
改进CBAM的轻量级注意力模型
2021-10-28 05:53付国栋郑思宇
计算机工程与应用 2021年20期
付国栋,黄 进,杨 涛,郑思宇
西南交通大学 电气工程学院,成都 611756
近几年深度卷积神经网络(Convolutional Neural Networks,CNNs)高速地推动着计算机视觉的发展,其在图像分类[1-6]、目标检测[7-9]、语义分割[10-11]、目标跟踪[12]等任务中展示着强大力量。为了进一步增强CNNs的特征表达能力,最近的研究主要聚焦在网络的三个重要因素:深度、宽度和基数。
从AlexNet[1]开始到目前为止,CNNs网络通过不断地叠加卷积操作,使得网络深度更深,以获得优秀的特征表达能力。ResNet[2]将相同的残差块叠加起来,构建了一个非常深的网络结构,极大提高了CNNs性能。GoogLeNet[3-5]通过实验证明网络宽度同样是提高模型性能的另一个重要因素。ResNeXt[6]则从网络的基数入手,证明基数不仅可以减小网络模型的复杂度,而且比深度和宽度对网络模型的提升效果更加明显。
除了以上三个因素外,近几年许多研究人员将注意力机制融入卷积模块,证明注意力机制在对网络性能改进方面拥有巨大的潜力。Hu等人提出了SE(Squeeze-Excitation)模块[13],它学习特征图中各个通道间的关联关系,生成通道注意力,让网络更加关注信息丰富的通道,为CNNs带来明显的性能提升。CBAM(Convolutional Block Attention Module)模块[14]则在SE模块基础上进行了进一步的扩展,该模块将特征图按通道进行全局池化,获得空间注意力;通道注意力让网络关注图像“是什么”,而空间注意力则让网络关注图像中物体“在哪”。BAM(Bottleneck Attention Module)[15]则采用并联的方式将空间注意力和通道注意力整合。Wang等人提出的Non-Local[16]模块则通过θ、ϕ、g三个操作产生关于特征图的全局注意力,并且成功融入三维卷积神经网络中,在视频分类任务中效果提升明显。Fu等人提出的DANet[17]则探索了输入特征图中各位置和各通道间的互相关性,分别生成全局空间注意力和通道注意力,该模型在语义分割任务中提升效果明显。Li等人提出的SK(Selective Kernel)[18]结构则将SE的思想和残差网络相结合,能够让网络根据特征图的不同尺度动态地选择不同的感受野,进一步扩展了对注意力机制的研究。
尽管上述注意力模型从不同的角度提升了CNNs的特征表达能力,但同时也给网络增加了大量开销。以目前广泛应用的SE和CBAM为例,它们通过全连接层生成通道注意力,其参数量与输入特征图的通道数平方成正相关,在深层的网络中,往往特征图的通道数量很大,因此融入注意力带来的开销也很庞大,这在需要实时性的应用场景中得不偿失。针对此问题,本文在目前性能最优且通用的CBAM模型的基础上,提出了一种轻量级的注意力模型——EAM(Efficient Attention Module),该模型摒弃了计算量巨大的全连接层和大卷积核,使用一维卷积和空洞卷积分别来聚合通道和空间信息,使得模型的参数量大幅缩小。本文将EAM融入YOLOv4[9]目标检测模型中,在VOC2012[19]数据集上进行实验测试,检测效果明显提高,取得了媲美YOLOv4融合CBAM模型的效果。本文的主要贡献如下:
