
基于Surfacelet变换和运动估计的自适应教学视频压缩
2021-10-31 01:37马宏茹李硕
大连交通大学学报 2021年5期
马宏茹,李硕
(大连交通大学 信息学院,辽宁 大连 116028)*
近年来,随着教学信息化的发展,移动终端技术、网络传播技术以及视频分享网站得到发展和普及,微课和MOOC(Massive Open Online Course)已经作为一种新兴教学模式,在短时间内被广泛地应用到日常教学中[1-2].而教学信息化发展不仅带来了学生学习模式的颠覆,教师的信息技术能力也受到了严峻的考验,因此教师信息化的培训十分重要[3].非信息技术专业教师对于文字教程的理解费力耗时,并且学习与交互过程分离的培训效果不理想.由于信息量大、观赏性好等特征,视频作为教学工具的效果要优于静态文字,以屏幕录制为基础的培训视频能实时地展示操作过程,在软件工具培训课程中效果显著[4].在视频编码中,传统的编码标准例如H.261/H.263,MPEG1,MPEG2,MPEG4都是采用帧内DCT变换与运动估计、运动补偿相结合的编码方法.但是基于分块DCT变换编码在解锁高压缩比情况下分块效应明显,而小波变换能够更好地捕捉视频帧图像的非平稳信息,因此,基于小波变换的视频压缩方法能够获得更高的压缩比[5-6].虽然小波变换在边缘处间断点能够有很好地识别,但对轮廓曲线的平滑度刻画能力不足.Do 和 Vetterli 于2002年提出了Contourlet变换,比小波变换具有更好的方向性,Eslamihe 和 Bellbachir等将其应用于压缩编码领域[7].Yue Lu 和 M NDo 于2007年提出了基于Surfacelet变换的三维变换,能够对三维或更高维信号进行多尺度方向分解,捕捉信号的面状奇异.文献[8-9]中对Surfacelet变换、Contourlet变换、NSCT变换以及3D小波变换之后的图像信息熵进行比较,结果证明Surfacelet变换能够使图像系数的能量更加的集中.
视频中的物体具有运动相关性,若逐帧进行变换域编码会出现帧间颤抖,影响视频质量,为解决这一问题,现有的视频编码技术利用运动估计和补偿来消除帧间相关性.文献[10]采用了将视频帧按顺序等分成视频帧组,在组间采用扩展自适应范围搜索快速算法进行估计,能够根据视频的运动特性,自适应的确定搜索范围.不过计算机屏幕视频帧图像是由各种不同类型的内容组成,现有的视频方法大多针对自然视频,没有考虑内容的不连续性[11-12].因此,本文提出了一种基于Surfacelet变换和运动估计的自适应视频压缩方法,在充分考虑视频的稀疏特性同时,采用根据内容特点进行自适应视频帧组分组的方法,再结合现有的运动估计方法进行压缩.针对不同类型的教育视频(微课、MOOC视频、屏幕视频)的仿真实验表明,本文提出的压缩算法在保证较高压缩比的情况下具有更好的视觉还原效果.
1 Surfacelet变换
Surfacelet变换能够准确地捕获三维信号中的奇异面,是一种很好的时频分析工具,与小波变换类似,其变换子带系数能量集中,子带间存在一定的相关性.由于多维方向滤波器组可以对任意维度信号分解,迭代滤波器组可以获得高效的树状结构,因此N维的多方向滤波器组只有N倍的低冗余度[13].
1.1 三维方向滤波器组
1992年,Bamberger和 Smith 提出了方向滤波器组(DFB,Directional Filter Banks),然而无论是DFB还是Contourlet变换都只能处理二维信号.Yue Lu 和M.N.Do 为了处理高维信号,在2007年提出了多维方向滤波器组(NDBF,N-dimensional Directional Filter Banks),不仅能够处理三维信号,甚至可以应用到更多维.我们对三维情况下的NDFB,即3D-DFB进行分析,结构如图1所示.
