
煤矿安全风险智能分级管控与信息预警系统
2021-10-28 04:43王道元孟志斌张雪峰李敬兆
煤炭科学技术 2021年10期
王道元,王 俊,孟志斌,张雪峰,李敬兆
(1.安徽理工大学 计算机科学与工程学院,安徽 淮南 232001;2.晋能控股集团有限公司,山西 大同 037003)
0 引 言
目前我国煤矿开采正逐步向深部发展,随之而来的是地质条件越来越复杂,开采过程中面临的安全隐患也逐渐增多[1]。采煤过程中安全事故频发,与煤矿相关企业对煤矿安全[2]风险等级评估能力较弱从而未及时处理安全隐患问题有很大关系。目前,煤矿企业急需一种能及时评估出煤矿安全隐患风险等级并将对应的风险等级应对措施及时反馈给监督人员的信息预警系统[3]。
目前,在煤矿安全风险分级管控方面,煤矿企业将记录的安全隐患数据存入到相关数据库中,综合分析在哪一方面容易出现问题,划分安全风险等级,进而寻找煤矿安全隐患管理工作重点,以此来提高煤矿开采过程中的安全性。以上虽然在安全风险上做了分级,但是在分级的数值方面划分不够精确,如果取到一个处于2个等级的中间值,很容易造成模棱两可的情况。研发一种可以精确计算煤矿安全风险等级的系统[4],并将对应的处理安全隐患的条例提供给相关人员,是亟待解决的关键问题。
随着国家对煤矿开采安全方面的重视,开采流程和安全隐患管控越来越规范[5]。针对安全隐患,许多企业提出了安全风险分级这一概念,使安全隐患问题更加直观地体现,并在分级的基础上,提供了应对每一级安全隐患的措施。王小林等[6]提出“四环五级”的管理模式,使安全隐患从被发现到解决这一过程更加规范化、流程化,将安全隐患纳入到实时监控范围之内。该方案实现了向现代化、科技化、数字化的过渡,但只是将隐患问题进行简单地叠加处理,对于更深入地划分安全风险等级的方案并没有做出更具体的阐述。何桥等[7]提出一种分析煤矿安全风险的方案,该方案对隐患生命周期、隐患风险因素、区域隐患风险综合分析,以此实现隐患的综合预警,并将排查治理能力考虑在内,使得对隐患程度的评估更加精确,采取的治理措施更加高效。但当评估的风险数值处于2个安全风险等级中间值或该中间值的近似区域范围时,上述方案容易造成预警不准确,且预警之后不能自动提供应对的条例,达不到预警信息及时反馈的效果。
针对上述研究中评估安全风险数值精确度低且信息分析预警能力较弱等问题,笔者通过构建数据筛选和安全风险精确分级的智能模型,设计了一种基于改进粒子群算法(Particle Swarm Optimization,PSO)和改进卷积神经网络(Convolutional Neural Network,CNN)的煤矿安全风险智能分级管控与信息预警系统。该系统具有安全风险精确评估、以各种统计图显示隐患数据、根据安全风险等级显示预警并提供合适的应对条例等功能,解决了因煤矿安全风险等级评估不精确而导致的应对措施不到位的问题,同时智能化显示数据和安全条例,为工作人员提供了很大方便,在解决煤矿安全隐患方面起到了重要作用。
1 智能分级管控与信息预警系统设计
煤矿安全风险智能分级管控与信息预警系统分为数据采集层、智能模型层、数据处理层、风险预警层,如图1所示。

图1 煤矿安全风险智能分级管控与信息预警系统体系结构Fig.1 Structure of intelligent hierarchical control and information early warning system of coal mine safety risk
1.1 数据采集层
数据采集层由人工汇总记录安全隐患信息,之后经过何桥等[7]提出的安全风险评估方案处理得到最初的数据,然后将这些初始数据导入到煤矿安全风险智能分级管控与信息预警系统的数据库里面。数据采集层结构如图2所示。