(1)本文引入一维卷积和空洞卷积分别对CBAM中的通道注意力和空间注意力做了优化改进,提出了EAM注意力模型,将整个注意力模块的参数量减小到常数级别。
(2)本文将改进后的轻量级模型EAM融入YOLOv4目标检测模型的特征融合部分,显著提高YOLOv4算法的检测精度,并通过消融实验分析论证了EAM的优越性。
1 CBAM与YOLOv4结构介绍
1.1 CBAM
CBAM是一种简单而有效的卷积神经网络注意力模块。在卷积神经网络中任意给定一个中间特征图,CBAM将注意力映射沿特征图的通道和空间两个独立的维度进行注入,然后将注意力乘以输入特征映射,对输入的特征图进行自适应特征细化。因为CBAM是一种端到端的通用模块,它可以无缝地集成到任何CNNs架构中,并且可以与基本CNNs一起端到端训练。CBAM中的通道注意力和空间注意力的结构如图1所示。
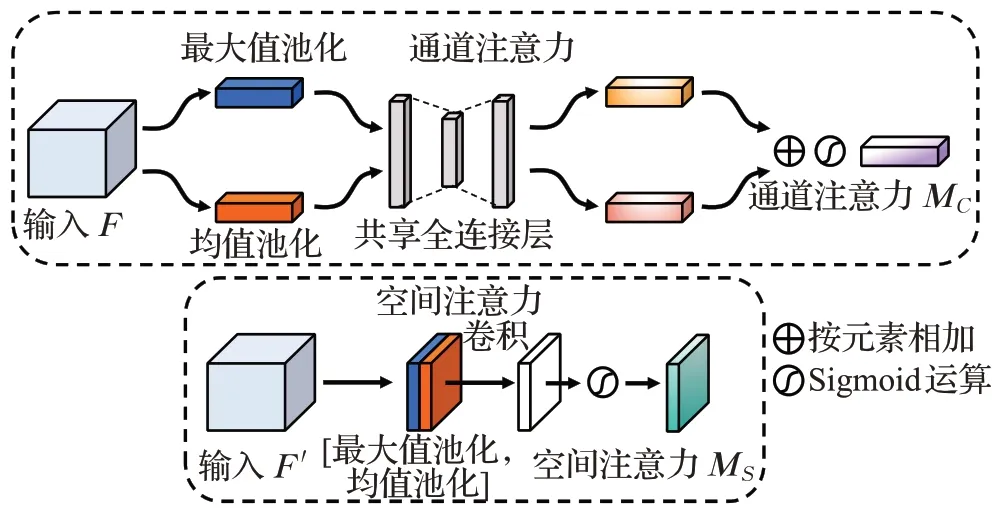
图1 CBAM中通道注意力和空间注意力结构Fig.1 Channel attention and spatial attention structure in CBAM
给定一个中间特征图F∈RC×H×W作为输入,CBAM模块的运算过程总体分为两个阶段:首先对输入按通道进行全局最大值池化和均值池化,将池化后的两个一维向量送入全连接层运算后相加,生成一维通道注意力M C∈RC×1×1,再将通道注意力与输入按元素相乘,获得通道注意力调整后的特征图F′;其次将F′按空间进行全局最大值池化和均值池化,将池化生成的两个二维向量拼接后进行卷积操作,最终生成二维空间注意力M S∈R1×H×W,再将空间注意力与F′按元素相乘。具体运算流程如图1所示,CBAM总体生成注意力过程可描述为:

其中⊗表示对应元素相乘,在相乘操作前,通道注意力和空间注意力分别需要按空间维度和通道维度进行广播。
1.2 YOLOv4结构
YOLOv4是从YOLOv3的基础上改进而来,属于一阶段目标检测算法,其总体结构如图2所示。YOLOv4使用CSPDarknet53作为主干网络,在CSPDarknet53中含有大量残差边,增加了网络宽度,训练时更加利于梯度的反向传播。假设YOLOv4输入416×416的图像,经过主干网络进行特征提取,则获得13×13、26×26、52×52的三组特征图,针对13×13的特征图,首先使用空间金字塔池化(Spatial Pyramid Pooling,SPP)结构进行特征融合,在SPP中使用多种尺寸的池化核对特征图进行池化处理,可以在没有显著降低网络推理速度的情况下,提高感受野,分离出最有意义的上下文特征。