
跨越中等收入阶段与劳动份额、收入差距的调控*
2021-10-27 00:37彭定赟
武汉理工大学学报(社会科学版) 2021年4期
彭定赟,陈 强
(武汉理工大学 经济学院,武汉 430070)
一、相关研究文献综述
在十四五规划中,我国明确提出居民收入增长速度要和经济增长速度相匹配、劳动报酬提高速度和劳动生产率提高速度相匹配,不断提高低收入群体收入,扩大中等收入群体数量。按照世界银行划分的国别分组标准,我国在1998年进入中等收入阶段,在中低收入阶段经历12年的高速增长后,于2010年踏入中高收入阶段。但在迈进中高收入阶段后,我国经济发展形势开始恶化,大量低端产业产能过剩,企业转型困难,经济增速逐步放缓,该现象引起了学术界对我国能否顺利跨越中等收入阶段的担忧[1]。鉴于此,研究如何跨越中等收入阶段成为当前我国经济保持持续增长的重点课题。
自我国进入中等收入阶段后,劳动份额持续下降,在2008年左右达到低点,随后有所上升;与此相反,我国收入差距却持续扩大,在2008年左右达到顶点后,随后略微下降,但也一直保持较高水平。从统计数据可以看出,我国劳动份额与收入差距存在一种相关性变化特征。这种相关性变化特征的具体表现形式是怎样的,以及在这种变化特征下,劳动份额与收入差距对经济增长的共同作用是什么?这是本文要探讨的问题。
自凯恩斯开启宏观经济学的研究后,学者们对劳动份额、收入差距和经济增长三者的关系便开始不断研究。最初学者们以“卡尔多事实”为准则,认为劳动份额和资本收入份额相对独立,不被国别差异和发展阶段不同所影响。1980年前后,受到高通胀影响,发达国家一致出现了劳动份额下降现象,学者们重新将视线聚焦于初次分配过程。随着对初次分配研究的深入,学者们逐渐将研究内容扩展到收入差距,认为劳动份额的变化不仅影响两种生产要素劳动和资本之间的财富分配,更影响到人民生活水平和社会福利。同时,经济增长也被引入到收入分配的研究中,形成劳动份额、收入差距和经济增长三者的共同研究。目前大多数学者对三者的研究主要包括三个方面:一是探讨劳动份额与收入差距的关系。根据发达国家数据显示,劳动份额和收入差距虽然在收入分配理论中属于不同领域,但两者具有内在的影响机理,即前者对后者具有反向影响[2]。结合我国发展状况,劳动要素和资本要素具有紧密的替代关系,从而导致劳动份额与收入差距具有负线性关系[3]。但当研究视角转为生产要素的供求格局时,劳动份额下降和收入差距上升并没有必然联系[4]。由此可见,对劳动份额与收入差距的相关关系在学界依然没有定论。二是劳动份额与经济增长的关系。