
Blockchain-Based Log Verification System for Cloud Forensics
2021-11-02 01:30AGBEDANUPromiseRicardoWANGPengwei王鹏伟LEIYinghui雷颖慧NORTEYRichardRASOOLAbdulODARTEYLamptey
AGBEDANU Promise Ricardo, WANG Pengwei(王鹏伟), LEI Yinghui(雷颖慧), NORTEY Richard N, RASOOL Abdul, ODARTEY Lamptey K
School of Computer Science and Technology, Donghua University, Shanghai 201620, China
Abstract: In this age when most organizations make use of cloud computing, it is important to not only protect cloud computing resources from cyber-attacks but also investigate these attacks. During forensic investigations in a cloud environment, the investigators fall on service providers for pieces of evidence like log files. The challenge, however, is the integrity of these logs provided by the service providers. To this end, we propose a blockchain-based log verification system called BlogVerifier that uses a decentralized approach to solve forensics issues in the cloud. BlogVerifier extracts logs produced in cloud environments, hashes these logs and stores the hashed values as transactional values on the blockchain. The transactions are then merged into blocks and shared on the blockchain. The proposed system also ensures the continuation of an investigation even when the primary source of a log is compromised by using encryption and smart contracts. The proposed system also makes it possible for any stakeholder involved in the forensic process to verify the authenticity of log files. The performance results show that BlogVerifier can be integrated into the cloud environment without any significant impact on system resources and increase in computational cost.
Key words: cloud computing; forensics; blockchain; cryptography; security
Introduction
Cloud computing is a technology that not only has improved efficiency in businesses, but also has reduced cost, increased flexibility and improved mobility. It has also brought a great deal of convenience to individuals and organizations. The advantages provided by the cloud make it even more attractive to cyber-attacks. This situation exerts a lot of pressure on the cloud in terms of security.
The number and the cost of cyber-attacks have been increasing over the years. According to Ref. [1], the damages caused by cybercrimes will cost a whopping 6 trillion dollars by the year of 2021. Fishing out the perpetrators of these cybercrimes in a cloud computing environment comes with several bottlenecks. In traditional digital forensics, an investigator can confiscate a computer system or any related device used in committing a crime and analyze it. This, however, is different when it comes to conducting forensic investigation in the cloud. It is very difficult for law enforcement agencies(LEAs) to use the same approach and methodology used in traditional digital forensic for cloud forensics, and these are caused by the architectural and dynamic nature of the cloud.
According to Ref. [2], computer forensics is the science of retrieving, analyzing and using digital evidence in either civil or criminal investigations. Besides, cloud forensics is relatively new as compared to computer forensics. Moreover, the nature of the cloud makes forensic investigation in the cloud more difficult than traditional digital forensics. National Institute of Standards and Technology(NIST)[3]defines cloud forensics as “the application of scientific principles, technological practices and derived and proven methods to reconstruct past cloud computing events through identification, collection, preservation, examination, interpretation and reporting of digital evidence”. From NIST’s definition of cloud forensics, the forensic process in the cloud involves identification, collection, preservation, examination, interpretation and reporting of digital evidence. This digital evidence could be in the form of logs, e-mails, audio, video, databases and so on.
According to Ref. [4], for any digital evidence to be accepted in a court, it must satisfy the conditions of authentication and chain of custody.
The cloud has a massive physical infrastructure that makes it practically impossible for an investigator to confiscate it for forensic analysis. The only possible means is for the investigator to contact the cloud service provider(CSP) for the evidence. The concept of depending on a third party for evidence introduces some challenges that may not be present when conducting a traditional digital forensic. Hermanetal.[3]identified 65 challenges that could be faced when conducting a forensic investigation in the cloud. Similarly, other researchers also identified some challenges that confronted forensics in the cloud[5-9]. The dependency on CSPs was captured as a challenge in Refs. [3, 5-9]. The dependency on a third party for evidence collection creates two primary challenges that can hinder the admissibility of evidence in a court of law. These challenges are trust and integrity.
A service provider may tamper with evidence before giving it to an investigator, or an investigator can connive with an attacker and change the content of the evidence before handing it over to a court. Based on the above challenges concerning forensics in the cloud, it is important to use a technique that will ensure the integrity, trust and verifiability of the evidence provided in a forensic investigation.
Blockchain technology has so far been promising and it has been used to solve a lot of problems in different research areas. Its ability to provide characteristics such as immutability, temper resistant and resilient to attacks like denial of service(DoS) and distributed denial of service(DDoS) makes it a likely panacea to most security-related problems. In vehicular networking, it has been used to achieve secured data storage and sharing[10]. In Internet of things(IoT) and edge computing, blockchain technology is being used to solve architectural problems[11-12]and secured storage problems[13]. Blockchain has also been used to solve cloud computing problems such as shared ownership[14]and effective resource management[15].
The field of digital forensics is also receiving some recognition when it comes to using blockchain to solve forensic problems. Lietal.[16]proposed a blockchain-based architecture for IoT and social systems. Although this work was preliminary research, it sought to provide some of the strengths blockchain that can bring to the field of digital forensics.