图2 数据采集层结构Fig.2 Structure of data acquisition layer
1.2 智能模型层
智能模型层主要由概念模型、物理模型和逻辑模型组成。应用设计模块将概念模型实例化,并将物理模型和逻辑模型结合起来,通过构建智能数据筛选模型和智能风险分级模型,来解决煤矿安全风险分级不精确问题,如图3所示。

图3 智能模型层结构Fig.3 Structure of intelligent model layer
概念模型是指对现实中用到的数据进行抽象化,在设计阶段了解和描述数据。该模型具有较强的语义表达能力,能够方便直接表达应用中的各种语义知识,易于用户理解,使应用设计模块更加符合要求。物理模型是包含初始的隐患评估值和安全条例的数据库。逻辑模型是煤矿安全风险智能分级管控与信息预警系统的核心模型,通过改进的粒子群算法和CNN算法来实现安全风险智能分级的功能。应用设计模块将3个模型连接起来,建立了一个具有定义数据、算法设计、计算数据等的数据运行环境。
1.3 数据处理层
数据处理层是将智能模型层中构建的模型加以运用,由人工录入矿区、日期、检查人员等相关的隐患信息,采用何桥等[7]提出的分析煤矿安全风险的方案来计算出风险评估值,将这些评估值记为初始数据导入到数据库。初始数据通过上一层的基于改进PSO的智能数据筛选模型,剔除掉不合理的数据。调用基于改进CNN算法的智能风险分级模型,经过计算数据得到高精确度的风险评估值。同时将计算后对应的风险等级、该风险等级对应的安全条例和隐患信息的统计图等显示出来,供工作人员查看,为接下来安全隐患的处理提供方便。数据处理层结构如图4所示。

图4 数据处理层结构Fig.4 Structure of data processing layer
1.4 风险预警层
风险预警层是将经过上面智能模型层处理后的相关数据进行分类、统计,以可视化的形式呈现,方便分析得到的安全隐患信息。工作人员在前台系统输入日期、矿区等关键词,检索存储安全隐患数据的数据库,可以查询得到相关数据信息。该系统的前台功能如下:首先,通过设定的风险阈值来判断处理后的数据所处的风险等级(本系统划分了4个等级:红、橙、黄、蓝),如果是红色和橙色风险级别,指示灯则一直快速闪烁,来提醒工作人员及早处理该安全隐患事件;黄色风险级别,指示灯慢速闪烁;蓝色风险级别,指示灯正常显示;以此增大预警信息的区分梯度和传递速度。其次,通过智能模型决策之后的整体安全风险数据信息采用扇形图、折线图等等各种图表格式展示出来,将大量的描述数据化繁为简,可以清晰地看出煤矿安全隐患问题的变化趋势。最后,根据相关的安全风险分级反馈,给出应对各级安全隐患的条例。工作人员依据煤矿安全隐患信息的情况和安全条例的建议做出整改措施,以此达到迅速整改安全隐患的目的,并极大改善煤矿井下工作人员的安全环境。风险预警层结构如图5所示。

图5 风险预警层结构Fig.5 Structure of risk warning layer
2 智能数据筛选模型构建
2.1 模型结构
基于改进PSO的智能数据筛选模型如图6所示,构建过程如图7所示。

