
应用模式识别的酒店冷水机组系统节能分析
2021-10-30 02:03谭时锴徐成良陈焕新吴俊峰
制冷技术 2021年4期
谭时锴,徐成良,陈焕新*,吴俊峰
(1-华中科技大学能源与动力工程学院,湖北武汉 430074;2-压缩机技术国家重点实验室(压缩机技术安徽省实验室),安徽合肥 230031)
0 引言
建筑节能是可持续发展的重要战略[1],然而几十年来,我国建筑能源消耗一直保持增长。相关研究显示,2015年全国建筑能耗占全国能源消费总量的20%,2017年全国建筑能耗占所有能耗的27%以上,而且以每年1%的速度在增加[2]。据相关统计,在我国许多大型宾馆、酒店的总能耗中,空调设备用电量占比很大,往往高达总用电负荷的55%~60%[3]。在建筑中央空调系统中,冷水机组的能耗最大[4]。国内外许多学者都对冷水机组系统进行了研究。
陈权等[5]从离心式压缩机工作原理出发,建立了双级离心式压缩机及其冷水机组的稳态灰箱数学模型。赵琳等[6]基于将冷水机组未知的结构参数进行集总并由实测数据获取机组集总的结构参数(即特征参数)的建模方法,建立基于特征参数的冷水机组模型。BROWNE 等[7]基于模型的物理原理及经验方程建立了一种新型的蒸气压缩离心式水冷机组稳态模型,该模型已通过在奥克兰大学运行的3 个不同的从部分负荷到满负荷性能的实验数据进行验证,发现预测结果与真实结果的偏差在±10%之内。JIN 等[8]提出了一种离心式冷水机组的混合模型,该建模方法综合利用物理和经验建模方法,可在较宽的工作范围内实时准确地预测性能,可以显著减少计算负担,提高预测精度。
以上学者的研究,均从制冷系统冷水机组的物理原理出发,对机组能效进行研究。但所建立的模型结构复杂,参数较多且难以确定,较难应用于工程实际。几十年来,数据挖掘技术快速发展。机器学习算法包括支持向量机[10]、神经网络[11]、决策树[12]、贝叶斯算法[13]、Logistic 回归[14]和聚类算法等,广泛应用于工程实际,很多的研究使用数据驱动的方式进行空调系统能耗分析。
周峰等[15]采用支持向量机对建筑进行能耗预测,并对建立的能耗模型进行了优化。周璇等[9]建立了基于支持向量回归机的冷水机组运行能效预测模型,并采用粒子群优化算法对模型参数寻优,提高了模型的精度。结果表明,该模型能准确反映冷水机组的运行能效,为冷水机组运行能效分析、故障诊断以及优化控制等提供参考依据。