运用世界各国劳动份额数据发现,即使经济发展水平不同,各国在经济增长过程中劳动份额都呈现出“U”形变化趋势[5]。根据我国历史数据,从产业结构角度来看,产业结构变化导致了经济增长与劳动份额逆向变化[6]。三是收入差距与经济增长的关系。在理论机理方面,将城乡二元结构与跨期经济增长模型相结合,以劳动力质量为中介变量,显示收入差距对经济增长具有持续影响[7]41。从收入差距分解角度来看,将收入不平等分解为机会不平等和努力不平等,但两者对经济增长具有相反的影响,而导致针对不同地区收入差距对经济增长的影响不同[8]。
综上可以看出,学界对于劳动份额、收入差距和经济增长的单项研究较为丰富,但还缺乏将其整体联系在一起研究的视角。本研究的创新点表现在两个方面:一是运用中国中等收入阶段以来的省级面板数据,实证得出劳动份额与收入差距逆向变化的规律;二是将劳动份额、收入差距及经济增长纳入同一系统,探究了劳动份额和收入差距对经济增长的共同影响。
二、中等收入阶段劳动份额与收入差距逆向变化的机理分析
(一) 统计描述分析
依据上文文献分析,劳动份额与收入差距的具体关系在学界没有定论,但这并不妨碍本文探求我国总体劳动份额与收入差距(以基尼系数表示)相关变化规律。鉴于我国从1998年进入中等收入阶段,借鉴程永宏[9]1998-2002年和《中国统计年鉴》2003-2018年基尼系数和《中国统计年鉴》1998-2018年劳动份额数据,本文绘制出1998-2018年总体劳动份额与收入差距曲线图,如图1所示。由图中可以看出,在中等收入阶段,我国劳动份额曲线呈现明显的“U”型特征,同时收入差距曲线呈现明显“倒U”型特征,并且两者在相同时间节点的变化趋势也基本相同。具体来看,从1998年到2004年,我国总体劳动份额从0.507下降到0.430,基尼系数从0.400上升到0.473。随后两者都稳定在相对水平。从2007年到2015年,劳动份额有所上升,从0.429上升到0.479;基尼系数开始下降,从0.484下降到0.462。相对于劳动份额,基尼系数呈现更小的变动。其可能的原因在于,尽管劳动份额有所上升,但相对来说其依然较低,此时劳动份额变化与收入差距变化相互影响较小。从2015年到2018年,劳动份额与收入差距都保持在相对稳定的状态。从整体变化趋势来看,劳动份额与收入差距具有显著的逆向变化趋势。
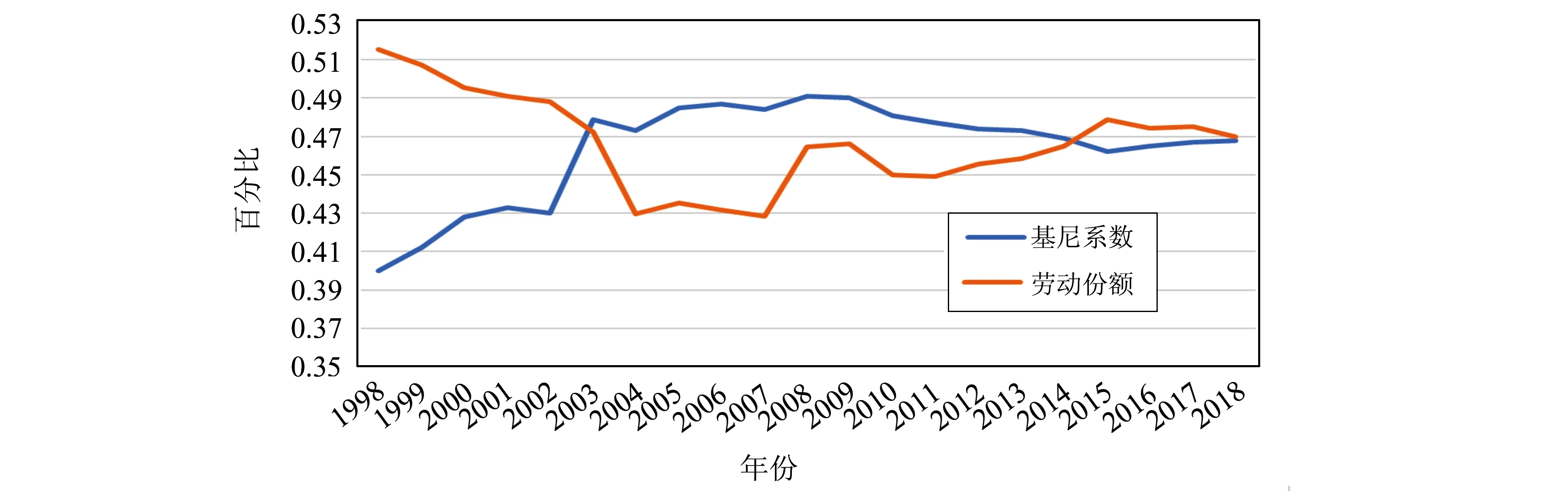
图1 1998-2018年劳动份额与收入差距曲线数据来源:程永宏(2007)(1998-2002年)及《中国统计年鉴》(2003-2018年)