图6 基于改进PSO的智能数据筛选模型结构Fig.6 Structure of intelligent filtered data model based on improved PSO
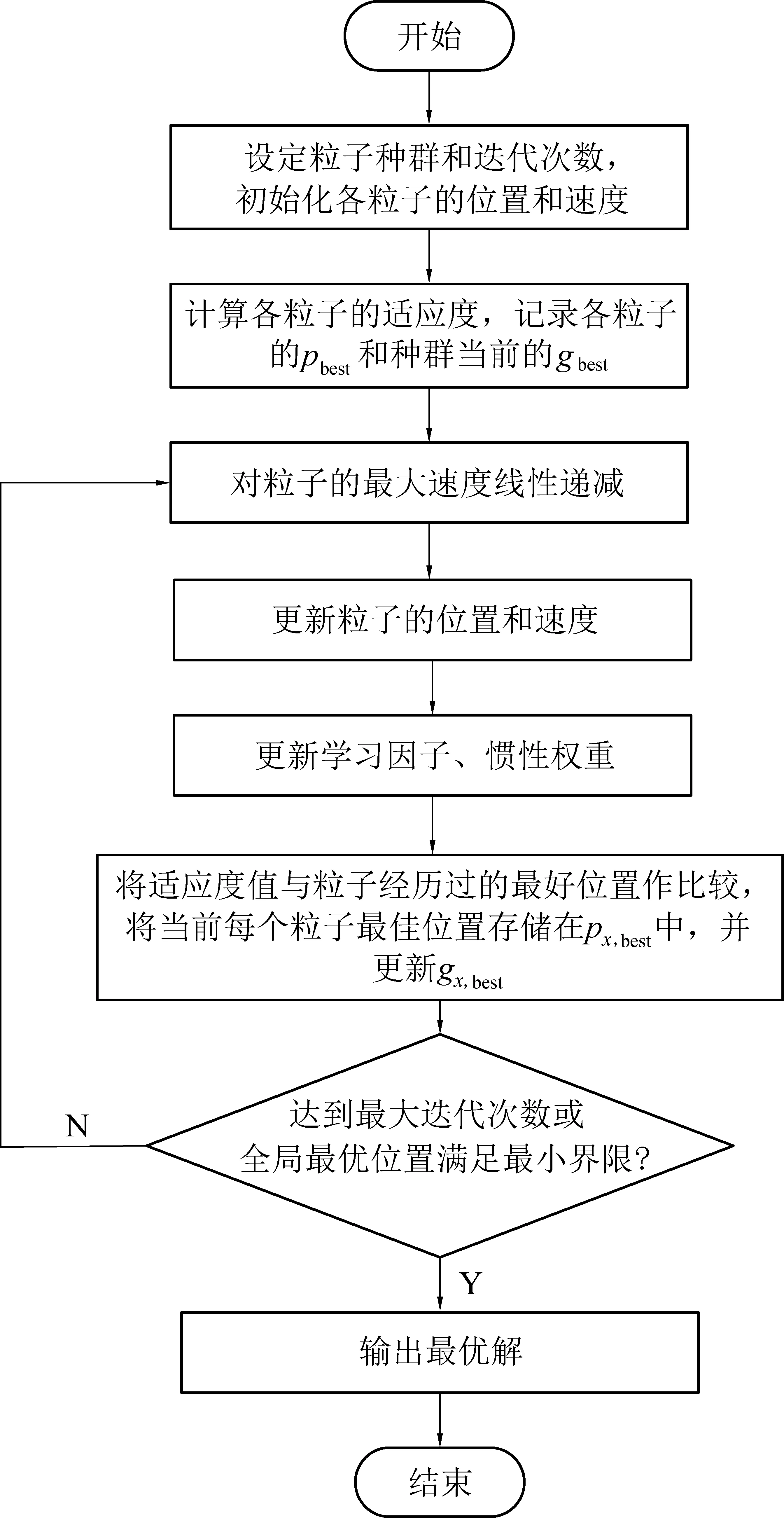
图7 基于改进PSO的智能数据筛选模型构建过程Fig.7 Building process of intelligent filtered data model based on improved PSO
将最初录入的安全风险评估值当作一个个粒子,要解决的剔除异常值的问题转化为搜索空间中的粒子最值问题,在系统开始运行之初,为所有粒子赋予1个适应度函数(Fitness Function),每个粒子还各自有1个可以决定他们移动距离和方向的速度。以初始粒子作为起始点,对该粒子周围的粒子探查,以此遍历完所有的粒子。粒子上包含有关速度和位置信息的粒子信息表,在探查具有安全风险评估值的粒子时,粒子和粒子之间经过信息共享,找到相对最优值,将数据记录下来。在迭代运算中,粒子会探查个体最优解和全局最优解,2个最优解分别指代粒子在其周围找到的个体极值pbest、在整体中找到的极值gbest,通过比较2个最优解来不断地更新自己。经过不断地迭代,当gbest满足设定条件时,将该值存储,作为首位最优解。再进行下一次查找最优解,得到次首位最优解。如果首位最优解和次首位最优解求得的是2个最大值,则再用同样的方式求得2个最小值,分别称为末位最优解和次末位最优解,反之亦然。将首位最优解与次首位最优解为1组比较,末位最优解和次末位最优解为1组比较,如果都没有超过设定的误差值,则都保留。如果其中有1组超过设定的误差值,则剔除掉首位/末位最优解,如果2组都超过设定的误差值,则将首位和末位最优解都剔除掉,再按照上述对比计算其余的值,直到保留首位和末位所有对比数据。
2.2 PSO算法计算步骤
1)设定初步的评估值数据为1个粒子种群,设置迭代次数k,初始化m个粒子,每个粒子i代表一个安全风险评估值,其包含一个d维的位置向量,表示为Xi=(xi1,xi2,…,xid),(i=1,2,…,m),粒子i的速度表示为Vi=(vi1,vi2,…,vid),(i=1,2,…,m)。
2)设置适应度函数,此处采用Griewank函数[8],函数表达式为
(1)
其中:f(x)为粒子值;xi为每个粒子i在该适应度函数中对应的横坐标;m为粒子数量。每个粒子都有1个体极值pbest、速度向量Vi、位置向量Xi存储在节点信息表。
3)在粒子迭代过程中,为防止粒子的盲目搜素,限定粒子的速度和位置在该区间[-vmax,vmax]、[-xmax,xmax]表示的范围内,-vmax为用户设定的最小速度,vmax为用户设定的最大速度,-xmax为用户设定的最小位置,xmax为用户设定的最大位置。针对粒子速度采用线性递减的方法,在迭代的初始阶段,给安全风险评估值粒子一个最大速度vmax,以此易跳出局部最优,增加全局的搜索能力;在迭代末期阶段具有比较小的速度,用来缩小粒子的搜索范围,增强局部收敛能力,提升寻优能力[10]。
4)在迭代过程中,评估值粒子在搜寻到最优解后,改变自己在d维空间中的搜索方式,按照式(2)来更新速度和位置。