严中俊等[16]建立了反向传播(Back Propagation,BP)神经网络的冷水机组能效预测模型,并利用实际运行数据对模型进行了训练及验证,提出了一种可准确预测冷水机组能效的方法,该方法简单实用,具有一定的适用性。NASRUDDIN 等[17]在多种天气条件下,选择干球温度和全球水平辐射作为预测因子,对吸收式制冷机发电机进气口进行了热水温度预测。使用了3种人工神经网络进行预测,包括feedforward BP 神经网络、cascade-forward BP 神经网络和Elman BP 神经网络。MANOHAR 等[18]基于人工神经网络技术建立了以蒸气为热输入的双效吸收式制冷机的稳态建模。
PAPADOPOULOS 等[19]基于模式识别技术,对纽约市建筑能耗进行时间序列的聚类分析,识别出一系列能耗模式。YU 等[20]基于模式识别技术(使用聚类分析),将影响建筑能耗的因素分为居住者因素和非居住者因素,提出了一种新的研究居住者行为对建筑能耗影响的方法。
使用模式识别的方式可以有效建立冷水机组系统的数学模型,可以与冷水机组系统的物理模型相互补充。目前,国内外基于数据挖掘方法对冷水机组的研究主要集中在对冷水机组能耗进行预测,无法给出相关的节能策略。模式识别技术主要用于建筑节能分析领域,较少涉及冷水机组系统的节能运行策略研究。本文将模式识别技术用于某工程项目的冷水机组实际运行数据,提出针对该冷水机组系统的节能策略。
1 研究方法
本文使用了BP 神经网络补全数据中的缺失值。BP 神经网络是有监督学习算法[21],是一种按照误差反向传播训练的多层前向神经网络[22]。包括1 个输入层,1 个输出层以及1 个或多个隐含层。它使用梯度下降算法[23],不断调整参数,使网络的实际输出值和期望输出值的均方差(Mean Square Error,MSE)为最小[24]。
k-Means 是一种原型聚类[25],是本文的主要研究方法。k-Means 要完成k-Means 聚类,必须先确定k的最优数目。本研究使用内部指标确定k数目的指标,主要有轮廓系数(Silhouette Coefficient)、DB(Davies-Boulding)指数、Dunn 指数和CH(Calinski-Harabaz)指数。轮廓系数、Dunn 指数和CH 指数越高,DB 指数越低,说明聚类结果越好。
