
引文动态如何变化:文献内容特征的作用研究
2021-10-26 05:41李凌英严笑然
情报学报 2021年10期
李凌英,闵 超,严笑然
(1. 南京大学信息管理学院,南京 210023;2. 之江实验室人工智能研究院,杭州 311121)
1 引 言
科学系统包含科研人员、 科研机构、 科研项目、科研成果等多类主体,作用机制十分复杂。其中,科研成果凝聚着科学家的研究智慧,研究者可以通过学术出版物窥探科学家的研究观点。文献的被引情况则反映了其在科研系统中的影响,这种影响的产生原因既包括文献本身的内部因素,如文献的研究内容、科研成果的质量等;也包括科研系统的外部环境,如科技政策、作者知名度以及偶然因素等[1]。针对文献因何被引用的持久讨论,目前,已有较多的研究关注文献自身的表层计量特征,如篇幅、标题长度、标点符号、作者、期刊等。但是,现有研究一方面忽视了文献在时间上的引文动态表现,另一方面由于文献内容特征较难量化,亦缺乏揭示内容特征与被引表现之间关系的研究。因此,本文将文献本身的内容特征分解为研究质量、创新类型和内容多样性三个方面,探究其分别对文献引文动态尤其是引文波峰的影响。
2 理论背景与文献综述
2.1 文献内容特征的衡量
2.1.1 文献质量的衡量
基于科学性、创新性和价值性维度,许多研究者将文献的研究质量进行拓展,包括正确性、严谨性、清晰度、美观性、重要性等。例如,Mårtens‐son 等[2]提出研究质量可以拓展为:可靠性维度、贡献维度、沟通性维度和可持续性维度。围绕质量的三大标准——科学性、创新性和价值性,对一篇文献的各个维度进行评价后可以获得文献质量得分。在Patterson 等[3]中,评定论文质量等级是审稿人在原创性、稳健性和重要性三个类别中为每篇论文分配1~10 分,根据审稿人给出的总分文献被划分为Q1~Q5 共5 个等级,得分最高的为Q1 等级。Ivars‐son 等[4]则基于严谨性和相关性两个维度来衡量软件工程领域的研究质量。
Faculty Opinions (曾用名: F1000Prime) 始于2002 年,是全球第一个医学同行评议系统。集合了全球8000 多名的生物和医学专家,覆盖40 多个研究领域,旨在利用F1000 专家的建议对已发表的学术著作进行评分,并展示其重要性[5]。专家对生物医学相关的研究进行同行推荐并分为三类等级,即推荐(good)、必读(must read or very good) 和杰出(exceptional),该系统加权计算专家的推荐分值,最终得到F1000 分值(F1000 score,又称FFa score)。具体规则如下[6]:将文献所收到的所有推荐得分中最高的等级作为基础分数,推荐为6 分、必读为8 分以及杰出为10 分,其他的评级为附加分值,推荐、 必读、 杰出的附加分分别为1、 2、 3分,基础分数加总附加分,即文献的F1000 分值。例如,文献A 收到了2 个推荐、1 个必读、1 个杰出,最高等级为杰出,故基础得分为10,附加分值为1×2+2×1=4 分,则总的分值为10+4=14 分。如果文献收到的推荐数越多,那么FFa 值越大,在F1000 的数据库排名越高。研究表明,F1000 分值可以反映文献的质量[7]。Allen 等[8]发现,专家评议的得分、F1000 得分以及被引次数均存在显著的正相关,Spearman 相关系数分别为0.450、 0.446,P<0.01,专家小组确定的论文重要性评级与F1000 的重要型评级的一致性,也说明了F1000 是生物医学领域文献出版后质量评估的重要附加机制,这种附加机制有助于识别领域的重要文献。Bornmann 等[9]赞同F1000 的FFa score 是研究质量的重要指针,并探究研究质量与被引之间的关系。 简而言之,F1000 的评分机制能够在一定程度上揭示文献的重要性,FFa score 作为一种同行评议的评价指标,可以被用来评估文献的质量。
2.1.2 创新类型的衡量
在Kuhn[10]的理论中,突破性研究被认为与学科研究范式转变以及科学革命存在关联。在常规科学中,范式转变的突破和科学革命在科学体系中相互补充。Häyrynen[11]则认为,突破性研究,可能是对既有的理论和科学范式提出挑战的研究,也可能是整合不同研究视角的跨学科研究。但对于这类研究,往往伴随着较高的失败风险。van Raan[12]认为,科学是个自组织的 “认知生态系统”,科学发展过程中较大改进的突破性研究往往只占据少数一部分,大多数研究是科研体系中的小进步。 Savov等[13]认为,文献的创新与研究主题相关,如果文献讨论的是在自发表日起遥远未来将会流行的主题,而这个主题在过去并未流行,那么可以将这篇文献当作具有创新性的文献。
在本研究中,采用F1000 数据库专家给予评级时给出的文献标签,作为文献的创新类型。专家会根据文献的研究特点和文献所作的创新贡献类别,给文献打上对应的标签。研究者可以根据F1000 分值和专家给予的推荐理由,识别有价值的、自己感兴趣的文献。标签主要为文献创新类型的分类,包括新发现(new finding)、 技术进展(technical ad‐vance)、 验证性(confirmation)、 争议性(contro‐versial)、 有趣的假说(interesting hypothesis) 等;也有文献类型的分类,包括临床试验(clinical trial(non-RCT))、 综 述/评 论(review/commentary)、 系统综述(systematic review/meta-analysis)[14]。
