
基于NLP技术的智能化监管规则体系构建研究
2021-11-05 08:03曾宣
电子技术与软件工程 2021年17期
曾宣
(云南电网有限责任公司信息中心 云南省昆明市 650000)
对于监管规则的准确理解,能够在一定程度上提高监管质量和监管效率。但目前,由于监管规则制定没有严格的标准机制,因此常常会出现监管规则的内涵和外延不够精确的问题产生,对于不同监管机构而言,可能由于错误解读造成更严重的管理问题产生[1]。同时,现有监管规则,缺少了对各个模块内容的体系化整合,因此也在一定程度上提高了监管合规的成本。NLP技术是一种全新的自然语言处理技术,将NLP技术应用于实际可以通过机器学习的方式,针对各类复杂法律、法规等内容进行汇总、分析和处理,是一种十分有效的体系构建方法,不仅可以提高规则体系在内容理解上的一致度,还能够进一步降低各个机构体系构建的合规成本。但目前NLP技术在监管领域当中的应用较少,为了实现监管的智能化,本文引入NLP技术,针对监管领域当中的规则体系构建进行优化,并进一步实现智能化监管规则体系构建。
1 智能化监管规则体系构建
1.1 基于NLP技术的监管规则关键词提取
由于采用传统监管规则关键词提取方法在实际应用中过程复杂,并且消耗巨大,因此本文引入NLP技术,利用机器学习实现对监管规则关键词及相关属性的智能化提取。由于当前各类监管描述文件的语言均为机器学习无法识别的自然语言,因此在获取监管规则关键词的过程中,借助NLP技术实现[2]。通过NLP技术的自动检索过程,将负责且没有规律的监管文件中的自然语言转换为计算机能够识别的句子,通过NLP技术对句子进行处理,并生成相应的规则集,得到计算机能够识别的监管规则关键词。大部分监管规则都是以自然语言描述,其结构当中包含了SEQUENCE 属性结构、属性类别以及属性值。无论监管规则关键词是自然语言结构,还是ASN.1 结构,其规则的格式都需要通过RFC2119 定义。
针对监管规则文件的描述,若一个语句当中包含的第一个小节描述的关键词,则将其称之为一个规则。图1 为基于NLP技术的监管规则关键词提取流程示意图。
在提取过程中,首先需要对数据进行格式化处理,并针对各个监管文件当中的页眉和页脚进行处理,并去除掉其中无效字符,例如空格,多余*等,只保留其语句部分。其次,再针对提取到的纯文本进行断句,并将其按照一定规律划分为一段一段字符串,由NLP技术对其进行识别[3]。在这一过程中,对包含提取到的关键词段落进行搜索,并将其存储在自然语言规则集当中,完成对监管规则关键词的提取。
1.2 智能化监管描述语句词性标记
完成对监管规则关键词的提取后,每一个词都有相对应的自然语言属性,针对名词词性的标记,可直接采用NLP 当中的自然语言处理包完成,并通过隐式马尔科夫算法实现。标记的过程可以称之为马尔科夫过程,可用如下公式表示:
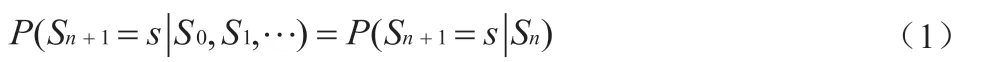
公式(1)中,P 表示为名词词性标记概率;S 表示为标记过程中的一个时间状态;Sn表示为在某一时刻n 时的状态。通过公式(1)可以看出,若Sn+1对于过去状态的条件概率分布仅表示为Sn的一个函数,则当前时刻的状态与上一状态相关,反之同理。按照上述公式完成对名词词性的关键词标记,但在一个完整的监管规则文件当中不仅包含了名词词性还有助词和动词[4]。表1 为大量监管规则描述语句当中的状态迁移矩阵。
从表1 中得出的状态迁移矩阵可以看出,在名词后接上述三个词性的概率分别为0.2/0.3/0.5。因此在对一个监管描述语句进行任务标记时,若前一个为名词,则后一个词最大概率为动词[5]。根据词性,对监管描述语句进行二元组表达,并通过组合元组信息生成条件从句信息,完成对监管描述语句词性的标记。通过上述标记方式实现对监管描述语句的结构化定义,将监管规则关键词作为NLP技术可识别的特征量,并生成最终的特征规则,实现对监管描述文件的标记和对信息任务的提取。