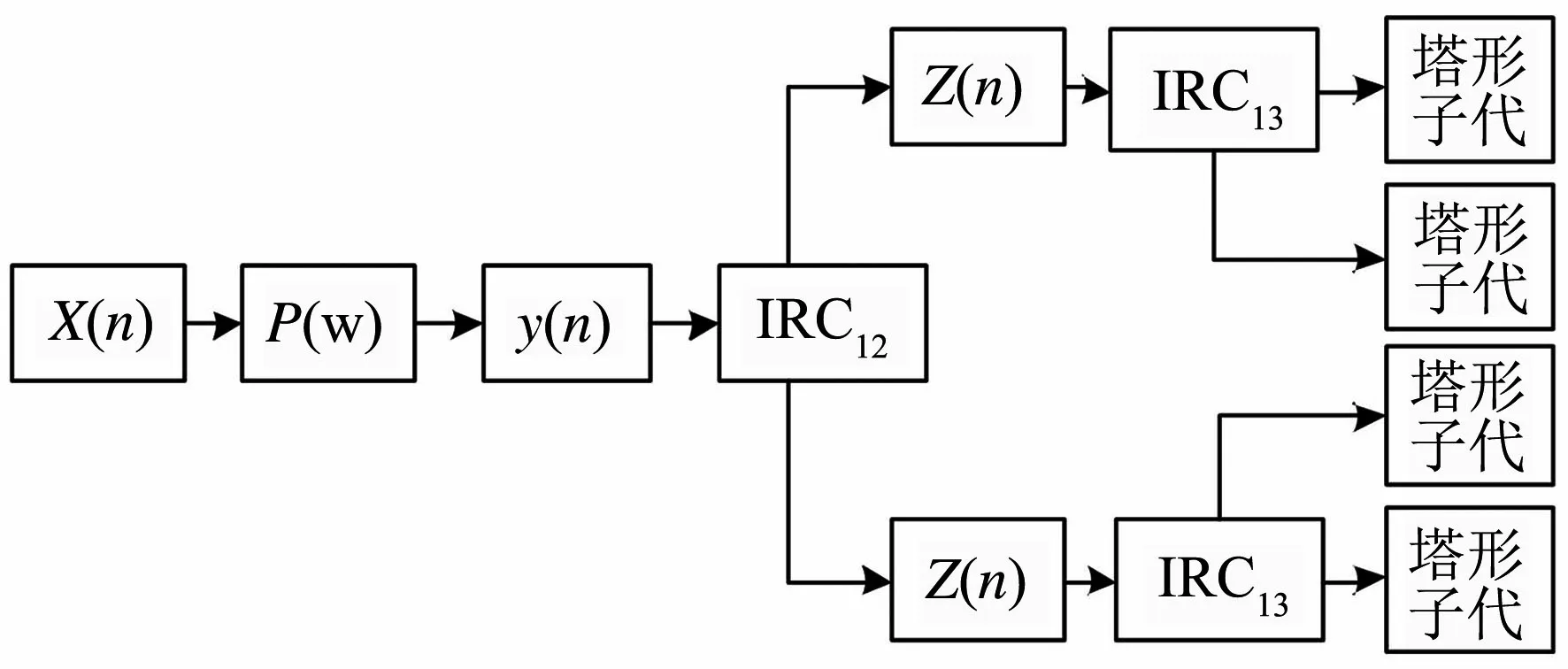
图1 3D-DFB结构图
其中,X(n)为具有n1,n2,n3三个维度的输入信号,P(w)为三维沙漏滤波器,y(n),Z(n)表示同样具有n1,n2,n3三个维度的输出信号,IRCl2为二维方向滤波器组.
视频序列经过三维滤波器P(w)得到输出y(n),然后对n1,n2进行二维DFB分解,通过IRCl2获得视频序列的楔形子带输出Z(n).再对Z(n)基于n1,n3平面进行二维DFB分解,同样获得视频信号的楔形子带.将以上两个楔形子带重合,就构造了一个沿着n1轴方向的3D-DFB.沿n2,n3轴方向的塔形子带用同样的方式获得.
1.2 多尺度分解
Surfacelet变换架构如图2所示.Surfacelet变换分解采用多尺度塔式结构实现,Di(w),Li(w)分别表示高通滤波器与低通滤波器,其中i=0,1.为了抑制由于进行了上采样而产生的频域混叠问题,多尺度塔形结构使用抗混叠滤波器S(w),只保留NDFB中S(w)部分的响应,也对各个维度的一级Li(w)进行1.5倍下采样(2倍上采样后再进行3倍下采样).对虚线框部分进行N次迭代能达到更多级尺度分解的效果,使得Surfacelet变换在时域和频域都有更好的细分效果.