Du 等[15]利用F1000 数据库中文献标签将文献类型划分为基于证据的、变革性和转化型三类。具体如下,认为带有clinical trial(non-RCT)、review/com‐mentary、systematic review/meta-analysis标签的文献是基于证据的研究;变革性研究主要包括带有interesting hypothesis、controversial、refutation 标签的文献;转化型研究则是novel drug target、changes clinical practice等。
本文的评估标准和Du 等[15]的划分标准具有一定相似性,结合数据实际情况,本文筛选了5 类占比较高的标签作为文献的创新类型——confirma‐tion、 technical advance、 new finding、 controversial、interesting hypothesis,将文献类型标签(如临床试验、综述/评论、系统综述) 和数量极少的标签舍弃。从标签定义来说,标签的创新水平由低到高的排序为: confirmation、 technical advance、 new find‐ing、 controversial、 interesting hypothesis。 争 议 性(controversial) 标签由于与现有理论存在较大不一致的地方,可能对现有知识体系具有一定的冲击,而interesting hypothesis 是提出新模型/假说,二者的创新水平更高。带有创新水平越高的标签,越有可能是突破性研究,而创新水平稍弱的文献则是带有创新性排序最低标签的文献。
2.1.3 文献内容多样性的衡量
文献在内容上的多样性可以由研究领域的多样性反映。例如,Enduri 等[16]认为,属于不同领域的文献拥有较高的多样性,利用APS 物理评论(American Physical Society's Physical Review Journals) 数据库中PACS (physics and astronomy classification scheme)编码分析文献的多样性,PACS 编码可以在一定程度上反映作者认为其论文的所属领域。 同时,PACS 编码是层级结构组织,因此,Enduri 等[16]借助Weitzman 公式来度量文献的多样性。 其中,Weitzman 公式衡量两个结点在树状结构的距离。若一篇文献含有多个PACS 编码,则可以利用Weitzman 公式计算编码间的距离,最终得到文献的多样性。类似地,Rafols 等[17]和Schmidt 等[18]基于文献的研究领域,采用Simpson index 和Gini-Simpson index 衡量文献的多样性。
本研究认为,文献内容多样性体现在文献的主题多样性,即跨多个子主题研究的程度。如果一篇文献包含了不同种类或者方向上的主题,那么文献的研究内容是丰富且多样的。一般认为,文献的内容多样性越高,文献的内容相似性越低。在实际操作中,文献研究主题借助数据库标引的MeSH(medical subject headings) 主题词来表示,MeSH 是由美国国立医学图书馆设计的受控医学主题词表,具有层级结构。假设文献有n个MeSH 主题(只考虑含*的主题,含*主题为文献的重要主题),若MeSH 主题词之间的距离越远,则相似性越低,文献的内容多样性越高。MeSH 主题词之间的距离可以用MeSH 词种类数和MeSH 主题词的相似性来度量,其中相似性的实现借鉴了R 包的MeSHSim[19]。MeSH 词种类数是指其文献有n个MeSH 主题所属的种类,若种类数越多,则文献的内容越丰富。基本原理为本体的语义相似度计算[20]。对于语义实体X和Y之间存在路径(path) 将这两个节点相连接,其中经过m个节点,则X和Y的相似性可以概括为
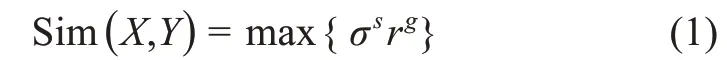
其中,σ代表到下位概念的路径权重;r为到上位概念的路径权重;s为下位概念的层数;g为上位概念的层数。在MeSHSim 中,运用shortest path 方法衡量相似度的方法为
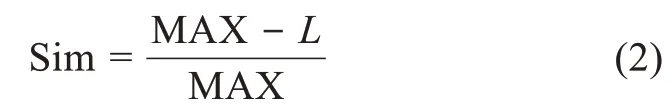
其中,MAX 为两个节点之间的最长路径长度;L为两个节点之间的最短路径长度。
通过MeSHSim 的最短路径方法计算,得到文献的MeSH 词之间的相似度之后,对词之间的相似度进行平均计算,即该文献的内容相似度。本研究借助内容相似度来反映文献的内容多样性,若文献的内容相似度越高,则文献的内容多样性越低,文献可能集中研究某一特定内容,跨方向内容越少;若文献的内容相似度越低,则文献的内容多样性越高,文献可能研究跨方向或者跨领域的相关内容。
2.2 文献特征与被引
2.2.1 文献内容特征
影响文献被引的重要因素之一就是文献的质量。许多研究者探讨了文献研究质量与文献的未来被引之间的关系。在这些研究中,部分研究发现,高质量的文献往往会吸引更多的引文。 例如,Buela-Casal 等[21]发现,质量高的论文是期刊中经由专家筛选的 “最佳文献”,与同期的其他文献相比,西班牙心理学学科的期刊中最佳文献的被引次数比其他文献的被引次数要高(P=0.001)。Patterson 等[3]发现,每年的引文与质量得分之间的相关性较低,但在统计学上具有显著意义(2003 年为-0.227,P<0.001;2004 年为-0.238,P<0.001;2005 年为-0.154,P<0.01),最高质量的论文Q1 (占已发表论文的10%) 被引用的次数是所有论文的平均值的2 倍。Molléri 等[22]发现,研究的严谨性与文献的引用次数存在正相关关系(r=0.263,P<0.01)。
