
知识发现视角下词汇历时语义挖掘与可视化研究
2021-10-26 05:41吴宗大
情报学报 2021年10期
潘 俊,吴宗大
(1. 浙江科技学院理学院大数据科学系,杭州 310023;2. 绍兴文理学院计算机系,绍兴 312000;3. 南京大学信息管理学院,南京 210093)
1 引 言
词汇是语言系统中具有明确语义的基本单位,词汇的语义表示属于自然语言处理领域的基础研究,在词义消歧、智能检索、机器翻译、自动问答、 知识工程等领域具有广泛的应用价值[1]。 然而,随着时间的推移,词汇的语义会因政治、经济、科技和文化等因素的影响而发生扩大、缩小或迁移等现象。例如,“跳水” 最初指的是一项水上体育运动,随着社会经济的发展,“跳水” 的词义得到扩大,产生了新的含义,是指金融领域股票或基金价格的大幅下跌。又如,“云”“收官”“双簧”“催化剂”“接轨”“旗舰”“软件”“防火墙” 等词汇,分别从自然、围棋、戏曲、化学、交通、军事、计算机、建筑等领域,逐渐扩展到其他领域,并形成新的意义。如何从历时的角度获得时序敏感的词汇语义表示,对优化现有的语义处理系统,具有十分重要的意义[2]。 此外,词汇语义的历时变化,与人类社会的发展息息相关,其中记录着人类认识世界、改变世界的过程,蕴含着反映社会生活整体变化的方方面面的知识,是计算社会学和知识工程研究的重要课题[3]。
词汇语义历时研究的基础是历时语料,其来源主要包括图书、报纸、期刊、网络文本等具有明确时序标注的语料数据。早期,相关工作主要集中在对历时语料的词频分析上[4-10],这些研究的思路是统计词汇在特定文本或语料中的使用频率,根据词频随时间变化的情况,探讨语言演变与社会变迁的关联,已经取得许多重要的发现。词频模型虽然直观、简单,但是难以刻画词汇语义内涵的变化,也不能反映词汇之间语义关系的变化情况,在追踪深层次的词汇语义历时变化时效果有限。
近年来,随着深度学习等技术的研究进展,分布式表示逐渐成为词汇表示的主流[11]。这类方法旨在将符号形式的词汇表示成数学形式的向量,并具有语义可计算的特点:一方面,向量表示可以作为自然语言处理多种任务的输入;另一方面,利用向量的一些几何性质,可以度量词汇的语义相关性,或进行语义推理等,已经在知识组织和语言智能等领域得到广泛应用。本质上,词汇分布式表示是对语料使用模式和偏好的反映[12],因此,若将语料打上时间戳标记,用不同时期的语料分别训练词向量模型,则可以得到反映时代特征的时序敏感的历时词向量。对此,信息科学领域的学者已经给出了一些有效的学习模型[13-19]。同时,基于词汇的历时词向量,研究者在词汇语义演变规律[16,20-21]、词汇历时语义关系抽取[22-24]、社会文化变迁[3,19]、舆情事件预测[25-26]等方面也取得了许多的成果。
然而,纵观现有研究,针对中文词汇的历时语义研究数量较少,仅有的工作主要集中在对词频的历时考察上[9-10,27-28],对分布式历时词向量的研究还极少。此外,已有的词汇历时语义表示学习主要针对学习模型,没有从知识发现的角度考虑历时词向量的应用价值问题。随着信息技术的迅速发展,数据获取方式日益便捷,语料数据的积累速度也在不断加快,如何有效地对各类语料数据进行整理和挖掘,实现从文本到数据再到知识的转化,已成为需要迫切解决的任务。在此背景下,本研究尝试建立一个通用的词汇历时语义挖掘框架,将语料预处理、历时词向量训练、语义计算等封装成服务的形式以供业务逻辑调用,并提出基于XML (extensi‐ble markup language) 配置的数据定制和分析方法,以支撑词汇历时语义计算和知识挖掘的实际需求。基于该框架,本研究以1946 年5 月—2003 年12 月的《人民日报》 文本为数据来源,构建了一个多维度、深层次的知识发现和语义计算平台,以展示词汇历时词向量在数字人文和社会计算研究中的可能应用模式。本研究提出的方法框架具有较好的通用性,通过二次开发,能灵活构建面向知识发现的各类应用,并可方便推广到对其他历时语料的知识挖掘,从而为人文学者根据学术兴趣和研究关注点展开具体的应用研究提供辅助。