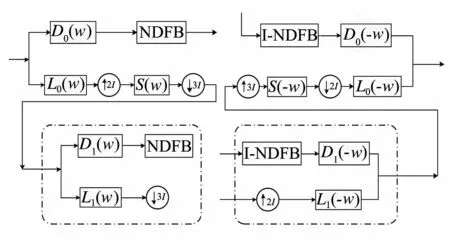
图2 Surfacelet变换结构图

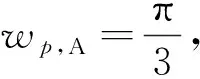
滤波器的设置过程中,为了确保能够完全去除频域混叠问题,严格的控制截止频率响应,对应的完美的多尺度金字塔形状结构合成部分可以简化为:
因此Li(w)确定后即可获得对应的Di(w),进行信号重建.
2 基于Surfacelet域的自适应运动估计算法
视频帧之间存在着信息冗余,通过运动估计技术来去除帧间冗余,其估计的效果与编码的质量和效率有着直接的联系[15].不过运动估计技术在基于多尺度变换域的视频编码中的应用存在着一些问题,多尺度变换的高频子带由于经过了下采样和平移操作,所以当前帧与参考帧之间的高频子带一般不能通过运动估计获得.为了克服这样的局限,P.Cheng等人提出了一种基于下层低频子带的分层运动估计方法,有效地避免了下采样操作和平移操作带来的问题,还确保了获得的运动矢量的精度.其方案的主要思想是:先对最低频子带进行运动估计,在参考预估计层的下一层低频子带运动估计获得相应的预测低频子带,再对其进行一级小波分解,即可获得三个高频子带的预测信息,迭代上述步骤,就可得到所有的高频预测子带.
2.1 自适应视频帧组选取
传统的运动估计方法是将视频帧按照编码的顺序,等分成视频帧组(Group of Pictures,GOP),按组进行编码.不过针对教学视频中的屏幕教学视频,帧之间的时域相关性与自然视频中的运动相关性不同,若依旧按照等分的标准分组,会造成预测帧的估计不准确,影响视频质量.因此,本文根据视频帧之间的相关性,自适应的对视频帧分组,确保同一帧组内的视频帧运动相关性一致.
首先对每帧的空域像素值求差值Dt(x,y)并排序,选取Di(x,y)序列的中位数作为判断阈值T,并将差值大于这一阈值的两帧的后帧与视频第一帧作为视频帧组的关键帧F,其他帧作为非关键帧.
Dt(x,y)=ft(x,y)-ft-1(x,y)
T=Me(Di(x,y))
其中,Di(x,y)为排序后的差值序列,F1为视频第一帧,Fi为满足阈值要求的后帧.
2.2 运动估计与补偿
文献[15]中已经证明,高频子带对位移的变化敏感,因此低频子带与高频子带对位移产生的影响不同,通过低频子带间接的估计高频子带比直接对高频子带进行运动估计具有很好的实验效果.因此,本文采用同样的方式,对视频帧的Surfacelet域子带进行估计.首先通过全搜索方法对当前帧与参考帧的Surfacelet域低频子带进行估计,获得运动向量,通过运动向量计算得到预测帧运动补偿的低频子带;对当前帧进行逆Surfacelet变换,并将之前获得的运动向量作为整帧的运动向量,对预测帧进行预测,将预测结果进行Surfacelet分解,得到运动补偿的高频子带.
3 视频压缩算法过程
本文提出了基于Surfacelet变换结合运动估计的自适应教学视频压缩算法.由于视频帧在帧内与帧之间都存在相关性,所以将视频信号作为三维信号的一种来进行处理,利用Surfacelet变换对视频信号的时域和空域信息做整理.相比一般视频,教学视频具有场景单一、画面质量清晰度高、课件图像中存在大量文字等特性,且教学视频在连续域有明确的方向性,因此需要在变换域下更多地关注多方向性和各向异性,而Surfacelet变换在捕捉视频帧的方向性和奇异性方面具有潜在能力.充分考虑了两种教学视频与一般视频的不同,采用自适应分组运动估计来对视频进行估计和补偿,保证视频还原效果.基于Surfacelet变换结合运动估计的自适应教学视频压缩算法的基本框架如图3所示.