理论上,文献的创新类型和文献在被引维度的表现具有一定关联,高创新级别的文献往往可以吸引更多的引文,这体现在部分学者的研究当中,例如,诺贝尔奖得主的文献往往吸引更多的被引。Garfield 等[23]调研了诺贝尔奖得主和非诺贝尔奖得主的文献生产力和文献被引情况,研究发现两者之间在文献生产力方面并无较大差异,但诺贝尔奖得主的文献被引次数显著高于非诺贝尔奖得主的被引水平。Wagner 等[24]将在1969—2011 年获得诺贝尔生理学或医学奖得主与一组相匹配的科学家进行比较,研究发现获奖者发表的论文更少,但平均引用率更高。Savov 等[13]研究发现,利用自己开发的创新得分公式对文献的创新进行评估,并与文献的被引次数进行相关性分析。文献被引次数和文献创新得分的相关系数为0.2944 (P<0.01),高被引次数的文献往往也有较高的创新得分。Varga[25]将文献的组合创新作为文献创新度评价的尺度,其思想是,文献的创新源于对过去知识体系的重新组织配置,这体现在参考文献或者关键词等知识要素的组合方式上,如果一篇文献的参考文献组合方式在之前没有出现,那么说明该文献具有组合方式上的创新,进一步说明了该文献的知识结构创新。同时,也认为这种 “组合创新” 会影响科学知识的传播方式,这将在引文趋势上体现。也有研究表明,引用的表现不能完全反映文献的创新类型,例如,尽管发现文献创新得分与文献被引之间存在显著的相关,但Savov 等[13]认为这种关系并非线性的,即文献的高被引不一定揭示了文献的高创新,其认为一些真正具有创新性的文献可能尚未引起学界的注意。
文献多样性程度越高,内容越丰富,就越容易吸引信息接受者。Bessi 等[26]探索Facebook 上推送多种内容的页面与推送相似性内容页面的信息消费模式,发现内容多样性的页面受欢迎程度更高。En‐duri 等[16]研究文献多样性和被引之间的关系,文献的多样性与自发表后收到的引文数量相关。与中度多样性论文相比,多样性较低和较高的论文被引用的次数较少。Chakraborty 等[27]利用文献的主题多样性和关键词多样性来预测文献的被引次数,其认为主题多样性有利于提升被引次数。而在Chen[28]的研究当中也提出,文献A 比文献B 获得更高引用的原因可能在于文献A 比文献B 囊括更多、更广泛的主题,即更广泛的主题范围和更多的主题数量。例如,如果文献A 综合多个主题进行阐述,而文章B围绕较少的主题进行探讨,那么文献A 就会由于主题多样性更为丰富而获得更高的引用次数。
2.2.2 其他控制变量
在被引数量上,已知存在的影响因素包括文献本身维度、期刊维度以及作者维度等因素。为了保证较为准确地评估上述三个因素对于引文数量、引文波峰特征的影响,本研究将在引文数量已知的因素当中挑选重要的影响因素,作为模型的控制变量纳入。在引文数量的影响因素当中,学界主要关注的变量为文献的篇幅长短、文献类型、作者的合作情况、期刊影响因子等。
在文献篇幅层面,被证实文献篇幅越长,越能够吸引更多的引用次数[29-30],即较长的论文比较短的论文受到更高的引用次数。其原因可能是,随着文献篇幅的增长,会包含越来越多的数据和想法,这些数据和想法为之后的研究人员提供更多的参考,所以得到引用的可能性更高。此外,文献篇幅还与文献的参考文献数量有关[31],当参考文献数量增加时,由于学者可以通过引文之间的关联搜寻该篇文献,所以该篇文献在学界的可见性增加。
在文献类型上,Vanclay[31]研究发现,综述比研究型的文献吸引的引文数量更多,综合全面的综述年均被引次数在2.0~3.9 次(生态学领域),但是低质量的综述不会得到这样的结果。Patsopoulos 等[32]探讨医学领域的研究设计类型(元分析、随机对照试验、队列研究、病例对照研究、病例报告等) 与被引之间的关联,发现元分析在短期被引和长期被引上更占优势。同时,随机对照试验与病例报告相比,在短期被引和长期被引上具有显著的优势。
在作者的合作情况上,学界主要关注作者的合作规模和合作结构。合作规模即合作数量,包括合作的作者数量、机构数量和国家数量;而合作结构是指跨学科合作等。研究表明,多作者合作的论文比单个作者的论文被施引的更为频繁[33]。因合作而导致的被引数量增加,可能与论文的质量改变有关[34],例如,论文由多领域的专家合作贡献多方面的知识,从而在完成论文的过程中更加严格,文献质量也更高。也可能与论文的被引层面的因素相关,例如,合作者的增加意味着当作者自引时有更多的文献选择,与更高影响力的学者合作会增加文献的可见性等[35]。但Bornmann[36]在研究中指出,文献质量指标几乎不受作者数量、机构数量和国家数量的影响,即合作活动的增加,并不会增加文献的质量,说明这种因合作者增加而导致的被引优势,主要与被引层面的因素有关(如更多的自引可能性)。
在期刊层面,对被引起重要作用的是期刊影响因子[37]。一般来说,期刊的影响因子越高,吸引引文的能力越强。在影响因子较高的期刊上发表文献,会提升知名度,从而获得更多的引用。影响因子越高,期刊的威望越高,论文发表的可信度就越高,论文越容易被访问。
总的来说,在文献被引的影响因素研究的因变量中,主要关注文献的被引数量,即静态的总被引次数,对动态的引文过程不够重视,这可能会遗漏时间轴上重要的引文活动。波峰作为引文动态过程中的重要时间节点,揭示了文献的动态被引特征,波峰的数量特征、时间特征和幅值特征从不同角度反映了文献的被引表现,包括生命周期特点、被引速度快慢和影响力大小。本次研究是一次新颖的尝试,从波峰的三大特征指标出发,探究文献在不同视角下的被引表现差异以及被引表现的影响因素,拓宽了引文分析领域的研究对象和研究方法。