本文采用熵权法确定了用户行为数据的权重;使用灰色关联分析法,求出各个天气变量与能耗指标的关联系数,然后将系数进行排序,取与能耗指标关联度较大的天气变量,进行后续的分析研究。
2 系统简介
2.1 数据采集
本研究所使用的数据分为两部分。一部分来自南京某酒店冷水机组的实际运行数据,包括数值型数据和状态型数据两部分(这两个数据是每30 s 记录一次)。该建筑的空调系统的冷热源设备是水冷磁悬浮机组,机组系统原理如图1所示。
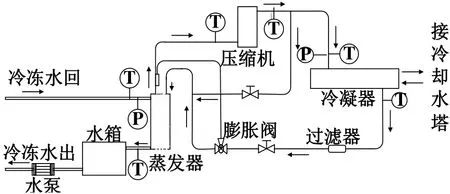
图1 机组系统原理
数据为连续采集和记录,采样周期为30 s,机组布置的传感器都位于机组内部,主要用于检测机组状态,用于实现机组的自动控制和故障自检。传感器主要包括压力传感器、温度传感器、电压变送器和电流变送器。机组主要的采集数据都是设备运行参数,不采集环境温湿度和室内PM2.5浓度等。数值数据是通过传感器读取或者通过传感器读取数据计算转换后的数据参数,为连续数值型数据。状态数据是用于显示设备或者传感器的当前状态,主要显示“是”(在数据中值为1)或者“否”(在数据中值为0)的数据类型。另外一部分数据通过调用R 语言worldmet 程序包,获取距离该建筑最近的机场的天气数据(该数据是每小时记录一次)。
2.2 数据筛选及预处理
将数据分成了两类来进行分析。第一类是和酒店居住者以及管理者(即用户)有关的数据,即用户能直接控制和影响的变量,称之为用户行为数据。第二类是与用户行为无关的数据,即用户的行为无法改变的数据,天气数据属于这一类。
2.2.1 空调系统用户行为数据筛选
系统运行数据的筛选步骤:由于运行数据中有很多变量的数据在整个时间段里面均不变,找到这些变量并剔除。方法是计算所有变量的数据的方差,方差为0 的变量说明是不变的,即为无效值。在留下的变量中选择出可以作为用户行为的变量。
在数值型数据中,选择以下变量:1)制冷时蒸发器侧出水温度设定;2)压缩机#1 和压缩机#2 的转速;3)能耗指标,原始数据中没有直接提供能耗值,但由于能耗指标与蒸发器进出口温度差成正线性相关关系,因此把蒸发器进出口温度差作为系统能耗指标。
