
基于ELMo-BiLSTM-CRF 模型的中文地址分词
2021-10-29 12:18于文年彭艳兵
电子设计工程 2021年20期
余 俊,于文年,彭艳兵
(1.武汉邮电科学研究院,湖北武汉 430070;2.南京烽火天地通信科技有限公司,江苏南京 210019)
外卖、网上购物、共享单车等互联网资源的普及化和大众化,衍生出了大量的中文地址信息,中文地址信息中包含着一个人每天的行动路线和个人信息,这类信息若可以获得高效利用,将会是一笔极其宝贵的资源,使得对中文地址信息解析[1]的研究显得尤为重要,而中文地址标准化是对地址信息解析的基础,这些都离不开中文地址分词。
不同于英文单词,由于中文有着自身的语言属性,不同词之间缺乏显著的切分凭据,而且中文词语本身有语法结构[2],中文地址信息容易出现歧义、缺失、冗余[3]等情况,使得该分词面临巨大困难。如今,国内外很多学者在该领域也展开了较为丰富的研究。
将字符串作为基础的匹配[4]方法,能按照一定规则扫描相关词条,直至找到需要匹配的字符串,实现简单,但是无法识别匹配速度偏慢且有歧义和缺失的字段;针对该方法存在的缺点,文献[5]中将标志词作为基础,搭建相应地址分词算法,该方法可以实现正向自适应长度匹配,并针对缺失的地址要素,给出相应的补偿,从而解决分词问题,可以有效消除字段缺失,进一步降低了时间复杂度,从而提升匹配速度,但是无法解决未登录词[6],且完全依赖于字典,对字典的长期维护也是一个极大的问题。
为了更好地提升中文地址分词的性能,文中将ELMo[7]模型应用于中文地址分词中,并借助于实验对该分词模型的有效性进行相应验证。
1 数据集预处理
文中的研究数据由南京烽火星空科技有限公司提供,抽取了50 000 条南京市地址数据信息作为数据源,数据中包含了不同的地址层级。
