基于磁共振扩散张量成像的机器学习模型对帕金森病人的识别
2021-10-28 10:00李静范文亮雷子乔余建明
中国医疗设备 2021年10期
李静,范文亮,雷子乔,余建明
1.华中科技大学同济医学院附属协和医院 放射科,湖北 武汉 430022;2.分子影像湖北省重点实验室,湖北 武汉 430022
引言
帕金森病(Parkinson’s Disease,PD)主要以黑质多巴胺能神经元进行性退变和路易小体形成的病理变化,纹状体区多巴胺递质降低、多巴胺与乙酰胆碱递质失平衡的生化改变,以动作迟缓、静止性震颤和肌张力增高临床表现为显著特征,是一种常见的中老年神经系统退行性疾病[1-2]。随着年龄增长,患病率逐年增高,80岁以上人群患病率超过 3%[2-3],带来巨大的社会和医疗负担,PD的早期诊断对治疗和预后影响重大。
随着人工智能在医学各应用场景下的落地,智能医学影像取得飞速发展,有效提高医学影像对于疾病的筛查、诊断和治疗决策功能[4-5]。一方面在个体水平上满足了疾病精准诊疗的需求,另外一方面也能为疾病的智能诊断发掘潜在的影像学标记[6-7]。目前基于多模态影像的PD分类研究,样本量一般较少[8-10],影响模型的泛化能力。为探索基于弥散张量的PD神经影像学标志物,为PD的诊疗提供影像依据,本研究基于较大的样本量,使用机器学习方法,利用 磁共振扩散张量成像(Diffusion Tensor Imaging,DTI) 脑影像的4个指标作为数据特征,构建区分PD患者和健康对照者的机器学习模型,寻找 PD可能的神经影像学标记物,以期为 PD 的临床诊疗提供更多线索。
1 材料与方法
1.1 临床资料
收集2015年6月至2019年12月在本院神经内科就诊的PD患者289例,同时期收集健康对照志愿者131例。纳入标准:① 符合临床诊断的PD;② 右利手;③ 获得病人或家属的知情同意并能够配合完成所涉及的量表评估及磁共振研究。排除标准:① 可能存在精神障碍病史的(包括痴呆,精神分裂症,双相情感障碍等);② 既往有物质(毒品、酒精或其他精神活性物质)滥用史;③ 磁共振上有明显器质性病变或其他神经系统疾病;④ 合并其他严重的躯体疾病; ⑤ 对检查不合作或不能有效完成测验者。420 例受试者按 7:3 随机分为训练集294 例和测试集 126 例。训练集及测试集中两组性别和年龄比较差异均无统计学意义(P值均>0.05)。两组组内 PD 患者和健康对照人群性别和年龄比较差异均无统计学意义(P值均>0.05)。本研究经华中科技大学同济医学院伦理委员会批准,所有被试者在磁共振扫描前签署知情同意书。
1.2 仪器与方法
所有被试者采用西门子3.0 T超导磁共振(Siemens-Trio Tim)12通道头部线圈进行MRI数据采集。被试者平躺在检查床上,头部用软垫从两侧固定,以减少扫描过程中被试者的头部运动,同时双耳塞入棉塞以减少扫描过程中的噪音。扫描序列包括用于头部常规临床序列:T1WI、T2WI及 FLAIR序列,以及本研究所需的高分辨T13D序列(磁化准备快速梯度回波序列)及DTI 扫描序列。高分辨T13D序列参数如下:回波重复时间(Repetition Time,TR):2250 ms,回波时间(Echo Time,TE):2.26 ms,翻转时间(Time-Reversal,TI): 900 ms,翻转角 9°,视野(Field of View,FOV):256 mm × 256 mm,采集矩阵:256 ×256,体素大小 :1.0 mm × 1.0 mm × 1.0 mm,矢状位扫描176 层。DTI 序列使用的是单次激发自旋回波平面成像序列,参数如下:回波TR:6000 ms,TE:93 ms,翻转角 :90°,B =1000 s/mm2,64 个方向(加上一个 B=0 的图像共计 65 个全脑图像),体素大小:2.0 mm × 2.0 mm× 2.0 mm,FOV:200 mm × 200 mm,采集矩阵大小:128 × 128,平行前后联合轴位采集,包含全脑采集 44 层。
