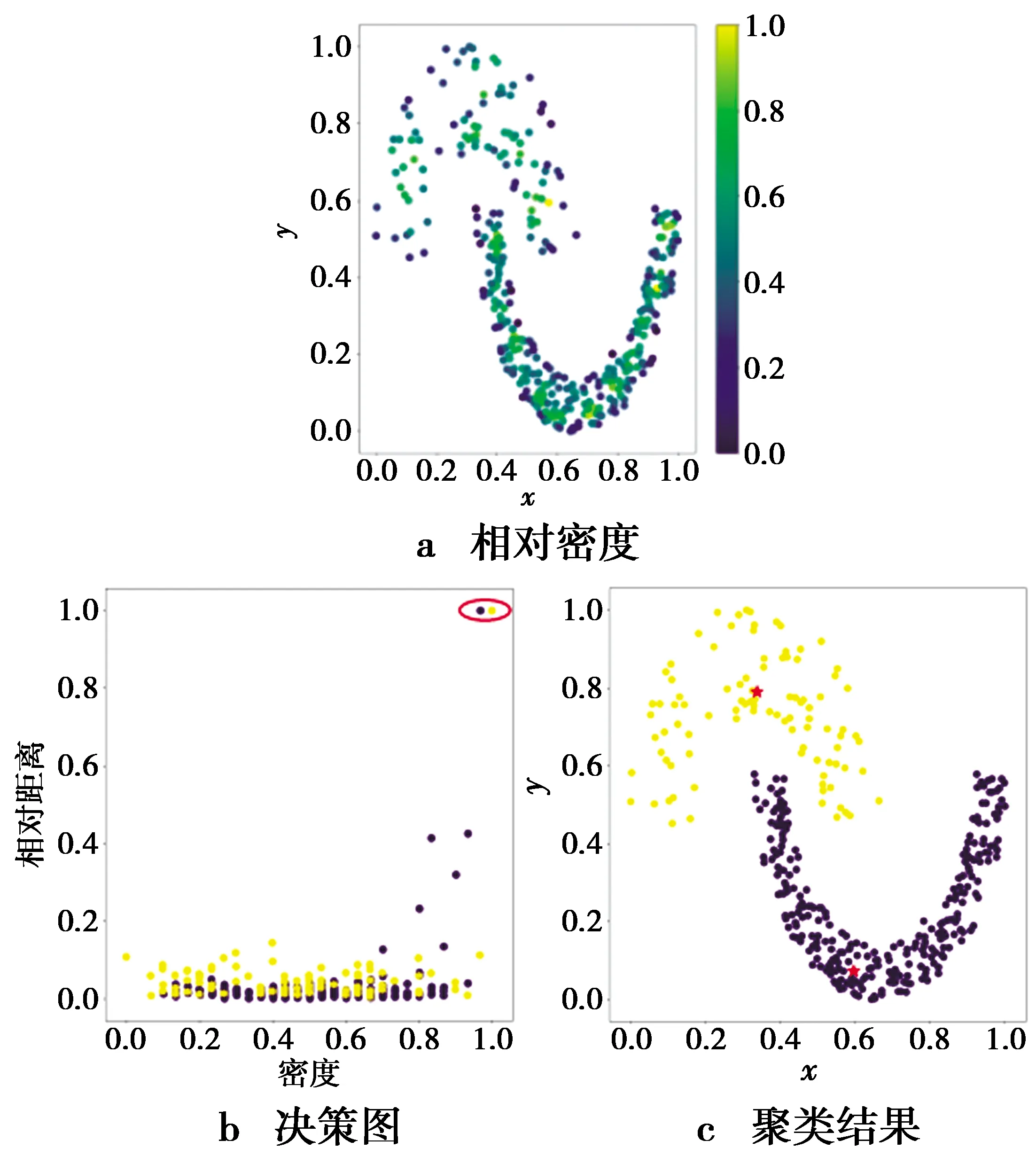
图2 Jain上相对密度度量结果
在计算得到样本的相对密度之后,RN-DPC算法根据样本间的相对密度关系计算样本的相对距离,然后基于相对密度和相对距离2个特征构造决策图,并进一步从决策图中选择聚类中心。RN-DPC的中心点选择策略的具体步骤给出如算法1。
算法1中心点选择策略
输入:数据集X,中心点数目m,近邻数k。
输出:聚类中心,k近邻矩阵knn,反向k近邻矩阵rnn,共享近邻矩阵snn。
步骤1计算每对样本的距离矩阵distn×n。
步骤2根据距离矩阵获取样本的k近邻矩阵knn、反向k近邻矩阵rnn和共享近邻矩阵snn。

步骤4根据定义2计算样本相对距离δi。

2.2 非中心点分配策略
针对FKNN-DPC的非中心点分配策略中边界点检测方法存在的问题以及为了提高非中心点分配的准确率,RN-DPC引入反向k近邻数作为检测边界点的指标,并结合共享最近邻相似度和k近邻思想提出一种新的非中心点分配策略。
以Jain数据集为例说明FKNN-DPC的边界点检测方法存在的问题。FKNN-DPC在Jain上的边界点检测结果如图3,其中,灰色“+”代表边界点。从图3中可以看出,几乎所有属于黄色类簇的样本都被检测为边界点,而只有极少部分属于紫色类簇的样本被检测为边界点。因为紫色类簇中样本与其第k个近邻的距离比黄色类簇中样本与其第k个近邻的距离更小且紫色类簇样本数量较多,这会导致FKNN-DPC的边界点阈值偏小。而黄色类簇密度较小,其中大量样本与其第k个近邻的距离都大于边界点的阈值,所以,黄色类簇中大量样本都被检测为边界点。显然,这是不合理的。

图3 FKNN-DPC的边界点检测结果
为了解决FKNN-DPC的边界点检测方法不能用于有密度差距的类簇中的问题,RN-DPC利用反向k近邻关系对类簇密度变化不敏感的特点,基于样本的反向k近邻数与k近邻数的比值作为检测边界点的指标,提出一种新的边界点检测方法如下。
定义8给定数据集X,knn(xi)和rnn(xi)分别表示xi的k近邻和反向k近邻集合,对于∀xi∈X,若|rnn(xi)|/|knn(xi)|<1,则xi为边界点,反之,xi不是边界点。边界点集合为B,非边界点集合为B′。