Distributed open ledger(DOL) has been used in different ways when it comes to cloud forensics. Blockchain, which is a DOL, is used to ensure tamper-proof forensic data[17]. Zhangetal.[17]accomplished this by sending the digital signatures of the interacting parties involved in the collection and submission of the forensic data to a third party known as the provenance auditor(PA). The use of blockchain by the PA ensures that the process records can be reliably verified and difficult to be tampered with. The downside of this method by Zhangetal.[17]is the use of a third party. This makes their approach more of a centralized one. In an event where the third party is compromised, the evidence loses its credibility. Similarly, Liuetal.[18]proposed a distributed cloud forensic system that did not depend on a single node or a third party for evidence gathering and verification. Although this work fully uses a decentralized approach, it lacks experimental validation.
Zawoad and Hasan[19]designed a system called Chronos, which prevented users or attackers from modifying system time. Chronos has three entities, namely, virtual machine(VM), host and Chronos server. Each of these entities verifies the timestamp of the other and the information is stored using a cryptographic scheme. The proof of time is then published on the Internet. However, publishing the proof of time on the Internet may lead to unavailability of proofs in case of a DoS attack.
Maintaining the integrity and confidentiality of logs as well as providing a verification mechanism is very important in every forensic investigation. Every cloud forensic model should ensure the integrity, confidentiality and verifiability of evidence they produce[20]. It is not an easy task achieving all these three parameters, especially in cloud computing environments. In solving these challenges, Singhetal.[21]proposed a model that first extracted network logs from the cloud node controller with the help of an intrusion detection system(IDS). Just like Zawoad and Hasan’s approach, publishing the proof of past log(PPL) online on a single node may lead the unavailability of the PPL during a DoS attack.
Wu and Yong[22]also presented a method of securely monitoring logging in a cloud environment. Similarly, Zawoadetal.[23]proposed a secure logging-as-a-service for cloud forensics that enables secure retrieval of logs and storage of the proof of past logs. The proposed system has the following components: parser, logger, log storage, proof accumulator and the web. The parser communicates with the log sources to collect different types of logs. After the log acquisition, the parser then parses the collected log and generates the log entry.
Some researchers have also used proof-of-concept methods to solve the problems of integrity and verification in cloud forensics. One of such works was proposed by Liuetal.[24]. The method used in their work includes a proof-of-concept system deployed on the top of the open-source cloud infrastructure. They then developed algorithms to verify the integrity of the streaming data that was presented. To efficiently verify the integrity of streaming data, the authors use the scheme of the fragile watermark which has demonstrated great efficiency for data integrity verification in other works. Developing forensic frameworks that ensure the integrity of logs is one of the surest ways that researchers and CSPs can use to make sure that evidence presented during a forensic investigation is genuine.
Zawoad and Hasan[19]proposed an architecture that ensured the integrity of logs generated in a cloud environment. The modules of this architecture include provenance manager, logger, data-possession manger, timestamp manager and a proof publisher. The challenge we identified with most of the works that are reviewed under this section is the centralization of proof of logs. This approach leads to service unavailability during DoS attacks. Moreover, not a single of these approaches focuses on the continuation of an investigation even when the primary source of the evidence is compromised.
In this work, we propose a blockchain-based log verification system called BlogVerifier that not only ensures the integrity of logs used for forensic purposes but also allows logs to be verified by various actors along the chain of custody. Our proposed model also allows forensic investigation to continue even when the source of logs is compromised.
The rest of this paper is structured as follows. Sections 1 captures our blockchain-based forensic framework(Bloclonsic). Section 2 provides details about our system design, while sections 3, 4, 5, 6, and 7 deal with consensus process, verification of evidence, implementation and experimental results, discussion, and conclusions, respectively.
1 Bloclonsic
In this subsection of the work, the proposed Bloclonsic is presented. Bloclonsic is made up of CSPs, users, VMs, a log extractor, forensic stakeholders, DoL(blockchain) and storage nodes. In cloud computing, a user subscribes to a service offered by a CSP. The user is then allocated a VM with a certain computational capacity based on the service model the user requested. These VMs generate logs such as systems, application, networks, security, setup and audit logs. In our framework, the various logs generated by VMs are extracted and processed. The processing of the logs involves hashing and encryption. The first stage is to hash the logs. The logs are hashed before being written onto the blockchain network because logs may contain critical and sensitive information. Hashing the logs prevents the possibility of exposing this information to other users. The hash values of the hashed logs are then written onto the blockchain network. Bloclonsic further ensures that even in the event where the primary source of a log is compromised investigations can continue. During the second stage, the logs are encrypted using the public key of forensic investigators and then storing the ciphertext of the log on storage nodes. Figure 1 shows the proposed Bloclonsic. Each component of Bloclonsic is briefly described in the successive paragraphs.
(1) CSP. The CSP is responsible for providing systems like VMs. In cloud forensics, the investigator is dependent on the CSP most of the time. This dependency comes as a result of the role that the CSP plays during a forensic investigation. The CSP in most cases provides the investigator with the evidence needed to solve a particular case.
