
面向设备质量提升的电力设备缺陷大数据分析研究
2021-11-02 11:53王卫斌陆嘉铭周韡烨屈志坚姚嵘瞿海妮
电力大数据 2021年6期
关键词:信息
王卫斌,陆嘉铭,周韡烨,屈志坚,姚嵘,瞿海妮
(1.国网上海公司电力公司,上海 200120;2.上海欣能信息科技发展有限公司,上海 200025)
“十三五”期间,电网企业信息化建设取得了长足发展,随着企业级数据中台的建成上线,电力档案、量测、拓扑、业务等各类型数据在同一个信息系统内实现了汇聚,为应用大数据技术开展面向设备质量提升的电力设备缺陷大数据分析提供了有利条件。依靠传统的数据库查询检索机制提取数据信息,运算效率低、专业性要求高、呈现形式单调,无法满足交互查询、下钻分析、趋势预测、重点呈现等生产管理的实际需求。目前,迫切地需要研究一种有效、可行的方法,实现自动、智能、高效、准确地将海量的电力大数据转化为有价值的信息[1-9]。
近年来,大数据技术在国内外电力研究领域也得到了许多关注与成果。文献[10]通过密度峰值聚类算法研究了电力大数据异常值检,分析了密度峰值聚类算法聚类过程。文献[11]基于改进增广节点方程,提出了柔性互联配电网统一潮流的计算方法。文献[12]对现有流数据聚类算法CluStream提出改进,提出流式K-means聚类算法,并将改进的算法应用于用户用电异常检测。文献[13]基于邻域关系矩阵,实现电力大数据增量式属性约简模式分析。文献[14]提出了一种考虑本位元胞接受能力和相邻元胞负荷影响的空间负荷预测方法。文献[15]基于稳态波形分解与神经网络,提出了负荷识别方法。
本文在综合调研了生产管理需求与数据中台软硬件支撑条件后,创新地提出了综合应用多维数据透视、时间序列模型、自然语言识别等方法开展面向设备质量提升的电力设备缺陷大数据分析,并结合实际项目从数据准备、数据挖掘、场景可视化、信息解读等多个方面验证了该方法的可行性与有效性。
1 设备缺陷分析数据准备
设备缺陷数据融合,涉及不同信息系统的不能功能模块,不但数据源头众多、数据类型众多,更需要业务专家参与梳理并制定融合规则,高质量的数据是确保分析准确性的关键和前提。具体步骤:业务模型构建,应用设备主数据和业务流程数据反应设备状态和业务流程;数据溯源,深入分析业务模型所需数据的源系统、源表和相关字段等;数据采集,根据业务需求按一定频度,自动抽取或查询相关数据;数据匹配,将分散在不同系统不同功能模块中的设备主数据和业务流程数据贯通;统一数据格式,将不同系统内的同类数据转化为统一的格式;业务判据制定,对设备主数据和业务流程数据设定合理性判断标准,以校验数据融合的准确性。
设备缺陷数据清洗,在实际生产过程中,采集到的设备主数据和业务流程数据往往是不完整、有噪声和不一致的。因此,首先查找主数据中设备档案参数为空、为异常的值,业务流程数据中缺陷性质为空、为异常的值、时间字段不在查询范围内等各类问题的数据项,进一步对缺失、异常数据项进行插值补充替代、拟合替代等清洗转换,为后续工作夯实基础。