由于数据源中地址的不规范性,存在大量重复、字段缺失、地址错误且含有字符等信息错乱的地址,为了对复杂多样的地址展开高效的数据处理,借助于文献[8]分布式框架对数据展开分析与并行处理,包括诸多非结构、结构化数据的处理。文中使用南京烽火星空科技有限公司自主研发的ETL[9]数据治理工具对数据进行处理,以保证测试数据集有较高的质量,减少由于数据源的原因导致实验结果不理想。
通过采用sql+的模式下发任务,并通过开发自定义函数(udf,udaf)来定制化地处理样本数据,以便针对数据集中各种数据进行去重、删除错乱地址和补充缺失字段。
一条地址往往包含多个地址要素,将这些地址要素提炼出来,为方便起见,主要将标准地址划分为12 个地址层级:国家、省、市、区(县)、街道、社区、路、号、小区、楼栋号、单元、楼层、室;每类都有其对应的特征词,地址层级如表1 所示。
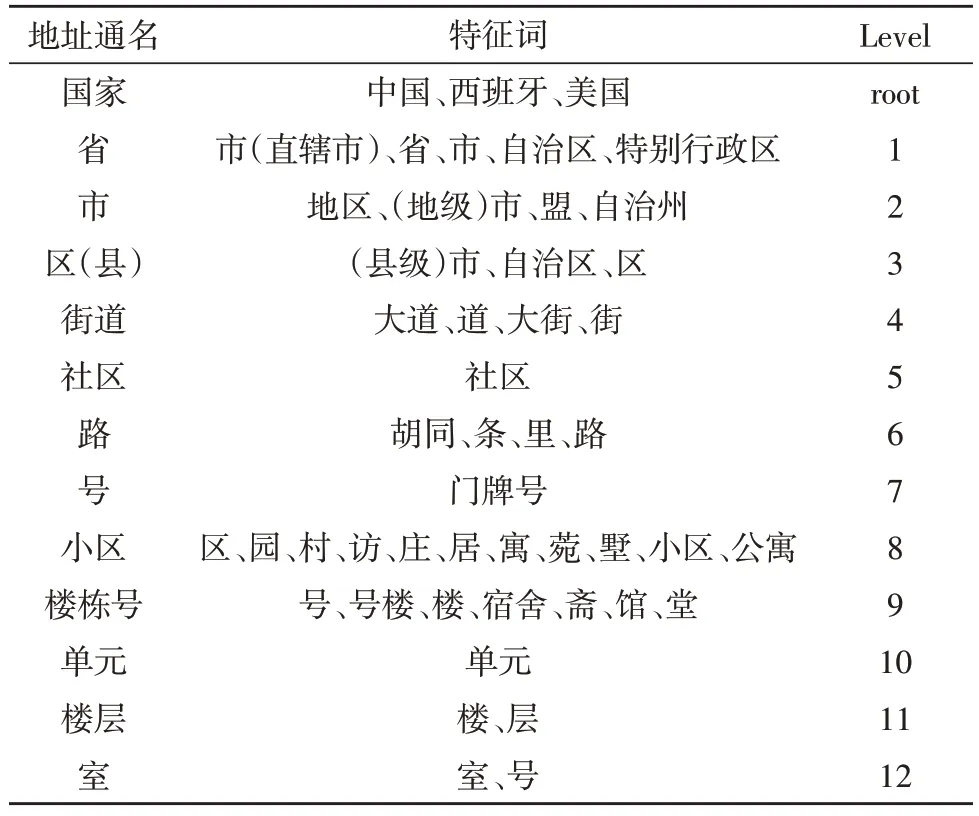
表1 地址层级
2 模型建立
2.1 ELMo模型
ELMo 模型通过采用两个阶段的方式对整个模型进行训练。第一阶段主要是利用语言模型对其进行预训练;第二阶段是在完成下游任务之时,借助预训练网络,通过单词网络对有关Word Embedding 进行提取,并将其视作新的特征补充到下游任务之中[10]。
循环神经网络被广泛应用于命名实体识别[11]、中文分词、智能推荐等自然语言领域,经典的RNN[12]模型中因存在某些原因产生了无法解决长时记忆的问题,比如梯度消失和梯度爆炸。而LSTM[13](Long-Short Term Momory neural Network)通过对RNN 算法进行改进,解决了长期依赖的问题。
该模型还运用了多层LSTM,同时还新增了后向语言模型,即为backward LM,当前阶段的输出通常情况下不仅与之前的状态有关,还可能与未来的状态有关。譬如对一句话中的重复单词进行预测,不仅需要根据当前状态进行判断,还需要考虑之后的内容,真正做到基于上下文判断。
该模型中的预训练过程,不仅对单词的Word Embedding 进行了学习,同时还能很好地掌握双层双向LSTM 网路结构。ELMo的双向LSTM 模型如图1所示。
