
企业潜在技术合作伙伴及竞争者预测研究
——以燃料电池技术为例
2021-10-26 05:41孙晓玲
情报学报 2021年10期
李 冰,丁 堃,孙晓玲
(大连理工大学科学学与科技管理研究所,大连 116024)
1 引 言
企业关注的转移转化工作主要包括技术引进、技术输出以及技术合作。为了使得企业进行更优质的转移转化,在各项工作的展开中需要进行对自身专利的盘点,包括与对标企业技术比较分析自身的优劣势、调整企业专利组合等。同时,更加需要对行业内专利技术评估以及技术持有者的评价,以便在专利技术转移转化中寻求到最佳的合作伙伴,在专利布局中防范可能的竞争对手。然而,外部专利数量的迅速增长,意味着大量新技术的不断产生与更替,对于企业进行后项工作而言,会造成时间成本和资金成本的大量消耗。如何在大的行业范围内帮助企业缩小寻找范围,快速定位潜在关系对象是本文想要解决的主要问题。
对于这项工作的开展,若采取行业范围内专利及专利持有者的逐一筛选和评估无疑不是最明智的选择,本文的研究思想是将企业在这一环节的工作聚焦在围绕自身的发展状况,牢牢把握现有的专利情报信息。这要求企业在对自身专利的盘点过程中,不仅需要关注已有的专利,对于已有专利的引用专利更加需要关注,这部分专利蕴含的信息是企业技术发展的知识基础,也是挖掘企业关注技术的信息依托。已有研究表明,技术相似性是企业挖掘技术竞争对手与合作伙伴的重要依据,可以给企业在全球范围内寻求技术竞合对象提供有效的决策信息支持[1]。对于专利引用信息的有效利用,可以挖掘企业关注的技术内容,而关注相似技术的企业则可能成为合作伙伴或是竞争对手,在实际中需结合具体情况而定,但可以达到缩小查找范围、精准定位的研究目的。
目前,采用专利信息挖掘企业合作伙伴的研究主题可以概括为两部分内容。其一是产学研合作研究。例如,王菲菲等[2]基于论文合作和专利合作网络对产学研潜在合作机会进行预测;许海云等[3]和王超等[4]基于基础研究、应用研究、转移转化、商品化和产业化五个环节组成的创新链对潜在产学研合作对象进行识别;周超强[5]通过构建科技领域词典,结合技术需求以及基于潜在语义的文本相似度计算,实现了专家推荐系统,并对产学研合作进行专家推荐;付鑫金等[6]利用科技查新识别产学研潜在合作对象;冉从敬等[7]从企业视角出发,构建了校企合作选择模型,为校企合作提供了便捷路径;Kang 等[8]将LDA (latent Dirichlet allocation) 主题模型和聚类算法相结合,对特定技术领域的子技术类别进行分类,并在每个类别中为企业确定最佳大学合作伙伴。其二是方法性研究,即对于寻找企业潜在合作伙伴的方法研究。例如,温芳芳[9]通过构建专利分类号的耦合网络分析企业间的潜在合作关系;杨梓[10]在其学位论文中利用专利数据,采用文本挖掘等方法,对技术关联的企业间潜在创新合作的可能性进行了探讨;傅俊英等[11]通过测度专利之间的相似性,来度量专利权人之间的技术相似性,进而对中小企业的潜在合作伙伴进行识别;温亮等[12]通过构建基于SAO (subject-action-object) 语义分析的技术合作伙伴识别体系,对网络内企业重点子技术领域进行相似度分析,从而识别企业潜在的技术合作伙伴;Angue 等[13]提出了一种基于专利组合的对偶分析方法,帮助企业识别潜在合作伙伴。
不同于上述研究,本文指明异质性网络建模的理论基础,利用企业引用专利的直接互动给关系,构建企业-专利的异质性网络。在研究方法上,新兴的机器学习和深度学习的方法在分类和预测问题上均达到了理想的效果,然而,已有的研究对于这类方法的利用依然不尽完善,对于算法的选择和研究的理论并没有做到十分的匹配。本文在二部图理论的基础上,选取基于SimRank 链路预测算法为实验方法,对企业潜在的技术合作伙伴和竞争对手进行预测挖掘,并基于text2vec 的表示学习对专利文本进行向量化表示,对潜在竞合对象和目标企业的专利文本进行相似度计算,衡量两个企业的技术差异度,进而判断竞合关系。本文进一步完善了以专利信息为依据对企业合作伙伴挖掘的主题研究,丰富了该主题的研究框架,更为实际企业发展中寻找潜在关系对象提供新的思路,缩小查找范围,节约企业发展成本。
2 研究设计
2.1 异质网络构建的理论模型
二部图是图论中一种特殊的模型。其定义为:若G= (V,E) 的顶点集V的一个划分是V=V1∪V2,V1∩V2= ∅,使得G中的任何一条边的两个端点分别在V1和V2中,如图1a 所示。在二部图的基础上延伸出完全二部图和有向二部图等概念。实践中,已有关于二部图利用的相关研究,如利用二部图可以求出网页的最大匹配与完全匹配,挖掘出隐含的知识社群,以及最常用的将V1作为用户集,V2作为商品集,进行产品的推荐[14-16]。

图1 企业-专利二部图设计