(2)
其中:vid(t)为第i个粒子(有d个维度)在t时刻的速度向量;xid(t)为第i个粒子在t时刻所在的位置;px,best(t)为粒子个体截止在t时刻出现的最佳位置;gx,best(t)为粒子截止在t时刻出现的全局最优解位置;w为惯性权重;c1和c2为学习因子;rand1( )、rand2( )为(0,1)间的随机数。
5)学习因子使粒子具备更好的学习能力。采用异步学习因子[11],即c1和c2。学习因子在运算过程中变化不一样,在前期设置c1较大的值,c2较小的值,可以增加计算的局部范围内评估值粒子数量,加强全局搜索能力,在末期设置c1较小的值,c2较大的值,有利于避免局部最优,从而收敛到局部最优解。学习因子数值变化表达式为
(3)
其中:c1,start、c2,start为学习因子c1和c2的初始值;c1,end、c2,end为c1和c2的末期值。为了达到较好的参数效果,一般设置如下:
(4)
适当的惯性权重[12]w在迭代过程中,可以提高算法性能,避算法陷入局部最优[13]。针对惯性权重,笔者采用线性微分递减策略[14],见式(5)。
(5)
其中:wmin和wmax分别为w的最小值和最大值,t、tmax分别为当前迭代次数和最大迭代次数。w在(0,1)中取值,实验室试验结果表明将w设置为从0.8到0.3的线性下降时,目标函数计算出数值更稳定,提高了算法的性能,比典型线性递减策略表达效果更好。
6)利用该改进的PSO算法对数据进行迭代,如果没有超过迭代次数或者达到计算的最小阈值,继续进行第4步,更新计算评估值粒子的速度和位置,直到满足条件得到最值。计算相邻的2个最大值和最小值,比较之后得到筛选的煤矿安全风险评估值数据。
2.3 算法仿真与分析
实验室中训练用到的数据集为煤矿实际数据,该数据集由2 000个安全隐患评估值组成。采用MATLAB R2017a进行仿真,平台软硬件配置如下:Window操作系统、Inter i7中央处理器、8核GPU、R2017a的Matlab、32GB内存。
通过使用普通PSO算法和改进后的PSO算法(IMP-PSO)2种不同数据处理方式比较,得出各算法数据处理性能的优劣。从图8可以看出,在相同的实验室环境下筛选200个偏差过大的安全隐患评估值,采用普通PSO算法需要600 s,而IMP-PSO算法则需要450 s,这表示改进后的PSO算法可以提升筛选目标数据的效率。