图2所示为12 d 里能耗值和1#、2#压缩机开启状态的线图。由图2 可知,变量“1#压机开”具有时间上的周期性,且与能耗值有很强的关联。因此,把变量“1#压机开”加入到用户行为变量中。
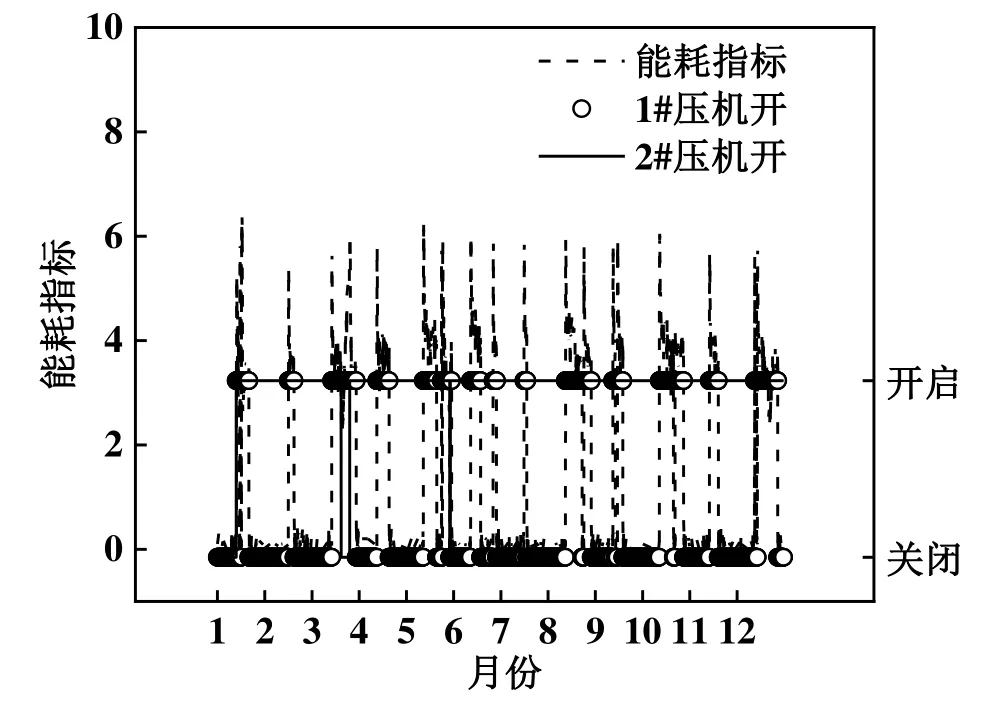
图2 能耗值与机开启状态关系
2.2.2 空调系统能耗值预处理
能耗值的预处理包括以下两方面:1)在能耗值原始数据中,出现了很多小于0 的数据,认为是异常值,将该变量小于0 的数据点的值设为0;2)该数据在12 d 中,有5 次突升突降,均只持续几分钟,而一般能耗值较高的运行状态会持续一个小时以上。9月1日全天的能耗如图3(a)所示,12~13 h出现了两次突升突降的情况,如图3(b)所示。另外有3 次异常,分别在第5 d(1 次)、第12d(2 次),此处不再赘述。
由图3 可知,由于1#压缩机突然开启了一段时间,因此能耗会突增。几分钟后1#压缩机又关闭了,能耗发生突降。原因可能是酒店管理人员的操作失误造成,因此将这5 段数据作为异常值。
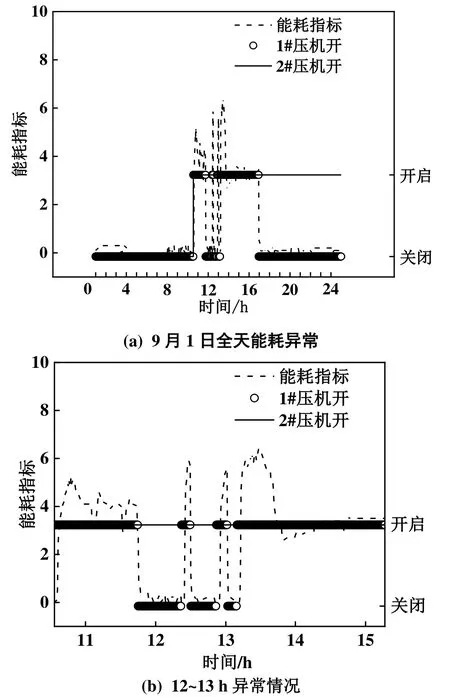
图3 能耗异常
异常能耗的处理方式,首先通过其他正常数据的天气数据和小时数作为训练数据使用BP 神经网络进行预测补全。这里的训练数据是34,491 个数据除去那些异常数据后所剩下的数据,预测变量是天气值和小时数,目标变量是能耗值。训练好BP 神经网络模型后,向模型中输入异常数据对应的预测变量,即可得到能耗值来代替原异常数据的能耗值。选取9月1日出现异常的两处数据,画出其处理前后的能耗值,如图4所示。由图4 可知,异常能耗的预测值大幅下降,较为合理。
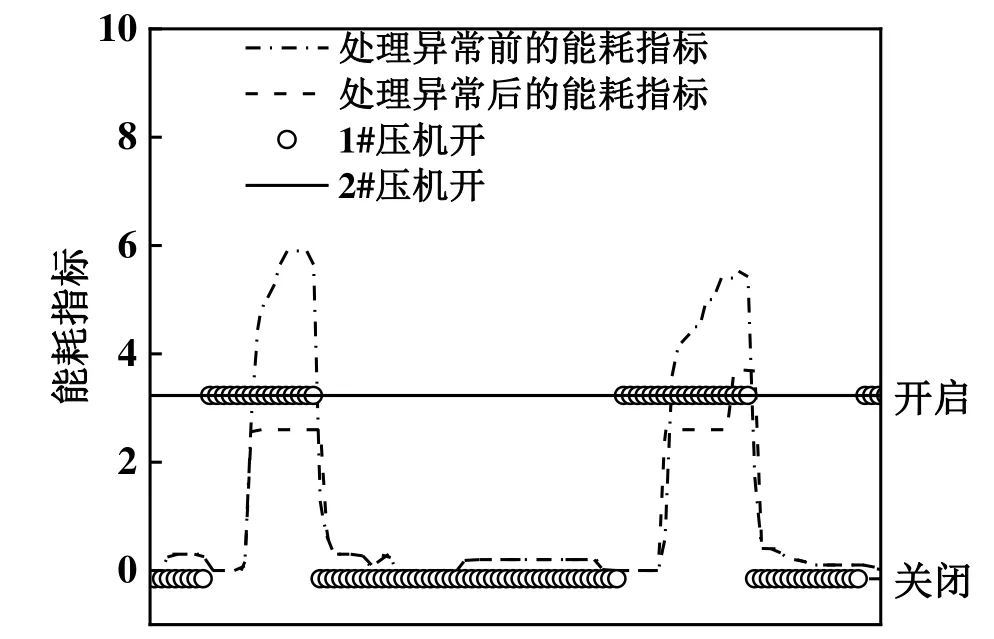
图4 能耗异常值处理结果
同时,这5 段的1#压缩机开启状态从开启改成关闭。因为这5 处异常都是1#压缩机突然开启后再突然关闭引起的,2#压缩机在此期间都是恒定的状态,因此只修改1#压缩机的开启状态。在能耗异常值处理结果图中也可知晓。
2.2.3 天气变量筛选