(二) 经济理论分析
本文借鉴Checchi&García-Pe1alosa[10]的研究,考虑不同收入水平情况。假设经济中收入水平分为四组:第一组为零收入的失业者,人数在劳动者中占比为u,只接受失业补助B;第二组为低收入工人,所占比例为l,收入来源为低工资ωu;第三组为中等收入工人,所占比例m,收入来源为高工资ωh,且ωh>ωu;第四组为高收入资本家,所占比例h。由于其本身拥有一定资本,所以其收入来源为高工资ωh和利润π。总劳动力标准化为1,即(u+l+m+h)=1。
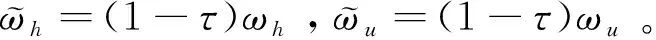
根据通用基尼系数公式计算各组群收入差距为:
(1)
其中y为样本平均收入,N为分组数,yi为各组平均收入,e为人口占比。计算得出的基尼系数是各子群的组间收入差距,对于各子群组内收入差距本文暂不考虑。将前文假定代入通用基尼系数公式,可得基尼系数的表达式。
(2)
(3)
对θ求偏导得
(4)
显然,基尼系数随资本份额的增加而增加,这也表示基尼系数随着劳动份额的增加而减少,即劳动份额与收入差距存在逆向变化趋势。
三、模型设定与实证分析
(一) 指标选取
本文样本包括1998-2018年30个省级行政区(除西藏、港澳台)的面板数据,对于有数据缺失的样本,本文采用线性插值法进行估算。全部数据来源于各省份历年统计年鉴、历年《中国统计年鉴》《中国劳动统计年鉴》和《中国人口和就业统计年鉴》。
1.主要变量。
经济增长水平(lnPGDP)。经济增长水平以人均GDP表示,数据来源于国家统计局历年统计年鉴,并对其进行对数化处理。
劳动份额(LSH)。由于国家统计局在2004年和2008年对统计口径进行了两次调整,导致对劳动份额的测算出现很大争议。本文基于数据可得性和与其他变量保持统一口径的考虑,选择国家统计局公布的劳动报酬与收入法计算的GDP的比值表示劳动份额,这也是学界认可度较高的计算方法。同时选择劳动报酬与收入法计算的GDP减去生产税净额的差值之比作为替代变量进行稳健性检验。
收入差距(GINI)。从不同的角度来看,收入差距分为居民收入差距、地区收入差距、行业收入差距等,本文使用的是居民收入差距。计算收入差距最常用的指标是基尼系数,其本质是利用洛伦兹曲线形成的不平等面积与总面积之比。具体计算基尼系数的方法是,先根据各省公布的城镇和农村收入分组计算城镇收入差距和农村收入差距,再结合省级数据计算各省收入差距。
2.控制变量。
为了保证模型设定的准确性,本文从贸易发展、政府决策和结构调整等角度控制影响经济增长的相关变量,控制变量主要包括:
人力资本(lnEdu)。采用人均受教育年限衡量人力资本,具体计算方法为:人均受教育年限=0Q0+6Q1+9Q2+12Q3+16Q4,Q0、Q1、Q2、Q3、Q4分别为未受教育、小学、初中、高中、大专及以上教育水平人口占比,并对人力资本作对数化处理。
资本偏向性技术进步(Tech)。采用资本份额作为衡量,用固定资产折旧和营业盈余比例之比表示。
市场化水平(Mkt)。采用各省份非国有企业工业总产值占总体工业总产值的比重反映。
对外贸易水平(EXPO)。采用各省进出口总额占GDP比例衡量。
城市化水平(UBZ)。采用城镇化率进行衡量,由各省份城镇人口占总人口比例计算。
政府干预(GOV)。采用各省份政府财政支出占GDP比例衡量。
产业结构(STRU)。采用第三产业产值与GDP比例衡量。
各变量描述性统计如表1所示。
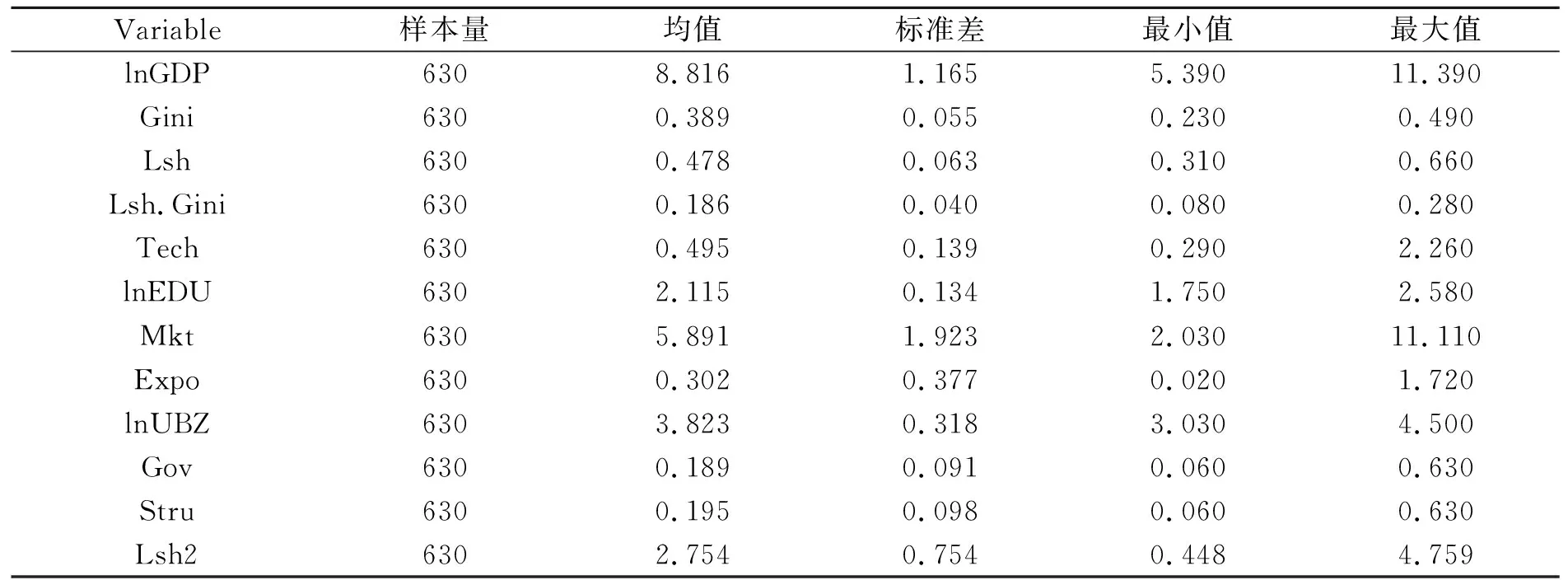
表1 各变量描述性统计
(二) 模型设定
1.劳动份额与收入差距逆向变化模型设定。
基于以上的理论分析,为了更好地体现劳动份额与收入差距各自的变化趋势及两者逆向变化特征,本文分别构建如下模型:
LSHit=α0+α1lnPGDPit+α2lnPGDP2it+λ1Control1it+εit
(5)
GINIit=β0+β1lnPGDPit+β2lnPGDP2it+λ2Control2it+εit
(6)
上式中,下标i为各个省市的标识(i=1,2,…,30),下标t代表各个年份的标识(t=1998,1999,…,2018),lnPGDPit表示第i个地区在t时期的经济增长水平,为了更好地反映劳动份额和收入差距与经济增长的非线性变化,本文引入经济增长的二次项lnPGDP2it;在式(5)中,Lshit分别表示第i个地区在t时期各省份劳动份额,参考钞小静等[7]37以及焦音学和柏培文[11]32-34的研究,选取人力资本(lnEDU)、资本偏向性技术进步(Tech)、对外贸易水平(EXPO)、政府干预(GOV)、产业结构(STRU)作为Control1it;在式(6)中,Giniit分别表示第i个地区在t时期各省份收入差距,参考吴孟珠和王佳雯的研究[12],选取人力资本(lnEDU)、对外贸易水平(EXPO)、城市化水平(UBZ)、政府干预(GOV)、产业结构(STRU)作为Control2it。εit为随机误差项。
2.劳动份额与收入差距对经济增长交互影响模型设定。