设备缺陷数据预处理,设备缺陷数据经过清洗转换后,在数据中台分析域内进一步生成各类数据中间表,用以描述或分析设备主数据和业务流程数据,经过数据预处理可以满足业务监测、状态评估、预测分析和场景可视化展示等应用的需要。
本文选取某地市公司100台35kV及以上主变压器、1000台10kV及以上断路器在2016年-2020年的设备主数据和缺陷管理业务流程数据。样本数据主要来源于市公司数据中台中集成的ERP系统、PMS系统、OMS系统、EMS系统、GIS系统和用电采集系统中的共享数据。首先,通过规定统一的数据格式和业务判据,实现多源异构数的初步融合。其次,通过缺失数据插值补充替代、异常数据拟合替代等操作后,基本消除数据的不完整和噪声毛刺。最后,根据设备质量提升应用场景的需求,生成设备基础档案、设备运行数据、设备空间拓扑、设备缺陷记录、检修运维成本等数据中间表。为下一步的数据分析挖掘做好充分的准备工作。
2 数据分析挖掘方法
2.1 多维数据透视法
在企业级数据中台,应用开源可视化组件库和数据透视设计器METABASE,将筛选、排序和分类汇总等操作依次完成,实现可自定义地搭建多维数据透视业务场景。多维数据透视功能既能对数值数据进行分类汇总、按分类和子分类对数据进行汇总,又可以快速、交互式地汇总大量数据。
本文对某地市公司的主变压器和断路器开展了多维数据透视分析,实现了横向分析、纵向分析、成分分析、穿透查询等功能,可以满足不同层级、不同岗位人员在进行决策、管理、生产、支撑保障等工作时的需要。多维数据透视还可以深入关联分析数值数据,收获一些预先未曾设想到的成果。
2.2 时间序列挖掘法
时间序列分析的特点在于:可以逐次地观测不独立的观测对象,并且分析观测对象发生的时间顺序,通过曲线拟合和参数估计来建立数学模型[16-17]。当被观测对象相关时,未来的数值可以由过去观测资料来实现预测,同时,也可利用观测数据之间的自相关性建立相应的数学模型来描述客观现象的动态特征[18-20]。正因为时间序列分析的特点比较符合设备缺陷具有趋势性发生、季节性波动、受随机事件波动的规律,所以利用时间序列模型来分析设备缺陷具有较好的分析和预测效果。
本文根据设备缺陷记录信息带有时间戳的特点,生成设备缺陷时间序列表,并采用时间序列算法进行模型训练,以获取设备缺陷在近几年的发生趋势,各个季节的季节性趋势以及受随机事件影响的波动性趋势,并对未来几个月的发生趋势进行拟合预测分析。
2.3 自然语言识别
自然语言识别处理(NLP)中有一块很重要的部分就是文本挖掘,是文本自然语言的一种展现形式,也是目前海量数据的主流展现方式。现在Google和百度也会采用主流的分词算法TF-IDF进行文本关键信息提取[21-23]。
TF-IDF算法的表达式为:
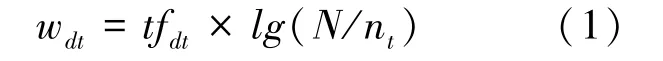
其中,wdt为特征项t在文本d中所占的权重,tfdt为特征项t在文本d中出现的频率,lg是以10为底的对数,N为全量文本信息中的总数,nt为文本语料库中包含特征项t的文本数[24-25]。
本文对于设备缺陷文本类信息的提取,主要步骤包括对原始填写记录的文字切分、关键信息提取和词云展示。首先,应用Python软件Jieba分词包进行文本分词,将缺陷描述的文本信息按词性切割成名词、介词、形容词、动词等常见词组,根据导入的电力专业常用词库进行关键词切分。然后,再使用TF-IDF算法对主变压器,断路器的缺陷文本关键词进行权重计算,并提取出设备类型、故障原因、故障部位、设备型号、介质材质、所属电站、生产厂家等关键字。最后,应用Python软件词云功能包wordcloud对TF-IDF算法提取出的关键字进行自适应的可视化处理,实现设备缺陷文本关键信息的快捷可视化展示[26-28]。
3 应用案例
3.1 设备缺陷多维透视分析
3.1.1 主变压器缺陷多维分析
以某市公司2016年-2020年35kV以上主变压器缺陷数据分析为例,通过对设备缺陷数据按设备生产厂家进行分类汇总,可以发现缺陷数量排前5的生产厂家分别是A公司(17.82%),B公司(14.60%),C公司(11.79%),D公司(11.67%),E公司(9.63%),五者合计占比达65.51%,如图1所示。
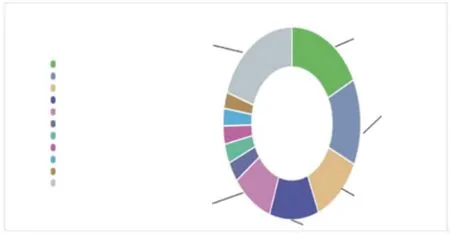
图1 主变压器缺陷厂家分布Fig.1 Distribution of main transformer defect manufacturers
再以A、B两家生产厂家为研究对象,对缺陷原因子类进行分类汇总,进一步下钻分析缺陷现象及相关原因,如图2所示。通过充分挖掘电力数据中蕴含的信息,可以针对性地指导生产厂家做好工艺质量、设计选材等方面的提升。

图2 A公司主变压器缺陷情况Fig.2 Defects of main transformer of Company A
关联分析两家厂家的主变缺陷数据,发现在2016年-2020年,A公司主变缺陷与设备比为1.46∶1,其中漏油和锈蚀相关缺陷达到60%,B公司主变缺陷与设备比为1.008∶1,主要缺陷为漏油渗油、锈蚀、污秽等缺陷,比例达66%,总体上看B公司设备表现优于A公司。
3.1.2 断路器缺陷多维分析
以某市公司2016年-2020年10kV及以上断路器为例,通过对设备缺陷数据按设备生产厂家进行分类汇总,可以发现缺陷数量排前5的分别为A公司(17.58%),B公司(15.1%),C公司(9.68%),D公司(7.41%),E公司(4.11%),五者合计(53.88%),如图3所示。
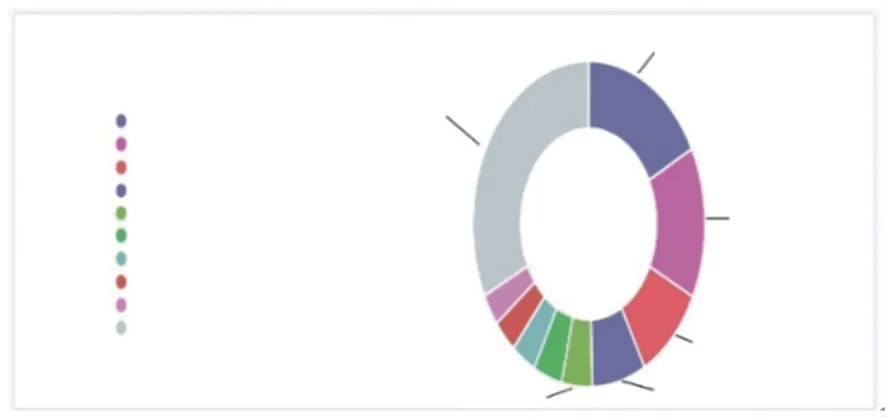