删除一些变量缺失的样本数过多的变量,使用线性插值补全其它有缺失值的变量。对补全缺失值之后的数据进行灰色关联分析。参考变量为天气数据,比较变量为能耗指标。由于能耗数据由34,491个(每30 s 记录一次),而天气数据只有288 个(每小时记录一次),因此将能耗数据每小时的平均值作为该小时的能耗量。结果见表1,由表可知,风速(ws)、气温(air_temp)、相对湿度(RH)这3 个变量与能耗的关联系数较大,因此,选择这3个变量进行后续的分析。
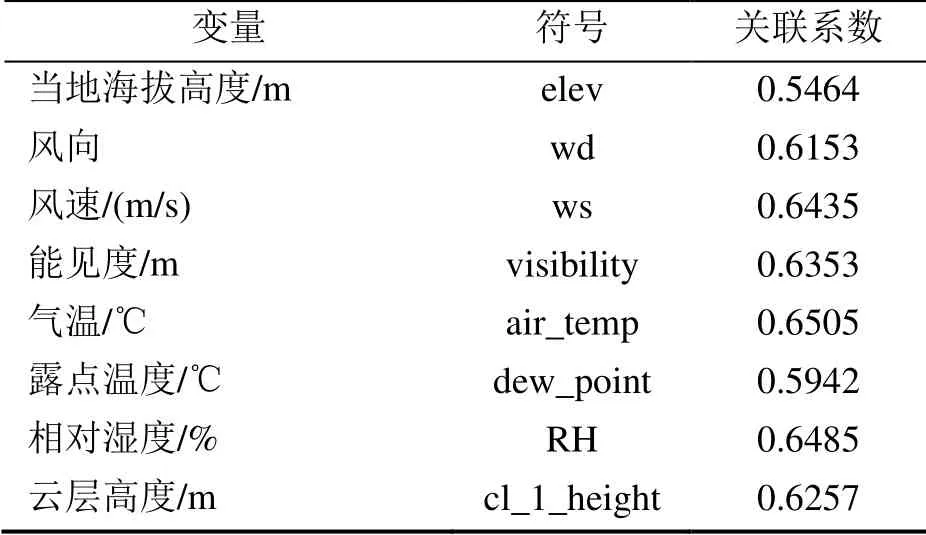
表1 天气数据灰色关联分析结果
3 空调系统数据分析
3.1 对空调系统非用户行为变量进行聚类分析
进行聚类的变量为风速、气温和相对湿度。在聚类前这3 个变量均归一化到[0,1]。尝试不同的类数k∈[2,20]之间,在每一种k的取值下,进行聚类求得4 个内部指标的值,由于平方误差和(Sum Square Error,SSE)、Dunn 指数和CH 指数值较大,为了能和轮廓系数、DB 指数在相近范围内显示,故将其归一化到[0,1]。图5所示为不同聚类数的内部指标。使用开源的 R 语言数学分析程序NbClust[41]。该开源程序提供了众多不同的指标来确定在一个聚类分析的类的最佳数目。它返回每一个聚类指数赞同的聚类数,结果如图6所示。拥有推荐指标数越多说明取该聚类数进行聚类的效果最好。综上所述,指标推荐数最多的聚类数是6,并且,在k=6 时,轮廓系数、Dunn 指数和CH 指数较高,DB 指数较低。故选择k=6 作为聚类数目。表2所示为每个聚类的一些变量的平均值,除了这3 个参与聚类的变量,还包括了每个数据点的6 个用户行为变量,以及每个聚类占有的数据量和相对总数据量的比例。除了数据量和数据量占比,其他的变量都已归一化到[0,1],因此可以忽略单位。该结果可用于挖掘出聚类的一些特征。如在聚类1 中,与其他聚类相比,风速最低、气温较低、相对湿度较高,1 号压缩机的开启状态接近平均水平,有32%的数据点,其1 号压缩机处于开启状态,2 号压缩机的开启状态接近平均水平,有96%的数据点处于开启状态,能耗接近平均值,其占有数据量为9,311个数据。其他聚类的分析与之类似。
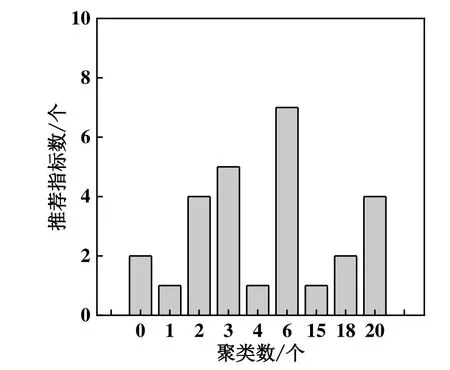
图6 每一种聚类的指标赞同数
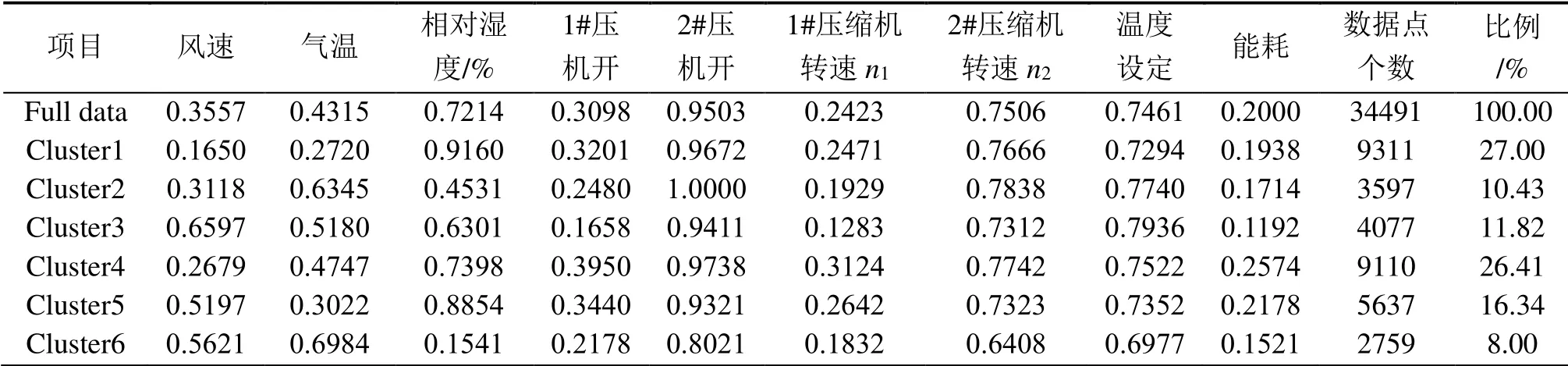
表2 每个聚类中心点的变量值