(2) User. This is a client who requests a service from a service provider. The user chooses a service plan based on his or her needs. A user may either be an individual or an organization. In the case of an organization, the user(organization) may have several sub-users(employees) who use the resources that have been provided to the organization by the service provider.
(3) VM. In a typical cloud computing environment, the service provider rents out a portion of its system to the user in the form of a VM. This concept is made possible through the use of virtualization technology. These VMs just like physical systems produce all kinds of logs which log the activities of both legitimate and illegitimate users.
(4) Forensic stakeholders. Forensic stakeholders are made up of all individuals, groups, and entities that are responsible for solving a particular cyber-crime. Forensic stakeholders include investigators, prosecutors, lawyers, and the court. Bloclonsic integrates forensic stakeholders in its setup to enable these stakeholders to verify the authenticity of the logs that they are dealing with.
(5) Log extractor. This is the part of Bloclonsic that is responsible for extracting and converting logs into hash values and ciphertext. Logs may contain sensitive information, and hence they need to be processed before broadcasting them on a blockchain network or before they are stored.
(6) Storage node. This is a location where encrypted logs are stored. This storage node is usually a storage space provided by a CSP. Encrypted logs are stored on storage nodes in the cloud.
(7) Blockchain. Building a Bloclonsic allows logs to be stored in a distributed manner. The immutability property prevents CSPs or investigators from modifying logs. The hash value of a log is stored on the blockchain network, thereby making it difficult to modify the transaction without it being detected.
2 BlogVerifier Design
In this section, we describe the proposed system and explain how it can be used to ensure the integrity of the log files generated by VMs which emulate cloud instances.
BlogVerifier is deployed in multiple cloud computing systems. The VMs of each participating system becomes a node(peer) while the cloud systems become committee members. Cloud systems are selected to be committee members because of their high computational power. This makes it practically impossible for a malicious node to become committee members. Unlike most existing systems as reported in Refs. [19, 23, 25], BlogVerifier uses a fully decentralized approach for ensuring the integrity of logs produced in a cloud environment. This approach makes the system more resilient to attacks like DoS and DDoS.
The inclusion of forensic stakeholders into the system makes verification easier and more transparent. Each forensic stakeholder is a participating node in the network and therefore has a copy of the entire blockchain transaction. A major advantage of BlogVerifier is its ability to allow the continuation of forensic investigation even when the primary source of logs is compromised.
2.1 System structure
The participants of this system are the various VMs and users of cloud computing systems. These participants are from multiple cloud computing systems. Our BlogVerifier has three layers, namely, user, log processing and storage layers. Figure 2 shows the system structure of BlogVerifier. These cloud computing systems generate logs that can be used to carry out forensic investigations. The generated logs are extracted and processed by the log processing and management unit(LPMU). After processing the logs, they are hashed and the hashed values are stored on the blockchain network as transaction values. A system user who wants to verify the authenticity of a log will make the request through the LPMU.
2.2 User layer
This layer is made up of all stakeholders involved in the forensic process. These stakeholders include forensic investigators, prosecutors and the court. Users are categorized into two groups. A user can either be predefined or ad-hoc. Predefined users are forensic investigators who have been incorporated into the BlogVerifier. The public keys of these users are used to encrypt logs and stored. The other group of users is known as ad-hoc users. Ad-hoc users have access to the BlogVerifier for verification and prosecution purposes. Ad-hoc users are made up of some investigators who have not been captured as predefined users and the court. The rationale behind the introduction of predefined users in our work is to help investigation to continue even if the CSPs fails to provide logs needed or when these logs are compromised. Although these are the major stakeholders in the forensic process, other users can be added to the system upon request.
2.3 Log processing layer
The log processing layer is basically made up of the LPMU which is responsible for processing and managing the logs. It is responsible for extracting and processing the logs by hashing and encrypting them simultaneously.
2.4 Storage layer
In our BlogVerifier, the storage layer has the logs generated by various systems and also the distributed ledger. The storage layer is found on the participating node. This layer serves as the foundation of BlogVerifier. The logs are extracted from the participating node and then processed by the LPMU. After the successful processing of the logs, they are written to a block after the consensus and verification processes. The block is then appended to the chain of blocks of which a copy is kept by the participating node at the storage layer. The encrypted log is then stored in the cloud.
2.5 LPMU
The log processing unit is part of the log processing layer. It has three sub-components, namely, log manager, authentication and service manager(ASM) and smart contract unit. We present a brief description of what each of these sub-components does in the following paragraphs.
(1)Log manager. The log manager is responsible for the extraction of logs from the participating system. Two different operations are performed on the extracted log. The first operation is the hashing of the extracted log using a SHA-256 hash function. The second operation is to encrypt the extracted log using the public keys of the predefined users located at the user layer of our system. Elliptic curve cryptography(ECC) is used in encrypting the logs. The hashed values are then presented as a transaction onto the block while the encrypted logs are stored on allocated storage nodes. Before the transaction is written onto the block, a consensus needs to be reached by the participating entity and subsequently verified. The log manager is also responsible for executing the consensus algorithm. The block is then added to the chain of blocks on the network.
