
基于孪生网络的双分支目标跟踪算法
2021-10-28 07:51:32许建龙
软件导刊 2021年10期
施 立,许建龙
(浙江理工大学 信息学院,浙江 杭州 310018)
0 引言
在计算机视觉领域,实时目标跟踪是一个极具挑战性的难题。区别于目标检测问题,目标跟踪给出一组图像序列初始帧任意目标的边界框,需要在后续帧中标出目标位置。高性能跟踪算法在视频监控、自动驾驶、人机交互等多个领域都有重要作用,然而真实场景中往往存在尺度变化、遮挡、背景杂乱等复杂条件干扰,设计一个能应用于工业领域的强鲁棒性实时跟踪算法具有很大难度[1,2]。
目前有两种目标跟踪算法框架受到普遍认可。基于相关滤波(Correlation Filter,CF)的跟踪算法在2010 年由Bolme 等[3]提出,其通过计算最小平方误差滤波(Minimum Output Sum of Squared Error filter,MOSSE),根据输入图像训练相关滤波器,在后续帧中通过计算图像与滤波器的响应确定跟踪目标所在位置。考虑到MOSSE 没有充分利用样本结构信息,同时缺乏高效密集采样策略,Henriques等[4]提出循环位移密集采样策略,同时使用核函数将问题映射到高维空间,并使用核戏法简化计算。为增强特征表达能力,Henriques 等[5]利用多通道HOG 进行特征表达,并利用对角化技术进一步优化计算过程;Danelljan 等[6]引入多通道颜色特征(Color Name,CN)并使用PCA 降维提取有效特征,提升了算法对形变目标的鲁棒性。
近年来,得益于深度学习领域的快速发展,深度特征凭借其优秀的表达能力逐渐取代手工特征,但深度特征在提升模型准确度的同时也增加了计算量,为基于深度学习的目标跟踪算法达到实时标准增加了难度。一种新颖的孪生网络使用共享权值的两个神经网络分别学习目标特征与搜索图特征,然后将跟踪视作相似性匹配问题,基于孪生网络的目标跟踪算法凭借其优异的跟踪性能吸引了大量业内学者关注。Tao 等[7]提出利用孪生网络模型离线学习匹配函数,然后对初始帧目标与后续帧候选样本进行相似度计算;Bertinetto 等[8]将互相关引入全卷积孪生网络,该算法不需要选取与模板同样大小的候选块,而是直接通过较大尺寸的搜索图特征与较小尺寸的模板特征进行互相关产生响应图以求得目标位置。最近,文献[9-13]利用孪生网络提取目标特征,然后利用目标检测领域的区域生成网络(Region Proposal Network,RPN)[14]确定最终目标边界框。文献[15]研究了深层与浅层特征的特性,以及它们对跟踪准确性和鲁棒性的影响,并指出深层特征能有效描述具有外观和杂乱不变性的高级语义信息,增强算法鲁棒性,而浅层特征能有效描述用于目标精准定位的低级外观信息。全卷积孪生网络目标跟踪算法SiamFC 未考虑深层与浅层特征各自的特点,仅使用网络最终输出对目标进行表达,难以发挥深度网络的全部价值。其简单地将目标跟踪视作相似性学习问题,忽视了不同跟踪场景下目标的变化,难以平衡特征表达的鲁棒性与判别性。
为解决上述问题,本文提出一种基于孪生网络的双分支目标跟踪算法,两个分支分别利用深度网络深层、浅层的特征优势,对目标语义信息和外观信息进行描述。此外,语义分支还通过引入注意力模块加强对目标区域的编码,降低背景区域干扰,最终融合独立训练外观分支与语义分支的响应结果以提升跟踪算法性能。
1 算法建立