表1:大量监管规则描述语句当中的状态迁移矩阵
1.3 基于End-to-End模型的监管规则体系内容表达
为进一步实现监管规则体系构建的智能化,引入End-to-End 模型,定义一个由单序列三元组的数据结构。将监管规则体系结构划分为Bi-LSTM 层(层级I)、Dropout 层(层级II)和LSTM 解码层(层级III)。分别针对其各个层次进行对监管规则体系内容的表达,首先针对层级I 而言,在监管规则进入到这一层级当中时,将输入的关键词放入到词嵌入层当中,构成一个嵌入矢量,其表达式为:

公式(2)中,W 表示为所有单词序列的集合;wt表示为关键词嵌入矢量;n 表示为当前监管规则语句的长度;d 表示为维度。在完成嵌入处理后,层级I 输入门当中的内容可用公式(3)表达:

公式(3)中,it表示为层级I 输入门当中的内容;δ 表示为监管规则语句信息附加权重;bi表示为监管规则语句状态数据,若使用,则bi值趋近于1,若不使用,则bi值趋近于0。其次,针对层级II,假设每一个隐藏单元都是相互不可依赖的,则需要利用Dropout 解决每个协同适应隐藏层,其表达式为:

公式(4)中,p(i)表示为某一监管规则关键词i 的隐藏激活概率。最后,在层级III 当中完成对监管规则的解码,实现对监管规则体系内容的精确表达。利用如下公式(5)对层级II 当中的监管规则体系隐藏单元进行处理:

公式(5)中,yt表示为监管规则体系内容最终表达结果;Wy表示为softmax 矩阵;Tt表示为上述标记的种类个数;by表示为隐藏层中监管规则语句状态数据。根据上述表达式,在层级III 当中完成处理后,得到各个监管规则所述标记实体的可能性,实现标记替代,完成对监管规则体系内容的表达。
2 实验论证分析
为了验证本文提出的智能化监管规则体系构建方法在实际应用中是否能够满足各项应用性能需要,选择将六种当前流行的SSL/TLS 监管描述文件作为实验对象。分别利用本文提出的构建方法和传统构建方法对六个监管描述文件进行规则体系构建。为了确保实验的客观性,在实验前,对构件评估标准进行设计,选择以构建后体系的漏洞数作为评价指标。其计算公式为:

公式(6)中,BPR(i)表示为某一监管描述文件i 完成规则体系构建后的漏洞数;N 表示为存在差异解释的证书个数;RN 表示为实验中某一类型监管描述文件的测试监管规则总数。根据上述公式,对两种构建方法生成的监管规则体系漏洞数计算,并将结果绘制成如表2所示。

表2:两种监管规则体系构建方法漏洞数对比表
根据表2 两组数据对比得出,本文构建方法在完成对6 个文件的监管规则体系构建后,漏洞数均控制在10 个以下,由于文件中规则信息较多,10 个以下的漏洞数可忽略不计。传统构建方法在完成对6 个文件的监管规则体系构建后,漏洞数均超过10 个,并且最高达到了58 个,严重影响对监管规则体系的理解,容易保证规则体系在内容理解上的一致性。因此,通过对比实验证明,引入NLP技术后,在对监管规则体系构建时能够实现对内容更容易地理解,并且利用机器学习实现智能化构建。
3 结束语
本文引入NLP技术对监管规则体系进行构建,并实现了对体系内容的准确表达。但这种方法在实际应用中仍然存在大量映射,受到人工干预的影响使得智能化程度较浅,因此在后续的研究中还将针对NLP技术在构建方法当中的应用进行更加深入研究,从而借助自然语言处理实现对映射问题的控制,从而实现该构建方法的广泛应用。
猜你喜欢
新高考·高二数学(2022年3期)2022-04-29
新高考·高二数学(2022年3期)2022-04-29
航天工业管理(2020年9期)2020-12-28
中学生数理化(高中版.高二数学)(2020年11期)2020-12-14
军事运筹与系统工程(2020年1期)2020-09-11
新世纪智能(语文备考)(2020年4期)2020-07-25
系统工程与电子技术(2016年2期)2016-04-16
语文知识(2014年4期)2014-02-28
小雪花·初中高分作文(2009年8期)2009-11-16