图8 各算法处理目标数据过程对比Fig.8 Comparison of each algorithm’s processing of target data
3 基于改进CNN的智能风险分级模型构建
3.1 模型结构
基于CNN的智能风险分级模型的构建过程如图9所示。首先构建矩阵,实验室对9个不同的矿区采集安全风险评估值,每个矿区由4个经过筛选后的评估值组成,对9个矿区进行3×3的数据排列,每个矿区进行2×2的数据排列,所有的矿区数据组成一个6×6的二维结构,每个评估值在(0,1)之间取小数点后3位小数。之后进行CNN建模,使用并行融合[15]的卷积神经网络设计,即将卷积核大小设计成不同的尺度,通过2个通道来提取特征[16],用来增大相关特征的提取量,以增加特征的多样性和鲁棒性,提高网络的分类精度。
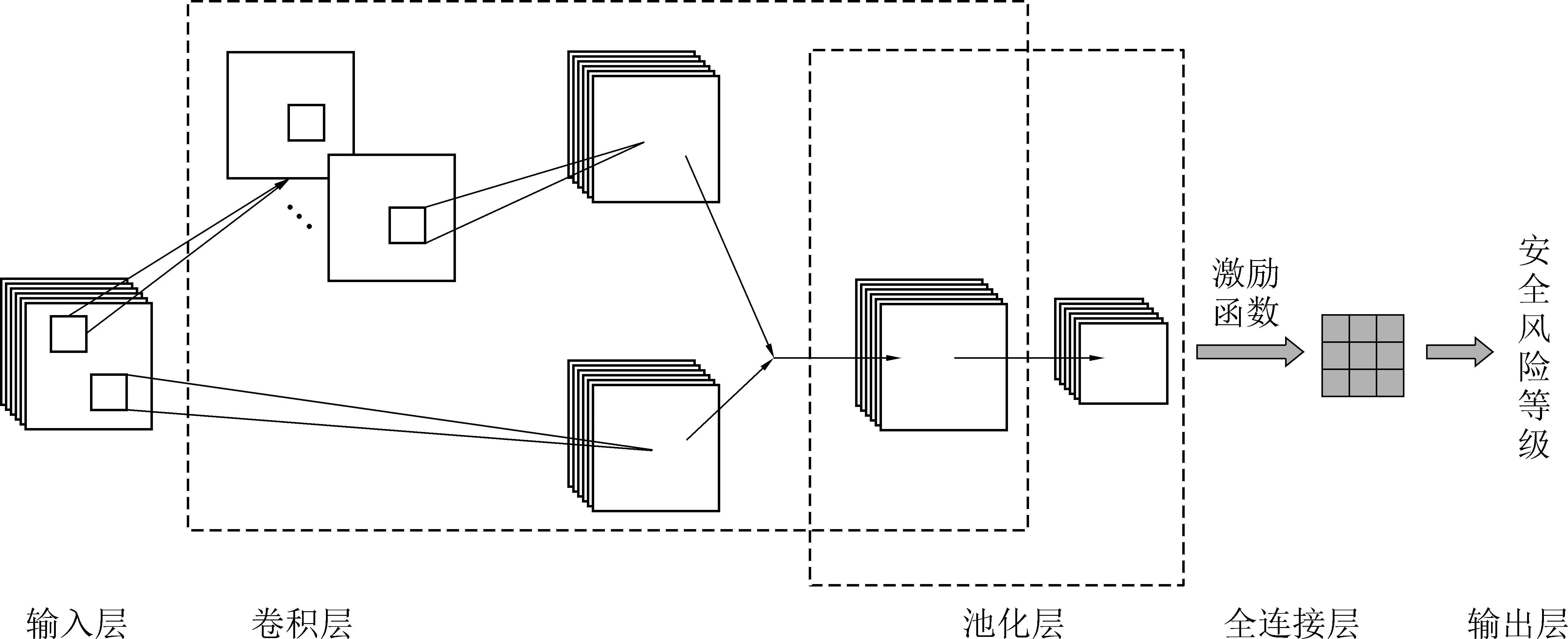
图9 基于改进CNN的智能风险分级模型构建过程Fig.9 Building process of intelligent grading risk model based on improved CNN
首先在卷积层通过设计卷积核,将得到的评估值放大,然后通过池化层进行降采样,以此压缩采集到的数据,这里采用Average Pooling的方式进行降维。最后得到一个3×3的矩阵,即安全风险评估值矩阵,将该矩阵的数值与安全分级做比对,得出这些矿区的安全风险等级。
3.2 改进的CNN算法步骤
1)记录i次9个矿区的安全风险评估值数据,每个矿区包括4个评估值,对每个矿区安全风险进行分析,评估值取小数点后3位,构建最初的矩阵数据模型,如图10所示。