在文献被引的影响因素研究的自变量中,更多的研究聚焦在文献的外部特征,如期刊、作者数量等,缺乏对文献内容特征的探讨。有些研究者分别探究了文献质量、创新类型和文献研究内容多样性对文献总被引次数的影响,但没有研究者将文献的内容特征归纳在一起进行系统性研究。本研究将从文献本身的内容特征出发,深入分析三大文献特征——文献质量、创新类型和文献内容多样性,剖析文献特征对文献被引过程的贡献,探索高质量、高创新论文的波峰典型特征,从而为科研评价提供新的启示。
3 研究假设
文献质量是指文献的研究质量,是一个极为复杂的概念。Polanyi[38]认为,研究质量分为科学性、创新性和科学价值。也就是说,一项质量较高的研究,首先是基于研究证据进行的研究,同时研究过程严谨,研究方法科学合理(即科学性);其次,是整个研究应当具备一定程度的创新,可以为现有科学体系提供新型知识(即创新性);最后,是对其他研究产生了重要影响(即科学价值性)。研究质量是学术出版物得到认可的重要途径,因此,本文提出研究假设H1:
H1: 研究质量对论文的被引表现产生正面影响。
文献的创新类型是指文献的创新程度。在科学的发展过程中,科学研究需要不断突破,突破的水平程度可以理解为文献的创新类型,覆盖的层面包括新颖的假说、新颖的方法、新颖的理论、新颖的模型以及新颖的结果,既可能涵盖对既有知识的增补/改进,也包括对现有研究的冲击与突破[39]。一般认为,对现有研究体系产生冲击与突破的文献具有更高的创新类型,而对既有知识进行增补与改进的研究,在创新类型的表现稍弱。高创新的文献对现有体系的冲击可能导致文献在短期内得不到广泛认可[40],因此,本文提出研究假设H2:
H2:与低创新的文献相比,高度创新的论文被引表现较弱。
文献多样性是指文献的研究内容包含了多个领域或方向的研究内容,这种多样性在跨学科或者跨领域的研究中较为常见。许多学者通过研究合作者之间的跨学科来研究文献的多样性。 Huutoniemi等[41]认为,来自不同领域的作者进行合作会贡献不同的知识,从而对文献的知识结构产生影响。多学科性意味着将不同领域的专业知识进行组合,这将创造新的知识。然而,文献作为科研知识的载体,其多样性的差别不仅仅体现在作者的跨学科性,更体现在其内容本身。即文献在内容上存在多样性,称为文献内容多样性,是指信息载体在内容上的丰富度。理论上,如果文献多样性程度越高,内容越丰富,那么越容易吸引信息接受者。因此,本文提出研究假设H3:
H3:文献的内容多样性对文献的被引表现产生正面影响。
文献被引表现最有代表性的指标是文献获得的总被引次数,因此,上述三个假设可以具体表示为:
H1a:研究质量能够提高论文的总被引次数;
H2a:与低创新的文献相比,高度创新的论文总被引次数更低;
H3a:研究内容的多样性能够提高论文的总被引次数。
然而,文献的被引是动态过程,仅以总被引次数并不能全面地表示文献被引表现。引文波峰(ci‐tation peak) 是指文献在被引过程中到达生命周期的最大值或者局部最大值时的点[42-43]。作为动态被引过程中的关键时点,对波峰及其规律的深度挖掘能够进一步丰富引文分析工具,揭示引文过程中的科学问题,为引文分析提供新的视角。在上文的研究中,本文证实了引文波峰能够有效反映文献动态被引过程的模式特征。例如,波峰时刻累积的被引次数可以作为预测其最终被引次数的重要依据,波峰到达的早晚可以衡量文献在学界的认可速度,通过波峰时刻被引量与周围节点被引量的差距解释当年的研究环境变化等。本研究探究文献特征对被引的影响将跳出静态的总被引次数指标限制,把能够反映动态被引特点的引文波峰各项特征纳入研究范畴,作为被引表现的指征。引文波峰分布特点可以从波峰的不同角度进行刻画,包括波峰的数量特征、时间特征和幅值特征,三者构成波峰的模式特征。
在数量特征上,有研究发现,大多数文献有且只有一个波峰,多波峰的出现提示二次或多次生命周期的出现。文献在逐年被引曲线上表现为多波峰,一般是对多个领域产生影响,从而依次在各领域到达被引高峰。因此,本文提出研究假设H3b:
H3b: 文献内容多样性对波峰数量产生正向影响。
在时间特征上,文献集中在发表后的0~5 年内到达首次波峰和最高峰;到达引文波峰的时间是文献被引速度的有效反映,也可以揭示文献特征。文献质量越高,逐年变化保持较高被引,波峰时间会较晚出现;文献创新程度越高,被学界接纳需要更长时间,从而表现为较晚的波峰时间;文献内容越多样,高被引状态维持较长时间,波峰时间较晚出现。故提出研究假设H1b、H2b、H3c:
H1b:文献质量越高,波峰到达时间越晚;
H2b:与低创新的文献相比,高度创新的论文波峰到达时间较晚;
H3c:文献内容越多样,波峰到达时间越晚。
在幅值特征上,可以构建波峰高度(peak height) 来揭示文献在波峰时刻的幅值特点。定义为:文献在波峰时刻的幅值与邻居节点幅值的差距占波峰幅值的百分比。通过与邻居节点对比得到波峰的相对高度。即对于序列C= [c1,c2,c3,…,cn],文献在第p年到达波峰,波峰幅值为cp,波峰两侧节点的幅值平均值为neighborheight= avg {cp-Δt,…,cp-1,cp+1,…,cp+Δt},则
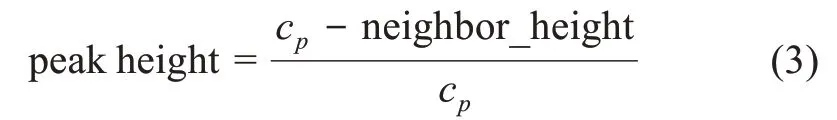
通过与邻居节点对比,将绝对高度(波峰幅值) 转化为相对高度(波峰高度),刻画在波峰时刻文献的影响力高峰。波峰高度反映的是波峰与邻居节点幅值的差距,即波段附近的曲线变化,变化越大,波峰高度的值越接近于1。文献质量越高,则曲线变化越平缓,与周围节点差别越小,波峰高度的值越小;创新程度更高的文献,在受到认可之后,会表现为突然上升,故曲线会骤然变化,波峰高度的值更高。因此,本文提出研究假设H1c、H2c:
H1c:文献质量越高,波峰高度越小;