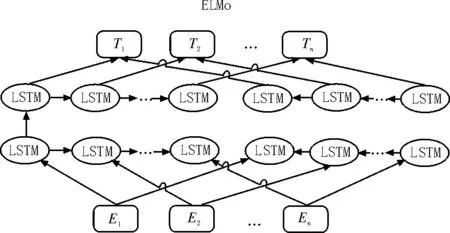
图1 ELMo的双向LSTM模型
前向LSTM 结构如式(1)所示。
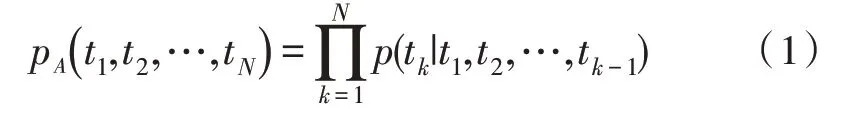
后向LSTM 结构如式(2)所示:
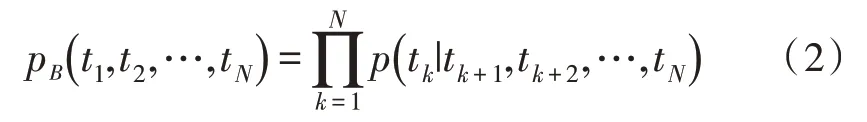
将前、后向语言模型相结合,同时还对该模型的对数最大似然函数最大化后得到:
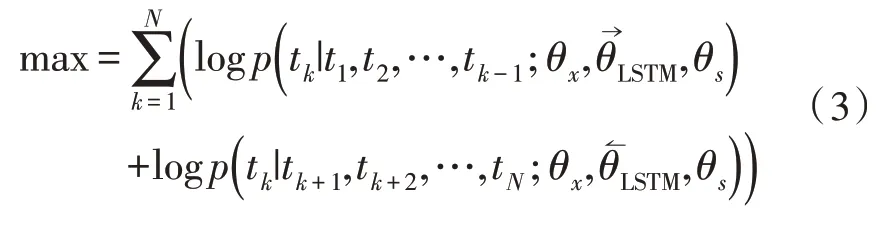
其中,θx表示token的参数,θs表示softmax 分类的参数,分别表示前、后向语言模型LSTM 层的参数。
ELMo 模型训练好之后,在下游序列中会产生不同的token,即:

下游任务充分利用了各种表示,同时利用了有关分配权重,即:
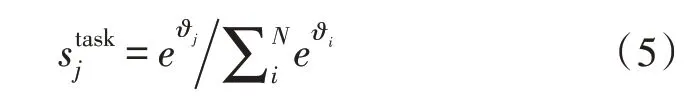
式中,softmax 通过归一化处理之后得到的权重是stask,而且准许任务模型缩放,并得到完整的ELMo向量γtask,其也是标量参量。
2.2 BiLSTM-CRF模型
对于LSTM 而言,利用训练方法可以得到需要遗忘或者需要记忆的信息,然而借助它进行建模时,存在一定的局限性,即很难借助于编码形式获取由后往前的信息,这些信息会丢失,然而借助BiLSTM 模型就能很好地捕捉双向语义依赖,不仅保存了向前的上下文信息,还考虑了向后的上下文信息,因此其在对中文地址分词中性能更优。
在序列标注任务中,BiLSTM-CRF 模型能取得极好的效果,BiLSTM-CRF 在时间上的展开图如图2所示。
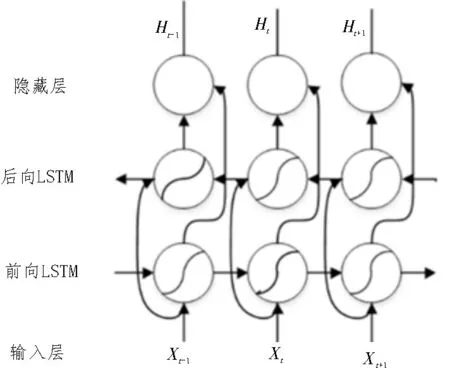
图2 BiLSTM在时间上的展开图
即便神经网络有着较高水平的非线性拟合功能,且能得出较佳的模型,然而该模型仅仅考虑了标签上下文关系,只需要输出概率最大的标注,没有考虑到输出标注间的关系。