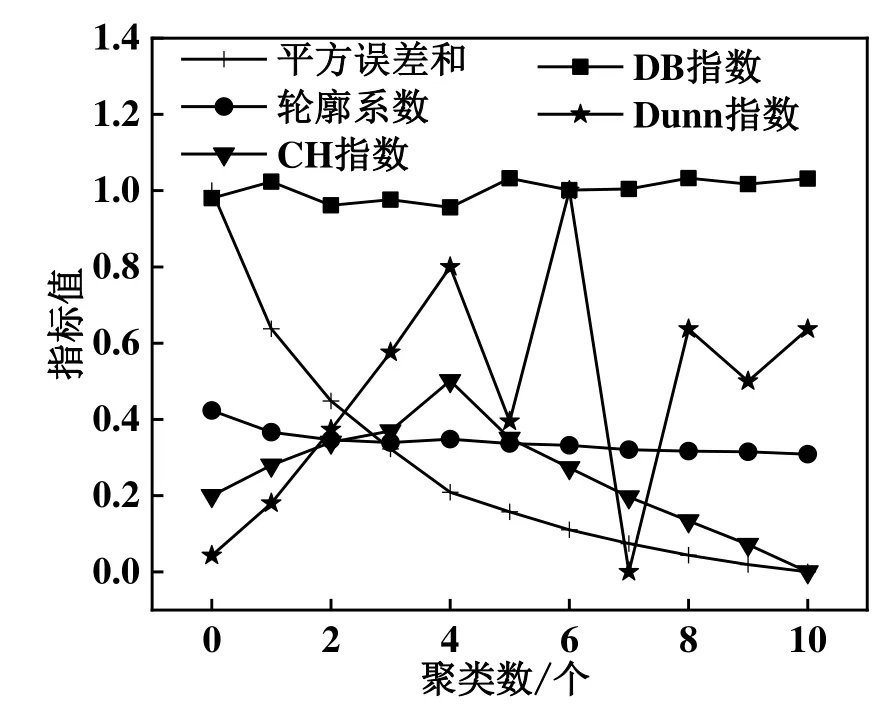
图5 不同聚类数的内部指标
3.2 空调系统变量相关性分析
在完成聚类后,取每个聚类内各个变量的平均值,如表2所示。以每个聚类内各个变量的平均值为数据,计算各个变量间的Pearson 相关性系数,其结果如图9所示。由图9 可知,温度与压缩机的开启状态之间的相关性与风速和相对湿度(RH)的相关性相比要略低一些,说明温度对压缩机开启状态的影响比风速和相对湿度要小,虽然在直观印象中温度的影响最大。此外,温度设定与天气以及能耗的相关性系数很低,说明酒店的用户很少随天气变化而调整制冷系统温度的设定。因此,用户应该随天气变化适当调整温度设定,使系统更加节能。能耗与1#压缩机开启状态之间的相关性系数是0.99,而与2#压缩机开启状态之间的相关性系数是0.36,说明能耗主要是由1#压缩机的开启状态所影响的。因此相对于2#压缩机,要更多考虑1#压缩机的运行策略的节能措施,比如寻找更优的系统运行控制策略,合理安排1#压缩机的运行。
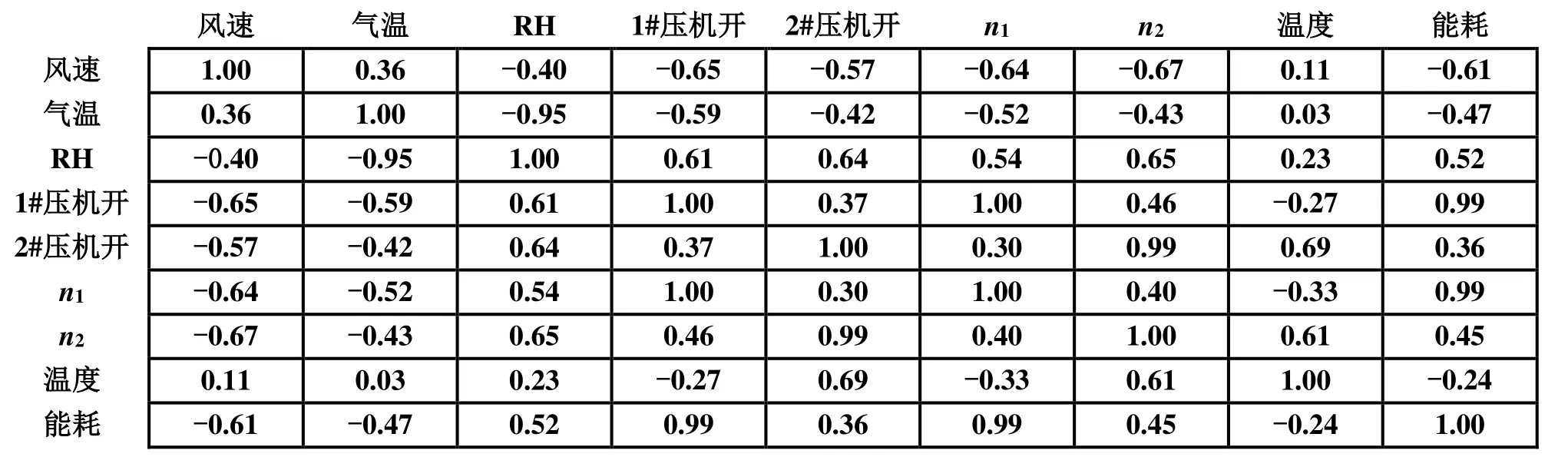
图9 变量间相关性系数
3.3 空调系统用户行为变量节能潜力分析
首先对用户行为数据通过熵权法确定每个用户行为变量的权重,结果如表4所示。将已求得的每个聚类的用户行为数据的平均值,乘以在每个用户行为数据的权重,得到一个加权平均值,把这个值作为该聚类的用户行为指标,或者称之为该聚类内用户行为数据的综合得分。结果如表5所示。

表4 用户行为变量的权重
由表5 可得出6 个聚类的能耗得分,进而可以得出一个综合能耗评价值的排序,即能耗评价从低到高分别为聚类3、聚类6、聚类2、聚类1、聚类5 和聚类4。

表5 各个聚类内用户行为数据的综合得分
将每个聚类内的每个用户行为数据通过该聚类内用户行为数据的综合得分进行均值归一化(即所有数据都除以各自聚类对应的用户行为数据综合得分),并画出箱线图,结果如图10所示。图中的横坐标标签v1~v6 分别表示1#压机开启状态、2#压机开启状态、1#压缩机转速、2#压缩机转速、温度设定和能耗指标。
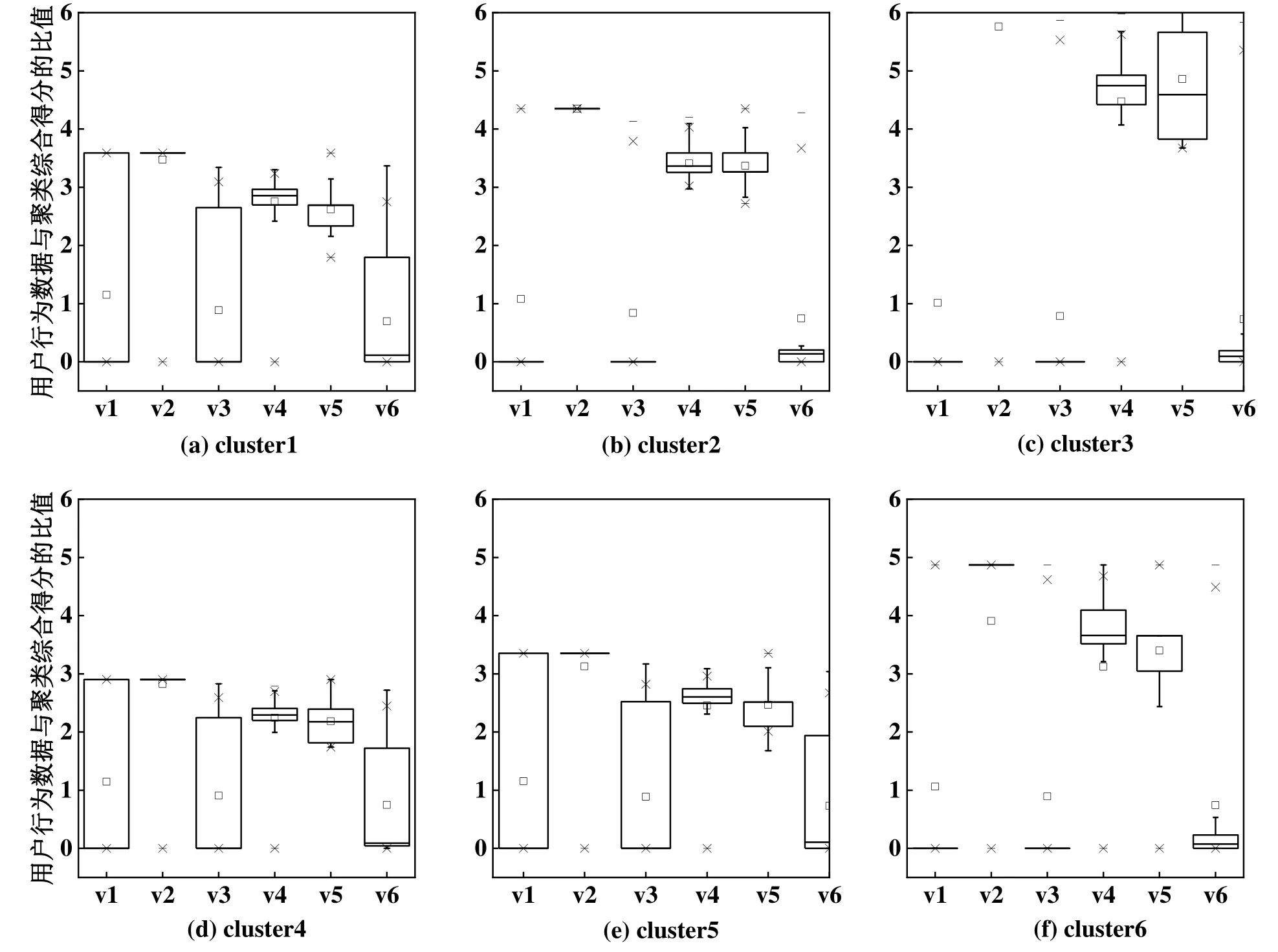
图10 用户行为数据箱线