H2c:与低创新的文献相比,高度创新的论文波峰高度更高。
4 数据和方法
4.1 数据集
文献来源数据选取PubMed 收录的医学和生物学文献,PubMed 是美国国家医学图书馆建设的收录医学相关文献的数据库。根据MeSH 词确定检索词,覆盖医学的12 个学科和生物学的10 个学科。为了保证文献较长的被引时间窗口,发表时间截至2010 年12 月31 日。经过去重处理后,得到文献共836628 篇。由于PubMed 没有文献的被引数据,所以文献被引数据来自Web of Science (WoS) 核心合集,获取截至2019 年的引文数据,利用PMID(PubMed unique identifier) 匹配Web of Science 文献的WoS-ID,一共匹配480725 篇,引文时间窗口大于等于10 年。为了避免极低被引的论文造成干扰,对总被引次数大于10 次的文献进行波峰识别,识别方法参见文献[43]。在识别出波峰的216719 篇文献中,有2867 篇文献被F1000 数据库的专家推荐。F1000 数据库的文献需要经专家挑选,存在一定的推荐门槛,生物医学领域约有2% 的文献会被纳入该数据库[44],故占比较低的结果符合预期。在这些文献中,发表年最早为1948 年,其中发表年小于2001 年的文献仅23 篇。由于时间跨度较大,而时间也会对文献的被引产生一定影响,为方便进一步研究,本文将这些文献剔除,最终剩下2844 篇文献,文献的发表时间跨度为2001—2010 年,引文时间窗为10~20 年。
数据处理流程如图1 所示。
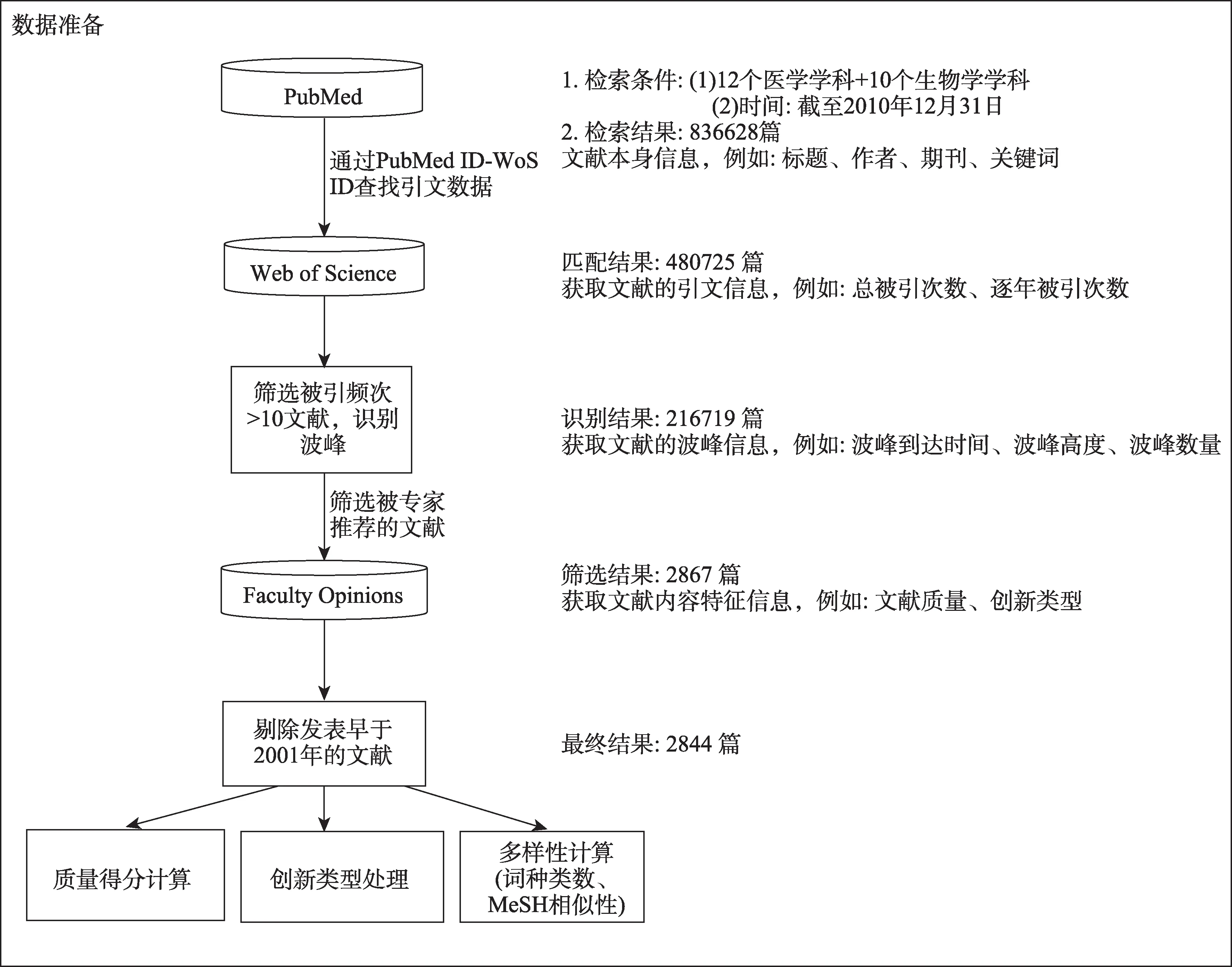
图1 数据准备处理流程图
4.2 变量操作方法
4.2.1 因变量
本研究主要探讨文献内容特征对文献被引的影响。静态的总被引次数在揭示文献的被引模式存在局限,因此,除总被引次数之外,将引文波峰的各项特征作为因变量纳入,包括波峰的数量特征、时间特征和幅值特征。其中,波峰的数量是文献自发表后波峰曲线中被识别的波峰数量;时间特征则采用了最高峰的到达时间,即文献在发表后第几年到达最高峰;幅值特征的指标为波峰高度,是最高峰与周围节点比较得到的结果。
4.2.2 自变量
本研究的自变量包括文献质量、文献创新类型以及文献的内容多样性。 其中,文献质量借助F1000 数据库同行评议的结果,F1000 将同行给出的good/very good/exceptional 标签转化为FFa Score,故文献质量通过FFa 得分进行量化评估。对于文献的创新类型,本研究采用专家对文献给出的标签,由于文献与标签之间存在一对多的关系,故在纳入文献标签时优先纳入区分度更高的标签,例如,new finding 标签最多,当一篇文献同时被标注为new finding 和interesting hypothesis 时,会将其标注为“interesting hypothesis”。 对于文献的内容多样性,本研究利用文献主题词的种类数和主题词之间的相似性均值来表示。
4.2.3 控制变量
本研究将上文探讨的与文献被引相关的影响因素:文献篇幅、文献类型、作者数量以及期刊影响因子均作为控制变量纳入模型。在实际操作中,文献篇幅为文献的页数; 文献类型为PubMed 中的publification type[45],在PubMed 数据库中,publifica‐tion type 主要包括综述类(review/system review/me‐ta analysis)、研究型(randomized controlled trial/clin‐ical trial/clinical study/comparative study/observational study)和期刊论文型(journal article)以及其他(letter/news 等)。由于本研究的数据样本的最晚发表时间为2010 年,故采用2010 年的期刊影响因子数据作为期刊影响因子值。
4.3 统计方法
由于论文的被引次数呈偏态分布,并且是计数资料,在统计中,负二项回归能够较好地解决此类问题。因此,本研究采用负二项回归来分析3 个自变量和4 个控制变量对文献的被引数量的影响。本研究选择波峰数量、波峰的到达时间、波峰高度这三个波峰特征指标作为模型的因变量。波峰高度是0-1 的连续变量,所以模型采用最小二乘估计的多元线性回归方法。波峰数量虽然呈偏态分布的计数资料,但因其数值只有1、2、3 三个数值,导致负二项回归结果的不显著性,故最终将其幂转换后采用多元线性回归。波峰时间本质是连续变量,经对数转换后能够转为相对正态的变量,故采用多元线性回归。自变量的文献创新类型和控制变量中文献类型均属于分类变量,故需要进行哑变量处理。
模型采用逐步回归方法,逐步回归的过程,根据R2和P的结果分析模型的拟合优度。由于在负二项回归、逻辑回归中采用的是极大似然估计方法,而不是最小二乘估计方法,故无法直接计算R2,模型利用伪R2来近似反映模型的拟合情况。如果模型较上一个模型的伪R2更大,同时在统计学上具有显著意义,便认为该模型比上一个模型有效。模型X1 为控制变量与因变量的回归模型,作为基础模型,而X2、X3、X4 则是在模型X1 之上分别加入某一自变量的回归模型。
5 结 果
5.1 描述性统计