(2) ASM. The role of the ASM is to authenticate users of the systems and then grant them access to a specific service. The ASM does this based on the functions declared and spelt out in the smart contract. Access to the system comes in two different levels. The first level requires a user to enter a username and its password. A correct username and the password grant a user access to the system but the user cannot read the content of the logs. For a user to read the logs, he or she needs to decrypt the log. At this stage, the second level of authentication and service granting is evoked. It is only predefined users who are eligible to decrypt logs. The user provides his or her private key which leads to the decryption of the log. All these conditions are taken care of by the smart contract.
(3) Smart contract unit. This unit houses the various smart contracts that are deployed in the BlogVerifier. The use of smart contracts in our BlogVerifier is to allow only legitimate and authorized users access to the system. The smart contract allows only users whose public keys are used in encrypting logs to be the only ones who can decrypt logs. The smart contract does this in conjunction with the ASM. The smart contract used in this work is presented in algorithm 1(shown in Fig. 3). Figure 4 shows a detailed structure of the LPMU of the BlogVerifier. The smart contract is initialized using six parameters. These initialization parameters arecheck_key,action,access,require,promptanduser. Five functions are declared. These arefunction(check_key),function(action),function(access),function(prompt) andfunction(user). Thefunction(action) is invoked to perform a particular action such as decrypting a log file and reporting the actions of a user. Thefunction(check_key) is responsible for checking that the private key used by a predefined user has its corresponding public key in the system. Thefunction(prompt) displays the output of a decryption process. Thefunction(user) checks whether a user is ad-hoc or predefined and then returns the value tofunction(access) for access to be granted or denied.
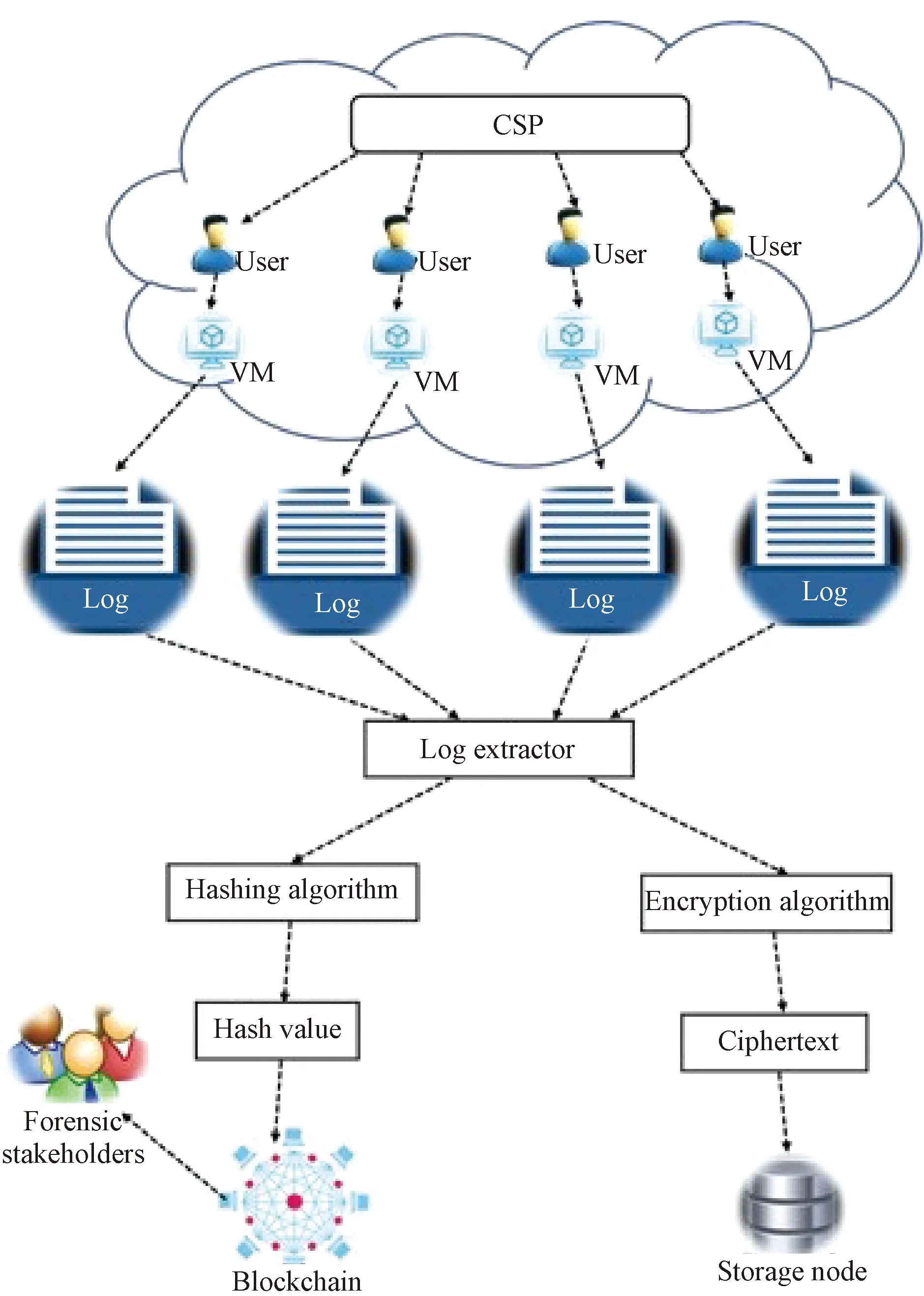
Fig. 1 Bloclonsic
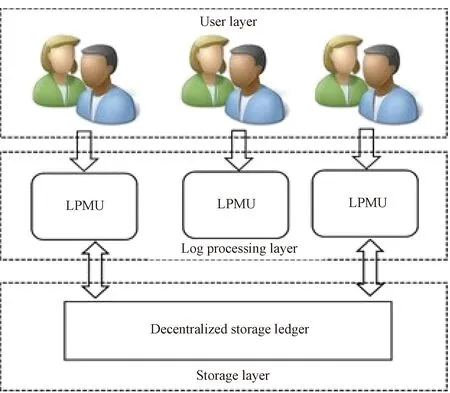
Fig. 2 BlogVerifier system structure

Fig. 3 Algorithm 1: smart contract execution

Fig. 4 Detailed structure of LPMU
3 Consensus Process
In our BlogVerifier, we adopted two consensus protocols and scaled them to suit the objective of our system. We adopted the ripple consensus algorithm(RCA) and Algorand proposed in Refs. [26-27]. RCA is robust against Byzantine failures and also provides low latency.
