
使用HRV 多特征参数和机器学习的心衰诊断方法研究
2021-10-26 12:27:24赵兴群
电子器件 2021年4期
张 敏,赵兴群
(东南大学生物科学与医学工程学院,江苏 南京 210096)
充血性心力衰竭(congestive heart failure,CHF)是一种常见的慢性心血管综合征,也称为心力衰竭,当心脏无法向人体中泵送足够的血液时,就会发生心衰[1]。CHF 的主要特征是心室收缩或舒张功能障碍,常见症状包括疲劳、呼吸困难、运动耐力低下和体液潴留等,进一步可导致内脏和肺部充血[2]。心衰是各种心脏疾病的严重表现或晚期阶段,死亡率和再住院率居高不下,中国心力衰竭注册登记研究(China-HF)显示,各年龄段心衰病死率均高于同期其他心血管病,七十岁以上人群患病率大于等于10%[3]。因此,研究心衰疾病的预防及诊断技术具有重要的价值和意义。目前,诊断心衰疾病主要根据症状和体征等综合分析判断,需要耗费大量的医疗资源及人工成本。对于不断增加的患者,需要研究一种便捷、快速且有效的检测系统来进行心衰诊断。
心电图(electrocardiogram,ECG)能够记录心脏电活动的变化情况,反映相关生理和病理信息,且具有无创、简便、经济等优点,已成为各种心血管疾病诊断中的必备基本诊断技术。与依靠医生经验直接通过心电图进行诊断相比,信号处理技术和生物医学分析方法的应用可以进一步提高诊断的可靠性。在过去的研究中,已经使用多种方法来通过ECG 信号检测CHF。Chen 等[4]使用稀疏自动编码器提取相邻两个R 波之间的间隔(RR 间期)的无监督特征,然后应用具有不同隐藏节点组合的全连接神经网络来检测心衰信号。Wang 等[5]设计了一个基于RR 间隔的长短期记忆(long short-term memory,LSTM)网络来检测CHF,准确度最高达到85.13%。Acharya 等[6]训练了一个11 层卷积神经网络模型,并直接对原始ECG 信号进行识别分类,最高准确度可达98.97%。这些研究均使用了神经网络和深度学习的方法,虽然分类准确度较高,但这些结果很难被临床医生解释,分解得到的特征参数也并无具体含义,同时,由于对整个模型的运作机制无法理解和解释,在进一步设计明确并有针对性模型的优化方案时也存在困难。
因此,通过ECG 信号得到有实际意义的特征,再进行分类识别,这样的方法可解释性和可应用性会更高。对于CHF 诊断,许多研究通过ECG 信号QRS 波群[7]、从QRS 波起始至T 波终止的时间间隔(QT 间隔)[8]和RR 间期差异[9]等重要特征进行检测。其中,RR 间期差异的变化情况又被称为心率变异性(heart rate variability,HRV),HRV 分析是一种用于评估心血管自主神经系统功能的非侵入性方法[10],已应用在临床心脏疾病和非心脏疾病研究的各个领域,包括心肌梗塞[11]、糖尿病[12]和心源性猝死[13]等。近些年来,越来越多的研究证明了HRV 与CHF 的相关性。CHF 患者通常具有较高的交感神经活动和较低的副交感神经活动[14]。Kamen 等[15]对健康受试者进行交感神经和副交感神经的控制并进行HRV 分析,结果表明交感神经活动的增强和副交感神经活动的降低会导致平均RR 间隔、RR 间期标准差、低频含量(LF)的降低和Poincare 图的宽度(SD1)的增加。Malliani 等[16]研究表明LF-HF 平衡会随着交感神经活动的增加而发生变化,且副交感神经活动的增加是导致高频(HF)含量增加的主要因素。Liu 等[17]计算了健康者和CHF 受试者HRV 信号的近似熵(ApEn),结果表明CHF 组的ApEn 值降低。上述研究表明,心衰病人和健康人的HRV 在多个特征参数上都具有明显差异性,可以通过HRV 分析提取特征参数来检测CHF。
本研究综合选取基于HRV 分析计算得到的多个特征参数,并使用机器学习的分类方法进行CHF的检测。首先,对ECG 信号进行HRV 分析,从时域、频域、非线性分析中各选取多个相关指标,并将其共同做为样本的特征参数。然后,使用机器学习方法中的决策树、支持向量机、贝叶斯、最近邻算法、随机森林等设计分类器,进行心衰信号的识别分类。最后,提出一种基于个人的分类评估方法,在数据划分时避免一个人的数据同时出现在训练集和测试集中,给出分类结果的客观评价指标。
1 实验数据与预处理
1.1 实验数据
本研究使用来自复杂生理信号研究资源库PhysioNet[18]中的充盈性心衰数据库BIDMC Congestive Heart Failure Database[19]及正常窦性心律数据库Mit-bih Normal Sinus Rhythm Database 1.0.0。其中心衰数据库包括15 例CHF 患者,信号采样频率为250 Hz;正常窦性心律数据库包括18 例健康人,信号采样频率为128 Hz。两个数据库中样本采样时间都在18 h~24 h 之间,为长时采样。
为了符合更多的实际应用场景,考虑短时采样的情况,并达到扩充实验样本数的目的,本研究采用信号分段的方式,将长时采样数据分割成以10 min 为间隔的信号段,结果可得到5 220 组有效心电信号。
1.2 预处理
由于HRV 反映的是心电信号中逐次心跳周期的变化情况,进行HRV 分析需首先从心电信号中计算得到心电信号周期,即RR 间期序列。因此要进行R 波检测,得到R 波峰值,本文采用基于滤波和自适应阈值的检测方法,经过滤波、差分、幅值逐点平方、移动窗口积分、自适应阈值及决策融合等步骤,检测到各个位置的R 波,结果如图1 所示,上图为ECG 信号R 峰检测结果,用符号“+”标注,下图为对应的RR 间期序列。
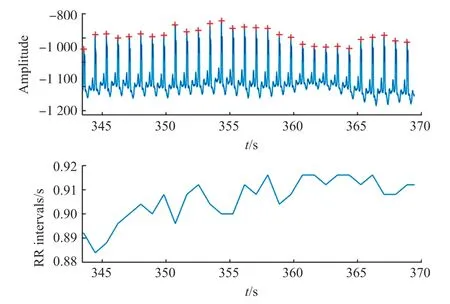
图1 R 波检测结果
1.3 HRV 特征参数计算
在CHF 检测和分析中可使用多种HRV 分析方法,其中最经典和全面的分析方法分为三个部分,时域、频域和非线性分析。
1.3.1 时域分析
时域分析法是心率变异性分析中最简单的方法,能够直观地反映信号的特点,同时具备医学上的生理意义。相关的指标直接从RR 间期序列中统计或计算得到,本研究选取RR 间期均值Mean、中位数Median、正常RR 间期标准差SDNN、每5 分钟RR间期平均值的标准差SDANN、相邻两个RR 间期差值的均方根rMSSD、相邻RR 间期相差大于50 ms的个数占总心跳次数的百分比PNN50、平均心率MeanHR、心率标准差SDHR 等8 个特征参数,对于数据长度为N的RR 序列{RRi:1≤i≤N},相关计算方法如下:

1.3.2 频域分析
频谱分析技术的原理是将随机变化的间期或瞬时心率信号分解成各种不同能量的频率成分,能反映更复杂的心率变化规律,也称为功率谱密度(Power Spectrum Density,PSD)分析。HRV 频域分析会首先计算RR 序列的功率谱密度,将频域分成多个频段,然后统计与每个频段匹配的RR 间期数量。通常将频段分为三部分:0.15 Hz~0.40 Hz 的高频(HF)、0.04 Hz~0.15 Hz 的低频(LF)和0.003 3 Hz~0.040 Hz 的极低频(VLF)。因此,选取以下4 个频域相关指标:VLF、LF、HF 和LF/HF。
HRV 时间序列功率谱密度的计算可使用自回归模型法求解[20],对于时间序列x(n)的p阶的自回归模型可表示为公式(8)。
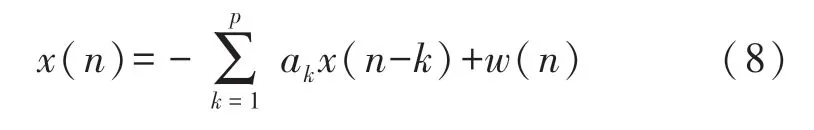
式中:w(n)方差为σ2的白噪声。功率谱密度的表达式为:
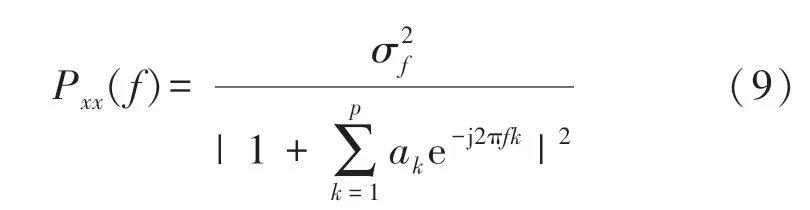
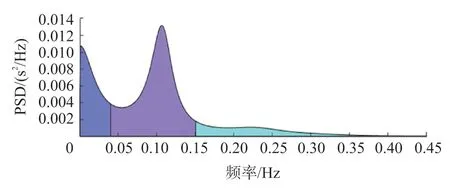
图2 RR 序列功率谱密度
1.3.3 非线性分析法
非线性理论的发展为心率变异性分析提供了更多的方法和手段,按照一定采样周期去测量得到的时间序列数据,几乎所有的非线性分析方法均被用于心率变异性信号的特征分析,本研究选取的方法包括Poincare 散点图(Poincare plot)、去趋势波动分析(Detrended Fluctuation Analysis,DFA)、递归图分析(Recurrence Plot Analysis,RPA),以及近似熵(Approximate Entropy,ApEn) 和样本熵(Sample Entropy,SampEn)等。
Poincare 散点图表示的是连续RR 间期的相关程度。以相邻两个心搏的前一个RR 间期为横坐标,后一个心搏的RR 间期为纵坐标绘制一点,如此连续绘制,即形成散点图,如图3 所示。图中这些散点的分布可近似为椭圆,其中,SD1 和SD2 分别为椭圆的半短轴和半长轴。