由表1 可知,在本研究的样本中,文献的平均篇幅为8.05 页,平均作者数量为7.11。 在Falagas等[31]的研究中,医学文献篇幅的中位数为7.88 页,合作作者数量为9.88。在文献类型上,数量最多的为期刊论文,占比为73.18%;其次为临床研究,占比为18.83%;综述型文献的占比为7.67%;其他类型的文献占比为1.75%。期刊论文是NLM (The Na‐tional Library of Medicine) 数据库的主要文献类型,综述型文献因其需要在较多的研究型文献之上,探讨学科的发展方向,其信息综合度更高。期刊影响因子的均值为12.56;Journal of Emergency Nursing的值最小,为0.43;New England Journal of Medicine的值最大,为53.48;期刊影响因子的中位数为8.23,数据呈右偏分布,说明在被挑选进F1000 数据库的文献并不集中在高影响因子的文献范围中。
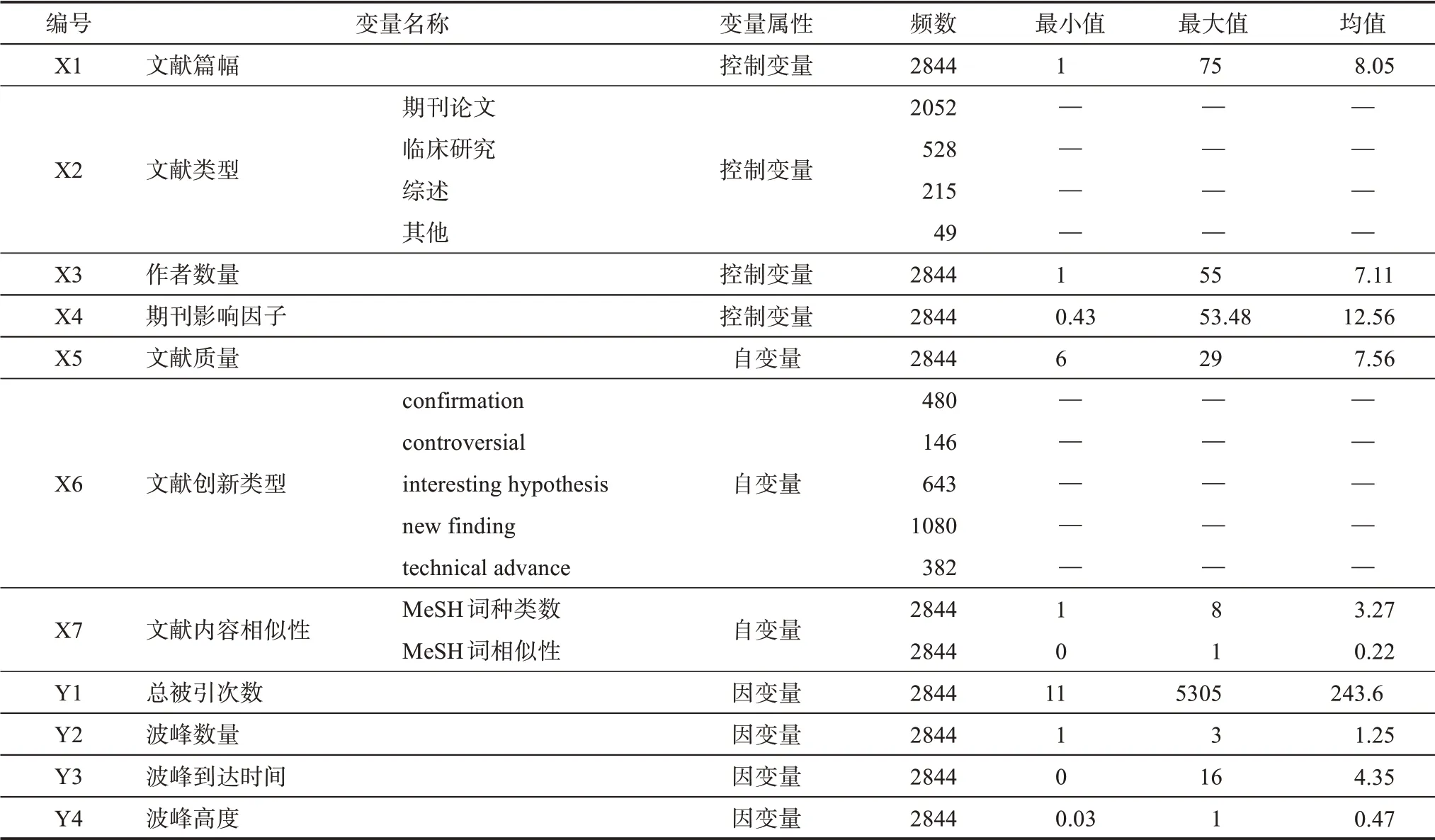
表1 变量描述性统计
对于自变量X5,文献质量得分均值为7.56,靠近得分最小值6。进一步分析发现,得分为6 的文献数量较多,这说明该文献只被推荐1 次,评级为good。在Waltman 等[45]的研究中,文献得到平均推荐数量为1.30,81.1% 的文献仅被推荐1 次。文献被评为good、very good、exceptional 的占比分别约为60%、30% 和10%。
对于自变量X6,由于少量文献专家在给予评分时未给出创新类型,在2844 篇文献中2731 篇文献拥有创新类型。本研究仅考虑了数量较多的5 个标签,其中比例最高的是new finding,比例最低的是controversial。
对于自变量X7,MeSH 词种类数的均值为3.27,MeSH 词相似性的均值为0.22,其中最小值0 值占比较大。测度主题相似性时,若两个MeSH 词属于A 和B 两个不同的树(一层级别不同),则相似度为0,如B03.440.400.425.127.100 与C19.642.355.480.500二者的相似度为0。在结果中文献内容相似性0 值较多,说明这些文献至少采用了2 个跨一层级别的MeSH 主题词,可以认为该文献的内容多样性较大。
5.2 相关性分析
首先进行自变量相关性分析,以排除自变量间的多重共线性。 自变量间进行Pearson 相关分析,结果显示自变量之间不存在强相关性。然后,经VIF (variance inflation factor) 校验,排除了自变量的多重共线性。表2 为自变量相关性分析结果。

表2 变量相关分析结果
5.3 回归结果
对于因变量Y1 总被引次数,模型采用的是负二项回归方法,模型1.1~模型1.4 体现了逐步回归的过程,模型1.1 为控制变量对文献总被引次数的影响;模型1.2 加入自变量1——文献质量得分FFa score,探究文献质量与4 个控制变量对文献总被引次数的影响;模型1.3 在模型1.1 的基础之上加入文献创新类型,探究文献创新类型与4 个控制变量对文献总被引次数的影响;模型1.4 在模型1.1 的基础之上加入文献内容相似性,探究文献内容多样性、文献创新类型、文献质量和4 个控制变量综合对文献总被引次数的影响。考虑到时间可能会对总被引次数产生影响,本研究将文献不同年发表的时间效应控制住。回归结果如表3 所示。
由表3 可知,在模型1.1 中,自由度为2844,P<0.001,通过了卡方统计检验,伪R2为0.037,认为该回归模型是显著的。对于自变量X1 文献篇幅,其回归系数为0.027,P<0.001,认为具有显性的正向效应。在回归过程中,当文献类型控制住之后,文献篇幅的效应为正,则说明文献篇幅越长,其收到引用的概率越大。Falagas 等[31]的研究也支持了这一点。对于自变量X2 文献类型,其基准组为 “其他” 类型的文献,对比 “其他” 类型的文献,期刊论文与临床研究的结果并不显著,综述型文献更具有引用优势。相较于 “其他” 类型的文献(如let‐ter/comments/news 等) 的即时性,综述型文献因其凝聚多项研究结果,对后续研究更具持久性影响。在X3 作者数量上,其与被引次数的回归系数为0.027,P<0.001,作者的数量对文献的总被引次数产生正向的影响。作者数量的增多,会促进文献获得更高的被引次数。X4 期刊影响因子与总被引次数的回归系数为0.050,P<0.001,说明期刊影响因子对总被引次数产生显著的正向效应,影响因子越高,文献被引的可能性越大。
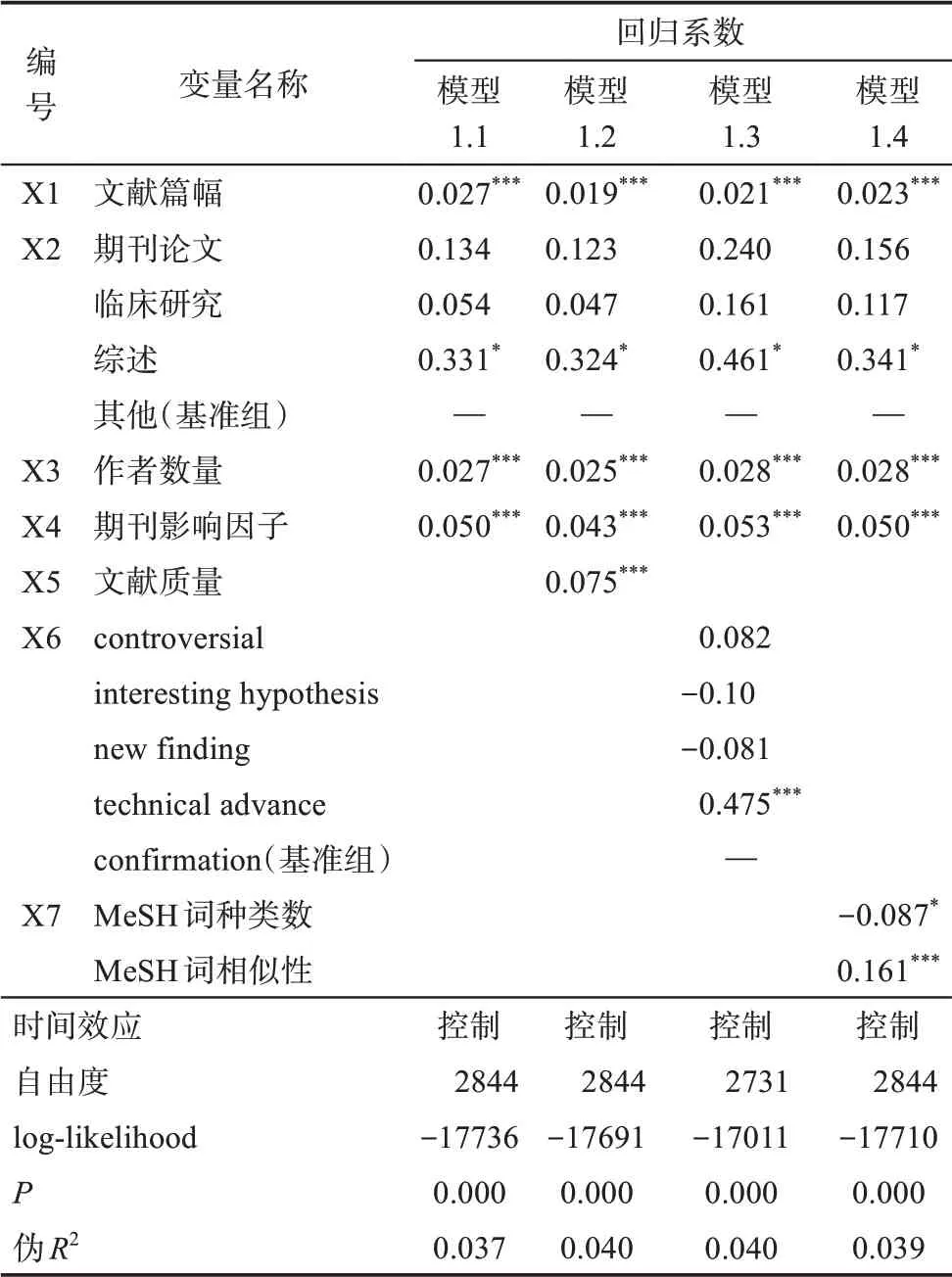
表3 总被引次数回归结果
在模型1.2 中,自由度为2844,P<0.001,伪R2为0.040,与模型1.1 相比,伪R2增加,尽管增加量不大,但具有显著性意义,可以认为该回归模型有效,认为变量X5 文献质量的纳入比控制变量建立的模型拟合效果更好。文献质量得分与总被引次数的回归系数为0.075,P<0.001,说明能够在99.9%的水平上拒绝原假设,认为文献质量得分对总被引次数存在显著的正向效应。文献质量是个复杂的概念,其包含了研究的科学性和研究的贡献性,如果一项研究是高质量的,那么文献可能因为其科学性而成为示范,从而成为学科的经典性文献;也可能因为其贡献性,导致社会价值和科学价值较大,影响范围更广,而获得更多引用。
在模型1.3 中,自由度为2731,这是由于部分样本在文献创新类型字段上缺失,P<0.001 说明通过卡方有效性检验。而伪R2为0.040,与模型1.1 相比,伪R2增加,认为该回归模型有效,即认为纳入变量X6 文献创新类型能够提升模型的拟合效果。文献创新类型中的基准组为confirmation,与confir‐mation 相比,对总被引次数的效益具有显著性差异的是technical advance;technical advance 是对研究进行技术点的创新,与confirmation 仅是对前人研究进行验证相比,其创新类型更高,因此可以获得更多的总被引次数。