图3 断路器厂家缺陷情况Fig.3 Defects of circuit breaker manufacturers
再以A、B两家生产厂家为研究对象,对缺陷原因子类进行分类汇总,进一步下钻分析缺陷现象及相关原因,如图4所示,应用大数据技术有效发现设备零件短板,促进设备质量提升。
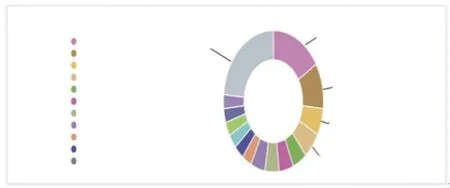
图4 A公司断路器缺陷情况Fig.4 Defects of circuit breaker in company A
关联分析2016年-2020年两家厂家的断路器缺陷数据,可以发现:A公司发生断路器危急严重缺陷66次,主要缺陷为各种原因导致开关无法合闸(开关变形、倾斜、卡死、拒分拒合等,占比28%)、指示器计数器异常(失灵、不正确、偏位或不清等,占比22%);B公司发生断路器危急严重缺陷52次,其中指示器计数器异常占比超过30%,无法合闸与机构箱老化进水问题分别占比为15%与10%,老化进水问题占比相较其他公司占比较高。以上问题均已反馈厂家,要求其做好产品质量的提升整改。
3.2 设备时间序列趋势分析
本文对2016年-2020年某市公司主变、断路器缺陷数据应用时间序列模型开展了分析挖,及时掌握设备缺陷数据的变化规律,并对设备缺陷发生开展预测分析,为有针对性地制定设备检修计划、提供设备质量提供参考依据。主要处理步骤包括:平稳性检验、自相关-偏相关系检查、历史数据分解分析、模型参数调整和模型预测。
(1)平稳性检验
应用Python软件statsmodels分析包,对主变、断路器缺陷数量按时间序列开展平稳性检验,关系如图5所示,从样本数据时序图可以明显地看出,它具有长期趋势成分和年周期变化成分,所以可认为是非平稳的序列。
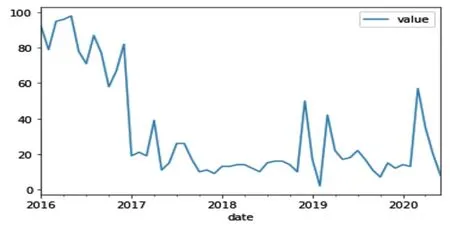
图5 缺陷时序数据示意图Fig.5 Schematic diagram of defect timing data
(2)自相关-偏相关系检查
基于statsmodels分析包,对样本数据建立自相关-偏相关系数图,通过观察图6可以发现,样本数据缺陷数量的自相关-偏相关系序列具有快速衰减的特性,显示该序列为非纯随机序列,即是该序列包含着相关信息,序列的历史信息对未来趋势有影响,因此具有非常高的研究价值。
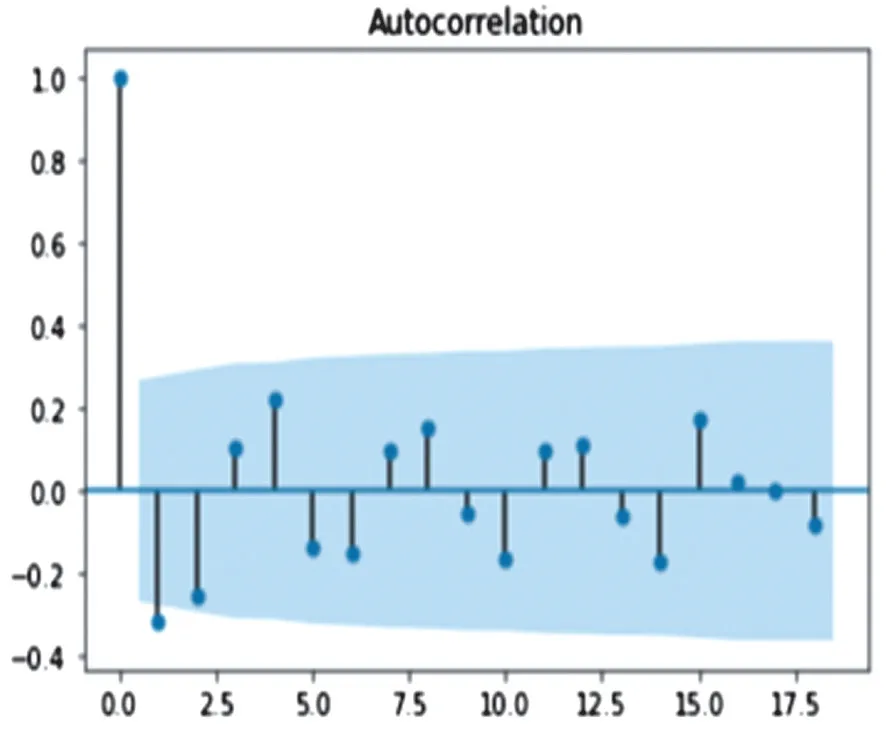
图6 自相关-偏相关系数示意图Fig.6 Schematic diagram of autocorrelation-partial correlation coefficient
(3)历史数据分解分析
所谓历史数据分解分析就是将时序数据分离成不同的成分。使用python软件,调用statsmodels分析包,应用seasonal_decompose模型算法,将一组连续的时间序列数据分解成长期趋势、季节趋势和随机成分,三者关系为:时序数据=长期趋势+季节趋势+随机成分,图7为样本数据的周期性分解情况。