同样,接下来仍用Jain数据集来说明RN-DPC算法的边界点检测方法的有效性。RN-DPC的边界点检测方法在Jain数据集上的检测结果如图4。从图4中可以看出,RN-DPC算法中的边界点检测方法可以保留2个类簇的核心部分,不会使得黄色类簇中大部分样本被检测为边界点。这说明了RN-DPC的边界点定义的有效性和合理性。
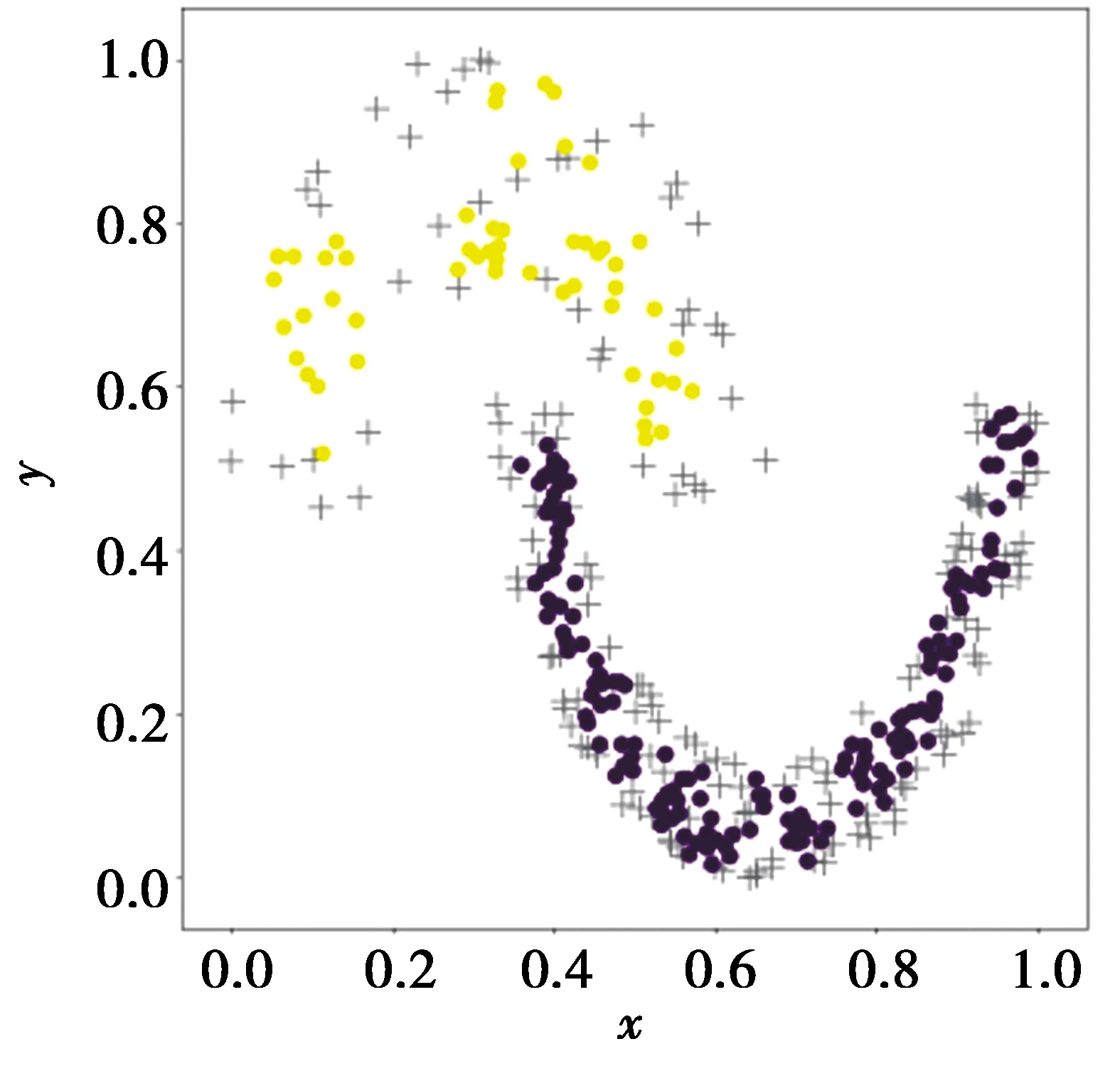
图4 RN-DPC的边界点检测结果
RN-DPC在进行了边界点检测后得到集合B和B′,接下来需要分2步对非中心点进行分配以保证分配的准确率。为了更好地叙述RN-DPC对非中心点的2步分配策略,给出RN-DPC的核心样本定义如下。
定义9给定数据集X,所有样本与其k近邻的共享最近邻相似度均值为γ,xi为任意一个有标签的样本,其k近邻集合为knn(xi),非边界点集合为B′。对∀xj∈knn(xi),若xj∈B′且xi和xj的共享最近邻相似度满足sim(xi,xj)≥γ,则称xj为核心样本,否则,xj为非核心样本。核心样本集合记为C,非核心样本集合记为C′。
RN-DPC算法的2步分配策略首先分配满足定义9的非中心点,然后分配不满足定义9的非中心点。2步分配策略的主要思想如下。
分配策略1:初始化待访问集合为所选择的中心点,每次迭代访问一个已经被分配但没有访问过的样本p,并将p的k近邻中满足定义9的近邻q分配到p所在的类簇,同时将q加入待访问的集合中,一直持续该过程直到待访问集合为空。得到C和C′。
分配策略2:初始化矩阵A,其中任意元素A(i,j)表示样本i的近邻中类簇标签为j的近邻数量。每次迭代找到A的最大值,将最大值对应的行所代表的样本i分配到最大值对应的列所代表的类簇j。进行一次迭代后对矩阵A进行更新,直到A的最大值为0或所有样本分配完毕则停止。
分配策略1和分配策略2的具体步骤分别如算法2和算法3。本文所提出的RN-DPC算法的流程如图5。

图5 RN-DPC算法流程图
算法2分配策略1