本文提出一种基于孪生网络的双分支目标跟踪框架,网络包含提取浅层低级信息的外观分支与提取深层高级信息的语义分支。两个分支均使用VGG-16[16]作为主干网络,其中语义分支通过引入残差注意力模块增强目标表达,同时减少背景杂乱影响,最终通过加权融合两个分支生成的响应图实现鲁棒的目标跟踪。
1.1 双分支网络结构
双分支网络结构如图1 所示。网络输入分别为从初始帧裁剪的目标图像z和从当前待跟踪帧裁剪的搜索区域图像X,其中目标图像z的尺寸为Wz×Hz×C,搜索区域图像X的尺寸为Wx×Hx×C。

Fig.1 Two-branch network structure图1 双分支网络结构
1.1.1 外观分支
将图像对(z,X)输入外观分支,外观分支对图像提取特征得到特征图(φɑ(z),φɑ(X)),其中φɑ(·)表示外观分支的特征映射,然后通过相似度计算得到外观分支响应图为:
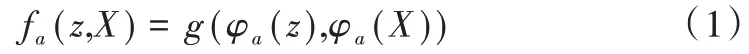
式中,g(·)为相似性度量。
然后使用logistic 损失表示训练样本的分类误差:
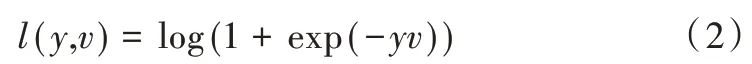
式中,v为候选位置响应值,y表示真实标签,取值为{+1,-1}。基于网络全卷积特性,仅对模板和搜索图求响应就能得到每个候选位置的响应值,然后对所有候选位置损失求平均得到响应图损失为:
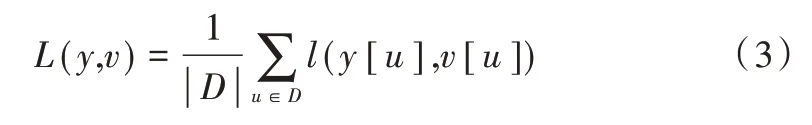
每个候选位置的真实标签y[u]取值为{+1,-1},u∈D表示响应图上每个点的位置,其中u与响应图中心的距离小于一定阈值时,标记该样本为正样本;如果距离大于该阈值,则标记为负样本。通过随机梯度下降(SGD)求解外观分支的网络参数θα为:
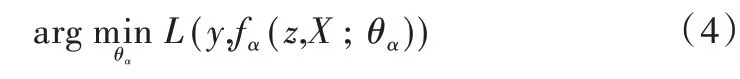
1.1.2 语义分支
将(z,X)输入语义分支,语义分支对图像提取特征得到特征图(φs(z),φs(X)),其中φs(·)表示语义分支特征提取模块的特征映射。考虑到使用高级特征信息的语义分支对外观变化有强鲁棒性,但面对背景杂乱的复杂场景时效果较差,因此在语义分支中添加残差注意力模块以增强该分支的判别能力[17]。传统残差结构直接与掩膜进行点乘,会导致特征值损失。为此,本文以恒等映射方式构建软掩膜部分,避免了注意力模块中目标特征值的损失。得到的残差注意力模块输出为:

式中,M(z)为掩膜部分输出,大小在0~1 之间。当掩膜部分输出M(z)接近于0 时,H(z)近似等于特征提取模块输出特征φs(z)。通过添加上述残差注意力模块,使得初始特征的良好结构得以保持,同时有效增强了语义分支对目标的注意力。得到语义分支注意力感知特征后,通过相似度计算得到语义分支响应图为:

通化最小化损失计算得到最终语义分支的网络参数为:
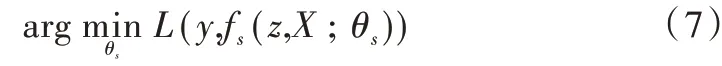
式中,θs表示语义分支待训练的网络参数。
在跟踪阶段,通过对外观分支和语义分支各自输出的响应加权融合得到最终响应图:
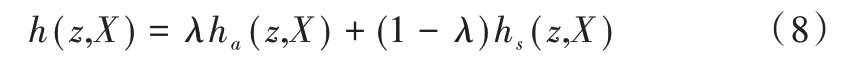
式中,参数λ为平衡外观分支与语义分支的加权参数,λ越接近1 表示跟踪过程中目标外观越趋于稳定,λ越接近0 表示跟踪过程中目标外观越趋于发生较大变化。通过求得最终响应图h(z,X)中最大值对应的坐标,即可确定跟踪目标在搜索图像中的位置。
1.2 残差注意力结构