Every participating node stands the chance of being nominated to be part of committee members(CMs). The selection of CMs is based on the computational resource participating nodes owning in the network. This is coded into the genesis block. The assumption is that honest nodes hold 2/3 of the total computing resources in the network. The selection is based on a private and non-interactive way. Every participating node in the system can independently determine if it is chosen to be part of the committee by computing a function of its private key and public information from the blockchain.
Any CM can propose a transaction that is then broadcasted on the network and added to the block after the consensus process. Each CM takes all valid transactions and makes them public in the form called the candidate set. Transactions that receive more than the minimum percentage of yes votes are passed onto the next round. The final round of consensus requires a minimum percentage of 80% of CMs agreeing on a transaction. In this work, there are 62 nodes in the network out of which 40 of them are CMs. The consensus process has four initialization parametersgenesis_block,com_mem,com_resourceandverifyNode. Thegenesis_blockis the first block of the chain of blocks,com_memrepresents the CMs andcom_resourcerepresents the resource each CM has in the network. In our work, the resources that CMs own are the speed of CPU, the capacity of memory and storage. The function to create the genesis block is the functiongenesis_blockwhich contains the CM’s identity, the resource they own and their public key. The functioncom_memhas the ID of the CM, the resource they own and private key of the CM. For other CMs to verify that a particular CM has been elected to propose a block, the functionverifyNodeis executed. The functionverifyNodeuses the public key of the CM to verify the node’s selection. The consensus algorithm is presented in algorithm 2(show in Fig.5).

Fig. 5 Algorithm 2: consensus algorithm
4 Verification of Evidence
Unlike traditional digital forensics, investigators solely depend on CSPs for evidence when it comes to cloud forensics. This dependency on CSPs may lead to the compromise of pieces of evidence. BlogVerifier not only ensures the integrity of logs through the use of a decentralized ledger but also allows logs tendered in as evidence to be verified by various stakeholders in the forensic process.
In Ref. [18], evidence verification ends when calculated proofs are not the same as fetched proofs. This approach allows most perpetrators of cyber-crime to go unpunished if the primary source of evidence is compromised. In BlogVerifier, this problem is solved by creating a backup of all logs in the form of encrypted logs. In the BlogVerifier, the forensic investigator still falls on the CSP for the evidence. The evidence which in this case is the various logs generated by the different VMs is hashed. The hashed value is then compared to the hashes stored on the distributed ledger. If the hash value exists on the distributed ledger, the log is accepted by the investigator and forwarded to the court as evidence. If the hash value does not exist on the distributed ledger, the log is rejected.
However, if the investigator is a predefined user, he or she will decrypt a copy of the encrypted log with his or her private key. The decrypted log is hashed and compared to the hash values stored on the distributed ledger. If the hash value is found on the ledger, the log is forwarded to the court. The court receives the evidence, hashes it and compares it to the hash values on the distributed ledger. If the value exists, the evidence is accepted by the court. Otherwise, it is rejected. The verification process of BlogVerifier is shown in Fig. 6 and the verification algorithm of BlogVerifier is shown in algorithm 3(shown in Fig. 7).