输入:近邻数k,中心点centers,k近邻矩阵knn,反向k近邻矩阵rnn,共享最近邻相似度矩阵sim。
输出:剩余未分配样本R。
步骤1初始化数组queue为所选择的中心点centers。
步骤2记queue中的第一个元素为thispoint并将其从queue中删除。
步骤3遍历每thispoint的每一个近邻p,如果p没有被分配并且是一个核心点,添加neighbor到queue的末尾并且分配neighbor到thispoint所在的类簇,否则,跳过点p访问下一个近邻。
步骤4若queue为空,则结束,否则,回到步骤2。
算法3分配策略2
输入:待分配样本集合R,近邻数k,中心点centers,k近邻矩阵knn,反向k近邻矩阵rnn。
输出: 聚类结果S。
步骤1初始化矩阵A,矩阵A中的元素A(i,j)记为样本i的k近邻中属于类簇j的近邻的数目。
步骤2找到矩阵A的最大值,记为maxvalue。
步骤3如果maxvalue大于0,则找到A(i,j)=maxvalue的样本点i和类簇j,并且分配样本点i到对应的类簇j。
步骤4更新矩阵A,将R中已经分配的样本点所在的行置为0,更新R中未分配的样本点的近邻的类簇信息。
步骤5若R为空,则结束,反之,回到步骤2。
2.3 时间复杂度分析
在本节将对RN-DPC的时间复杂度进行分析,设近邻数为k,类簇数为m,核心样本集合为C,非核心样本集合为C′。RN-DPC的时间复杂度主要由算法1、算法2和算法3组成。
算法1这一部分的时间复杂度主要来源于算法1的步骤1,2和4,这3个步骤的时间复杂度均为O(n2),因此,整个算法1的时间复杂度为O(n2)。
算法2分配策略1中需要遍历所有核心样本及其k近邻,时间复杂度为O(k×|C|)。
算法3分配策略2中待分配的样本数为|C′|,最坏的情况下算法3迭代次数为|C′|,每次迭代的主要时间复杂度来源于搜索矩阵A的最大值,时间复杂度为O(m×|C′|)。因此,算法3的平均时间复杂度小于O(m×|C′|2)。因为非核心样本数量远远小于样本总数,所以分配策略2的时间复杂度小于O(n2)。
综上所述,RN-DPC的时间复杂度为O(n2)。