图10 评估值矩阵数据模型Fig.10 Data model of evaluation matrix
图10每个点代表1个安全风险评估值,设定,xi,j为矩阵中的第i行、第j列的节点值。在卷积层使用2个通道来处理数据,为了增强网络的特征提取能力,首先对2个通道采用卷积核为1×1的卷积操作,之后对其中1个通道进行卷积核为3×3的深度卷积提取特征,最后对输出的特征图进行融合。融合输出的卷积值可以表示为
(6)

2)将获取的yi,j进行平均池化[17]操作,以获得更小的参数网格,减少计算维度[18],见式(7)。
f(x)=average(yi,j,0)
(7)
令池化后的数据为P,则每一层输出数据P={P1,1,P1,2,…,P3,3},可得到计算矩阵为
(8)
其中:矩阵f(x)为数据处理之后的每层安全风险评估值的组合,在一次卷积[19]和池化操作之后如果得到的数据划分不够明显,可增加多层卷积[20],来达到数值界限分明的效果。
3)将经过池化层后输出的f(x)作为全连接层的输入数据,对N层数据进行处理,得到一个3×3的数据矩阵,即安全风险评估值矩阵。
4)对照划分安全风险各级的数值范围,得到各个矿区安全风险处于何种等级,并提出相应的整改意见,见表2。

表2 煤矿安全风险等级划分Table 2 Grading risk of coal mine safety
3.3 算法仿真与分析
模型中训练用到的数据集为煤矿实际数据。该数据集由1 000张样本组成,每个样本包含36个隐患评估值,图10展示了一个样本的数据组成。本实验室的超参数设置如下:动量系数为0.8,初始学习率设置为0.01,学习率为0.1,权值衰减系数为0.001。
采用改进的tiny-YOLO为深度学习框架,由此搭建实验室运行环境,本实验室平台软硬件的配置如下:Darknet网络框架;8核GPU;Linux操作系统;32G内存;Inter i7中央处理器。通过未使用神经网络、使用普通的CNN网络和改进的并行神经网络3种不同数据处理方式试验比较,得出各网络模型数据处理性能的优劣,对比结果见表3。其中,准确率为准确判断风险级别的数据条数与处理数据条数的比值;训练时间为处理全部测试数据用时。