在模型1.4 中,自由度为2844,P<0.001,模型通过卡方有效性检验。同时,可以观察到伪R2为0.039,与模型1.1 相比,具有显著性的微弱增长,认为该回归模型有效,纳入变量X7 后,模型的拟合效果更佳。变量X7 主要分为两个指标:MeSH 词种类数与总被引次数的回归系数为-0.087,P<0.05,说明主题词种类越丰富,总被引次数越低;MeSH词相似性与总被引次数的回归系数为0.161,P<0.001。说明文献内容相似性越高,即文献内容多样性越低,总被引次数越高。这与最开始的研究假设H3a 多样性越高的文献会吸引更多的引用的观点相反。文献内容相似性高,说明其研究主题之间的距离较近,那么文献比较可能是深入型研究。
对于因变量Y2 波峰数量,由于因变量的值为离散变量,最小值为1,最大值为3,故将其转为以10 为底的幂指数后进行多元线性回归。对于最小二乘法的线性回归模型,采用R2估算模型的拟合度。由于R2的大小是自变量个数的非递减函数,即自变量的增加不会减小R2的值,所以单纯比较模型R2大小不能判断模型是否拟合得更好,因此,统计学上增加了调整后的R2,通过比较调整后的R2大小,可以判断模型的拟合效果,故在表4 中列出的为调整后的R2。
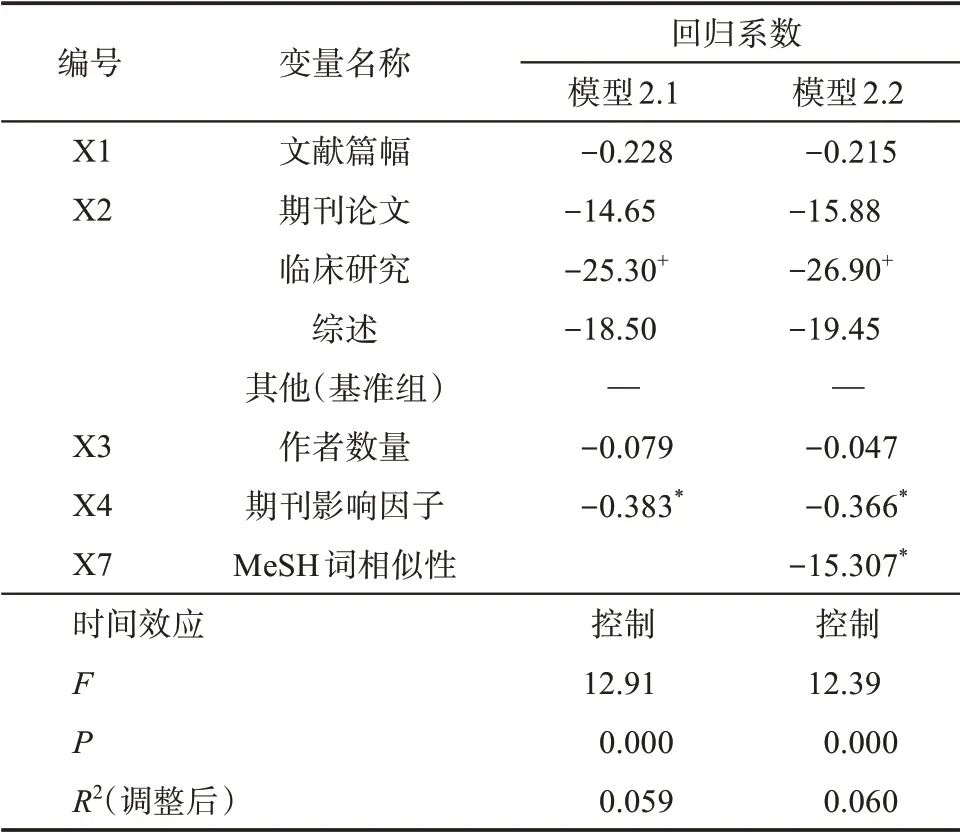
表4 波峰数量回归结果
由表4可知,在模型2.1 中,F=12.91,P<0.001,说明模型有效。控制变量中对波峰数量产生显著影响的变量是期刊影响因子,回归系数为-0.383,P<0.05,发表在高影响因子期刊的文献,更多地表现为单波峰。在P<0.1 的水平下,临床研究型的文献与其他类型的文献相比,被引曲线的波峰数量更少。
在模型2.2 中,F=12.39,P<0.001,调整后R2比模型2.1 稍高,说明模型有效。自变量X7 MeSH 词相似性与波峰数量的回归系数为-15.307,P<0.05,这种显著的负效应提示,文献的内容相似性越高,波峰数量越少,即文献内容越丰富,文献的被引曲线就越有可能表现为多个波峰。
对于因变量Y3 波峰到达时间,因变量的值为离散变量,最小值为0,最大值为16,数据呈左偏分布,故将其数值加1 后取对数,即因变量的数值转化为ln(波峰到达时间+1),多元线性回归结果如表5 所示。
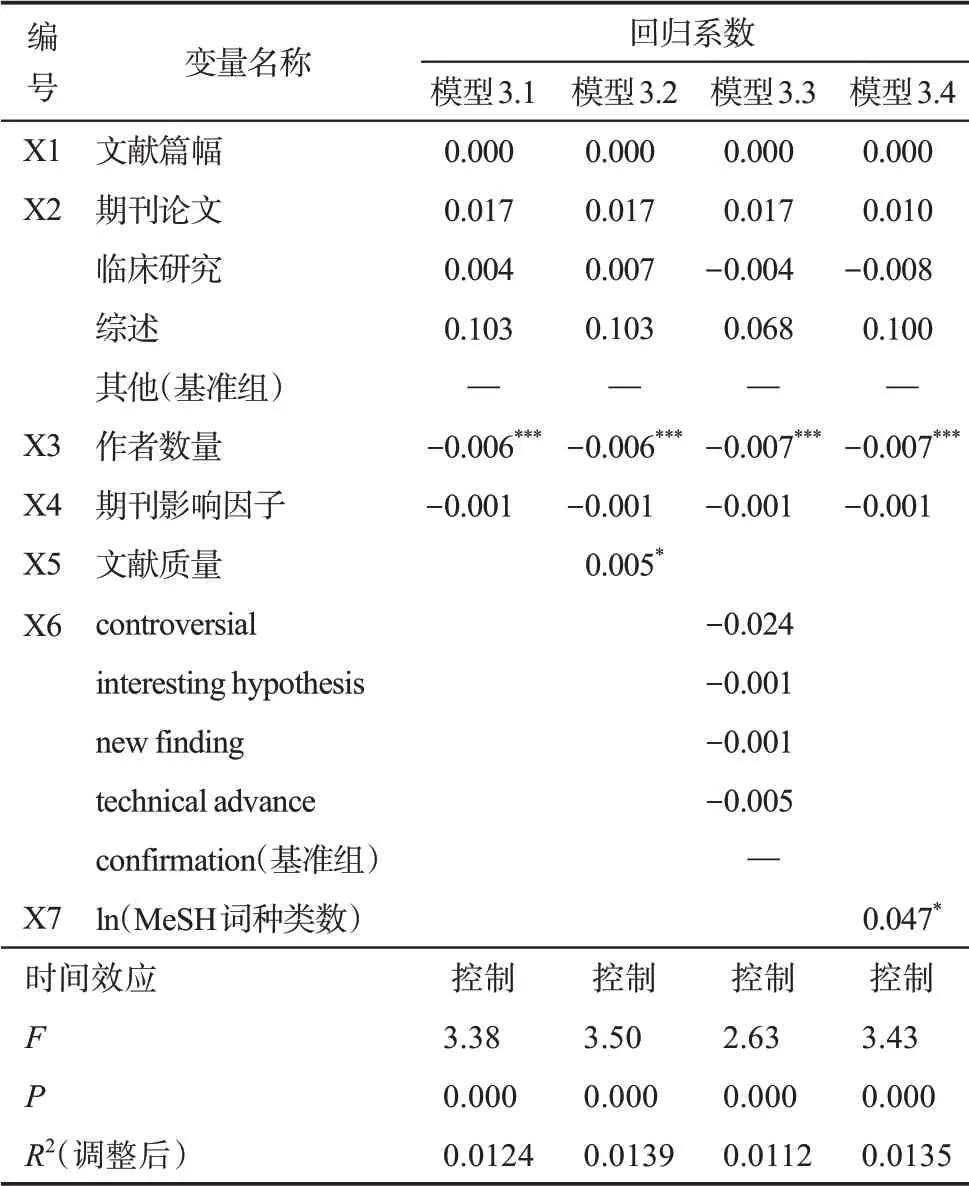
表5 波峰到达时间回归结果
由表5 可知,在模型3.1 中,F=3.38,P<0.001,模型有效。对波峰到达时间产生显著效应的是作者数量,作者数量越多,波峰到达时间越早(回归系数为-0.006,P<0.001)。文献的合作者越多,其影响力和可见度越高,这可能促进了文献更早到达引文波峰。
在模型3.2 中,F=3.50,P<0.001,调整后R2为0.0139,较模型3.1 的调整后R2有所增长,说明新增加的自变量文献质量提高了模型的拟合优度。文献质量对波峰到达时间的回归系数为0.005,P<0.05,说明文献质量越高,波峰到达时间越晚。文献质量越高,吸引的引文越多,逐年被引次数都保持较高的被引水平,需要经历长持续的高被引状态后才到达被引高峰,最终波峰到达时间较晚。
在模型3.3 中,F=2.63,P<0.001,调整后R2为0.0112,比模型3.1 的调整后R2低,说明X6 文献创新类型的引入并未增加模型的拟合优度。回归系数和显著性提示,与confirmation 相比,其他组的波峰到达时间并未出现显著差别。
在模型3.4 中,F=3.43,P<0.001,调整后R2为0.0135,比模型3.1 的调整后R2高,说明文献内容多样性变量的加入提高了模型的拟合优度。MeSH词种类数与波峰到达时间的回归系数为0.047,P<0.05,说明文献的主题词种类越丰富,被引曲线的波峰到达时间越晚。因变量是最高峰的到达时间,对于种类越丰富的文献,可能因为其影响的领域广泛性,而出现了二次生命周期,故波峰到达时间较晚。
对于因变量Y4 波峰高度,因为其属于连续型变量(范围为0~1),本研究采用的是多元线性回归方法;因为波峰高度偏态分布,故将波峰高度数值加1 取对数后再进行回归。模型4.1 为控制变量对波峰高度的影响(控制变量为文献类型、作者数量、期刊影响因子);模型4.2 加入自变量1——文献质量得分FFa score,探究文献质量与3 个控制变量对文献波峰高度的影响;模型2.3 在模型4.1 的基础之上加入文献创新类型,探究文献创新类型与3个控制变量对文献波峰高度的影响;考虑到时间因素可能会对波峰高度产生影响,回归时将文献因发表年不同而产生的时间效应也控制住。回归结果如表6 所示。
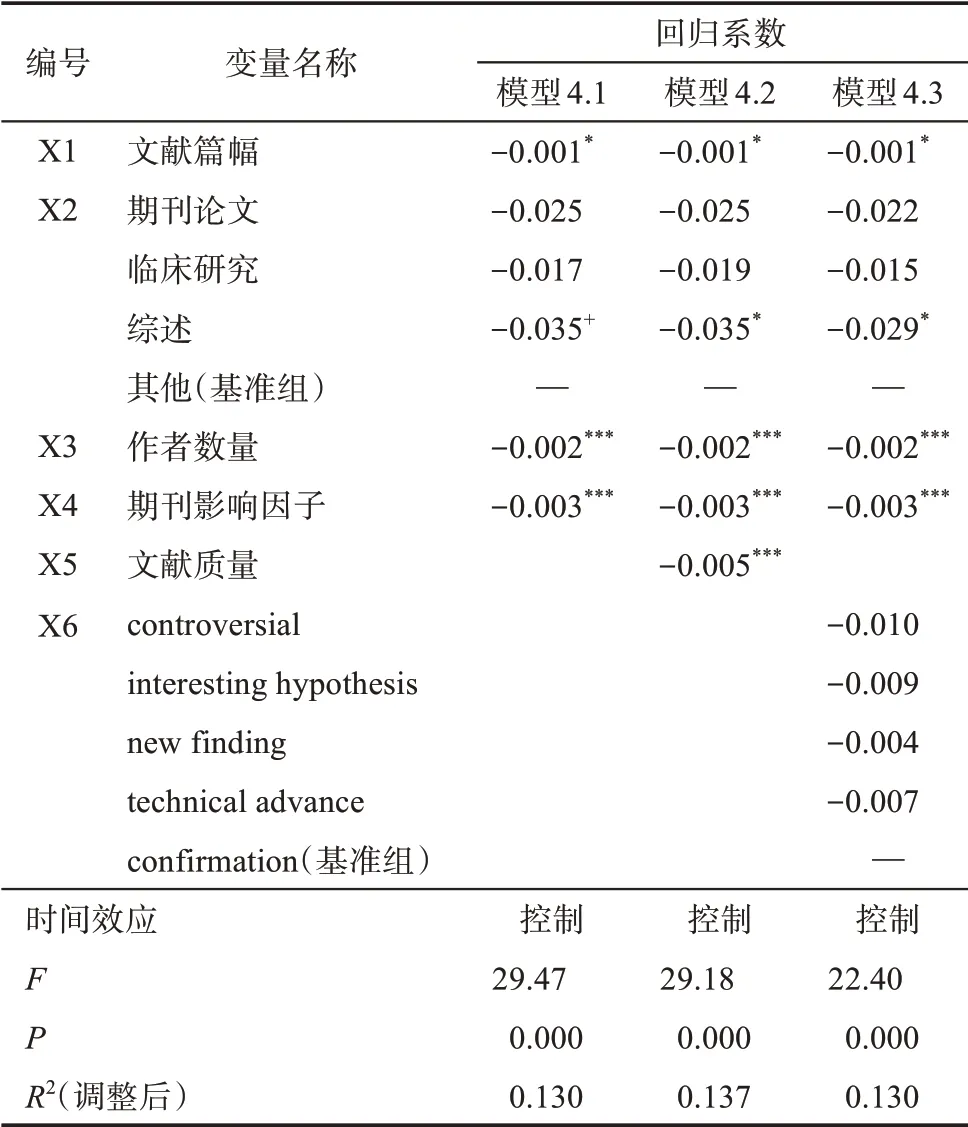
表6 波峰高度回归结果
由表6可知,在模型4.1中,F=29.47,P<0.001,说明该模型通过了检验,模型有效。文献类型中选择的基准组为 “其他” 型文献,与 “其他”型文献相比,期刊论文和临床研究型的波峰高度值分别是-0.025 和-0.017,但遗憾的是未通过显著性检验,所以不能认为期刊论文、临床研究型文献与“其他” 型文献的波峰高度值存在显著性差异。与“其他” 型文献相比,存在显著性差异的是综述组,说明综述组文献的波峰高度与 “其他” 型文献相比更低,即综述型文献的被引曲线在波峰附近的走势更平缓(与 “其他” 型文献相比)。作者数量与波峰高度的回归系数为-0.002,P<0.001,说明作者数量对波峰高度产生负效应,作者数量的增加会降低被引曲线在波峰附近的突增性。期刊影响因子与波峰高度的回归系数为-0.003,P<0.001,认为期刊影响因子负向影响波峰高度,并且这种影响是显著的。说明波峰高度会随着期刊影响因子的增加而降低,在高影响因子期刊上发表的文献,其在波峰附近展现为平缓上升平缓下降的可能性越高。