3 对比实验与分析
RN-DPC算法将在人工数据集和真实数据集上与DPC算法、RDDPC算法、KNN-DPC算法、DBSCAN算法和K-means算法进行对比实验以验证其有效性。本文采用ARI[33],NMI[34]来评估聚类算法的聚类结果。ARI和NMI的取值均为[0,1],且值越大,表示聚类的效果越好。
实验所用到的数据集由表1给出。序号1-8为常用的人工数据集,它们被用于测试聚类算法在面对不同分布的类簇时的聚类能力。序号9-16为真实数据集,它们经常被用于测试聚类算法性能。人工数据集中包含了符合高斯分布的数据集,流型流形数据集,类簇高度重叠的数据集以及不同类簇之间有密度差距的数据集。
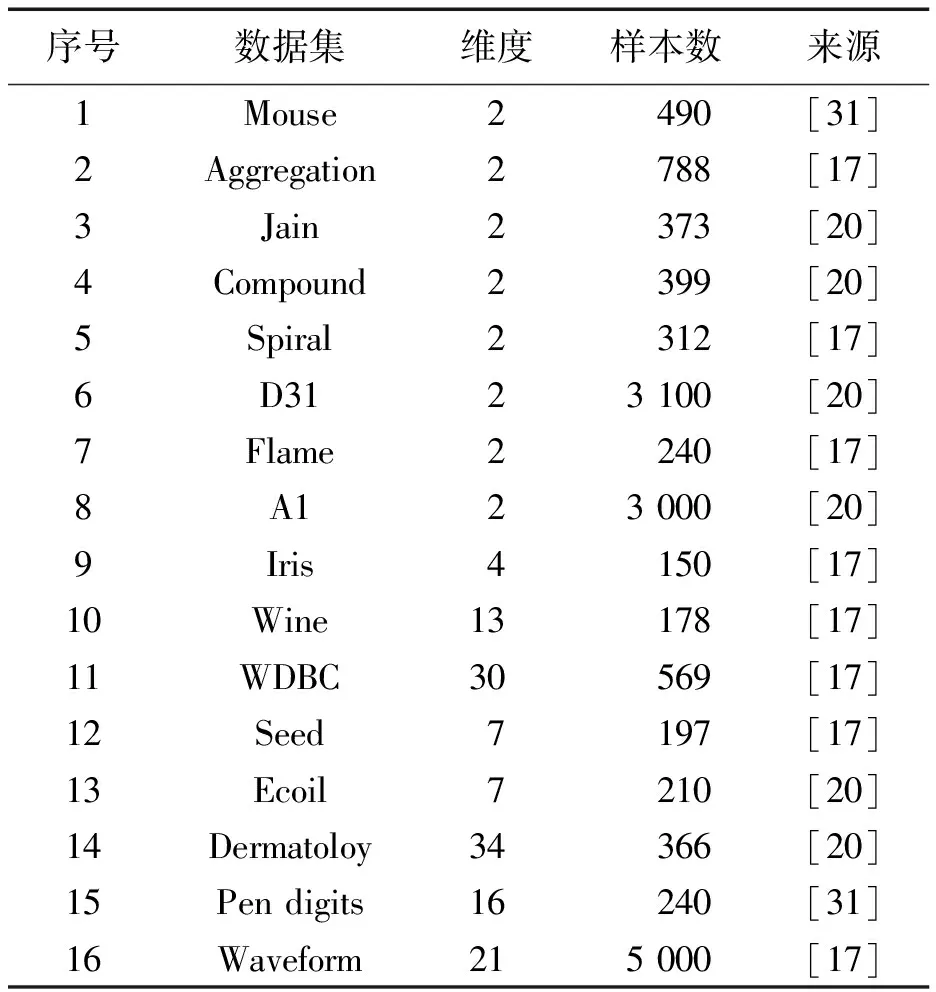
表1 数据集信息
3.1 数据预处理与算法参数设置
为了避免数据集中不同属性量纲不同影响实验结果,本文采用最大最小归一化原则对实验数据进行处理。针对含有缺失值的属性,采用对应属性的均值代替缺失值。
为了保证对比实验的有效性,本文对每种算法都进行参数调优。FKNN-DPC、RDDPC和RN-DPC都需要设置近邻数k,取值为[5,50],调整步长为1。DPC中截断距离dc的取值为(0,1],调整步长为0.01。DBSCAN中需要设置半径eps和密度阈值minpoint,2个参数分别的取值为(0,1]和[1,40],调整步长为0.01和1。因为K-means算法的初始聚类中心点是随机选取的,初始聚类中心点选择不同会导致最终的聚类结果不同,所以对于K-means算法,本文在每个数据集上运行30次,取各聚类评价指标的均值作为最终的聚类结果。
3.2 人工数据集上实验对比分析
人工数据集的样本分布如图6。不同聚类算法在人工数据集上可视化聚类结果如图7—图14。其中,每一幅图的横纵坐标分别表示人工数据集中样本点的2个属性的属性值。图中不同的类簇用不同的颜色区分,聚类中心采用红色五角星进行标识,错误分配的样本点用红色“X”标识。DBSCAN算法检测到的噪声用灰色“+”标识。没有被对应算法所识别出的类簇用灰色圆点标识。6个聚类算法在人工数据集上的具体聚类性能评价指标如表2。