随后对三组不同级别的特征图使用路径聚合网络(Path Aggregation Network,PANet)进行特征融合。相比于特征金字塔网络(Feature Pyramid Network,FPN),PANet额外增加了一条自下向上的特征融合路径,使得特征图融合的语义更加丰富,其特征表达能力也更强。最后,经过特征融合后的三组特征图的每个位置预测3个边界框,若数据集中含有k个类别,那么对于每个边界框将预测3×(5+k)个值,其中前4个值为(t x,t y,t w,t h),用来确定边界框的位置,第5个值s则表示该边界框中存在目标的置信度。
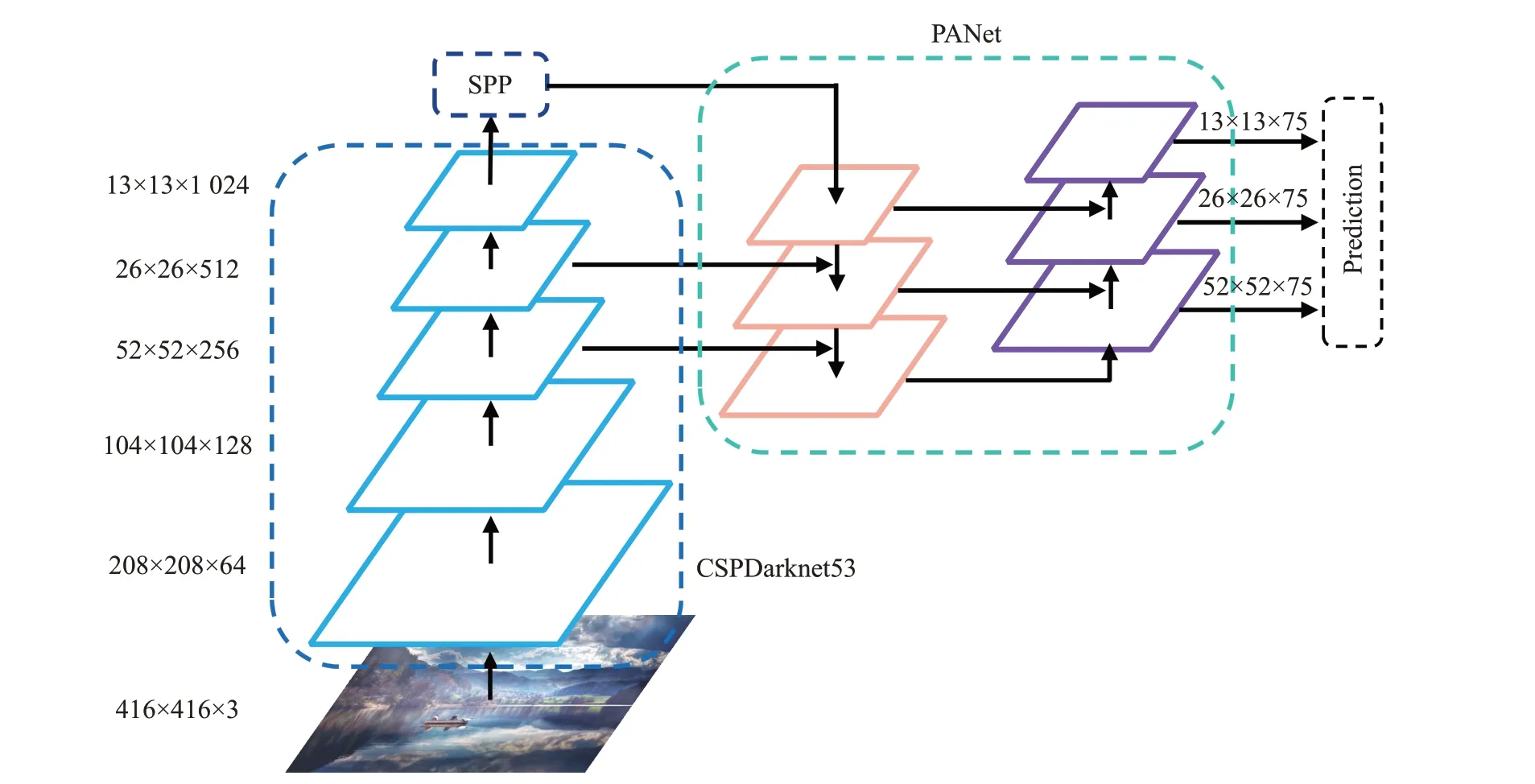
图2 YOLOv4总体结构(输入图片大小为416×416,类别数为20)Fig.2 Overall structure of YOLOv4(input image size is 416×416,number of categories is 20)
2 EAM及融合EAM的YOLOv4
2.1 EAM
CBAM在计算生成通道注意力时,使用全连接层对特征进行映射,然而全连接层的计算量巨大,即使在设计共享全连接层时首先对通道特征压缩r倍,共享全连接层的参数量仍然与输入特征图通道数的平方成正相关;另外在空间注意力模块中,为了聚合更广泛的空间上下文特征,使用一个7×7的大感受野卷积核来聚合空间特征,相比于使用3×3的小卷积核,这在增大了感受野的同时,模块的参数量也随之增大。因此当在一个卷积神经网络中大量插入CBAM模块时,网络参数量会大量增长,这也限制了该模块的应用场景。针对此问题,本文借鉴了文献[20]的思想,认为在CNNs中任意给定的中间特征图,其相邻通道间的相关性更大,使用全连接层对通道特征进行映射会产生许多冗余计算。因此本文设计使用一维卷积操作来对一维通道注意力进行通道特征聚合,一维卷积核的大小即为聚合邻域内通道数的数量,由于卷积操作的参数共享性质,引入一维卷积使得通道注意力模块的参数量下降到常数级。对于空间注意力,与CBAM中的思想相同,认为卷积操作的感受野大小决定了空间注意力的性能,大的感受野能聚合更加广泛的上下文信息,使得空间注意力的表征能力更强。因此本文使用空洞卷积来对二维空间注意力进行空间特征聚合,使得在同等大小感受野的情况下,减小了模块参数量。本文将改进后的模块叫做EAM(Efficient Attention Module),EAM模块的总体结构如图3所示。

图3 EAM总体结构Fig.3 Overall structure of EAM
2.1.1 通道注意力模块