每个聚类内用户行为数据与该聚类的综合得分间比值的波动范围大概在0~6,因此认为比值在0~3 的波动是不明显的波动,明显波动与不明显波动间的阈值设为3。由图10 可知,阈值大致将聚类分成两部分,聚类2、聚类3 和聚类6 各个数据值较高,聚类1、聚类4 和聚类5 各个数据值较低。对于开启状态和转速这两个具体变量而言,1#压缩机均比2#压缩机分布地更离散。一个系统运行状态越离散,说明该系统运行越没有规律,原因可能是受到过多人为控制干预。而人为控制时,对环境状态的反应总是滞后的,比如当温度上升,或风速下降,或相对湿度上升的时候,用户打开空调的需求增加,需求增加后才打开空调,用户的反应是滞后的;同样,当以上3 种天气量向与刚才相反的方向变化的时候,用户开启空调的需求是减小的,需求减小后才关闭空调,反应同样是滞后的。前者会影响用户的热舒适性,后者造成能源浪费,无法兼具热舒适性和节能。因此,一个系统运行状态越离散,说明该系统有更高的潜力去采取措施达到节能的目的。因此,1#压缩机的运行状态的分布比2#压缩机的运行状态分布更加离散,1#压缩机上有更高的潜力去采取措施达到节能的目的。
3.4 空调系统聚类节能潜力分析
为了评估每个聚类的节能潜力,首先定义每个聚类内的参考运行状态。已经求得每个聚类内各个用户行为数据的平均值,可得1 个6 维中心点(因为有6 个用户行为变量)。在每个聚类内,与中心点的欧几里得距离最小的运行点就是参考运行点。
根据熵权法求得的权重,可以求得每个运行点的综合能耗评分,文中定义每个聚类中综合能耗评分最小的运行点为该聚类中的最小评分运行点,定义每个聚类中综合能耗评分最大的运行点为该聚类中的最大评分运行点。
因此本文定义了在每个聚类内的3 种特殊的运行点:参考运行点、最小能耗评分运行点和最大能耗评分运行点。这3 种特殊的运行点的堆叠条形图如图11所示。图中Ref 为参考运行点,Min 和Max分别为最小能耗评分运行点和最大能耗评分运行点,纵坐标是6 个聚类的用户行为数据值。
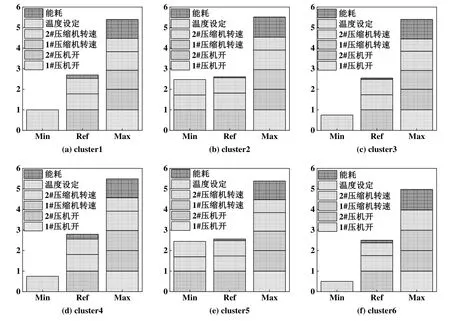
图11 特殊运行点用户行为数据堆叠条形图
文中将聚类内的参考运行点作为一个基准,可以求得每个聚类内最大能耗评分运行点和参考运行点间的用户行为数据的差。两者差越大,说明该聚类内运行点的节能潜力越大。因此将聚类内运行点的节能潜力指标定义为最大能耗评分运行点和参考运行点间的用户行为数据的差。聚类1 至聚类6 的节能潜力指标依次为2.70、2.91、2.86、2.69、2.82 和2.47。因此,节能潜力从小到大的排序是聚类6、聚类4、聚类1、聚类5、聚类3 和聚类2。