数据处理及机器学习模型构建流程图如图1所示。DTI 数据处理使用MATLAB平台下集成FSL工具包的PANDA[11]软件(http://www.nitrc.org/projects/panda),包括数据格式转换、运动及涡流校正、弥散张量参数计算等。具体为使用FMRIB里面的FLIRT工具包对弥散加权图像进行运动校正和涡流伪影校正。校正之后的图像使用Brain Extraction Tool(BET)工具包剥除非脑组织成分。最后使用FSL提供的DTIFIT工具包计算每个被试个体脑空间中每个体素的各向异性分数(Fractional Anisotropy,FA)、平均扩散率(Mean Diffusivity,MD)、轴向弥散系数(Axial Diffusivity,AD)、径向弥散系数(Radial Diffusivity,RD)值。最后将个体空间的各弥散参数指标图像,通过空间标准化,投射到标准空间,使用Mori的2008年ICBM-DTI-81白质模板,提取每个被试50个核心脑区的FA、MD、AD及RD值。
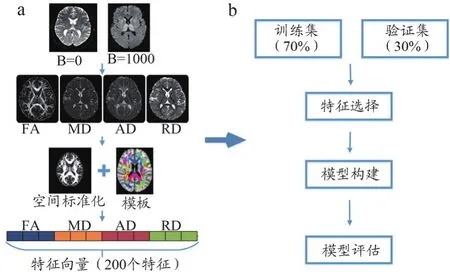
图1 实验方案流程图
将提取的每个被试50个脑区的FA、MD、AD及RD值顺序连接,构成一个200维的向量,此向量即为后续进行数据降维与建模分析的原始数据。本研究使用5种机器学习分类器来构建PD分类识别模型,包括Logistic、GLM_LASSO、GLM_PCA、SVM_Linear、naïve Bayes。首先对数据进行归一化处理,将原始数据映射到0-1 之上;为了避免特征值过多导致的过拟合,进行特征筛选;使用机器学习分类模型的方法进行训练;根据训练出来的模型对测试集进行预测,获得相关受试者工作(Receiver Operating Characteristic,ROC)曲线以及曲线下面积(Area Under Curve,AUC),同时获得对预测有贡献的特征定位,得到有贡献的脑区。
1.3 统计学分析
采用 SPSS 22.0 统计软件对各变量进行统计分析。计量资料以(±s)表示,组间比较采用独立样本t检验。计数资料组间比较采用χ2检验。P<0.05 为差异有统计学意义。
2 结果
2.1 训练集和测试集的一般人口学资料比较
本研究共纳入420名受试者,其中PD患者289例,健康对照131名。按照7:3 分为训练集和测试集后,其中训练集共计294 名,包括PD 患者202 例,年龄(65.5±10.6)岁,男性132 名;健康对照92 名,年龄(63.7±12.7)岁,男性61 例。测试集共计126 名,包括PD 患者87 名,年龄(65.3±11.9)岁,男性57 名;健康对照39 名,年龄(63.5±13.6)岁,男性24 名。组间在年龄和性别分布上没有显著的统计学差异。
2.2 不同机器学习模型的性能
构建的不同机器学习PD分类模型性能表现如表1所示,SVM_Linear模型在训练集和测试集上的表现优于其他模型,其中训练集上的AUC为0.897,准确度为0.867,特异度为0.89,敏感度为0.833;在测试集上的AUC为0.878,准确度为0.853,特异度为0.884,敏感度为0.793。经过特征选择后,SVM_Linear模型共使用12个DTI参数构建分类模型,这些参数包括胼胝体膝、右侧脑脚、右侧下辐射冠、左侧扣带回、右侧穹窿、左侧毯的FA值,右侧钩束的MD值,右侧内囊前肢、左侧上辐射冠、左侧扣带回、左侧毯的AD值,右侧穹窿的RD值。各特征重要性排序如图2所示,特征之间的相关系数及聚类分析如图3所示。