2 相关研究综述
研究词汇历时演变最直接的方法是计算词频随时间变化的情况,通过对词汇使用频次、分布等变化的统计,可以测量词汇的稳定性,发现语言的使用规律,观察语言变化与社会文化、科学技术、政治经济发展的历时联系等。相关工作主要涉及三类历时文本:①图书文本。例如,谷歌公司于2011 年发布全球图书词频统计数据库①http://books.google.com/ngrams,可对1800—2000年出版的共5195769 本图书的单词和词组进行历时频次统计,研究者利用该数据库和词频工具进行定量分析和知识挖掘,取得了一系列发现[4-6];欧阳剑[27]搜集大规模中国古籍文本并建立历时语料库,以词频分析统计为核心,构建了古籍词频历时统计分析平台,获得了若干基于量化分析的结果。②报纸期刊。例如,金观涛等[28]整理近代报纸期刊文献,通过分析不同时期表达相同观念的不同词汇的词频变化,考察中国现代政治术语的形成和演变;荀恩东等[9]搜集了约60 年的同质新闻语料,开发了现代汉语历时检索系统,通过可视化技术直观显示词频的历时变化。 ③网络文本。 例如,Leskovec等[8]从互联网上采集海量新闻和博客文章,抽取其中的热门短语和短句,跟踪这些短语短句的历时频率变化,为美国政治文化的发展潮流和变迁研究提供新的视角。
基于上述词频模型的研究,主要关注海量语料中词汇的频次、频率、频序、分布等经典表征形式,直观简单,但难以刻画词汇语义内涵的变化,也不能表达词汇间的语义关联。要表达词义,有一种方式是使用分布式表示[11,29],即将词汇表示成稠密实向量,用词汇之间的向量距离来表示语义相关度。如何通过历时语料获得时序敏感的词向量,研究人员已经给出了不少有效方法,大致可分为以下三类。
(1) 基于共现统计的方法,使用词汇的历时性上下文语境来表达词义。例如,Gulordava 等[30]使用词汇的2-gram 来刻画历时词义,并使用了局部互信息(local mutual information,LMI) 来构建共现矩阵。Zou 等[31]使用词汇所在子句的其他词汇来刻画语义,并使用点互信息(pointwise mutual informa‐tion,PMI) 来构建共现矩阵。这一类方法的缺点是,所构建的共现矩阵存在高维稀疏问题,且缺乏概率意义上的解释。
(2) 基于概率的动态主题模型,其思想是利用词汇在主题上的分布来刻画词义,进而挖掘词汇语义的历时变化[26,32-34]。将主题模型应用于词汇聚类,能有效识别聚类中词汇的语义变化,但在追踪单个词汇语义的变化时效果有限。
(3) 基于预测的动态词向量模型,将历时语料按时期划分为不同的数据集,采用词汇表示学习模型来学习词义[13-15,17-18]。这些工作的基础可追溯到Bengio 等[35]于2003 年提出的神经网络概率语言模型(neural probabilistic language model,NPLM),即把词向量作为神经网络模型的参数来训练,通过对语言模型(预测一个词出现在给定词序列之后的概率) 的学习,得到词汇的向量表示。
基于预测的神经网络模型的参数是随机初始化的[36],在不同时期数据集上训练得到的词向量,并不处于同一个语义空间,因此,不能直接计算语义相关度。对齐语义空间的思路,主要有两种。一种思路是在模型训练时保持词向量的连续性。例如,Kim 等[13]采用了递增迭代更新的SGNS (skip-gram with negative sampling) 模型,用前一个时间周期的训练结果作为下一时间周期的输入;Peng 等[14]和Kaji 等[15]的工作均借鉴这一迭代更新的思想来训练历时词向量。另一种思路是假设大部分词汇的语义具有一定的稳定性,通过线性变换将不同时期的词向量对齐到同一个语义空间。例如,Kulkarni 等[17]采用正交分解法,通过最小化t时刻和t-1 时刻相同单词之间的距离,将t时刻的向量空间转变到t-1 时刻的向量空间;Yao 等[19]进一步提出t时刻的向量空间不仅受前后时刻的影响,还与其他时刻的向量空间有关,并据此对齐语义空间。