为此,借助于CRF[14]开展词性标注,由于要对临近单词词性进行标注,因此,对于序列CRF 模型而言,借助于BiLSTM 模型的状态序列向量,将其用作CRF 层输入,同时运用维特比算法,解决训练和解码问题,得出最好的地址标注序列。
对于BiLSTM-CRF 模型而言,要明确输入序列,输入序列用X表示,而输出的相应序列是y,预测输出为:
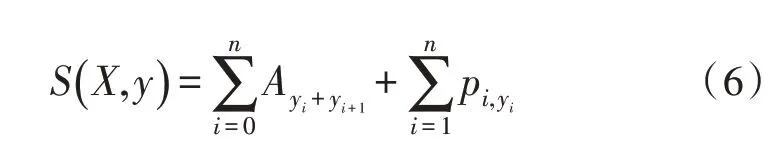
S(X,y)为计算出来的最终得分,通过维特比算法计算出最好的地址标注序列。
对于BiLSTM 而言,在学习语句时,由于模型大小的约制,使得关键信息出现丢弃问题,为此可以在该模型中新增CNN层,并提取当前局部特征。而且这种方式还是典型、高效的方法,可以对词的形态信息进行抽取,譬如词的后、前缀等。又由于BiLSTM 得到的128维是整个地址对当前位置的信息,而CNN得到的是当前位置前后窗口大小的局部信息,两者拼接相当于综合考虑了全局信息和局部信息。
图3 中,BiLSTM的I、O 层都运用了dropout 层,结果显示它可以明显提升模型性能。
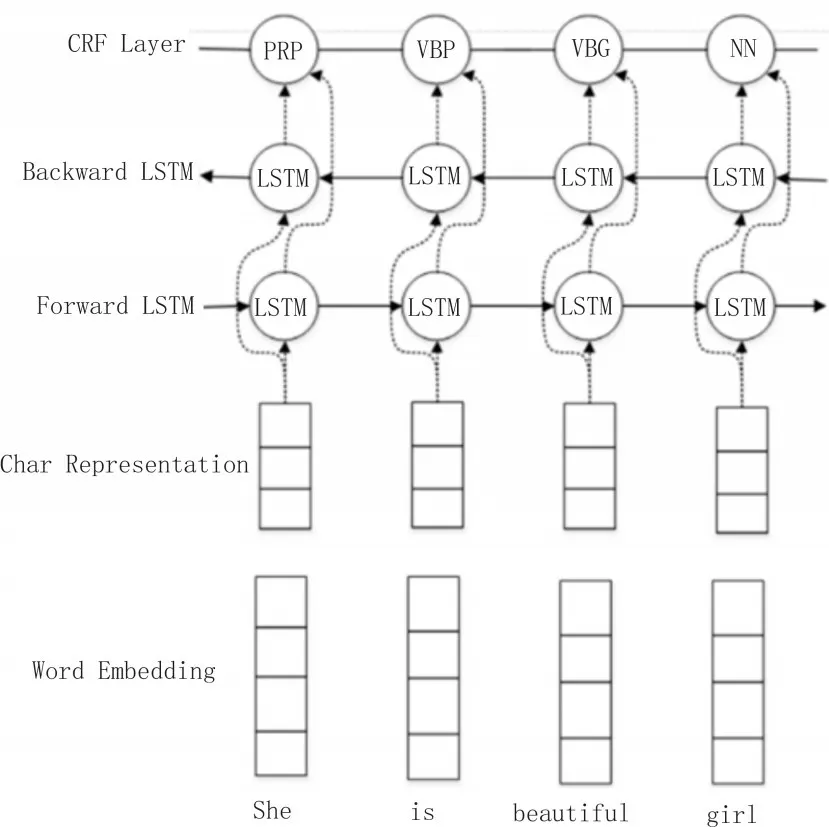
图3 基于BiLSTM-CNN-CRF的中文地址
3 实验
3.1 实验设置与参数
实验的主要环境参数如下:CPU 为Intel(R)Core(TM) i7-9750H CPU @ 2.60 GHZ 2.59 GHZ,GPU:NVIDIA GeF orce GTX 1660 T-i with Max-Q Design,操作系统为Window10 64 bits,而且使用了Tensorflow[15]Bi-LSTM 模型和allennlp 下的ELMo。
模型训练参数如表2 所示。
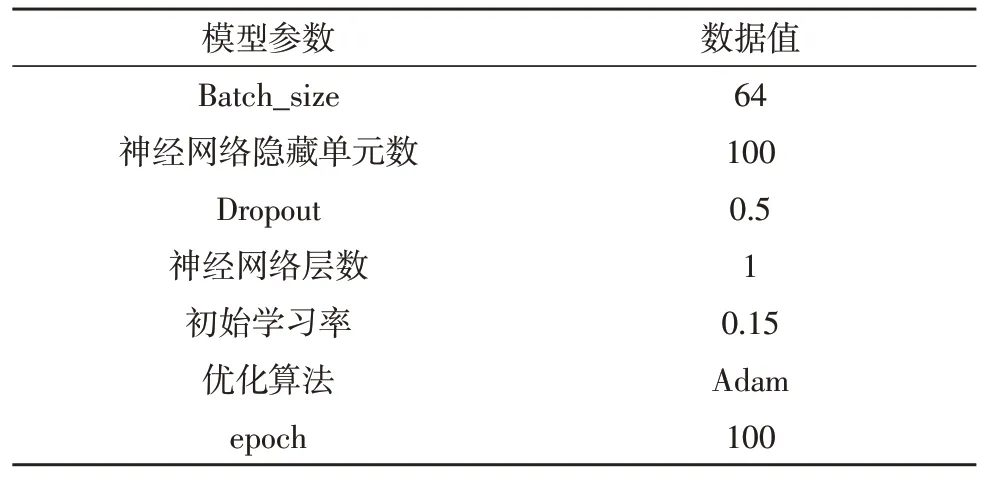
表2 模型训练参数
3.2 模型调优