从表2中可以看出,RN-DPC算法在人工数据集上的聚类性能评价指标总体优于其余5个算法。本文所提出的RN-DPC算法在Jain,Flame和Spiral 3个流形数据集上都取得了正确的聚类结果。从图6c中可以看出,Jain中的2个流形类簇间存在明显的密度差距,位于图上方的黄色类簇密度明显小于图下方的紫色类簇。DPC和FKNN-DPC都没有在Jain上取得正确的聚类结果,因为这2个算法的密度度量不能消除不同类簇中样本的密度差距,导致聚类中心选择出错,2个算法的聚类中心选择结果如图9b和图9c,它们都没有识别出位于Jain上方的类簇。从DBSCAN的聚类结果中可以看出,DBSCAN能够正确识别出位于图6c下方的类簇。由于DBSCAN的参数对于类簇密度变化敏感,该算法将图6c上方的类簇识别为了2个不同的类簇。FKNN-DPC没有在Flame数据集上取得正确的聚类结果,因为该算法在分配Flame的边界点时没有考虑到数据点间的密度关系,导致其错误地分配了4个样本,如图13c。其余的DPC算法以及DPC的改进算法在Flame上都能够获得正确的聚类结果。从图13e中可以看出,DBSCAN错误地分配了Flame中的2个边界点,导致其没有获得正确的聚类结果。通过图11展示的不同算法在Spiral上的聚类结果可以看出,除了K-means以外其余5个算法都能获得正确的聚类结果。K-means在3个流形数据集上的表现不太理想,因为该算法按照距离最近的原则划分类簇,这种划分策略无法处理不符合高斯分布的类簇。Compound数据集中有6个类簇,如图6d,其中位于图6d右边的紫色类簇非常稀疏。通过图10展示的不同算法在Compound上的聚类结果中可以看出,6个算法均没有识别出位于图6d右边的紫色类簇。从图10e中可以看出,DBSCAN将属于紫色类簇中的样本全部错误地检测为了噪声。本文算法和RDDPC算法能够识别出Compound中的6个类簇。通过对比图10a和图10d展示的本文算法和RDDPC算法在Compound上的聚类结果可以看出,本文算法可以正确地分配更多的非聚类中心点。因此,本文算法在Compound上的聚类结果优于RDDPC算法。DPC和FKNN-DPC均正确地识别出Compound中的6个类簇,其原因是Compound中右边的紫色类簇不但稀疏,而且还包围了另外1个类簇,这使得2个类簇很难被聚类算法区分出来。