建立在历时语料上的历时词向量兼具语义可计算性和时序敏感性,其应用目前主要有两方面。一方面,是通过观测词汇语义变化,研究词汇语义演变的规律,例如,文献[16]通过对4 种语言历时200年语料的分析,总结出语义变迁的两条规律:一致性规律表明高词频词汇语义倾向于稳定,革新性规律表明多义词的语义变化更为剧烈。另一方面,是挖掘分析词汇语义变背后隐藏着的社会、政治、文化等方面变迁的知识[37-38],例如,Garg 等[37]以十年为单位,通过历时词向量探讨了近百年来美国社会在性别和种族两方面的社会偏见趋势,研究结果表明特定的偏见存在随着时间推移而减少的趋势,也展示了其他类型的刻板印象随时间增加的现象。此外,通过实时分析短时期内词汇语义的变化,国外相关研究人员还对民众骚乱,以及政治抗议集会预测进行了研究[25-26]。
综上所述,针对历时语料的词汇语义表示及其应用研究,已经取得许多成果。研究人员对历时词向量的训练模型进行了研究,有些模型已被应用于词汇语义变化规律发现、社会事件监测等领域。同时,相关工作还存在一些不足:①目前历时词向量研究多针对英文,而汉语词汇的历时语义研究主要集中在词频模型上,这限制了更深层次的知识发现;②现有工作主要针对具体而分散的领域主题,没有形成一个通用完整的模型框架,难以支撑对各类学术问题的知识挖掘需求;③虽然研究者已提出多种历时词向量的训练方法,但在应用方面,还未发现面向中文词汇知识发现的历时语义计算研究。
针对上述不足,本文重点从两方面展开研究:①设计一个通用的词汇历时语义挖掘框架,建立松耦合的可配置的服务式架构,底层提供数据清洗、数据规范化、历时词向量训练等服务,中间层通过XML 配置制定基础数据的抽取策略并完成界面映射,上层通过对服务的组合,实现知识发现、可视化等业务逻辑,框架应具有高可扩展性,能够即插即用地通过维度筛选和服务组合来构建具体应用。②以《人民日报》 历时语料为数据源,构建一个支持多维挖掘并可快速定制的词汇历时语义计算平台,以展示本文框架的落地应用。
3 研究框架
本文提出的面向知识发现的词汇历时语义挖掘框架如图1 所示。主要步骤为:①收集历时语料数据并按照规范进行清洗和标注;②构建历时词向量训练和词汇语义计算等关键服务,并生成面向主题的数据集;③依据研究主题选择历时词向量数据集,完成知识挖掘与可视化。具体处理过程描述如下。
(1) 深加工历时语料库的建立。首先,确定语料库类型和数据来源,语料数据应具备相当规模,并有明确的时间信息。其次,制定加工规范,并对语料进行加工。以报纸语料为例,对每一则语料,可提取版面、栏目等信息,打上刊发日期时间戳标记;再次,对语料进行清洗,去掉冗余噪音数据(如声明、符号、乱码或无关字符);最后,完成分词和词性标注,并通过统计TF-IDF (term frequen‐cy-inverse document frequency)值或利用TextRank等关键词抽取算法,从语料中提取关键词,最终得到规范化的加工历时语料库。
(2) 关键服务的实现和管理。将历时词向量训练、历时语义相关度计算、词向量聚类、词向量类比推理等计算任务,封装为服务的形式并提供外部调用。利用配置文件定制数据抽取策略,建立各类主题数据集:①通过时期、版面栏目、关键词等各个维度筛选得到所关注的熟语料;②通过对时间粒度、词向量训练模型、训练参数的不同设置,在同一语料数据集上训练得到不同的历时词向量;③通过词性、命名实体类型等维度配置和映射,建立各类面向主题的历时词汇数据集。