图3 RR 序列Poincare 散点图
去趋势波动分析度量了信号内部的相关程度。计算方法如下:
首先对RR 间期序列进行积分:

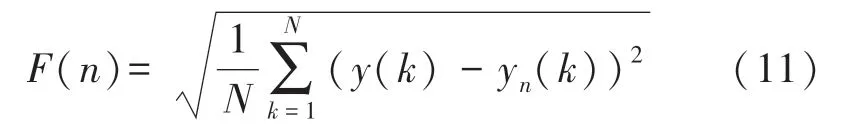
取n=4,5,…,16,得到一组数据(logn,log(F(n))),采用最小二乘法对这组数据进行拟合,其斜率即DFA 分析的一个参数αl。相应的,取n=16,17,…,64 时,得到DFA 分析的另一个参数α2。拟合结果如图4 所示。

图4 RR 序列DFA 分析结果
近似熵是测量信号复杂度或不规则度的指标,取值越大,复杂度或不规则度越大。计算近似熵,首先需要计算向量

最后得到近似熵:

样本熵的计算与近似熵类似,首先需要计算向量ui,并定义距离d,然后根据以下公式计算样本熵:


2 分类及结果分析
2.1 分类
随着对分类问题研究的深入,越来越多泛化性高、稳健性强的算法涌现而出。其中,机器学习算法能够从数据中自动分析获得规律,并利用规律对未知数据进行预测,具有精确、自动化、分类用时短等优势。本文选择了五种不同的机器学习分类器,一是利用概率统计知识进行分类的朴素贝叶斯算法(Naive Bayes,NB),二是以实例为基础的归纳学习算法决策树(Decision Trees,DT),三是具有聚类思想的K 近邻算法(K-Nearest Neighbor,KNN),四是具有集成学习思想的分类器随机森林(Random Forest,RF),五是具有最大边距决策思想的支持向量机算法(Support Vector Machines,SVM)。
2.2 结果及分析
本研究对5 220 个样本数据分别进行了时域、频域、非线性分析,选取8 个时域指标、4 个频域指标和7 个非线性指标作为特征参数,使用朴素贝叶斯算法、决策树、K 近邻、随机森林、SVM 等机器学习方法的分类结果进行比较。分类结果主要通过三个指标进行评估:准确率(Acc),灵敏度(Se)和特异性(Sp)。通过式(20)~式(22)计算得到,其中TP表示正确诊断出的CHF 的数量,TN 表示正确诊断出的正常信号(以Normal 表示)数量,FP 表示被误分类为CHF 的Normal 数,FN 表示被误分类为Normal 的CHF 数。