与CBAM模块的思想相同,本文使用通道注意力让网络关注给定图像“是什么”。为了有效地计算通道注意力,首先使用全局均值池化和最大值池化操作来聚合特征映射的空间信息,生成两个不同的通道描述符和,分别表示均值池化特征和最大值池化特征。与CBAM中使用全连接层聚合通道特征不同,本文选择使用卷积核长度为k的一维卷积来聚合该通道邻域内的k个通道的信息。将卷积后的两个特征按元素相加,并通过Sigmoid函数运算,生成通道注意力,随后将生成的通道注意力沿空间上的两个维度进行广播扩充至RC×H×W,再与输入特征图按对应元素相乘获得注入通道注意力后的特征图。具体地,通道注意力计算过程可如下表示:
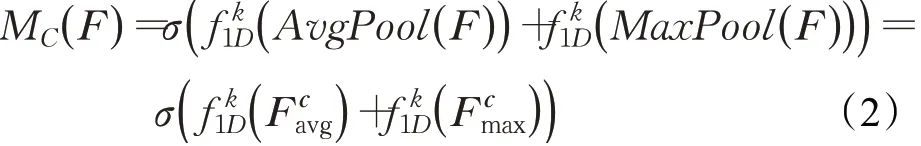
其中,σ表示Sigmoid函数,表示卷积核大小为k的一维卷积操作。k的大小由文献[20]中的方程自适应决定:

C表示输入特征图的通道数,||todd表示与t最接近的奇数。
2.1.2 空间注意力模块
本文利用特征图中的空间关系生成空间注意力,空间注意力作为通道注意力的补充,使网络关注图像的有用信息“在哪里”。空间注意力模块首先沿输入特征图的通道轴进行全局均值池化和最大值池化操作,生成两个不同的空间上下文描述符和,并将分别生成的描述符沿通道轴进行拼接,生成一个有效的空间特征描述符。随后使用空洞卷积来对空间中需要强调或抑制区域信息进行编码映射,更加高效地聚合空间上下文信息,将卷积后的特征经过Sigmoid函数运算生成空间注意力。最后将生成的空间注意力沿通道维度广播扩充至RC×H×W,再与输入特征图按对应元素相乘获得注入空间注意力后的特征图。具体地,空间注意力计算过程可如下表示:
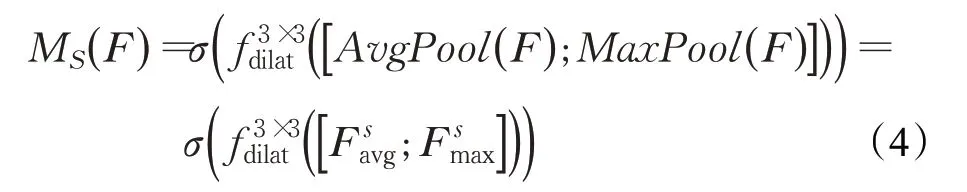
其中,表示卷积核大小为3的空洞卷积,实验使用空洞率为2的空洞卷积。
2.2 融合EAM的YOLOv4
由于本文提出的EAM模型是一个通用的CNNs模块,它可以插入网络中的任意位置,本文将注意力模型融入YOLOv4网络中主要遵循以下两点原则:
(1)不显著增加网络的复杂度。因为YOLOv4本身属于一阶段网络,为满足实时性目标检测而设计,因此不必在整个网络中每个位置添加注意力模型。同时网络在训练时应方便加载CSPDarknet的预训练权重,减少网络的训练时间。
(2)在深度卷积神经网络中,浅层的特征比较具有通用性,它符合图像广泛的一般性特征;而深层特征更加抽象和复杂,其表征能力也更独特,更加适合融入注意力调整。
根据以上两点原则,本文不修改YOLOv4的主干网络CSPDarknet的结构,选择将注意力引入PANet结构中,在同级别的特征图进行卷积操作后注入注意力,融合注意力模块的PANet结构如图4所示。

图4 注意力模型融入PANetFig.4 Attention model integrated into PANet
3 实验结果与分析
3.1 实验数据集及评价指标
本文将融入注意力模型的YOLOv4目标检测算法进行实验论证,实验数据集选择使用VOC2012公开数据集。该数据集共包含飞机、自行车、鸟、船、汽车等20个类别,在该数据集中,含有5 717个训练样本和5 823个验证样本。