(3) 知识发现与可视化模块的构建。根据研究者的学术兴趣,选择相关历时词向量数据集或主题数据集,调用数据语义计算服务,实现历时语义近邻词、语义变迁、历时关系类比等知识发现任务。
从图1 的系统架构可以看出:①通过将语料加工、词向量训练、语义计算等任务分解为各个独立的细粒度服务,能够实现业务逻辑的松耦合,便于任务类型的扩展。②采用XML 作为熟语料库和历时词向量数据集的维度配置元数据描述语言,能支持研究者根据学术关注点进行数据定制。③通过配置文件和数据语义计算服务的组合,在提供知识挖掘及可视化的同时,提供底层语料级别的循证数据,使得知识发现有语料级别的数据支撑。
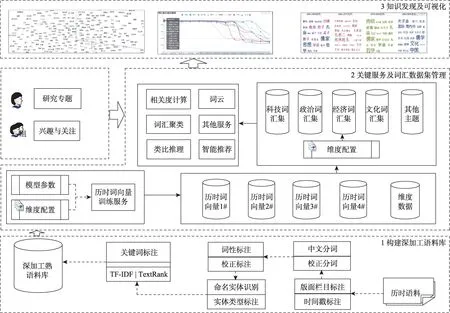
图1 面向知识发现的历时词汇语义挖掘系统架构
综上所述,本文框架具有可热插拔的优点,表现在对深加工语料各种维度的配置,以及对历时词向量各种特征维度的筛选定制上,研究者可根据研究兴趣建立各类数据集,为上层的可视化知识发现定制基础数据。
4 《人民日报》词汇历时语义知识发现平台的构建
基于第3 节提出的系统框架,本文以《人民日报》 历时语料为例进行实证研究,构建面向知识发现的现代汉语词汇历时语义计算平台,一方面从共时角度分时段展示特定时期词汇语义的相关度情况,另一方面从历时角度分析词汇语义的时序变迁过程。
4.1 数据源与预处理
报纸是构建历时语料的理想来源,报纸语言具有规范、简洁的特点,与社会生活息息相关,并具有明确的时序信息。《人民日报》 作为中国共产党中央委员会机关报,自创办以来一直承担着宣传党的理论和路线方针政策以及中央重大决策部署等的使命,完整地记录了不同时期中国政治、经济、文化和社会生活等方方面面的变迁,其语料具有重要价值,图情文献领域的许多研究就是建立在《人民日报》 语料的基础上的,但从历时角度切入的研究工作还较少,尤其缺少对历时词向量的研究。为此,本研究选用了1946—2003 年刊出的《人民日报》 文本作为语料数据源(其中1946 年5 月15 日至1948 年6 月15 日为晋冀鲁豫《人民日报》),并展开实证研究。
在数据预处理阶段,首先构建停用词表,去除标点符号、拉丁字母、数学符号、特殊符号及其他停用词,并使用NLPIR (natural language processing and information retrieval) 汉语分词组件和命名实体抽取组件对语料库进行分词、词性标注和命名实体识别[39]。由于部分专题研究需要观察特定词组的语义演变,因此,在分词时使用自定义词典供用户构建特定分词与短语,例如,“中国人民的老朋友”“不受欢迎的人” 等属于《人民日报》 话语体系的自定义短语词汇。
为了方便研究者根据学术兴趣从各个维度筛选历时语料并训练词向量,本研究从每一则语料中,抽取版面、专栏、标题、关键词等信息作为维度,其中,语料关键词的识别采用TF-IDF 算法。历时语料需要时间戳标记,并要对原始历时语料作单位分割,一般来说,较高的粒度(十年甚至百年) 更容易发现语言的变化规律,较小的粒度则多用于分析社会文化的变迁。早期,不少研究都采用了较大的粒度[4,7,30],近年来的一些工作开始以低粒度(如以年为单位) 考察词汇语义变迁,更关注实际问题[13,17,19,22]。本研究为每一则语料打上时间戳标记,方便后续研究根据具体需要,按不同粒度将所筛选的语料划分为不同的片段并进行训练。表1 给出了经过预处理后的标注结果的一则样例。
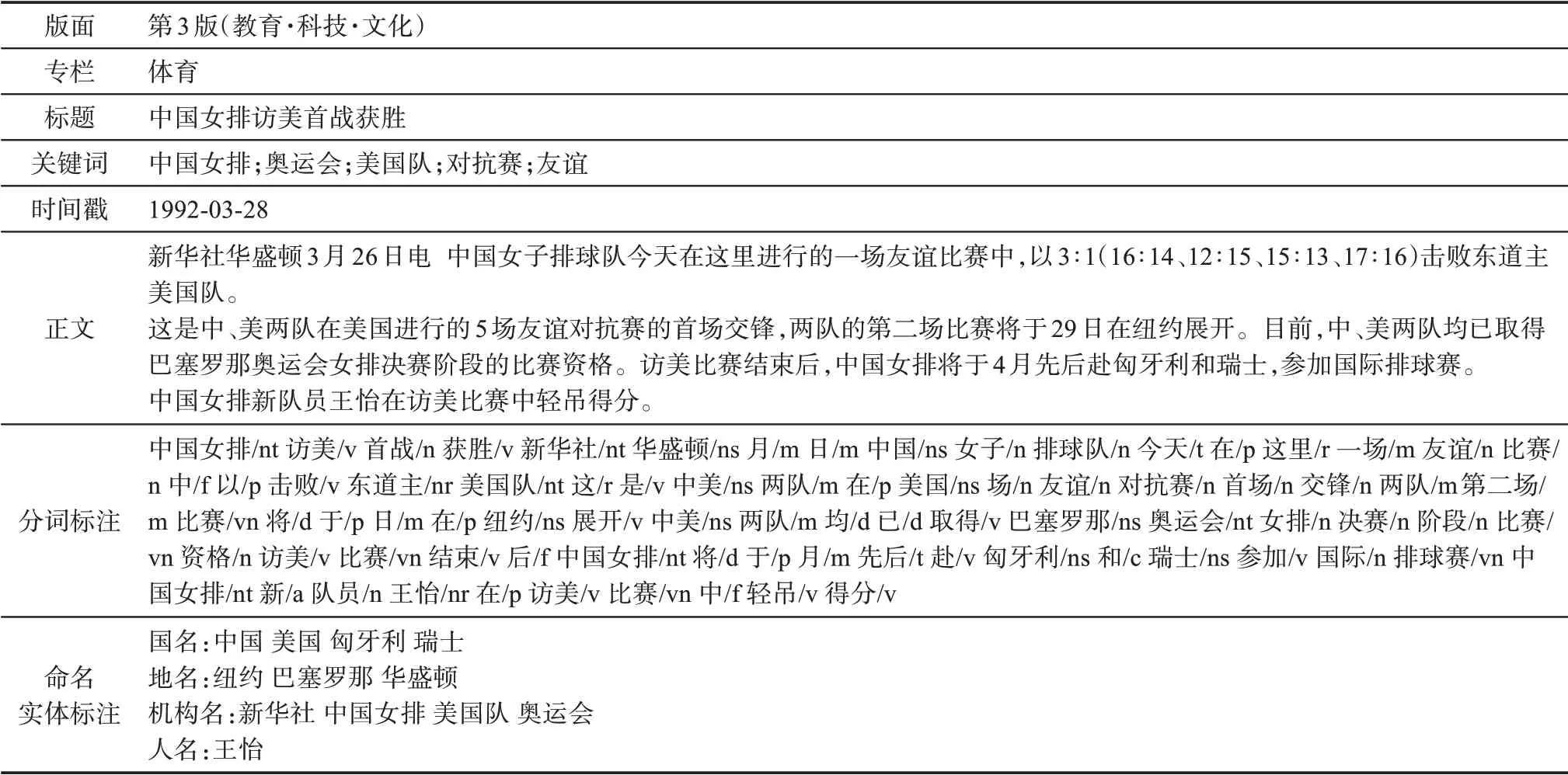
表1 经过预处理的一则语料
4.2 语义计算关键服务与数据配置映射
4.2.1 历时词向量训练服务
历时词向量的学习过程可以形式化表示为:令D={d1,d2,…,dn}表示历时文本数据集,每一则文本di∈D具有时间戳tdi∈T,文本数据集D中的词汇集合记为W={w1,w2,…,wk},学习目标是从D中为W中的词汇学习时序敏感的词向量。