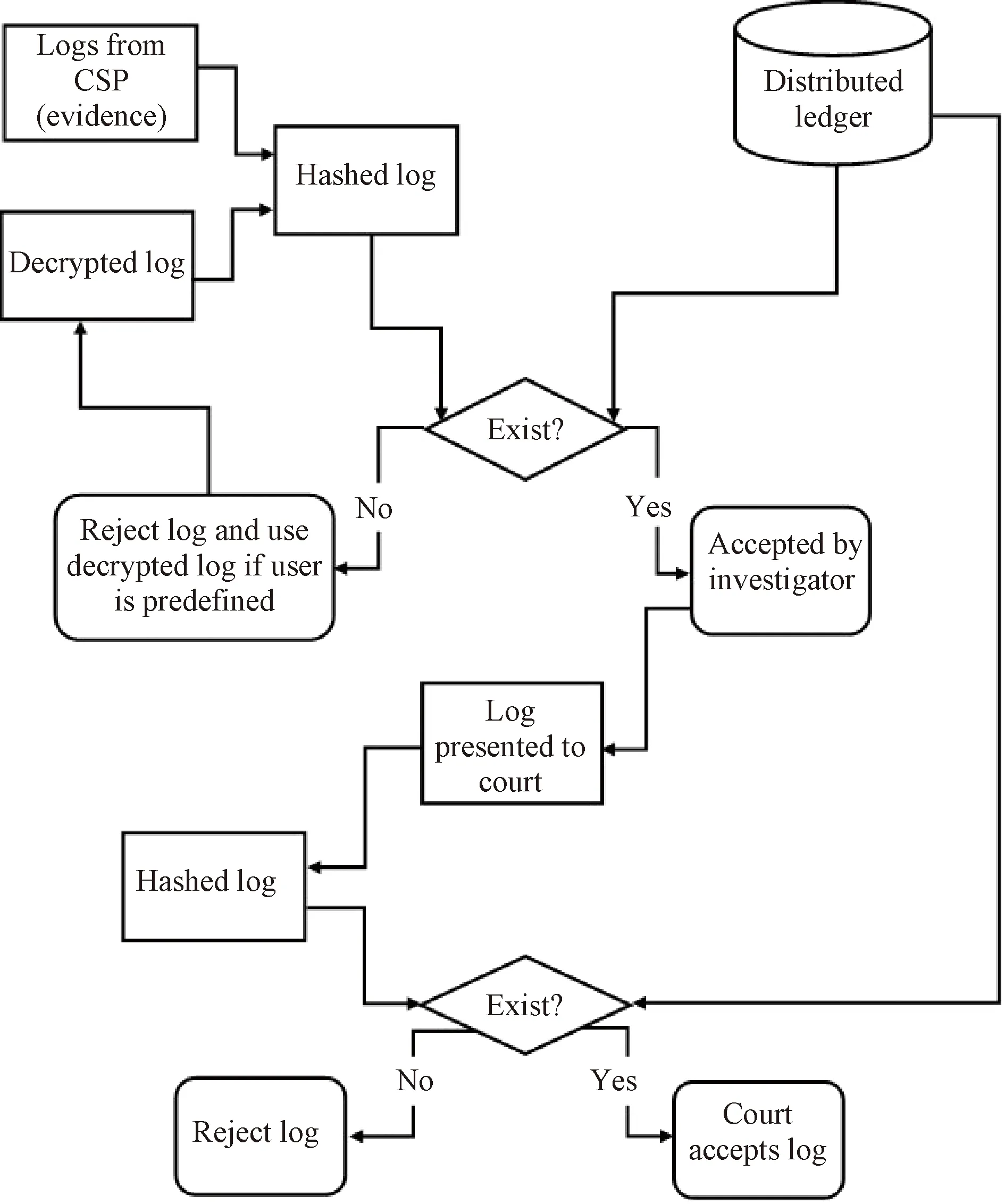
Fig. 6 Verification process of BlogVerifier

Fig. 7 Algorithm 3: verification process
5 Implementation and Experimental Results
The proposed system was deployed using OpenStack and Hyperledger fabric. OpenStack software was implemented as a cloud architecture whereas Hyperledger fabric was implemented as the blockchain network. OpenStack is chosen because it is popular, open-sourced and most importantly free. Similarly, Hyperledger fabric is chosen because it is a permissioned blockchain infrastructure, executes smart contracts, and allows for a configurable consensus and membership.
OpenStack is deployed on CentOS 7 which runs on a VM with a 128 GB RAM, disk space of 400 GB and 4 CPU cores. The VM runs on a physical machine with an Intel CPU of speed 2.66 GHz, RAM of 384 GB, 7 CPU cores and hard disk capacity of 2 TB. On our OpenStack, 32 Ubuntu instances were created, with Hyperledger fabric version 1.4 installed on 30 of these Ubuntu instances. Each instance was deployed on a system with a RAM of 1 GB and a 4 GB disk space. Each of these 30 instances hosted two peer nodes on each Hyperledger fabric and 20 out of the 30 instances were configured as CMs while the remaining 10 were configured as participating nodes. The other two instances were deployed as a verification node used by forensic investigators or the court.
SHA-256 hash function was used for hashing the logs before they are written onto the block. The rationale behind the hashing of logs before they are written on the block is to ensure the privacy of the logs since they contain sensitive data. The proposed system ensures that forensic investigations continue even when the primary source of logs is compromised. This is achieved by encrypting the logs using an elliptic curve cryptography. The encrypted log is then stored on different storage nodes in the cloud.