图6 8个人工数据集

图9 Jain数据集上的聚类结果

图10 Compound数据集上的聚类结果

图11 Spiral数据集上的聚类结果
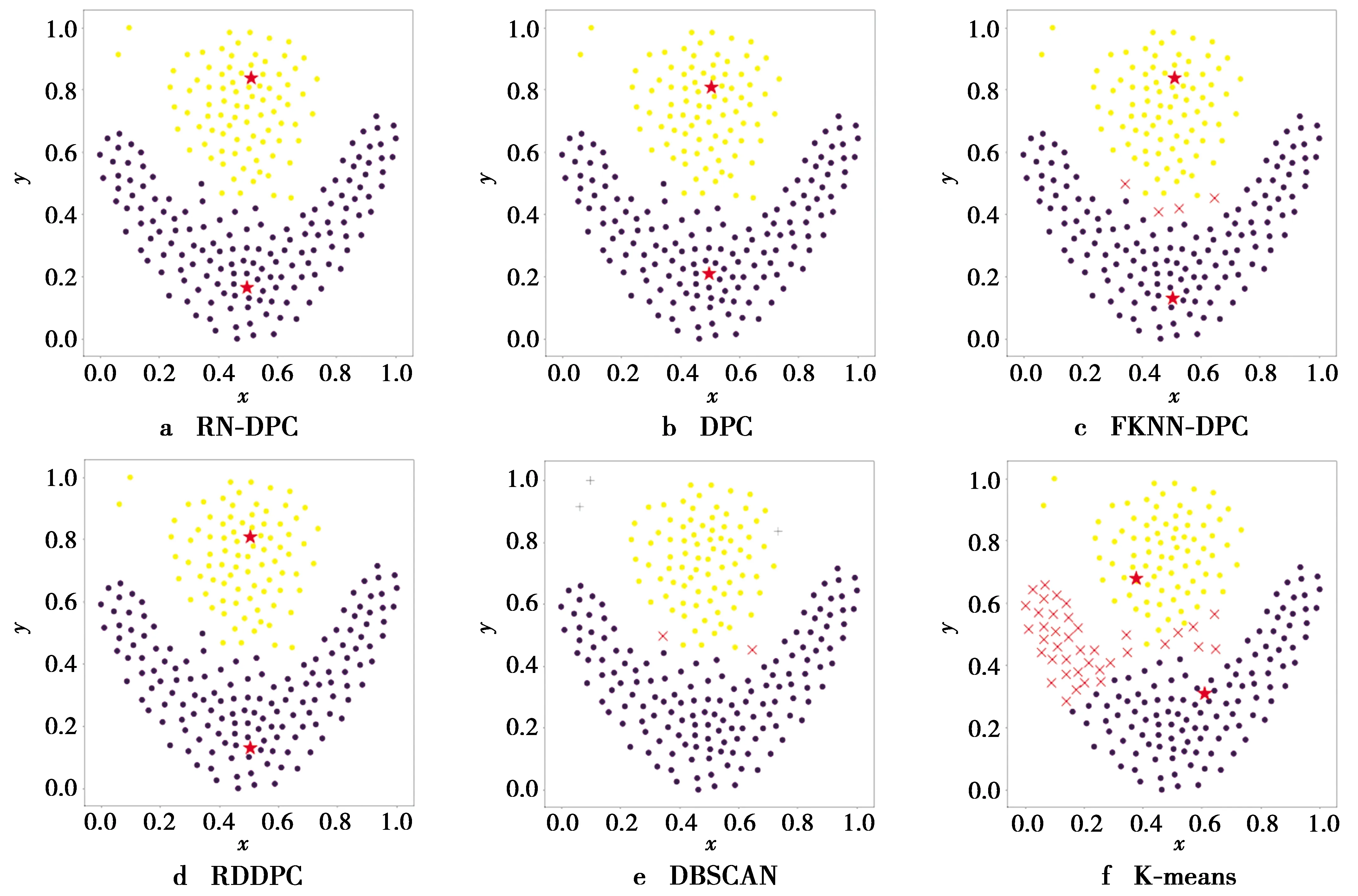
图13 Flame数据集上的聚类结果
接下来讨论Aggregation,Mouse,D31和A1这4个符合高斯分布的数据集。对于Aggregation数据集,从表2中的2个聚类性能指标来看,本文算法的聚类结果略低于DPC,FKNN-DPC和RDDPC,然而,本文算法的聚类结果明显优于K-means和DBSCAN。从图8展示的不同算法在Aggregation上的聚类结果来看,FKNN-DPC只错误地分配了1个样本,因此获得了最好的聚类结果。D31和A1是2个类簇间存在重叠样本的数据集,其中每个类簇的大小基本一致。对于这类数据集,DPC及其改进算法都能选择到正确的聚类中心。由于RN-DPC的边界点检测策略比FKNN-DPC能够更准确地识别出类簇边界,因此,在分配非中心点时能够更好地避免类簇间重叠样本对聚类结果的影响。对比图12a和图12c,本文算法在D31上可以正确地分配更多的非中心点。对比图14a、图14c,本文算法仍然可以正确地分配更多的非中心点。因此,本文算法在A1和D31上的聚类结果都优于FKNN-DPC。K-means算法在D31上取得了最好的聚类结果,这充分地体现了该算法聚类高斯分布类簇的能力。Mouse数据集中的类簇仍然服从高斯分布,但是它包含的3个类簇中有一个类簇较大,其余2个较小。从表2所示中的不同算法在Mouse上的聚类结果可以看出,RN-DPC在Mouse数据集上的聚类结果仅次于FKNN-DPC。从图7f可以看出,K-means算法根据样本与聚类中心的欧式距离对样本进行划分,这导致远离Mouse中最下方类簇中心的一些样本被错误地分配到2个规模较小的类簇中。