本研究采用三种历时词向量的代表性方法,并提供服务调用:①使用word2vec 中基于负采样的Skip-Gram 模型(SGNS) 模型[36],对每个时间周期的语料进行词向量训练;②使用显式的正向点互信息(positive pointwise mutual information,PPMI) 表示[40],即为词汇wi∈V构建一个高维稀疏的词-上下文共现矩阵,上下文定义为目标词左右窗口内的词,使用PPMI 值作为矩阵元素;③使用增量训练方式的Skip-Gram 模型,即将语料数据按时期分割后,用时期t语料上训练得到的词向量来初始化时期t+ 1 的词向量,依次训练直至收敛[13]。三种训练方法采用python 编写并提供调用,python 服务器维护一个轮询进程与Web 客户端进行socket 通信,接到请求后开启处理线程服务计算,并返回结果,服务调用界面如图2 所示。Hamilton 等[16]研究表明,不同训练方式得到的历时词向量,在不同任务上的性能存在差异。因此,研究者可针对专题研究特点,选用不同的时间粒度和词向量训练方式,并将训练后的历时词向量数据集存储到关系型数据库中以作进一步分析。
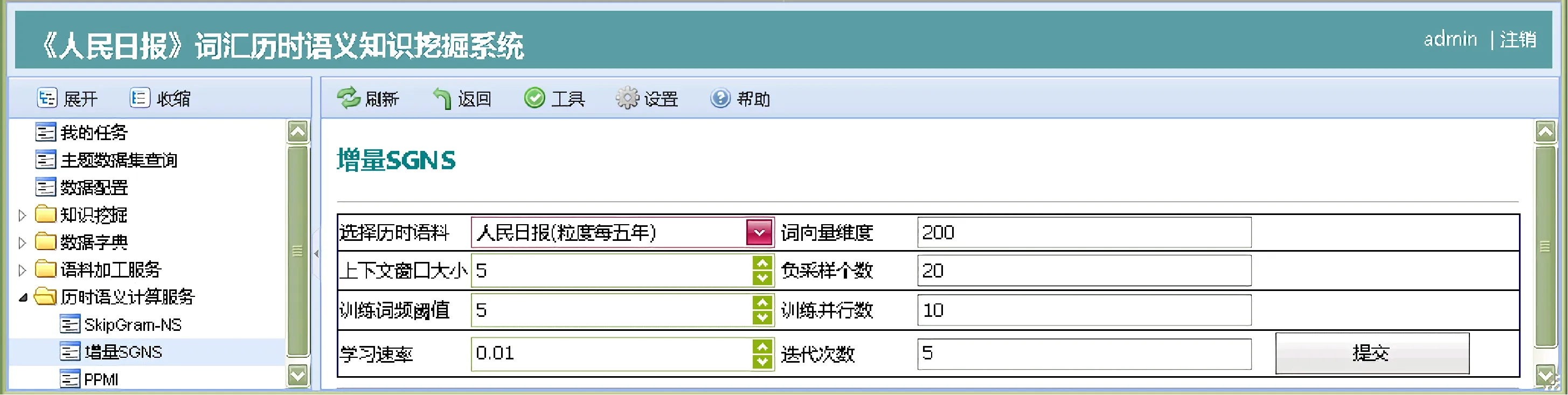
图2 历时词向量训练的服务调用
4.2.2 语义相关度计算服务
基于预测的方法训练得到的词向量,通常不能直接计算其历时语义相关度,这是由于词向量算法具有随机性,即使是在同一语料上的同一个算法,也会得到不同的向量表示。这意味着一个词的历时语义即使非常稳定,其向量距离仍可能相隔很远。为此,对采用传统SGNS 训练得到的词向量,在计算不同时段词汇的语义相关度时,可通过计算相关词的交集来判定两个词的语义相关度。若某个词在两个不同时期的近邻词的交集越小,则可认为词义的变化程度越大,定义时期tm的词汇wi和时期tn的词汇wj的语义相关度为
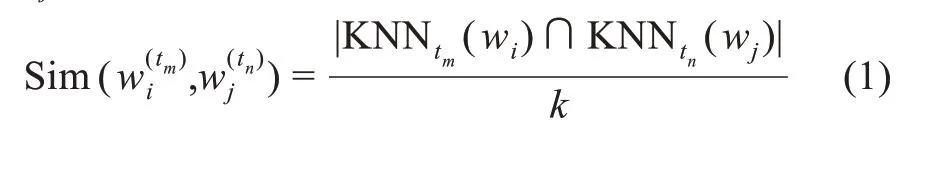
由于KNN (k-nearest neighbors) 算法时间开销较大,本研究采用近似近邻的随机投影方法[41]将每个节点中的数据投影到一维子空间,然后在子空间中进行近邻词的划分。
对另外两种历时词向量训练方式,即正向点互信息(PPMI) 和增量训练Skip-Gram 模型,所得到的词向量是自然对齐的。其中,PPMI 的词向量每一列都显式地对应于特定上下文,而增量训练方式每一次迭代,均保持了上一阶段词向量的信息,使得每个时期训练所得的词向量处于可比较的语义空间内,因此,两者均可直接使用余弦距离或欧几里得距离来计算不同时期词汇的语义相关度。
4.2.3 维度配置与数据映射
“维” 是观察数据的视角,本研究提供的维度挖掘主要有两方面。一方面,研究者根据研究兴趣和关注内容,在训练历时词向量之前,依据年代、专栏、版面、关键字等标注特征,从深加工语料库中筛选出相关语料,进行历时词向量训练,建立各种面向主题的数据集。例如,要考察《人民日报》 政治话语体系的变迁和建构,可根据版面和专栏特征,从语料库中抽取《人民日报》 社论、评论员文章等语料,分时期训练历时词向量以构建专题词汇数据集。另一方面,对于特定主题数据集,可以通过XML 文件来配置多维数据集,并自动生成可视化界面,以方便研究者从多个维度深入观察数据,进行知识发现与挖掘。 例如,对 “人民日报社论专题数据集” 的一个多维配置描述如图3 所示。

图3 XML数据集多维配置
该配置定义了 “词性”“命名实体类型”“起止日期” 等维度作为知识挖掘所需数据的过滤条件,并提供词汇、词向量、命名实体类型、词频、对应语料、所在句子等普通列供选择,通过配置文件与界面逻辑的映射,可以灵活高效地完成主题数据集的构建,并通过向导式界面获得所需数据(图4),使领域学者从技术细节中解脱出来,将精力投入于问题本身。