To evaluate the performance, scalability, and effectiveness of the implemented system, some experiments were performed to determine the resources that the system consumed, the time used to propose and commit a block(execution time), latency, throughput, scalability, the time used to encrypt and decrypt a log, and how long it took to search for a record during the verification process. The experiments were carried out in two different stages.
(1) Latency. This is the delay that occurs between the time a transaction is initiated and the time the transaction finishes.
(2) Execution time. The execution time is total the amount of time in seconds that it takes for a complete forensic transaction to take place. A complete forensic transaction means the total time it takes for a hashed log to be committed to the blockchain.
(3) Throughput. This metric measures the number of successful transactions that are executed per second.
(4) Scalability. Since the rationale behind the development of the system is to deploy it in a real cloud environment, it is important to measure its scalability. Scalability was achieved by increasing the number of participating nodes to 60 while measuring the execution time, throughput, verification time and latency.
(5) Verification time. This metric evaluates how long it takes for a forensic stakeholder to look up for a transaction on the block.
The experimental results of our prototype system are shown in Fig. 8.
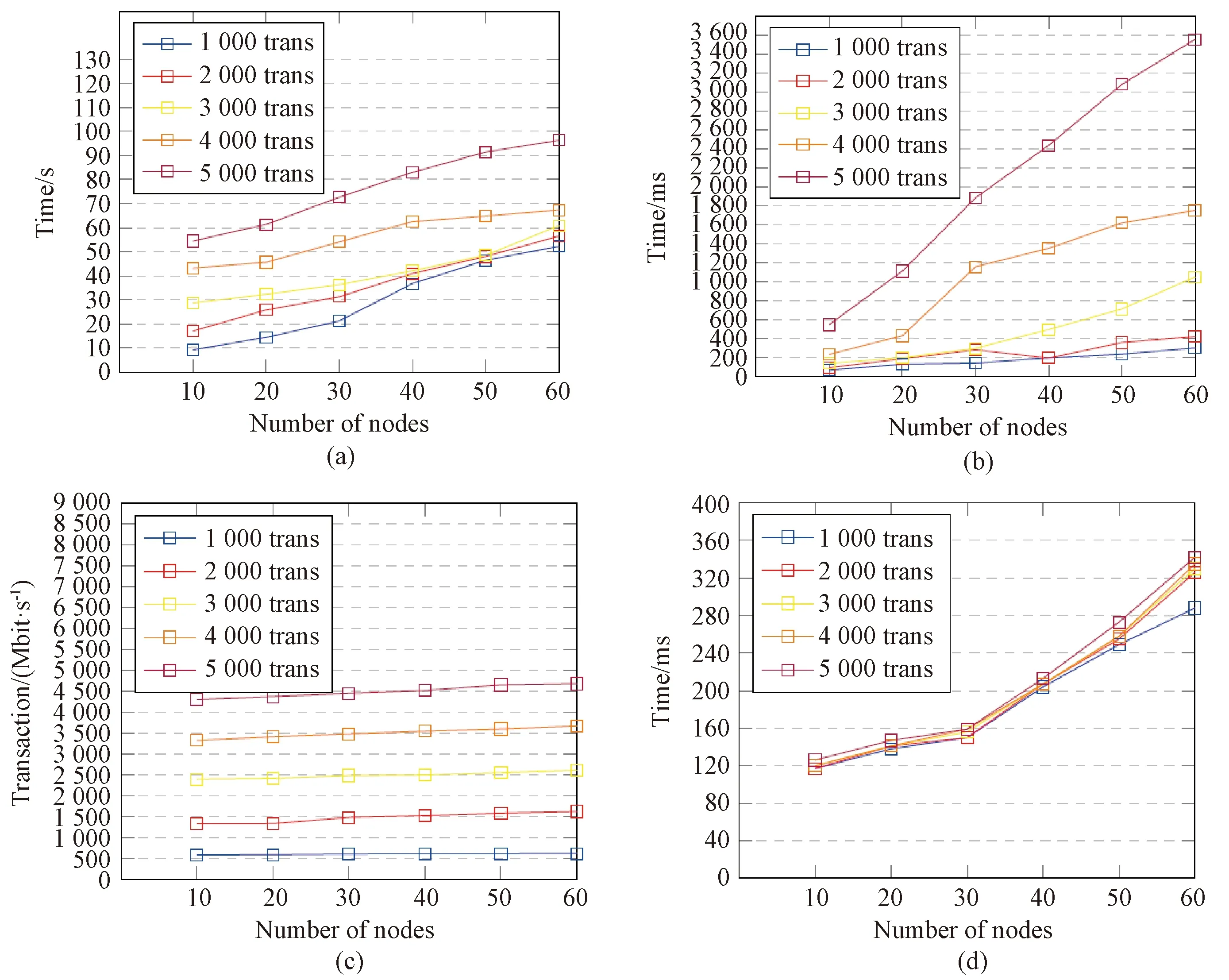
Fig. 8 Experimental results showing the performance of BlogVerifier(trans means transactions): (a) execution; (b)latency; (c)throughout; (d)verification
6 Discussion
In this section we discuss the advantages of BlogVerifier, the possible impact it may have on the performance of cloud computing and then the comparison of our system to other existing systems. Firstly, BlogVerifier is a blockchain-based system that is fully decentralized. This characteristic of BlogVerifier ensures the integrity of logs. BlogVerifier uses the immutability property of blockchain as a leverage to ensure the integrity of logs produced in a cloud environment. Secondly, BlogVerifier offers the advantage of verifiability. This advantage makes it possible for forensic stakeholders to verify the authenticity of the logs. The proposed system can be fully deployed in cloud environments. During our experimental design, we scaled up the number of nodes to emulate cloud instances and the results showed that BlogVerifier was scalable. Finally, BlogVerifier offers the possibility of continuing forensic investigations even when the primary source of logs is compromised.