残差注意力结构的输入为主干网络从跟踪目标中提取的深层特征。在残差注意力结构中,掩膜分支首先通过前馈网络结构扫描并整合图片全局信息,快速增大感受野;然后通过自顶而下的网络结构将全局信息与原始特征图结合;最后通过softmax 层将输出归一化到(0,1),通过掩膜分支对主分支的加权,得到注意力感知的目标特征。由于注意力感知模块仅应用于初始帧,实验过程中对后续帧目标跟踪的速度不受计算复杂度的影响。
2 实验结果与分析
实验平台的处理器为Inter Core i7-8750H,主频为2.20GHz,内存为8GB。实验时使用CUDA 进行GPU 加速,GPU 型号为NVIDIA GeForce GTX 1060。程序实现语言为Python,使用PyTorch 作为深度学习框架。
为验证算法有效性,选择在流行跟踪数据集OTB2015上进行实验。OTB2015 包含100 个目标跟踪图像序列,每个图像序列被标记了不同属性,对应目标跟踪领域的不同难点,包括光照变化(Illumination Variation,IV)、尺度变化(Scale Variation,SV)、遮挡(Occlusion,OCC)、变形(Deformation,DEF)、运动模糊(Motion Blur,MB)、快速移动(Fast Motion,FM)、平面内旋转(In-Plane Rotation,IPR)、平面外旋转(Out-of-Plane Rotation,OPR)、离开视野(Out-of-View,OV)、背景杂乱(Background Clutters,BC)和低分辨率(Low Resolution,LR)。通过在不同属性图像序列上进行算法验证,可评估跟踪算法在不同复杂场景时的跟踪效果。
将本文算法模型与近年热门的6 种跟踪算法进行比较,包 括SAMF[18]、DSST[19]、KCF[5]、Staple[20]、SiamFC[8]、BACF[21]。以下从定性、定量两个方面进行对比分析。
2.1 定性分析
图2(彩图扫OSID 码可见)给出了本文算法与6 种对比算法在OTB2015 数据集上的部分跟踪结果。表1 列出了本文测试图像序列中包含的影响因素。

Fig.2 Comparison of partial tracking results between algorithm of this article and other six algorithms图2 本文算法与6 种对比算法部分跟踪结果比较

Table 1 Influencing factors included in the test image sequence表1 测试图像序列包含的影响因素
图像序列Basketball 展示的是篮球比赛。跟踪目标为一名球员,摄像机拍摄的篮球比赛视频中球员间经常出现互相遮挡或粘连的情况,这也是跟踪难点。从第606 帧开始,跟踪目标周围相似扰乱增多,在631~665 帧之间,目标与相似扰乱之间发生了严重重叠,DSST、Staple 和SiamFC算法出现了误跟现象,而本文算法仍能准确框定目标,表明其判别性增强,在面对杂乱背景时仍能确保准确跟踪。
图像序列Human9 展示的是摄像头下步行的行人。行人从镜头前向远离镜头的方向运动,并多次经过树阴,跟踪难点主要在于目标尺度与光照变化。由于目标在摄像场景中的相对位置没有发生很大改变,大部分算法计算出的边界框都能框住目标。但相较于其他算法,本文算法计算出的边界框与人工标注真实边界框之间的交并比更大,跟踪结果更为精确,表明本文跟踪算法对目标尺度变换具有更好的处理能力。