为了检验劳动份额和收入差距对中国经济增长的影响,在充分借鉴现有研究和考虑数据可得性的基础上,将基本计量模型构建如下:
lnPGDPit=γ0+γ1Lshit+γ2Giniit+γ3Lshit·Giniit+λ3Controlit+μi+υt+εit
(7)
式(7)中,被解释变量和主要解释变量如前所述,本模型还引入劳动份额与收入差距的交乘项Lshit·Giniit,以此表示两者对经济增长的交互影响;参考焦音学和柏培文[11]32-34的研究,选取对外贸易水平(EXPO)、城市化水平(UBZ)、政府干预(GOV)、产业结构(STRU)为控制变量Controlit,μi为个体效应,υt为时间效应,εit为随机误差项,且服从独立同分布。模型中部分变量经过对数化处理,以此来消除异方差性。
(三) 实证分析
1.劳动份额随经济增长的变化趋势。
表2汇报了经济增长对劳动份额的实证结果。共分为两组,第一组为以全部省份数据进行估计;第二组为不同地区数据进行估计。不同地区分类是以国家统计局地区分类三大地带为依据。全部结果都显示lnPGDP的一次项系数在1%的水平下显著为负,二次项系数在1%的水平下显著为正,表明我国劳动份额随经济增长表现出“U”形变化趋势。

表2 经济增长对劳动份额影响的实证结果
具体来看,第一列全部省份估计结果显示,lnPGDP的一次项系数为-0.507,二次项系数为0.025,由此可以得出劳动份额“U”形变化的经济增长拐点为10.14。对比各个省份,发现我国各省份基本在2009—2011年出现劳动份额拐点。但由于我国不同地区可能出现异质性,所以对不同地区分别进行估计。对于东部地区,其估计值与全部省份较为接近,可能的原因在于,东部作为相对发达地区,不仅是我国劳动力的聚集地,我国资本集聚地,区域经济增长也是全国经济增长的主力。其区域劳动份额比例与全国其他地区劳动份额比例近似,劳动份额对经济增长的边际变化也大致相同;而中部地区估计值的绝对值远大于全部省份,说明经济增长对劳动份额的边际影响较明显。其可能的原因在于,中部地区有着充足的劳动力资源,但其吸引资本的能力相对于东部地区较差,这就导致了劳动份额相对较高,劳动份额对经济增长的边际变化较大。西部作为劳动力流出区域,但由于其第三产业占比较高,其劳动份额比例相对较低,这就导致西部地区估计值的绝对值远小于全部省份,劳动份额对经济增长的边际变化相对较小。
2.收入差距随经济增长的变化趋势。
表3汇报了经济增长对收入差距的实证结果。也分为两组,第一组为以全部省份数据进行估计;第二组不同地区数据进行估计。全部结果都显示经济增长的一次项系数在1%的水平下显著为正,二次项系数在1%的水平下显著为负,表明我国收入差距随经济增长表现出倒“U”形变化趋势。