这也说明了K-means算法只能处理高斯分布的数据集并且数据集中的类簇规模不能相差太大。从图7e可以看出,DBSCAN算法将Mouse数据集中最下方的类簇的大量边界点错误地检测为了噪声,没有取得较好的聚类结果。DPC和RDDPC在Mouse上发生聚类错误的主要原因是在分配边界点时发生了密度跳跃,密度跳跃进一步引起连续错误效应。从图7b和图7d可以看出,DPC和RDDPC错误地分配了较多的边界样本,所以最终的聚类结果不理想。

图8 Aggregation数据集上的聚类结果

图12 D31数据集上的聚类结果

图14 A1数据集上的聚类结果
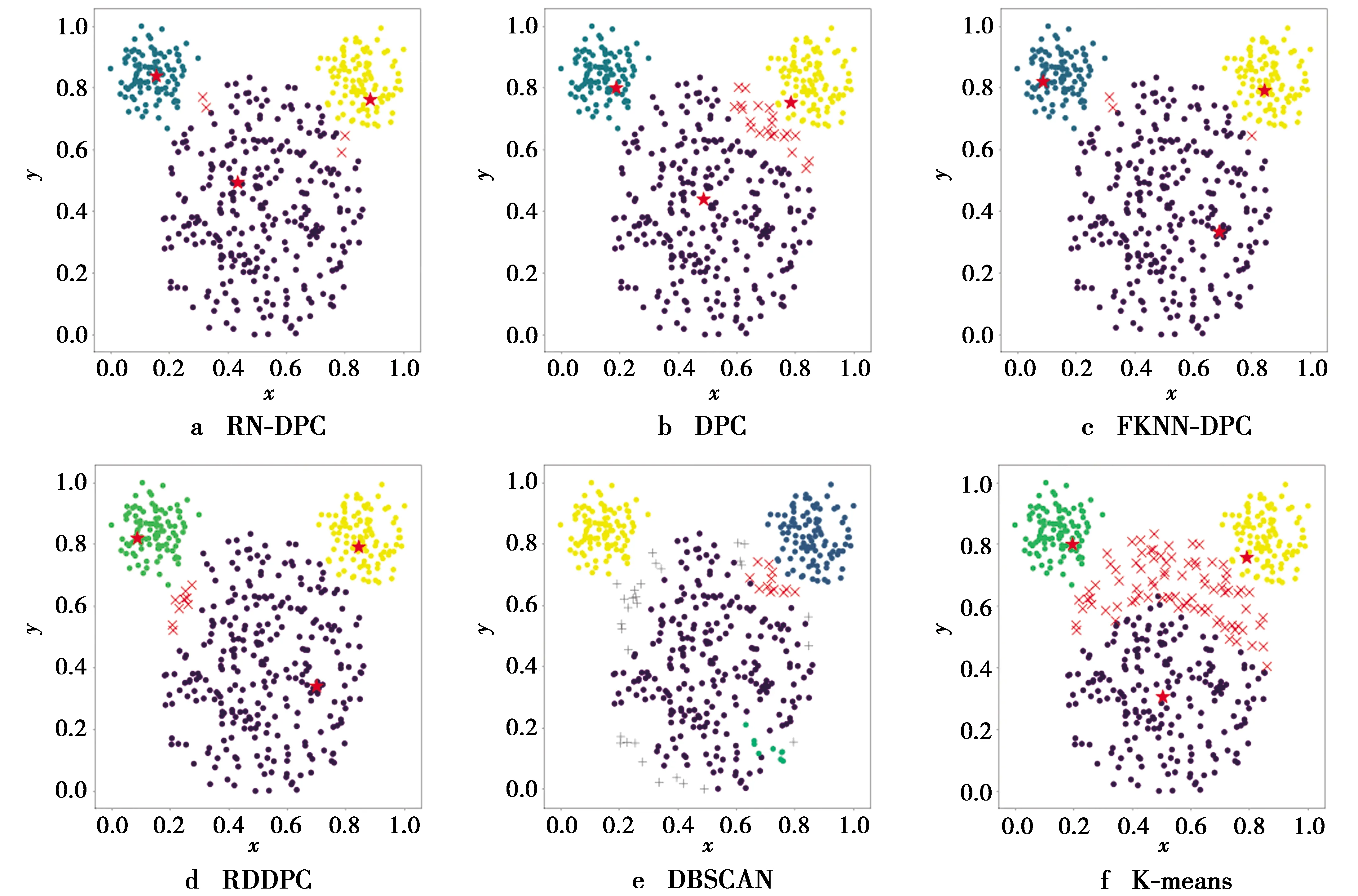
图7 Mouse数据集上的聚类结果
3.3 真实数据集上实验对比分析
真实数据集上聚类结果如表3。从表3中可以看出,RN-DPC算法在8个真实数据集上的聚类性能评价指标均值优于其余5个算法,取得了较好的聚类结果。RN-DPC算法除了在Dermatoloy数据集上的NMI值低于K-means以外,在剩余数据集上都能取得较好的聚类结果。本文所提出的RN-DPC算法在8个真实数据集上的NMI均值相比较于FKNN-DPC和DPC分别提升了4.09%和10.2%,ARI均值相比较于FKNN-DPC和DPC分别提升了6.84%和15.4%。

表3 真实数据集上的实验结果
FKNN-DPC算法取得了仅次于RN-DPC算法的聚类结果。K-means算法的聚类结果排名第3,优于DPC,RDDPC和DBSCAN。对比K-means在人工数据集和真实数据集上的聚类结果,可以看出,K-means在真实数据集上的聚类结果远远优于其在人工数据集上的聚类结果。其原因是人工数据集中大部分数据集的类簇规模大小不一致且类簇形状十分不规则,所以,K-means算法无法很好地处理这些数据集。但是,在真实数据集中,大部分数据集中的类簇符合高斯分布。因此,K-means算法可以在真实数据集上取得不错的聚类效果。RN-DPC算法是基于密度选择聚类中心和k近邻思想分配非聚类中心,不仅可以处理不规则的类簇,而且也可能聚类高斯分布的类簇。所以能够在人工数据集和真实数据集上都取得较好的聚类结果。