实验选择参数量和平均精确率(Average Precision,AP)[20]两个评价指标。参数量用来描述目标检测算法模型的复杂度,特别地,本文以YOLOv4的参数量为基准,融入注意力模型后整个网络结构的参数增量来评价模型的复杂度。AP被定义为不同召回率下的平均检测精度,通常以特定类别的方式进行评估,AP用来描述目标检测模型的性能。为了比较目标检测算法对所有对象类别即整个数据集的检测效果,使用所有类别AP的均值(mAP)作为目标检测算法性能的最终度量。在计算mAP的过程中,为了测量对象定位精度,判断目标预测的包围框是否正确,使用交并比(Intersection over Union,IoU)来衡量预测框和目标真实框之间的误差。预定义一个IoU阈值,如果预测框和真实框的IoU大于该阈值,则目标将被认为成功检测,否则将被标识为误检。实验计算mAP时,取IoU阈值为0.5。
3.2 融合注意力模型的YOLOv4实验测试
本文在YOLOv4中的PANet部分分别融入SE(记为YOLOv4+SE)、CBAM(记为YOLOv4+CBAM)、EAM(记为YOLOv4+EAM)模块进行对比实验。目标检测网络的输入大小固定为416×416,训练时对图片采取随机水平翻转和亮度调节的数据增广方法,选择Adam优化器对网络参数进行优化,β1设为0.9,β2设为0.999,训练批次大小设为8,训练时加载YOLOv4主干网络的预训练模型,首先冻结主干网络的参数训练20个周期,学习率设置为1E-3,随后解冻整个网络对全局参数进行微调15个周期,学习率设置为1E-4。所有算法均使用tensorflow2.2深度学习框架实现,实验硬件环境CPU为IntelⓇXeonⓇGold 6278C@2.60 GHz,GPU为Tesla T4@16 GB。
实验对SE和CBAM模块中全连接层的通道压缩率设置为16,YOLOv4与三种改进模型在VOC2012数据集上测试结果如表1所示。由表1可以看出,YOLOv4融合本文提出EAM注意力模型后,在VOC2012数据集上测试,mAP显著提高3.48个百分点。并且本文提出的EAM注意力模型相比于SE和CBAM的参数量显著减小,对比SE和CBAM可以发现主要是因为全连接层使得注意力模型的参数量显著增加。另外EAM在引入微量参数的情况下,网络的性能提升显著,分析认为因为在SE和CBAM模块生成通道注意力的过程中,首先使用全连接层来对通道数量进行了压缩,此过程丢失了部分特征信息,而一维卷积并未进行通道压缩而效果更好,在3.3节中会深入分析通道注意力中一维卷积和空间注意力中空洞卷积的优势。

表1 融入注意力模型的YOLOv4实验结果对比Table 1 Experimental comparison of YOLOv4 incorporating attention module