表3 经济增长对收入差距影响的实证结果
具体来看,全部省份估计结果显示,lnPGDP的一次项系数为0.239,二次项系数为-0.011,由此可以得收入差距倒“U”形变化的经济增长拐点为10.86。对比各个省份,发现我国各省份在2010—2012年出现收入差距拐点。从分区域来看,三大区域经济增长对收入差距的边际变化都大于全国总体。其可能的原因在于,全国样本的组内差距较大,分区域后各区域的组内差距较小。具体来看,东部地区和西部地区的估计系数较为接近,虽然两区域具有较大差异,但可能在复杂因素作用下使得经济增长对收入差距的边际影响大致相同;对于中部地区,可能由于组内差距较小,其估计系数相对更大。
综合以上三部分实证结果,显示以经济增长指标作为基本变量,我国各省劳动份额先下降后上升,在2009—2011年出现拐点;各省收入差距先上升后下降,在2010—2012年出现拐点。由此得出我国各省劳动份额与收入差距变化趋势分别为“U”形和倒“U”形,且拐点基本一致,从而得出我国劳动份额与收入差距呈现逆向变化趋势。
3.劳动份额与收入差距对经济增长的交互作用。
为了检验劳动份额与收入差距共同作用下对经济增长的影响,本文建立带有劳动份额与收入差距交互项的基础回归模型进行回归。
对于面板模型回归分析,首先要通过Hausman检验确定模型适用固定效应还是随机效应。对式(6)进行Hausman检验后,结果显示卡方为负值,参考连玉君等人的研究[13],本模型应采用固定效应模型,回归结果如表4显示。从全国样本来看,劳动份额和收入差距的系数均为正,但其交互项的系数为负,且两者的总效应为负。从分地区样本来看,东部地区与全国样本估计值符号相同,其绝对值都相对较大;中部和西部地区劳动份额与收入差距的系数估计值都为负,但两者的交互项系数为正,且两者的总效应为正。造成这种结果可能的原因在于,当前劳动份额与收入差距各自对经济增长具有不同的影响。参考焦音学和柏培文的研究[11]36,当前我国处在中高收入阶段,总体劳动份额对经济增长具有正向作用、收入差距对经济增长具有负向作用。结合本研究,收入差距的估计系数大于劳动份额,从而从全国样本来看,两者的总效应为负;对于东部地区,由于其是我国经济增长的主要贡献地区,劳动份额与收入差距对经济增长的影响效果相同,同时东部地区各省样本数据差异较小,因此系数估计值相对于全国样本更大;对于中部和西部地区,大部分处于中低收入阶段,由于人均收入水平相对较低,此时劳动份额与收入差距对经济增长的总效应都为正。