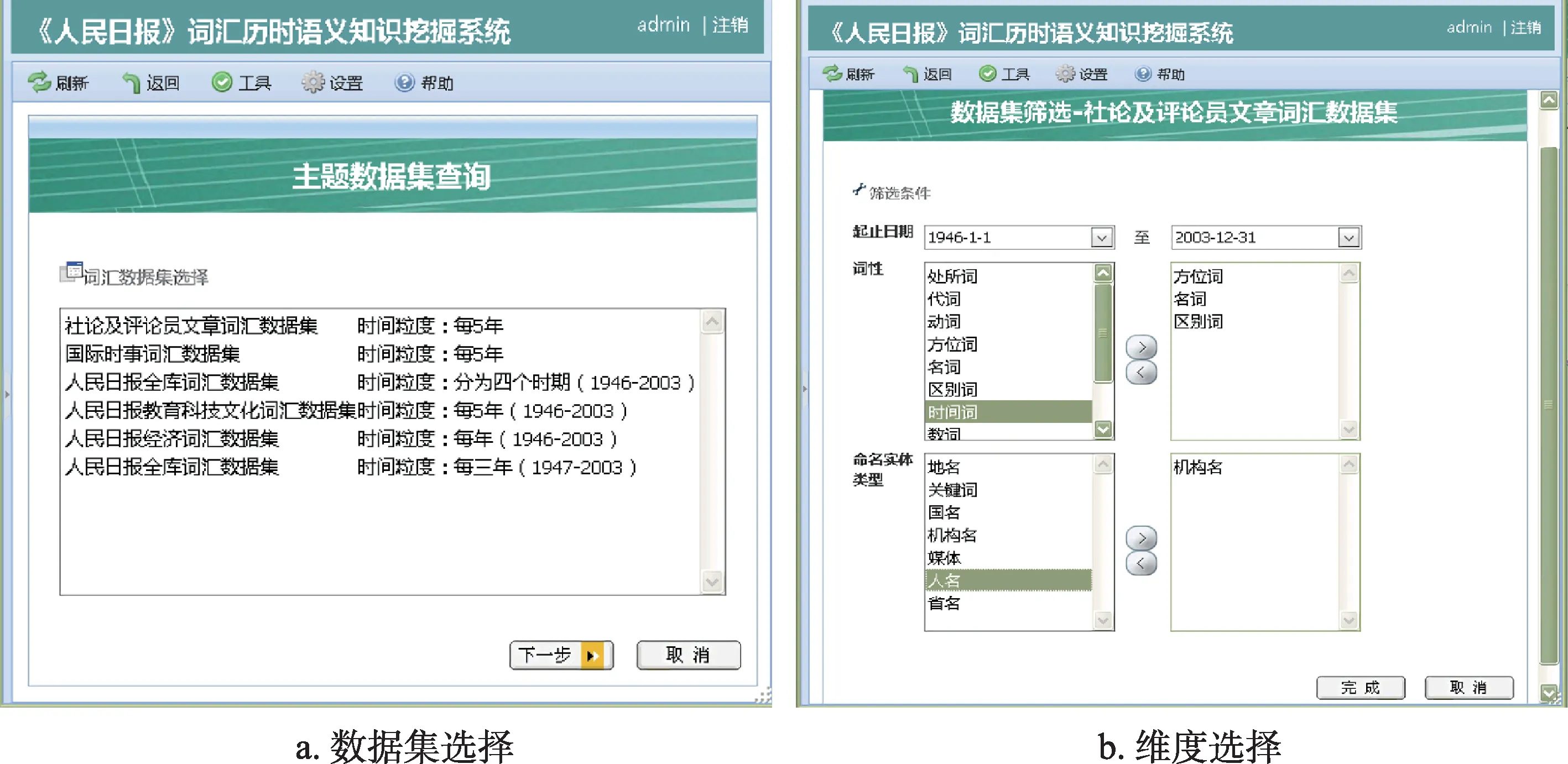
图4 XML配置映射成的数据集维度过滤界面
4.3 知识发现与可视化分析
通过对关键语义服务的调用,可以定制针对各项研究专题的知识发现和可视化模块,并展开定量分析。本节通过三个实际主题的知识发现实例,介绍可视化分析及应用的构建方法。
4.3.1 词汇历时近邻关键词可视化
词汇历时近邻词可视化的目的在于直观、快速地观察词汇的语义变迁情况,其依据是词汇语义的分布式假设[42],即认为词汇的语义由其上下文确定,相似的概念在空间中的距离也相近,通过词汇的近邻词可以表达其语义。通过统计词汇在某一语料中的词频及总语料中的词频(即TF-IDF 值),能筛选得到关键词汇。因此,通过对词汇近邻关键词的可视化展现,可以直观地观察词汇的语义演化趋势,进而对一些社会现象进行分析。
《人民日报》 的词汇与中国社会政治生活密切相关,各个版面均记录了中国每个时期在社会、政治、经济、科技、文化等领域的变化和进步,具有强烈的时代色彩。本研究参照中国现代史重大事件[43],将1946 年5月15日至2003年12月21日的《人民日报》 全库语料,分为四个时期:时期一为1946—1965 年,时期二为1966—1976 年,时期三为1977—1992 年,时期四为1993—2003 年,并采用传统Skip-Gram 的训练方式,训练得到每个时期的词汇语义向量。图5 以词汇 “经济”“农业” 为例,展示了词汇近邻关键词随时间变迁而变化的可视化过程。

图5 词汇历时近邻关键词
由图5 可以看出:①1946—1965 年,这一时期是社会主义建设的过渡和探索时期,“经济” 的近邻关键词包括 “国民经济”“合营”“购销”“公营企业”“棉纱”“计划调节” 等反映经济领域的三大改造和高度集中的计划经济体制的词汇;“农业” 的近邻关键词则有 “互助组”“初级社”“自给性”“飞跃发展”“全力” 等,反映了这一时期集体农业建设的面貌以及对增收增产的迫切需求。②1966—1976 年,“经济” 的近邻关键词包括 “经济主义”“唯生产力论”“多快好省”“三自一包” 等,在这一时期,经济与政治紧密关联,与经济建设直接相关的词汇比较少见;“农业” 的近邻词包括 “春播”“大寨”“国防”“备荒” 等,反映了这一时期农业建设停滞的状况以及农业学大寨运动的时代特征。③1977—1992 年,这一时期是改革开放建设时期,“经济” 的近邻关键词有 “资金”“市场经济”“生产力”“生产关系”“按劳分配”“市场调节”“经济效益” 等一系列具有改革开放典型时代特征的词汇,反映了改革开放后我国经济蓬勃兴旺的发展态势。“农业” 的近邻关键词则包括 “开荒”“高产”“双季稻”“商品粮”“科学种田”“科技兴农”“农副产品” 等词汇,反映了这一时期开荒造田以及科技发展农业的趋势。④1993—2003 年,这一时期是改革开放的深化期,“经济” 的近邻关键词包括 “交易所”“股票”“利用外资”“扩大开放” 等,表明随着市场经济地位的确立,我国经济建设进入一个新的历史阶段。“农业” 的近邻关键词包括 “农业投入”“支农”“信息化”“精准”“观光农业”“绿色食品”“无公害” 等词汇,表明了农业管理随着现代农业的发展变得更为精细化,“三农” 问题提上日程,绿色环保成为热点主题。
4.3.2 词汇语义变迁考察
根据词汇的历时词向量,可以计算出不同时期单个词向量与初始词向量的相关度,若相关度变化不显著,则表明该词汇的语义相对稳定。本研究以每三年为时间分片,从深加工《人民日报》 语料库中,构建语料训练集,并选择增量Skip-Gram 模型进行训练,得到词汇在每一阶段的向量。部分词汇特别是一些后期出现的新词,在早期的文本中没有或很少出现。例如,“软件” 一词在《人民日报》中最早出现的时间是1976 年2 月,在74-76 时间分片(即1974—1976 年) 中仅出现了2 次,如果按正向时间周期训练会带来语义失真的问题。为此本研究采用文献[44]的方法,训练时采用从后向前训练的方式,即从2001—2003 年开始训练,并反向初始化,最后,计算每个阶段词汇与起始阶段词汇的语义距离,以观察词汇的语义变化程度。在图6 中,以 “井喷”“缩水”“防火墙”“孵化” 等12 个具有代表性的词汇为例,展示了选定词汇的词义变化趋势图。