在模型4.2 中,F=29.18,P<0.001,同时模型调整后R2为0.137,比模型4.1 调整后的R2(0.130) 有所提升,认为模型有效,即新增自变量X5 文献质量能够有效提升模型的拟合优度。文献质量得分与波峰高度呈现的是显著的负向效应(回归系数为-0.007,P<0.001),说明文献质量越高,波峰高度越低,波峰附近的邻居节点和波峰的差距缩小,文献在波峰附近表现为平缓上升-平缓下降。
在模型4.3 中,F=22.40,P<0.001,但由于模型调整后R2为0.130,和模型4.1 相比没有增加,则认为模型在纳入自变量X6 文献创新类型后没有提升模型的拟合优度,故模型无效。同时,模型中文献创新类型与波峰高度的回归结果也表示,与基准组conformation 相比,其他四组均未对波峰高度产生显著的效应,因此,本研究拒绝了假设H2c——文献创新类型对波峰高度产生影响。综合因变量Y1总被引次数的回归结果,文献创新类型可以影响总被引次数,但对波峰高度无显著影响。
本研究探究了文献特征对被引相关4 个因变量(含静态的总被引次数和动态的波峰特征) 的影响,回归结果汇总如图2 所示,在第3 节提出的研究假设中,文献质量对总被引次数、波峰时间、波峰高度均产生显著的影响(H1a、H1b、H1c 成立),文献创新类型对总被引次数产生显著影响(H2a),文献内容多样性被证实对总被引次数、波峰数量、波峰时间具有显著作用(H3a、H3b、H3c 成立),文献创新类型对波峰时间和波峰高度的影响尚不显著(H2b、H2c 未能证明成立)。

图2 变量关系回归结果汇总
6 讨论与结论
本研究主要分析文献内容特征对引文动态的影响。文献内容特征从三个方面切入,包括文献的质量、文献的创新类型和文献在内容上的多样性。在被引方面的指标,本研究选用了总被引次数、波峰数量、波峰到达时间和波峰高度。由于文献的质量和创新类型较难定量衡量,本研究最终利用了医学生物学领域同行评议系统——F1000 数据库的专家评价数据。采用F1000 数据库根据专家意见所得到的文献质量得分FFa score 来表示文献的质量,采用专家给文献打的标签作为创新类型。而在文献内容的多样性上,本研究利用PubMed 数据库的MeSH主题词,根据MeSH 主题词的种类数和MeSH 主题词相似性,间接表示文献内容多样性。
通过回归分析发现,文献总被引次数受控制变量文献篇幅、文献类型、作者数量和期刊影响因子的影响,在自变量文献特征上,文献质量、文献创新类型以及文献内容相似性均存在显著的影响效应。波峰数量受文献内容多样性的影响,研究内容越丰富,越会增加文献获得二次生命周期的机会。波峰到达时间的回归结果显示,文献质量越高,越会表现为更晚的波峰到达时间;文献内容的多样性会延迟波峰到达时间。波峰高度受控制变量文献篇幅、文献类型、作者数量、期刊影响因子的影响,在自变量中,仅文献质量与波峰高度具有显著的作用。文献质量对波峰高度产生的效应方向与其对总被引次数的效应方向相反。由于波峰高度值越大的文献,其在波峰处的变化性也越大,这说明文献质量越高,在被引上越会表现为更高的总被引次数和波峰处更平缓的曲线变化。文献创新类型在波峰到达时间、波峰高度上的不显著性,揭示了文献在波峰幅值的被引表现受文献创新程度的影响较小,因此,波峰高度和波峰到达时间指标可更多地用于反映文献的质量;文献被引曲线的波峰数量、波峰到达时间能够在一定程度上揭示文献的内容多样性。
本文存在一些不足。在研究数据上,波峰识别所采用的是医学和生物学领域的数据,其中文献类型与其他学科的文献类型划分存在一定差异,故本研究的结论是否可以推广至其他学科仍需要进一步探讨。 此外,鉴于Faculty Opinions 数据库的特殊性,其成立时间相对较晚,同时,专家推荐文献时会有一定的专业门槛,导致最终进行实验的文献与初始数据集相差较大。由于文献是经由各位专家筛选的结果,故这些文献可能拥有更高的被引次数和更高的研究质量,这会导致研究结论存在一定的偏倚。后续研究中,可以尝试文献体量较大的同行评议数据库为样本,做相应的研究补充,以保证结论的健壮性。本研究探讨的文献内容特征中的文献质量与文献特征,虽然在Mohammadi 等[7]、 Wang等[46]的研究中证实二者不存在较强关联,但往往专家在进行同行评议时会考虑文献的创新性,在今后的研究中仍需探索优化更合适的文献内容特征的量化指标。本研究仅考虑了文献内容特征对波峰的影响,实际上,研究结果表明,尚存在其他因素等待进一步挖掘。例如,从引文网络视角来看,被引和波峰的发生。在创新扩散的过程中,对于采纳者来说,决定创新是否被采纳起决定性作用的是采纳者的主观判断,而不是这项创新本身的内容。例如,如果采纳者是创新先驱者,在创新问世之初他就会率先采纳,而从众者则在后期才采纳这项创新。故从施引者角度,思考引文的扩散过程,也具有潜在的研究价值。
猜你喜欢
检察风云(2022年10期)2022-06-02
数学小灵通(1-2年级)(2021年10期)2021-11-05
商用汽车(2021年4期)2021-10-13
宁波大学学报(理工版)(2021年5期)2021-09-14
作文周刊·小学一年级版(2021年36期)2021-01-14
科学导报·学术(2020年40期)2020-10-30
阅读与作文(小学高年级版)(2020年8期)2020-09-12
中国科技纵横(2019年16期)2019-12-02
小学生学习指导(低年级)(2019年3期)2019-04-22
小猕猴智力画刊(2016年6期)2016-05-14