本文所提出的RN-DPC算法能够取得较好的聚类效果的原因有以下几点。
1)本文算法在度量样本密度时使用一种新的相对密度度量方法,该方法能够消除不同类簇间的密度差距,更客观地度量样本的密度。
2)本文引入反向k近邻关系进行边界点检测,该方法可以减小类簇间密度差异对边界点检测的影响。
3)本文算法在设计第一步基于k近邻的分配策略时引入共享最近邻相似度,充分考虑了样本的共同邻居信息,使得样本间的相似度度量更合理。
4 总 结
本文为了解决DPC的密度度量无法消除不同类簇间的密度差距以及FKNN-DPC算法的边界点检测方法无法应用到有密度差距的数据集中的问题,定义相对密度并结合近邻关系提出RN-DPC算法。首先,该算法利用样本的反向k近邻数计算相对密度,根据相对密度计算样本的相对距离以选择聚类中心; 其次,根据样本的反向k近邻数进行边界点检测; 然后,针对非边界点,根据样本间的共享最近邻相似度定义核心样本,分配非边界点中满足核心样本定义的样本; 最后,采用k近邻分类的思想设计分配策略用于分配非边界点中不满足核心样本定义的样本,得到聚类结果。经过实验验证,本文所提出的RN-DPC算法不仅可以聚类有密度差距的类簇,而且在满足高斯分布的类簇上也有较好的聚类效果。希望本文的研究工作能够为如何处理复杂场景下的聚类任务提供思路。未来工作将进一步研究如何构建更有效的聚类模型。
猜你喜欢
计算机技术与发展(2020年8期)2020-08-12
数学年刊A辑(中文版)(2020年2期)2020-07-25
电脑报(2020年12期)2020-06-30
数学物理学报(2019年6期)2020-01-13
电脑报(2019年4期)2019-09-10
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
郑州大学学报(工学版)(2017年2期)2017-05-18
大众摄影(2015年9期)2015-09-06
微型电脑应用(2014年4期)2014-08-08
电脑与电信(2014年6期)2014-03-22