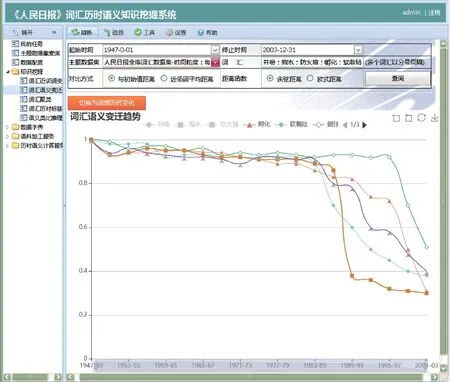
图6 词汇语义变化历时曲线图
从总体上看,词汇在语义空间中的位置会随着时间的推移而发生偏移,若偏移程度较大,则表明在这个时期词汇的语义发生了变化。例如,“下海”“眼球” 的语义变化曲线分别在1989-91 时期(即1989—1991 年),以及1995-97 时期(即1995—1997年) 有显著下降,则表明这段时间语义发生了较为剧烈的变化。通过查询词汇转义期前后的近邻关键词,可以观察具体的词义变化情况(表2)。
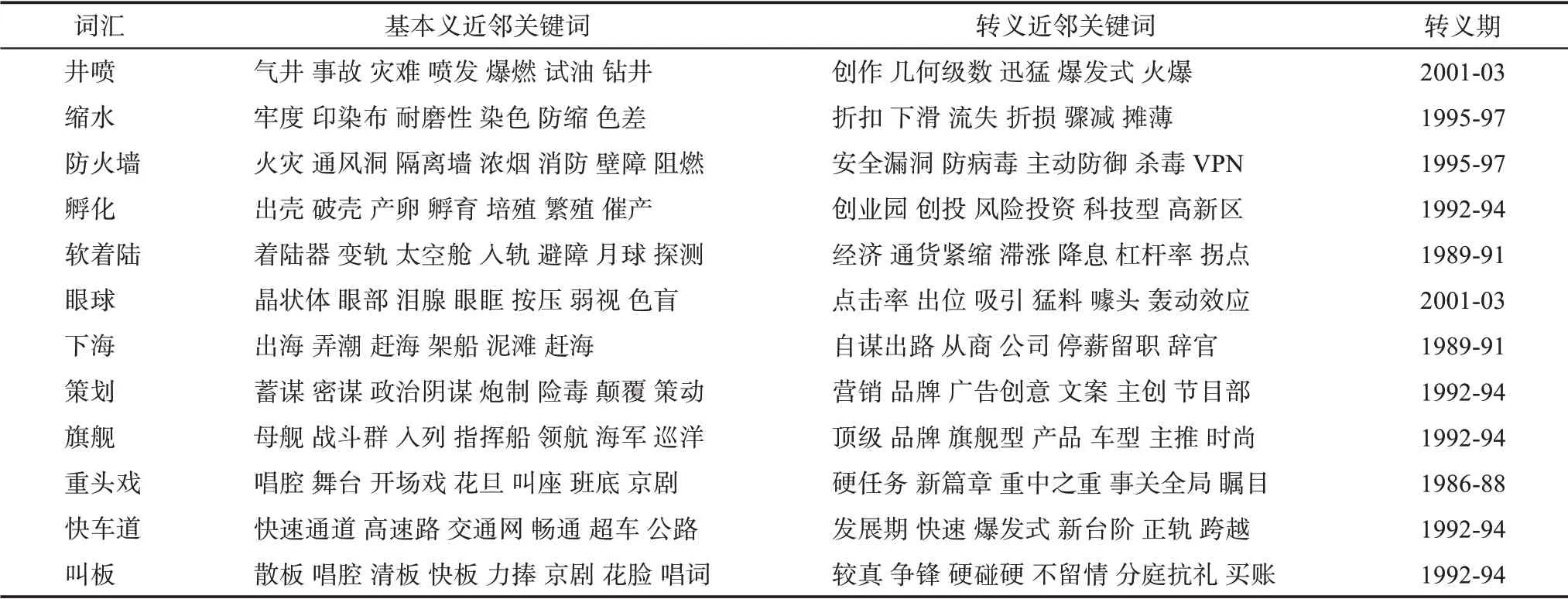
表2 部分词汇的近邻关键词词变迁
结合图6 和表2 可以发现,第一,随着社会的发展和时间的推移,有些词汇从各个学科和行业中表示具体概念的本义,逐渐泛化为表示抽象概念的隐喻义,涉及的学科既包括戏曲、军事、医药、物理等领域,也包括金融、计算机、互联网等新兴行业。通过检索词汇所在语料,可以分析词汇语义变迁的具体语境。以 “旗舰” 为例,其原意是指载有海军将官或舰队、分舰队司令官并悬挂旗帜的军舰,例如,“去年九月二日在东京湾的密苏里旗舰上举行了日本投降的签字典礼(1946-08-11) ”;在1998 年之后,“旗舰” 逐渐泛化到商业领域,比喻同类中起主导作用的产品或机构,例如,“由我国软件旗舰企业浪潮软件为北京市民政局开发的‘北京市城乡居民最低生活保障管理服务系统’一期工程开通(2003-07-18) ”。 第二,在词义变化过程中,有些词的色彩意义发生了变化。在20 世纪90年代之前,“策划” 的近邻关键词主要包括 “阴谋”“ 蓄 谋”“ 幕后 操纵” 等贬 义 色彩 的 词,例 如,“ (亚洲人民) 反对国际战争势力在任何幌子下策划新战争的罪恶阴谋(1955-02-26) ”;而随着改革开放的不断深入,其近邻关键词逐渐转为中性,出现了“ 营销”“ 品牌”“ 文案” 等中性词,例如,“该中心将与新闻界广泛联系,代理策划各类公关和广告宣传活动(1992-11-01) ”。第三,随着科技的发展,有些词汇的语义逐渐迁移到专业领域。1996 年之前,“防火墙” 还是建筑学术语,其关键近邻词包括 “火灾”“通风洞”“隔离墙” 等建筑领域词汇,例如,“该公司擅自在防火墙上凿开7 个通风洞(1994-03-01) ”; 在1996 年之后,“ 防火墙” 一词开始转移到网络领域,其近邻词包括 “安全漏洞”“主动防御” 等随着互联网飞速发展而出现的词汇,例如,“通过一种称为‘防火墙’的多种软硬件防护体系即可保护自己的计算机不受侵犯(1995-02-18) ”。由此可见,通过计算词汇的历时语义变化和观察其近邻关键词的变迁,可以有效辅助对词汇语义的具体变化及其背景进行分析并举出例证。
4.3.3 特定词汇的历时标签演变
《人民日报》 词汇系统与时代话语体系密切相关,通过对一些人名、地名、机构名、历史事件的近邻词的变迁的考察,可以窥见特定历史时期的时代特征和观念的变化过程。例如,要观察时代背景制约下《人民日报》 中 “孔子” 的形象变迁,可通过其近邻词中标签类词汇(近邻名词、动词、形容词、命名实体) 的历时变化来观察(图7)。
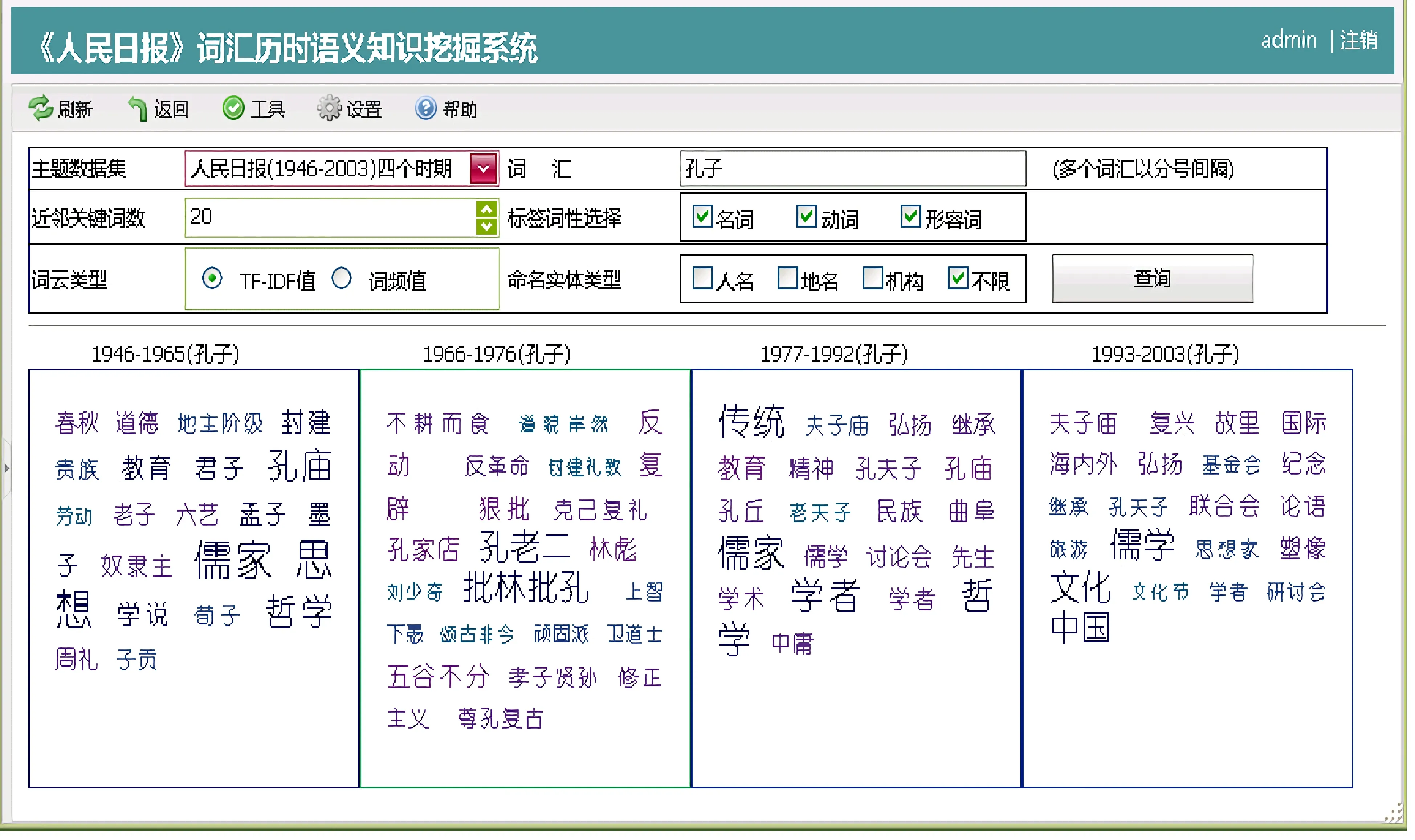
图7 “孔子”形象历时演化