因为ELMo 预训练模型权重通常比随机初始化权重更优,为此在具体修改时要更具精细性,文中使用更小的学习率来应对训练时的表现,使用0.15的学习率能使效果更好;在遴选dropout 层时要慎重进行选择,如果dropout 层过低会产生过拟合问题,在隐藏与输入层中,可以运用两层的dropout,就能使模型的泛化能力得到明显提升;使用正交化优化策略使方差和偏差两者保持均衡,通过增加网路的深度、训练时间长度来减小偏差,以及通过增加训练数据、正则化等方式来降低方差,循环该过程,直至达到平衡。
在标注词性时,可以将其词位标注细分成4、6,词位标注也会对分词性能造成影响。
3.3 模型评价指标
该指标主要涉及到均值、精确率与召回率,计算公式如下:
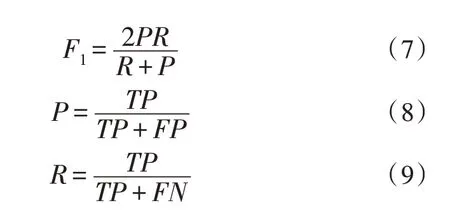
式中,F1为均值,P为精确率,R为召回率。
3.4 实验结果与分析
在以上实验环境下,使用如下训练模型对同一测试样例数据进行地址分词性能对比,选用随机抽取已经治理好的南京市的50 000 条地址作为测试数据集进行分词性能对比;在表3 中,BiLSTM-CRF 比单独使用BiLSTM 高了接近1.2 个百分点,可能是由于CRF 能够限制模型标注间的输出,BiLSTM 能够双向记忆,能够记忆过去的地址信息和未来地址的信息;整体的实验结果表明BiLSTM-CRF 在地址分词中有很好的性能,除了BiLSTM 和BiLSTM-CRF 之外,ELMo 模型的召回率均大于90%,原因可能是测试数据集中存在较多的歧义地址,ELMo 模型在处理地址歧义方面有天然的优势。加入了CNN 模型之后,效果略有增强。
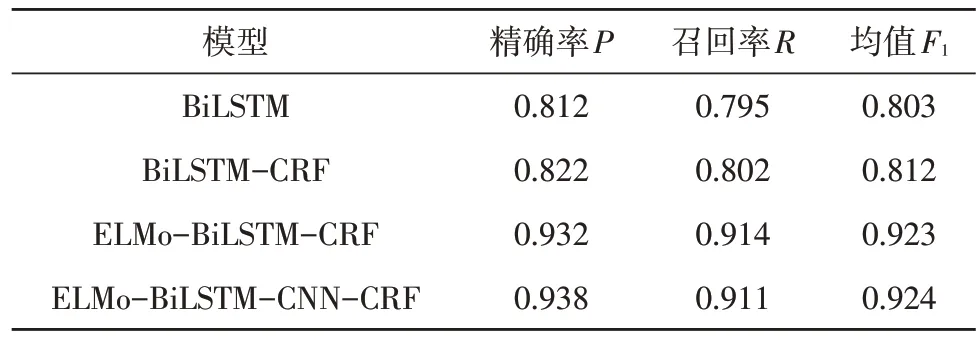
表3 模型整体分词性能对比
表5 中,1~6 分别表示BiLSTM4 词位标注,BiLSTM6 词位标注、BiLSTM-CRF4 词位标注、BiLSTM-CRF6 词位标注、ELMo-BiLSTM-CRF4 词位标注、ELMo-BiLSTM-CRF6 词位标注,使用同样的测试数据集分别对1~6 模型进行性能测试,结果表明,采用6 位词性标注的性能均比采用4 位词性标注的分词性能好。