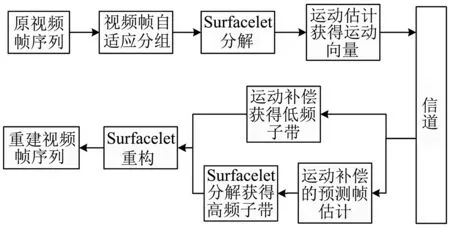
图3 算法流程图
视频序列作为算法的输入,由于考虑到不同类型视频的自身特点,首先进行自适应分组操作,将视频序列分成不等分的视频帧组.把每组的视频帧序列作为一个三维信号,进行Surfacelet变换,获得不同子带的Surfacelet变换系数,不同子带具有不同的特性,低频子带包含大多数的能量,系数幅值较大,而且对位移变化敏感,高频子带系数幅值小,能量较低,对位移变化不敏感.
通过对低频子带进行运动估计,获得运动向量并补偿得到预测帧的低频子带,再将得到的运动向量作为帧间的运动向量得到一个估计的参考帧,并对其进行Surfacelet分解,获得其高频子带,至此预测帧的低频子带与高频子带全部得到,逆变换求得预测帧.迭代此步骤直至所有视频帧序列处理完毕.
4 实验结果分析
为了验证本文提出的压缩算法具有很好的视频还原效果,分别取两种类型的教学视频的30帧进行实验,并将通过本文方法获得预测帧PSNR实验结果与通过文献[14]与文献[15]提出方法获得的预测帧PSNR实验结果进行对比.
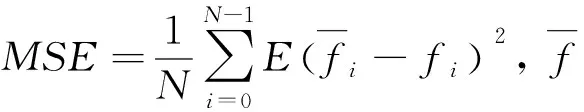
本次实验的仿真环境在Matlab 2009a中进行,实验的视频素材为class和screan.其中class为摄像机录制的公务员培训网课,screan为慕课网上屏幕录制的计算机考研培训课程.通过自适应视频帧组选取结果,视频class的关键帧为视频序列的第1,14,23帧,视频screan的关键帧为视频的第1,5,16,21,27帧,分别取前三个关键帧的下一帧进行实验,首先在压缩比相同的情况下,两种方法处理两种视频的结果如下,表1,表2分别为序列预测帧的PSNR和预测结果.

表1 视频序列class和screan的PSNR对比

表2 视频序列class和screan的预测帧对比
通过上述数据和预测结果的对比可以发现,文献[14]的方法针对摄像机获得的教学视频进行压缩后,能够获得良好的复原效果,不过对于运动比较剧烈的屏幕视频帧的还原效果一般;本文提出的方法无论对摄像机录制的视频序列还是对屏幕软件录制的视频序列的还原效果都好于文献[14]与文献[15]所提出的方法.
5 结论
通过上述分析了解到由于教学视频中,录像教学视频与屏幕录制视频的差异性,针对某一类的视频压缩算法由于忽略了另一类视频的自身特性,在进行视频压缩处理的时候效果往往不是很理想.本文充分的考虑了视频帧空域的冗余性、不同类型教学视频的自身相关特性,结合多尺度变换和运动估计技术,提出了一种基于Surfacelet变换和运动估计的自适应教学视频压缩方法.实验结果证明,对于录像教学视频以及屏幕录制教学视频,本文提出的方法对这两类视频都能有很好的还原效果.然而考虑到算法的复杂性,本文在视频帧组选择的阈值选取采用视频帧差的中位数,在以后的研究工作中应致力于更加自适应的选择方法.
猜你喜欢
黄河之声(2022年10期)2022-09-27
客联(2022年4期)2022-07-06
成都信息工程大学学报(2022年2期)2022-06-14
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
好日子(2021年8期)2021-11-04
中华诗词(2018年11期)2018-03-26
Coco薇(2016年8期)2016-10-09
智能计算机与应用(2016年1期)2016-03-02