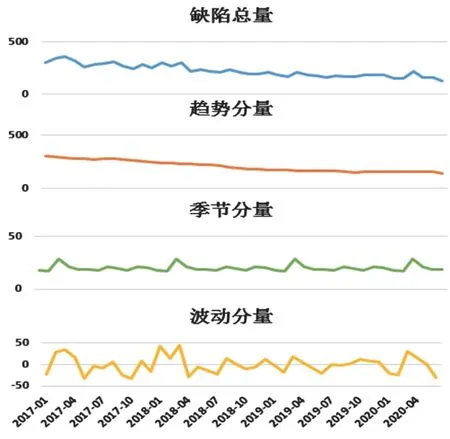
图7 周期性分解示意图Fig.7 Schematic diagram of periodic decomposition
(4)模型参数调整
为进一步提高时间序列模型对历史数据的拟合准确度、对未来预测的准确,依据BIC准则,校验该模型的p,q值,通常认为BIC值越小的模型相对更优。BIC准则,它综合考虑了残差大小和自变量的个数,残差越小BIC值越小,自变量个数越多BIC值越大。本课题在实践过程中,经比较选择p=0,q=1为最理想阶数。
(5)模型预测
对分解出来的趋势部分单独调用statsmodels分析包内的Arima模型做训练,预测出趋势数据后,加上周期数据即作为最终的预测结果,误差高低区间的设定来自刚刚分解出来的残差residual数据,然后对2020年后续数据进行预测,图8所示。经实际验证,2021年1月某市公司的设备缺陷预测值为57,实际值为59,偏差率3.39%,在合理范围内。
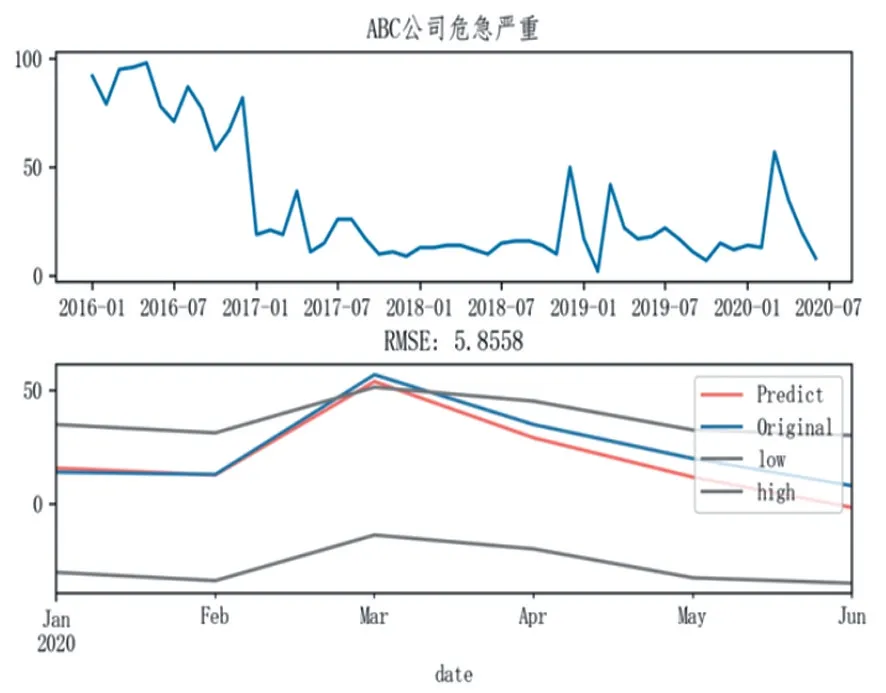
图8 时序数据预测示意图Fig.8 Schematic diagram of time series data prediction
3.3 自然语言识别
在实际生产活动过程中,输变电设备缺陷描述信息通常是由现场人员根据实地观察、经验判断后用通俗易懂的文字对各种现象进行描述记录的,由于用词习惯、句子组织结构的差异,传统数据计算方式无法快速提取重点信息。同时,在文本信息数量持续不断增长的情况下,人工阅读文字获取信息的效率低,还会发生信息提取不够精准、信息遗漏等问题。
本文应用了NLP自然语言识别技术,对2016年-2020年某地市公司主变、断路器缺陷记录内的文本描述信息开展挖掘分析,结合文本信息提取与可视化技术将大量文本中的复杂文字内容和规律用视觉符号表达出来,使人们能够快速获取到文本中蕴含的关键信息。
自然语言识别主要步骤包括:构建设备缺陷信息字典、创建中文停词词典、创建词模型矩阵、提取关键词信息、词云可视化展示,如图9所示。
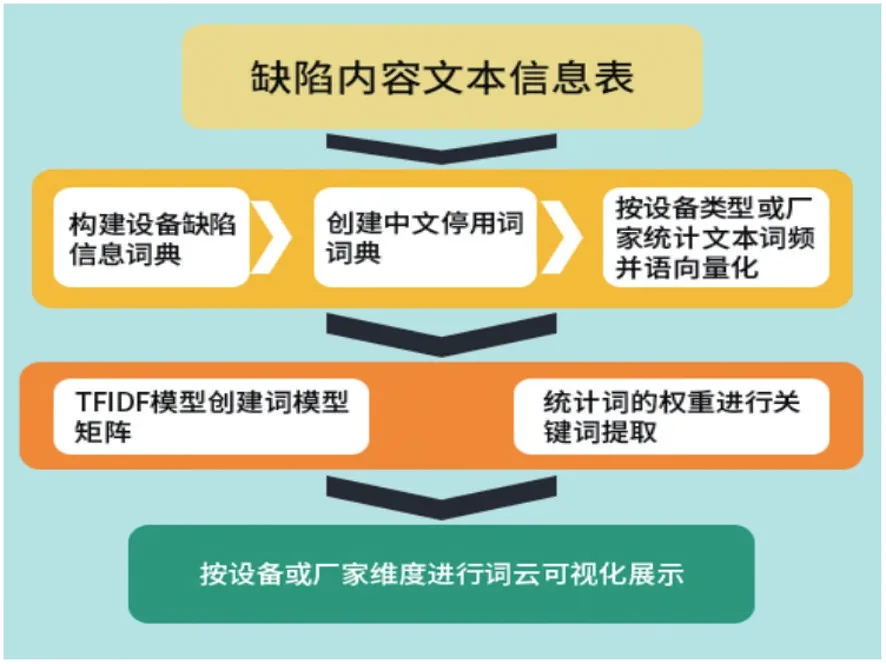
图9 设备缺陷文本分析示意图Fig.9 Schematic diagram of text analysis of device defects
(1)构建设备缺陷信息字典
根据设备主数据信息,构建设备缺陷信息词典,包括电站名称、设备回路名称、缺陷分类、零部件、厂家名称、型号等专业词汇,使软件可以自动识别并提取。
(2)创建中文停词词典
根据实践情况,在Jieba分词包中,补充创建设备缺陷描述中文停用词词典,去除各地区的常用停用词(虚拟词,语气助词,副词,符号,一个字的词……)。