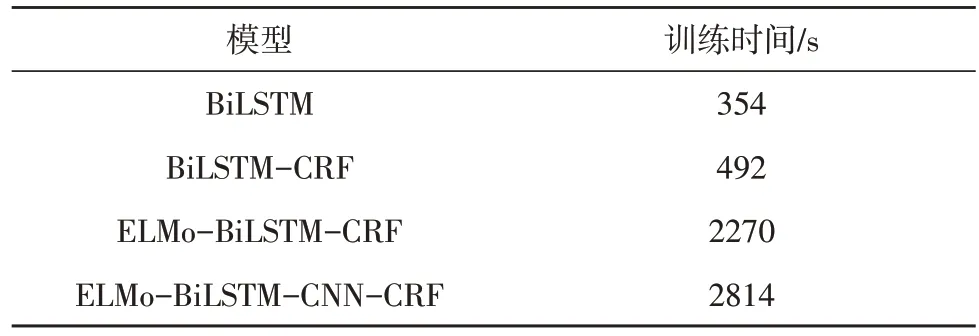
表4 模型训练时间
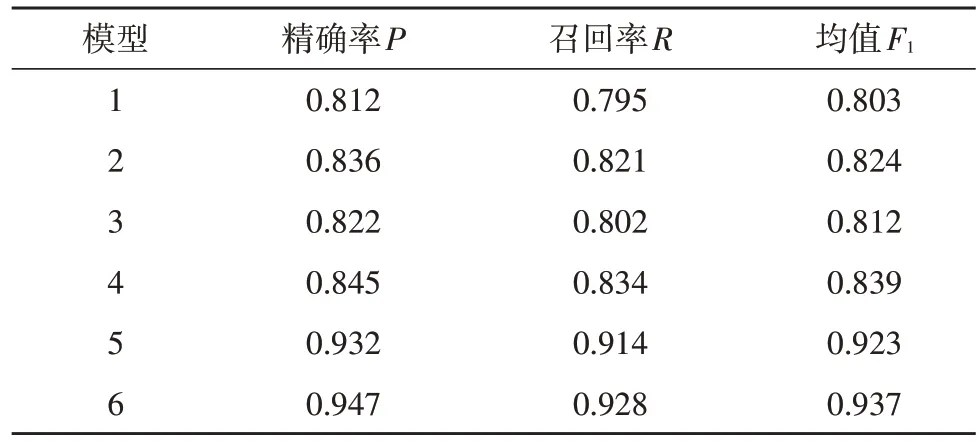
表5 不同标注下模型分词性能对比
4 结束语
文中将地址信息按照地址层级进行分级,并使用标注体系进行中文地址标注,根据ELMo、BiLSTM、CRF 模型特点,将几者结合起来并进行实验对比,结果表明,按照层级进行地址标注更加符合地址的真实情况,利用MapReduce 分布式计算,处理数据更高效,使得地址标注更贴切实际,粒度更细致,为后续的工作做了良好的铺垫。
文中研究了ELMo-BiLSTM-CRF 模型在地址分词领域中的应用,并对BiLSTM、BiLSTM-CRF 地址分词性能进行对比分析,发现针对地址歧义的地址数据ELMo 模型有明显的性能优势,BiLSTM-CRF 整体效果较佳,单独使用BiLSTM 模型分词效果不佳。
文中使用dropout 和Adam 优化[16]提高实验效果,并使用正交优化策略保证方差和偏差的平衡,使用较小的学习率使模型表现更加精细,并加入CNN 模型,使得模型更加丰满,在分词性能上有更好的表现。
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
家庭影院技术(2019年8期)2019-08-27
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
中华手工(2017年2期)2017-06-06
燕山大学学报(2015年4期)2015-12-25
中国塑料(2015年4期)2015-10-14
中外会展(2014年4期)2014-11-27
火炸药学报(2014年1期)2014-03-20
外语学刊(2011年3期)2011-01-22