4 结论
本文使用模式识别的技术,利用某酒店冷水机组系统的实际运行数据,分析了该系统可以采取的节能运行策略,使用神经网络对能耗指标异常值进行处理,并对天气数据进行聚类分析,将所有数据分到了6 个聚类中,再对数据进行相关性分析和节能潜力分析,得出如下结论:
1)温度与1#、2#压缩机开启状态之间的相关性系数分别为-0.59、-0.42;而风速和相对湿度与压缩机开启状态的相关性系数与之相比更高;说明温度对压缩机开启状态的影响比风速和相对湿度要小,虽然在直观印象中,温度的影响似乎是最大的;温度设定与3 个天气变量的相关性分别为0.11、0.03和0.23,都非常低,说明酒店的用户很少随天气变化而调整制冷系统温度的设定,为了使系统更加节能,用户应该随天气变化更恰当地调整温度设定;
2)能耗与1#压缩机开启状态之间的相关性系数是0.99,而与2#压缩机开启状态之间的相关性系数是0.36,说明能耗主要是由1#压缩机的开启状态所影响的,因此相对于2#压缩机,要关注在1#压缩机的运行策略上考虑节能措施;
3)6 个聚类的能耗评价从低到高分别为聚类3、聚类6、聚类2、聚类1、聚类5 和聚类4;根据对用户行为数据的箱线图分析可以得出,1#压缩机的运行状态的分布比2#压缩机的运行状态分布更离散,说明1#压缩机上有更高的潜力去采取措施达到节能的目的;6 个聚类的节能潜力指标,依次为2.70、2.91、2.86、2.69、2.82 和2.47。
猜你喜欢
昆钢科技(2022年2期)2022-07-08
当代水产(2021年10期)2022-01-12
建材发展导向(2021年23期)2021-03-08
上海节能(2020年3期)2020-04-13
船舶标准化工程师(2019年4期)2019-07-24
石油化工建设(2018年3期)2018-11-30
石油化工自动化(2018年5期)2018-11-14
华人时刊(2018年15期)2018-11-10
压缩机技术(2014年5期)2014-02-28
河南化工(2013年13期)2013-08-15