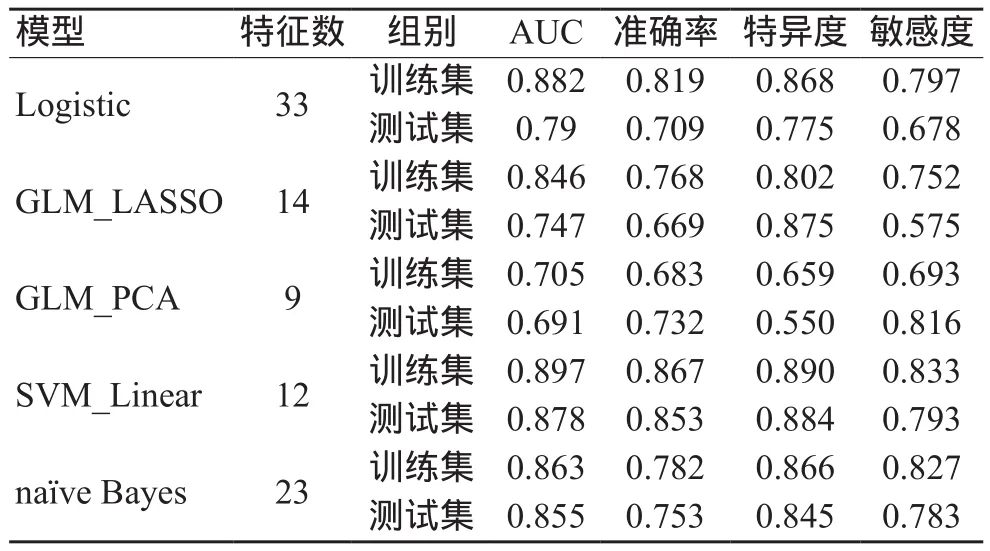
表1 不同机器学习模型的PD分类性能表现
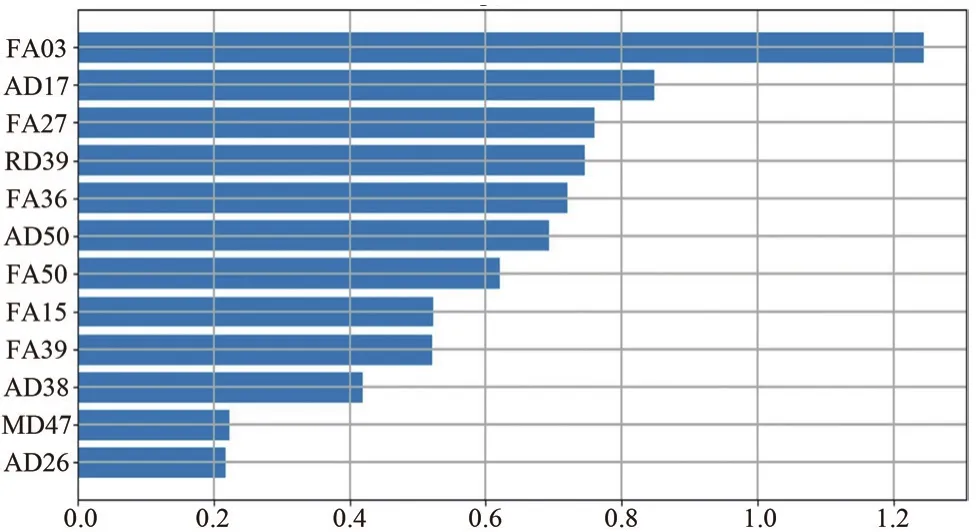
图2 SVM_Linear模型各特征重要性排序
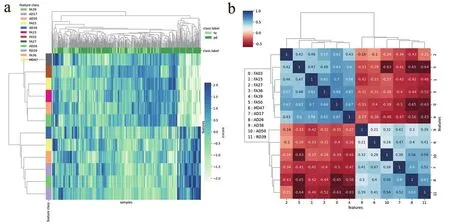
图3 各特征之间的相关系数及聚类分析
3 讨论
随着人工智能技术的发展,基于影像的临床疾病分类方法被广泛应用于各类神经[12-13]及精神疾病的研究[4-5]。本研究基于DTI常用参数(FA、MD、AD、RD 值),经过特征筛选的降维方法,构建了用于PD与健康对照的不同机器学习方法,探讨可用于PD的影像标记物。结果表明,使用12个脑区DTI参数构建的SVM_Linear分类模型在训练集和测试集上都具有良好的分类效能。
本研究中构建的机器学习分类模型,发现胼胝体、扣带回、辐射冠、穹窿等脑区对分类模型有贡献,提示我们PD患者可能在这些脑区存在白质完整性的异常,这也和先前的报道中PD患者放射冠区、胼胝体、丘脑等在内的脑区存在广泛的白质结构改变相一致[13-16],结合其他基于DTI数据构建脑网络并结合机器学习方法对PD进行分类的研究[17-18]一起表明,这些脑区有作为PD影像诊断标记物的潜力[19-20]。当然,考虑到在不同的模型中,不同的脑区的模型贡献度差别很大,所以在实际应用中,如何利用这些影像标记物的脑区,还需要进一步研究。
本研究中构建的模型在训练集和测试集上敏感度、特异度与准确率均有不错的表现,说明构建的模型没有出现过拟合现象,具有一定的泛化能力,不同模型最终选定的特征数差别较大,提示我们在构建机器学习模型时,需要考虑模型性能与复杂度之间的非线性关系。同时,我们发现并不是所有PD与健康对照有差异的参数指标经过特征筛选后被保留下来,推测可能是不同DTI参数之间存在多重共线性,或者是由于具有差异的指标,不一定都对模型构建有贡献。
本研究仍然存在一定的局限性。首先,为了获得更大的样本集以及构建泛化能力较强的机器学习模型,在本研究中将不同病程分期的PD病人合并到一组,可能会影响PD病人组样本的同质性;其次,本研究主要构建的是基于脑区水平的机器学习模型。在以后的研究中,可以利用基于神经网络的深度学习模型,探索构建体素水平的PD分类模型。
4 结论
基于DTI数据特征向量构建的机器学习分类模型,能有效区分PD患者和健康对照者。PD患者大脑胼胝体、扣带回、穹窿等大脑区域的DTI参数,有作为PD神经影像学标志物的潜力,用于辅助PD的临床诊疗。
猜你喜欢
安徽医科大学学报(2022年11期)2022-11-01
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
数学小灵通(1-2年级)(2021年4期)2021-06-09
浙江大学学报(理学版)(2021年1期)2021-01-26
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
电影(2018年8期)2018-09-21
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
首都医科大学学报(2015年4期)2015-12-16