图像序列Ironman 展示的是运动摄像头下机甲头部的运动。由于图像分辨率较低,且场景多次发生强烈的光照变化,加之跟踪目标多次发生平面内外旋转,对跟踪算法的鲁棒性提出了较高要求。从图2 中可以看到,在目标发生多次旋转变换后,大部分跟踪器都丢失了跟踪目标,而本文算法不仅成功跟踪了目标,还保证了较高准确性。本文算法中的语义分支对鲁棒性有很大提升,在跟踪目标外观发生变化时仍能实现较好跟踪效果。
图像序列MotorRolling 展示的是山地车比赛项目。在图像序列中,随着目标运动,背景亮度不断发生变化,加之目标一直处于高速运动状态,导致图片序列出现严重模糊,加大了跟踪难度。在该条件下,传统滤波类算法无法生成有效滤波器,而本文算法通过残差注意力模块提取的目标感知特征成功对目标外观进行了表达,最终得到的跟踪结果明显优于其他算法。
2.2 定量分析
使用一次性通过评估(OPE)方法在OTB2015 数据集上对本文算法与其余6 种对比算法的性能进行了整体评估,根据实验数据绘制的成功率曲线和精度曲线如图3 所示。从图中可以看出,本文算法的性能明显优于其他算法,与基准算法SiamFC 相比,成功率提升了8.2%,精度提升了10.2%。为进一步分析本文算法的优缺点,表2、表3 列出了基于不同属性图像序列下各种算法的跟踪精度与成功率。结果表明,本文算法在除背景杂乱属性以外的复杂跟踪场景中跟踪成功率与准确率均为最佳,具有较好的目标跟踪性能。
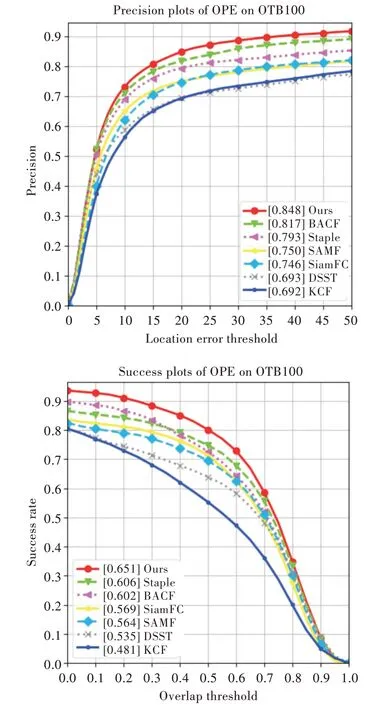
Fig.3 Success rate and accuracy curve on OTB2015 dataset图3 OTB2015 数据集上的成功率与精度曲线
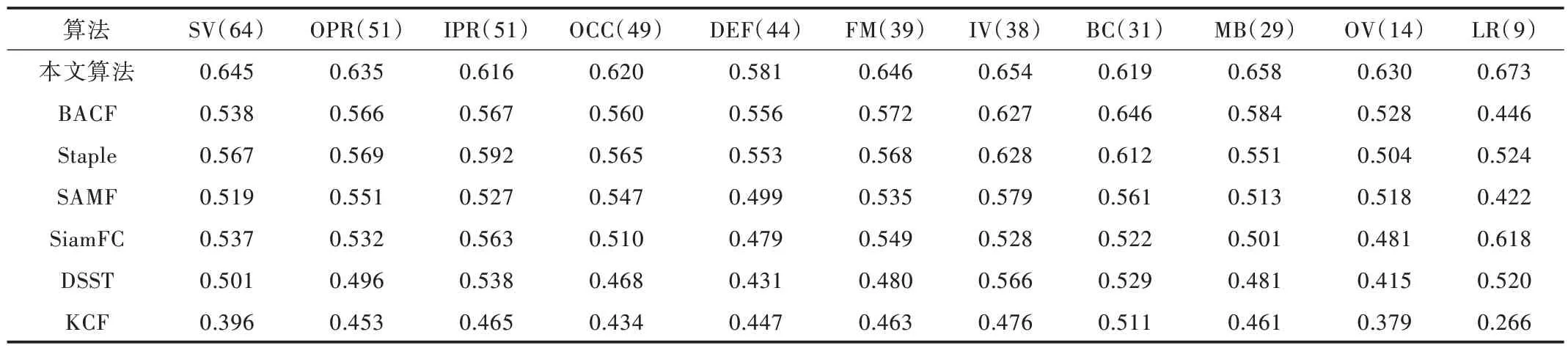
Table 2 Comparison of tracking success rate of algorithms under different attributes表2 不同属性下算法跟踪成功率对比

Table 3 Comparison of tracking accuracy of algorithms under different attributes表3 不同属性下算法跟踪精度对比
3 结语
本文针对复杂场景下跟踪鲁棒性差的问题,提出一种融合注意力机制的双分支孪生网络结构,通过利用不同层次特征充分发挥深度特征的能力,同时在语义分支中嵌入残差注意力结构进一步提升算法的特征表达能力。然后,在流行跟踪数据集OTB2015 上对算法跟踪性能进行评估,结果表明,本文算法能有效提高跟踪成功率与准确率,跟踪性能优秀。但本文算法在背景干扰的复杂场景下跟踪性能还有待提高,如何将背景信息纳入考虑范围,以减少跟踪过程中相似目标的干扰,将是下一步的研究重点。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:59:12
阅读(快乐英语高年级)(2022年6期)2022-06-17 04:48:48
家庭影院技术(2021年10期)2021-11-20 06:08:52
农业机械学报(2020年2期)2020-03-09 07:35:30
中华建设(2019年7期)2019-08-27 00:50:18
学生天地(2019年28期)2019-08-25 08:50:54
数学物理学报(2018年1期)2018-03-26 08:16:36
紫禁城(2017年6期)2017-08-07 09:22:52
项目管理技术(2016年12期)2016-06-15 20:29:33
西南交通大学学报(2016年6期)2016-05-04 04:13:11