针对单个类别,四种算法在VOC2012数据集上的测试实验结果如图5所示。由图表可以看出,在VOC2012数据集上,YOLOv4对于椅子和餐桌两个类别的检测效果相对较差,在融入注意力模型后,对于这两个类别的检测效果明显提升。浏览数据集发现数据集中的椅子和餐桌样本通常与其他类别的样本有较多重叠,并且包含困难样本较多,分析认为YOLOv4在融合注意力模型后能够显著提高网络的特征表达能力,因此网络对两个类别的检测效果明显提升。另外,YOLOv4在融合本文提出的EAM注意力模型后对船、盆栽、沙发这三个类别的检测精度相比较融入其他注意力模型有明显提高。分析认为主要原因在于三种类别的样本在VOC2012数据集中数量较少,在PANet中融合EAM注意力能够显著提高网络的特征表达能力,增强网络对少样本的学习能力,提高网络的检测性能。
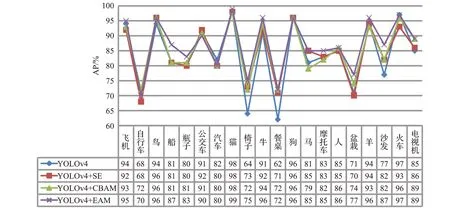
图5 YOLOv4及三种改进算法在VOC2012数据集上检测结果对比Fig.5 Comparison of detection results of YOLOv4 and three improved algorithms on VOC2012 data set
本文对YOLOv4及融合CBAM和EAM后的检测结果进行了可视化对比,对比结果如图6所示,根据对比可以发现YOLOv4在融合EAM注意力模型后对遮挡较为严重的目标检测效果明显提高,并且目标置信度也有小幅提高。由图6(d)、(e)、(f)三个检测结果对比可以发现在复杂的环境条件下,YOLOv4在融合本文提出的EAM注意力模型后,网络的检测效果提升显著。

图6 YOLOv4及其改进算法检测效果可视化对比Fig.6 Visual comparison of detection effect of YOLOv4 and its improved algorithm
3.3 消融实验
3.3.1 通道注意力
实验只保留CBAM和EAM模块中的通道注意力,舍弃两个模块中的空间注意力,依然将保留的通道注意力模块融入YOLOv4的PANet结构中,在VOC2012数据集上进行测试,只保留通道注意力设计了三组实验来验证EAM通道注意力的有效性:
(1)使用共享全连接层聚合通道特征,压缩率取r=16,用CBAM-C表示。
(2)直接使用一层含C个(输入通道数)神经元的全连接层聚合通道特征,用CBAM-C+表示。
(3)使用一维卷积聚合通道特征,用EAM-C表示。
实验结果如表2所示。

表2 CBAM与EAM中通道注意力模块对比Table 2 Comparison of channel attention modules in CBAM and EAM