为了能够与之前的分类算法进行比较,在数据划分时,训练集与测试集首先按照3∶1 的比例从所有数据中随机选取,并将所得结果与以前的研究进行比较,最终比较结果如表1 所示。
由表1 可看出,将HRV 分析的多个参数作为特征时,使用机器学习的各分类方法识别心衰信号都可取得较高的准确率,其中,SVM 方法分类准确率最高,可达到98.81%,特异性和灵敏度分别达到98.76%和98.87%,与之前的研究结果相比,超越了基于其他特征的分类方法,如基于Hankel 矩阵的特征值分解方法[21]和基于经验模态分解的分类方法[22],证明了本研究方法的可行性。
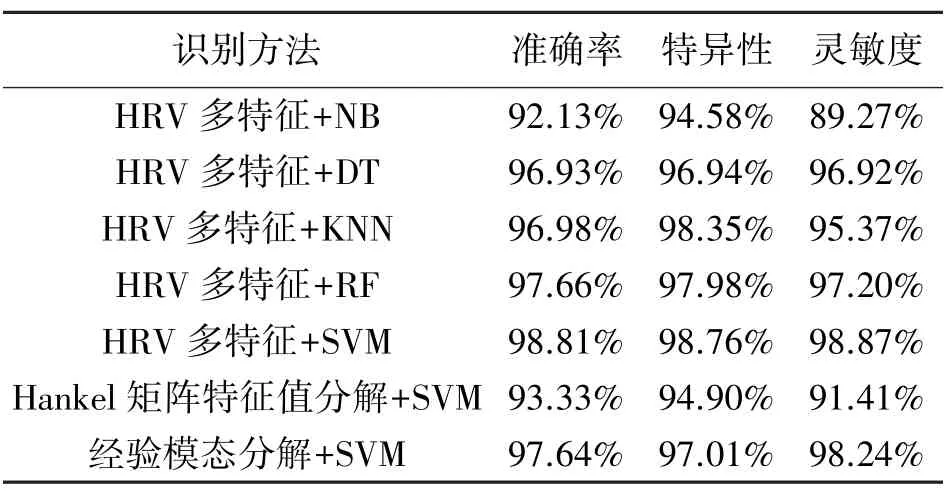
表1 分类结果比较
此外,本研究还进行了基于个人进行数据划分,使同一个人的相关样本数据只出现在测试集或只出现在训练集中,在这种方式下,训练集和测试集中不会同时出现同一个人的数据,更符合实际应用场景,评估结果更客观可信。结果表明,应用SVM 分类方法准确度仍可达到98.32%,灵敏度和特异性分别为98.62%和98.03%,进一步验证了本方法在实际应用中的有效性。
3 结束语
本文研究了基于ECG 信号进行心衰诊断的方法,首先进行R 波检测得到RR 间期序列,再通过HRV 分析计算得到时域、频域、非线性的多个参数,并使用机器学习的多种分类方法进行心衰信号的分类识别,均取得较高的准确率,其中,SVM 方法超越了已有的心衰检测算法,在分类精度、特异性和灵敏度方面均有所提高,证明了在心衰诊断方面的可行性。未来将进一步充实临床数据,继续探讨本方法在临床方面的应用效果。
猜你喜欢
现代临床医学(2022年3期)2022-06-06 07:59:46
中老年保健(2021年2期)2021-12-02 00:50:10
中国特种设备安全(2021年5期)2021-11-06 05:09:00
装备制造技术(2021年4期)2021-08-05 07:39:54
医学食疗与健康(2021年27期)2021-05-13 21:25:09
雷达学报(2018年3期)2018-07-18 02:41:34
制造技术与机床(2017年11期)2017-12-18 06:46:39
火控雷达技术(2016年1期)2016-02-06 02:17:55
无线电通信技术(2015年3期)2015-12-23 11:37:02
电测与仪表(2015年7期)2015-04-09 11:40:04