表3 各网络模型数据处理性能对比Table 3 Data performance comparison of each network model
从表3可以看出,由这3种处理数据的方式得到的准确率分别为73.5%、81.2%、90.7%,试验结果说明数据经过神经网络处理后,能够提升最终的安全隐患评估值的精度,且提出的并行神经网络的效果优于普通网络。在处理相同数据量的情况下,由于并行神经网络结构比较复杂,会增加一定的计算量,因此最终的训练时间也有所增加。表5为各卷积核对并行网络模型的影响,其中,准确率为准确判断风险级别的数据条数与处理数据条数的比值。从表4可以看出,并行网络模型中卷积核大小选取1×1、3×3、5×5,得到的准确率分别为81.2%、90.7%、83.5%,即选取卷积核为3×3可以达到更好的测试效果。

表4 各卷积核对并行网络模型的影响对比Table 4 Comparison of effects of convolution kernels on parallel network models

表5 相同条件下2种系统查全率和查准率的对比结果Table 5 Comparison of recall and precision of two systems under same conditions
4 实验室分析与应用
为验证基于改进PSO和CNN的煤矿安全风险智能分级管控与信息预警系统的实用性、可靠性,在某煤矿集团的9个矿区进行了试验。每个矿区在每一时间点提取 9 条数据,多个时间点采集,共81 000条实时记录数据,平均分为10组进行数据处理。实验室中将每组数据输入到基于改进PSO的智能数据筛选模型中,进行数据的初步筛选。然后从每个矿区筛选后的数据中随机选出4条数据,作为基于改进CNN的智能风险分级模型的输入数据,经过该算法后,计算出各矿区的安全风险精确评估值,并对比安全风险范围划分得出安全风险的等级。计算在使用该系统和何桥提出的方法评估数据的查全率和查准率。查全率为准确判断风险级别数据条数与全部初始数据条数的比值;查准率为准确判断风险级别数据条数与实际查找到的数据条数的比值。
通过表5的对比可以得出,笔者提出的安全风险智能分级管控系统在查全率和查准率上取得了较大幅度的提升,本系统解决了安全风险分级精确度不高的问题,适合煤矿企业用于安全隐患预警。
在此之前,有关安全隐患预警方面的信息只是简单记录下来,并未对数据进行分析、展示、提出相应的排查安全隐患的措施,使得工作人员不能以一种高效的方式处理安全隐患,导致安全事故频发。本系统的应用实现了隐患数据直观展示,并针对精确的安全风险分级情况,给出相应的整改意见,大幅提升了煤矿作业的安全性、可靠性。
煤矿安全风险智能分级管控与信息预警系统已于2018年1月份投入到某煤矿企业中使用,该企业某矿区某一时间段的矿井隐患级别分类统计图如图11所示。制订的《煤矿安全规程》部分条例截图(图12)对出现的安全风险问题提供了整改建议,供工作人员参考。

图11 矿井隐患级别分类统计Fig.11 Statistics of grading mine risk level

图12 煤矿安全条例查询Fig.12 Regulations of coal mine safety
5 结 论
1)煤矿安全风险智能分级管控与信息预警系统使用改进的PSO算法构建智能数据筛选模型,从初始的数据中筛选掉不正常的数据,这部分数据可能是人工计算不准确或者采集矿区信息的过程中出现纰漏造成的,经过这一模型处理之后,确保了下一步对安全风险等级的正确计算判断。
2)使用改进的CNN算法构建智能风险分级模型,实现了对矿区安全风险精确分级的功能。
3)该系统实现了对煤矿安全风险分级、预警显示、风险问题统计图查看、整改建议提示等功能,解决了煤矿安全风险等级划分不精确的问题,有效减少了安全隐患发生的频度。实验室结果与企业使用情况证明了该系统的可靠性与实用性。
猜你喜欢
中国煤炭工业(2019年1期)2019-06-17
测控技术(2018年10期)2018-11-25
劳动保护(2018年8期)2018-09-12
浙江工业大学学报(2017年5期)2018-01-22
中国医疗保险(2017年6期)2017-07-18
中国卫生(2016年5期)2016-11-12
中国卫生(2015年10期)2015-11-10
中国卫生(2015年6期)2015-11-08
江西煤炭科技(2015年2期)2015-11-07
河南科技(2014年24期)2014-02-27