本文使用Lsh2替代Lsh作为劳动份额进行稳健性检验,结果显示主要变量依然在10%以内的显著性水平显著且主要变量在符号上与表4相同,说明原模型设定具有稳健性。限于篇幅,本文不报告稳健性检验结果。
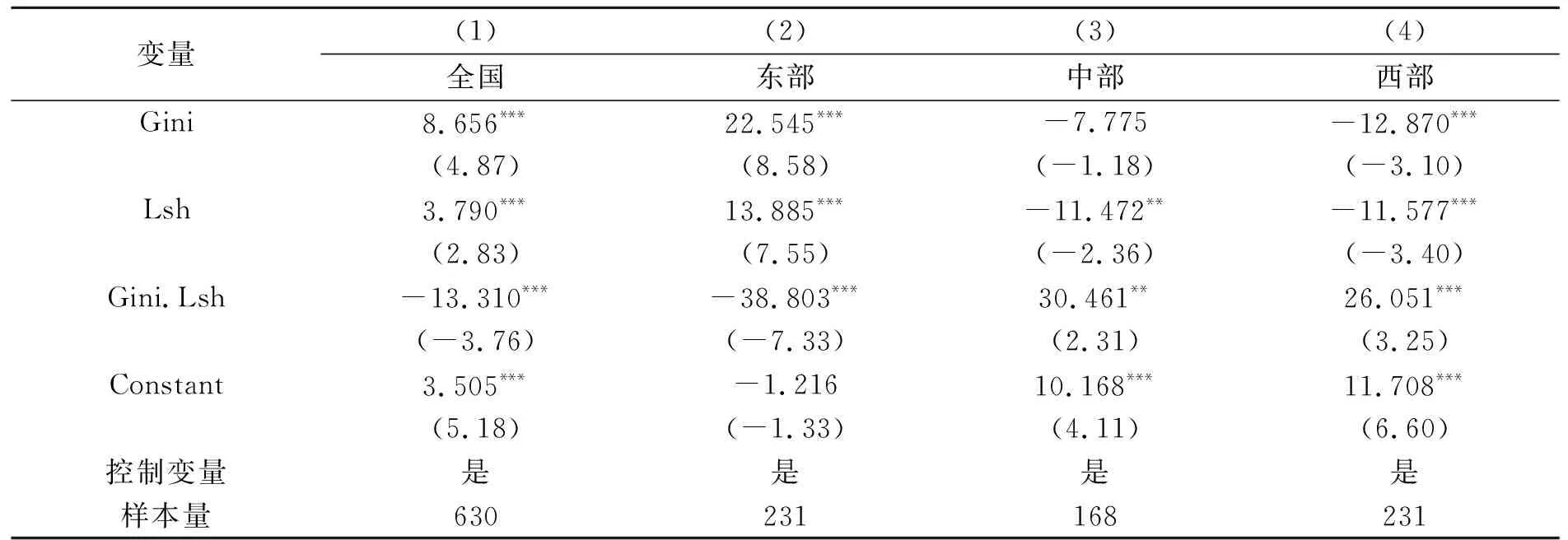
表4 劳动份额与收入差距交互项的基础回归结果
四、结论与启示
本文基于中等收入阶段的经济发展背景,探讨了我国总体及各地区在中等收入阶段劳动份额与收入差距的逆向变化规律,深入分析了劳动份额和收入差距对经济增长的叠加影响。运用各省份面板数据,分别构建了经济增长与劳动份额和收入差距的非线性模型;构建引入交互项的劳动份额和收入差距对经济增长影响的基础回归模型,模型回归结果显示如下:
(1)在中等收入阶段,全部省份与各地区劳动份额与经济增长呈现“U”形变化趋势;全部省份与各地区收入差距与经济增长呈现倒“U”形变化趋势;且两种变化趋势的人均GDP拐点基本一致,从而我国劳动份额与收入差距呈现逆向变化趋势。(2)全部省份与东部地区省份劳动份额与收入差距单独对经济增长都具有正向影响,两者的交互项对经济增长具有负向影响,且两者的总效应为负向影响;中部地区和西部地区劳动份额与收入差距单独对经济增长都具有负向影响,两者的交互项对经济增长具有负向影响,且两者的总效应为正向影响。
据此,本文得出以下两点启示:
其一,需稳定我国总体劳动份额与收入差距进入合理区间。劳动份额与收入差距逆向变化且两者对经济增长具有负向的总效应,为了更好地促进经济增长,使我国跨越中等收入阶段,应当在降低收入差距的同时提高劳动份额,将两者稳定在一定的波动水平,且政策对象主要是东部地区。
其二,需提高中部地区和西部地区劳动份额与收入差距的总效应。当前两地区劳动份额具有上升趋势,收入差距具有下降趋势。因此需要在降低收入差距的同时更多地提高劳动份额,使两者的总效应为正,从而更好地促进经济增长,早日实现中部和西部地区跨越中等收入阶段。
猜你喜欢
中国经济周刊(2018年31期)2018-08-14
决策探索(2017年11期)2017-06-23
中国证券期货(2017年3期)2017-03-30
中国证券期货(2017年3期)2017-03-30
经济(2015年6期)2015-09-10
实践·党的教育版(2014年4期)2014-05-15
恋爱婚姻家庭·养生版(2014年2期)2014-01-27
高中生学习·高一版(2013年3期)2013-04-01
环球时报(2013-01-23)2013-01-23