We acknowledge the fact that integrating BlogVerifier into a large cloud environment will come with some additional cost in terms of resource usage and computation. However, the performance analysis of the experiments we conducted shows that BlogVerifier can effectively and efficiently be integrated into large cloud environments with a little overhead cost. We also compared our system to other existing systems that focus on provenance and integrity of evidence in cloud forensic. The comparison is based on metrics which ensure that forensic pieces of evidence presented to a court is admissible. These metrics also ensure that evidence is not compromised by a CSP or any other person along the chain of custody. Table 1 presents a comparison between BlogVerifier and other existing works considered in this paper. From Table 1, when a particular stratifies a metric, the cell is marked with Y(yes). Otherwise, the cell is marked with N(no).
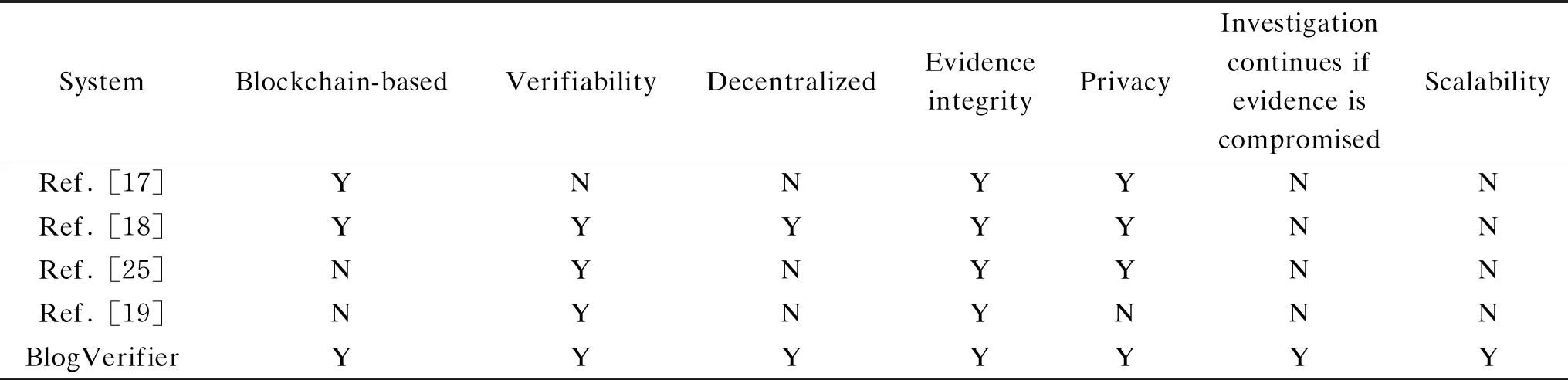
Table 1 Comparing our system to other existing systems by different metrics
7 Conclusions
Unlike traditional digital forensics, evidence collection in the cloud is very challenging. The investigator solely relies on CSPs for evidence like logs. This dependency on CSPs introduces the problems of trust and integrity. A CSP can modify a system log before handing it over to an investigator. Furthermore, an investigator can connive with the perpetrator of a cyber-crime and modify the content of a log before presenting it to a court of law. To solve the above-mentioned challenges, we proposed a blockchain-based log verification system called BlogVerifier that prevents both CSPs and investigators from modifying system logs. The BlogVerifier not only ensures that logs presented for prosecution purposes are credible, but also provides a means by which investigators and the court can verify the authenticity of the logs. The BlogVerifier also considers possible threats that can be launched against the system and designed ways of mitigating such threats. From the experiments and evaluations conducted, BlogVerifier can be integrated into an existing cloud system without any significant increase in computational cost. As part of our future work, we want to scale up BlogVerifier into the fog and edge computing infrastructure.
 Journal of Donghua University(English Edition)2021年5期
Journal of Donghua University(English Edition)2021年5期
- Journal of Donghua University(English Edition)的其它文章
- Axial Compression Properties of 3D Woven Special-Shaped Square Tubular Composites with Basalt Filament Yarns
- Structural Color Modified Fabrics with Excellent Antibacterial Property
- Parametric Effects on Length of Stable Section of Electrospinning Jet
- Preparation and Performance of Fluorescein Isothiocyanate-Labeled Fluorescent Starch and Polyvinyl Alcohol for Warp Sizing
- Effects of Magnolia denudata Leaf Litter on Growth and Photosynthesis of Microcystis aeruginosa
- Order Allocation in Industrial Internet Platform for Textile and Clothing