由表2可知,在CBAM生成空间注意力过程中为了减小模块的参数量,首先使用了r倍压缩率的全连接层对通道进行聚合压缩,对比直接使用一层全连接层对通道信息进行聚合的效果,后者虽然舍弃了一个全连接层,但是mAP提高了0.85个百分点。分析认为是因为CBAM引入了对通道进行特征压缩的过程,该过程虽然使得模块的运算量减少,同时也舍弃了特征图的部分信息,使得通道注意力的特征表达能力下降。对比EAM的通道注意力,由于直接对全局池化后的通道特征进行一维卷积,并没有对特征进行压缩,整个特征图的通道信息得以完整保留,因此生成的通道注意力比CBAM效果更好,但由于一维卷积只聚合了k个邻域通道的信息,相比于直接使用全连接层进行特征映射效果略微下降。另外,使用全连接层聚合通道信息,在参数量大量增长的情况下,模型的检测效果并未获得显著性提高,这也证实在特征图中相邻通道间的信息依赖关系更强,使用全连接层聚合所有通道信息存在大量冗余运算。
3.3.2 空间注意力
实验只保留CBAM和EAM模型中的空间注意力模块,舍弃模型中的通道注意力,来测试空洞卷积的有效性。仍然将保留空间注意力模块融入YOLOv4的PANet部分,在VOC2012数据集上进行测试,只保留空间注意力设计了四组实验:
(1)使用卷积核大小为7×7的标准卷积,用CBAM-S表示。
(2)使用卷积核大小为3×3,空洞率为2的空洞卷积,用EAM-S表示。
(3)使用卷积核大小为7×7,空洞率为2的空洞卷积,用EAM-S+表示。
(4)使用两次卷积核大小为3×3,空洞率为2的空洞卷积,用EAM-S++表示。
实验结果如表3所示。

表3 CBAM与EAM中空间注意力模块对比Table 3 Comparison of spatial attention modules in CBAM and EAM
由表3可知,对比使用7×7的标准卷积和7×7空洞卷积的实验结果,论证了在卷积聚合空间信息过程中,感受野越大,能聚合的空间上下文信息越丰富,对空间特征的编码能力越强,映射生成的空间注意力效果越好。空洞率为2的3×3的空洞卷积与7×7的标准卷积拥有相同的感受野,两者的效果近似,但前者的参数量只有后者的9/49。另外由第二组和第四组实验结果对比发现堆叠多个卷积层同样能提高空间注意力的特征表达能力。
4 结束语
基于CBAM注意力模型,本文提出了一种轻量级的通用注意力模型EAM,该模型使用一维卷积来聚合通道信息生成通道注意力,使用空洞卷积来聚合空间上下文信息生成空间注意力,极大地减少了注意力模型的参数量。本文将EAM融入YOLOv4网络中进行实验测试,实验结果证明该注意力模型只需要付出少量参数的代价,模型检测的效果可以显著提高。未来将进一步探索EAM模块在CNNs其他领域的应用,如实例分割、目标跟踪等。
猜你喜欢
科学技术与工程(2023年3期)2023-03-15
小雪花·成长指南(2022年1期)2022-04-09
软件导刊(2022年3期)2022-03-25
新一代信息技术(2021年22期)2021-12-29
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
计算机技术与发展(2019年1期)2019-01-21
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