作为儒家文化的创始人,孔子对中国社会产生了深远影响。以图7 中的 “孔子” 为例,①1946—1965 年,“孔子” 的近邻词主有两类,第一类是将孔子视作中国古代的学者,如 “哲学”“君子”“周礼”“六艺”“学说” 等,与其相关的人名则有 “老子”“孟子”“墨子”“荀子”“子贡” 等;第二类是视孔子为封建秩序的维护者,如 “封建”“贵族”“地主阶级”“奴隶主” 等。这一时期孔子的形象塑造主要集中在孔子的哲学思想和孔子的阶级属性上,反映了当时对孔子学术教育贡献的客观评价,以及对孔子的阶级属性的讨论。②1966—1976 年,“孔子” 的近邻词主要包括 “孔老二”“批林批孔”“孔家店”“复辟”“反动”“上智下愚” 等,表明在这一时期,孔子及其思想受到大面积的批判,孔子形象跌入低谷。③1977—1992 年,孔子的近邻词为“儒家”“传统”“教育家”“学术”“哲学” 等,这一时期对孔子的评价已经较少有政治上的定性,而主要突出其思想家、教育家的定位。④1993—2003年,孔子的近邻词出现了 “夫子庙”“国际”“海内外”“文化节” 等词汇,反映了随着国家经济和文化的发展,孔子的形象兼具了旅游文化乃至对外交流的功能。需要说明的是,图7 中孔子形象的 “标签” 词,是从历时语料中由词向量算法自动学习得到的,其本质是对语料使用的反映,因此,可以为观察不同时代的孔子形象提供一种新的视角。
5 讨论与总结
在信息技术飞速发展的背景下,历时文本数据正以前所未有的速度增长,试图从浩瀚的文字海洋中人工观察社会变迁的整体面貌,已超出了一般分析理解所能处理的范畴;而机器学习和大数据技术的兴起,则为文本处理和挖掘提供了更大的研究空间和新的研究可能。在此背景下,本研究提出了一个面向知识发现的词汇历时语义挖掘框架,该框架基于服务式体系架构,通过语料预处理、历时词向量训练、词汇语义计算等服务,可实现从文本到数据再到知识的转化。同时,本研究以《人民日报》历时语料为基础,实现了中文词汇历时语义知识挖掘平台,通过数据集定制和服务组合,构建了词汇语义知识发现的若干应用。本研究工作的特色与优势有:①具有高可扩展性,在松耦合的面向服务的架构下,开发者可根据业务逻辑灵活构建特定的知识发现应用模块;②具有高可配置性,通过定义或修改配置文件,可与数据集建立映射,实现即插即用功能;③具有高可用性,人文学者可根据学术兴趣,定制或选择现有的面向主题的历时词汇数据集,从多个维度观察数据,从而发现线索或得出结论。
本文的意义在于展现了数据驱动的知识生产范式的潜力,不同于传统研究主要依赖于对文献的辨析、思考和领悟得出相关结论,本文所取得的若干结果是通过大量数据的汇集而自动涌现的,具有精确、可复现等自然科学研究的特点。然而,本研究还需要进一步完善和深入。第一,本文采用了三种主流的历时词向量训练方法,但没有讨论不同训练方法得到的词向量特征的差异。第二,本文的实证部分使用了《人民日报》 历时语料,而没有使用微博等新兴社交媒体语料,主要是因为时间跨度较长的大规模语料的获取较为困难,处理较为烦琐,而《人民日报》 语料用词规范,与社会生活联系紧密,适合作为词汇历时语义挖掘的基础语料。未来我们将进一步采集《人民日报》 的语料数据,以及《人民文学》《新闻联播》 报道等记录中国社会生活变迁的历时语料,对词汇系统进行更深入的知识挖掘。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
厦门大学学报(自然科学版)(2021年4期)2021-06-22
汉字汉语研究(2021年1期)2021-06-11
汉字汉语研究(2021年1期)2021-06-11
红楼梦学刊(2019年5期)2019-04-13
计算机应用与软件(2018年9期)2018-09-26
长江学术(2016年4期)2016-03-11
海外星云(2015年15期)2015-12-01
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