(3)创建词模型矩阵
使用Python软件,调用sklearn中tf-idf算法将文本中的词语转换为词频矩阵,计算词频大于2的词语相似度,相似度高的词语可以在上下文中替换并合并统计结果,替换原始矩阵后文本预处理完成。
(4)提取关键词信息
通过TfidfTransformer类中fit_transform()方法统计每个词语的tf-idf权值,进行关键词提取。
(5)词云可视化展示
对设备缺陷关键词按频度统计分析,并通过词云可视化技术进行展示。
图10是通过对主变故障文本记录进行分词处理、词频统计、布局设计和实现后得到的关键词云,反映主变故障主要围绕“储油柜”,“冷却器”,“呼吸器”这些关键词,应对相关的设备零件加强监测。采用这种手段在信息获取效率和准确度方面具有明显优势,是一种十分简洁、直观又有效的非结构性文本数据的挖掘方法。

图10 设备缺陷信息词云展示图Fig.10 Display diagram of word cloud of device defect information
4 结语
通过对电力设备缺陷进行大数据分析研究,本文研究的数据分析方法在实际应用中具有以下实际意义:
(1)电网公司基于设备缺陷数据融合与挖掘技术,对各类设备档案数据、业务数据、非结构化数据进行整合并提取有价值的信息,助力设备缺陷的精准高效管理,促进设备质量提升,夯实电网本质安全基础。
(2)应用METABASE数据开源透视图工具,从多个维度综合分析电网内主变、断路器等主设备的运行状况,对开关拒动、主变漏油等危急严重缺陷的有效跟踪监测,客观提示主要设备的问题短板,反馈给设备厂家,精准指导设备质量持续改进,有效消除各类电网安全隐患。
(3)创新应用时间序列算法,从长趋势、周期趋势、随机因素三个维度分析了设备缺陷发生的规律,初步实现了对设备缺陷情况的预测,有针对性地加强了设备质量管理。
(4)基于自然语言识别技术,从海量非结构化数据中提取出与设备缺陷高度相关的文本信息,大幅度提升了文本数据的利用效率。
本文详细介绍了基于多维数据透视、时间序列模型、自然语言识别分析等3种大数据分析方法,并结合工作实践开展了面向设备质量提升的电力设备缺陷大数据分析研究,为广大读者在实际生产中处理相关问题提供了参考。
猜你喜欢
中华手工(2017年2期)2017-06-06
中外会展(2014年4期)2014-11-27
大众创业(2009年10期)2009-10-08
数字社区&智能家居(2009年7期)2009-09-29
数字社区&智能家居(2009年11期)2009-06-25
数字社区&智能家居(2009年3期)2009-04-21
数字社区&智能家居(2009年2期)2009-03-27
数字社区&智能家居(2009年12期)2009-02-03
建筑创作(2001年3期)2001-08-22
祝您健康(1987年3期)1987-12-30