本文借鉴二部图的理论思想,将企业看作用户,专利看作商品,企业对于专利的引用可以看作用户对商品的选择,以此构建企业-专利的异质性网络,可以充分体现企业与专利的直接互动关系。在这里,企业之间的合作以及专利之间的引用关系暂时不考虑,由此得到的数据集的链接关系符合二部图理论。
2.2 研究方法
2.2.1 链路预测
在二部图理论的基础上,本文选用的研究方法是基于SimRank 指标的链路预测算法。近年来,链路预测方法由于其广泛的应用性已经得到了普遍的认可,并且在学术研究中已经与专利信息挖掘进行了较好的结合[17-19],其内涵的算法有很多,其中比较经典的如优先连接(preferential attachment,PA)、共同邻居(common neighbor,CN)、 Salton 指标(也叫余弦相似性)、Jaccard 指标、Sorenson 指标、大度节点有利指标(hub promoted index)、大度节点不 利指 标(hub depressed index) 和LHN-I 指标等,对于链路预测算法有不同计算方式的不同分类[20]。已有研究表明[21],SimRank 算法在预测效果方面显得较为稳定,受到网络结构扰动的影响相对较小,这是本文选择SimRank 的原因之一;另外,该算法的计算思想与二部图模型更加契合,体现了研究理论与研究方法相结合的研究设计,故本文选取SimRank 算法。
SimRank 算法的思想是,若同一类型的两个对象与第二类型的相似对象相关,则两者是相似的。这种思想与本研究的目的相契合,映射到本研究中就是:如果图1 中的专利1 和专利5 相似,那么企业1 和企业2 就具有更多链接的可能性,引用相似专利的企业更可能成为潜在的合作者或竞争者。对于算法的计算,本文采用Antonellis 等[22]计算公式

其中,s(a,b) 是节点a和b的相似度,当a=b时,s(a,b) = 1;Ii(a) 表示节点a的第i个in-neighbor 或out-neighbor;当I(a) = ∅或I(b) = ∅时,s(a,b)=0;参数C为阻尼系数,本研究中设为0.8。对于Sim‐Rank 算法有效性的验证,本文采用预测值与实际链接情况进行比较。
2.2.2 表示学习
通过链路预测可以挖掘出潜在竞合对象,而对于竞争对手的确认,本文从技术威胁角度考虑,技术威胁衡量的是技术差距、技术差异等实际因素,可能给企业自身利益与安危带来的影响。本文以专利数量衡量技术差距,以专利文本内容相似性衡量技术差异进行潜在竞争对手的确认。
在技术差异度量中,将专利技术进行文本向量化表示,深度学习中的表示学习可以将研究对象,如词汇、短语、句子等的语义信息,表示为稠密低维的实值向量,目前已有较为成熟的运用[23-24],由于篇幅限制本文不再详细介绍。从技术特征和功效特征两个角度,本文对专利文本的技术标签进行抽取,然后采用text2vec 将抽取的技术功效句进行语义向量表示。 text2vec 包是由Dmitriy Selivanov 于2016 年10 月所写的R 包①http://text2vec.org/index.html,此包主要是为文本分析和自然语言处理提供了一个简单高效的API (appli‐cation programming interface) 框架,可以进行词向量化操作、word2vec 的升级版GloVe 词嵌入表达、主题模型分析以及相似性度量四大方面。在专利向量表示之后,通过计算向量之间的相似度来度量两个企业间的技术差异性,余弦相似度的计算公式为
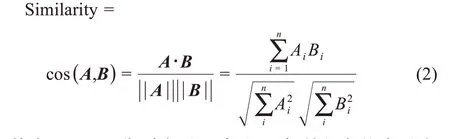
其中,A、B分别表示两家企业专利文本的表示向量;Ai表示向量A的第i维度值,Bi表示向量B的第i维度值,这里A、B均为128 维度的向量;n为128。由此计算可得cos(A,B)在(-1,1)区间,该值越接近1,表示两个向量相似度越大,专利表示向量之间的相似度越大,技术差异越小。
综上所述,将本文的研究设计梳理成图,如图2 和图3 所示。首先,在数据获取和预处理之后,基于专利引用信息,构建企业-专利有向二部图,网络边的权重以引用频次进行计量。其次,对算法在本研究中的有效性进行检验,将企业与企业之间的实际合作次数作为实体链接的实际值,与链路预测的预测值进行比较,进而检验算法是否合格,若合格则进行下一步的实际预测应用。在实际预测中,本文制定随机抽取数据集构成的网络图中10%的节点作为测试集,剩余90% 的节点作为训练集。最后,在随机生成的节点中选取目标企业,通过目标企业的预测链接对象类型将预测关系进行划分,高校和科研院所视为目标企业潜在转移转化对象,企业视为潜在竞合对象。在竞合关系的判别上,本研究以技术差距作为参考,以技术差异为主要标准,即在同技术领域内,技术越相似的企业越可能成为竞争对手。
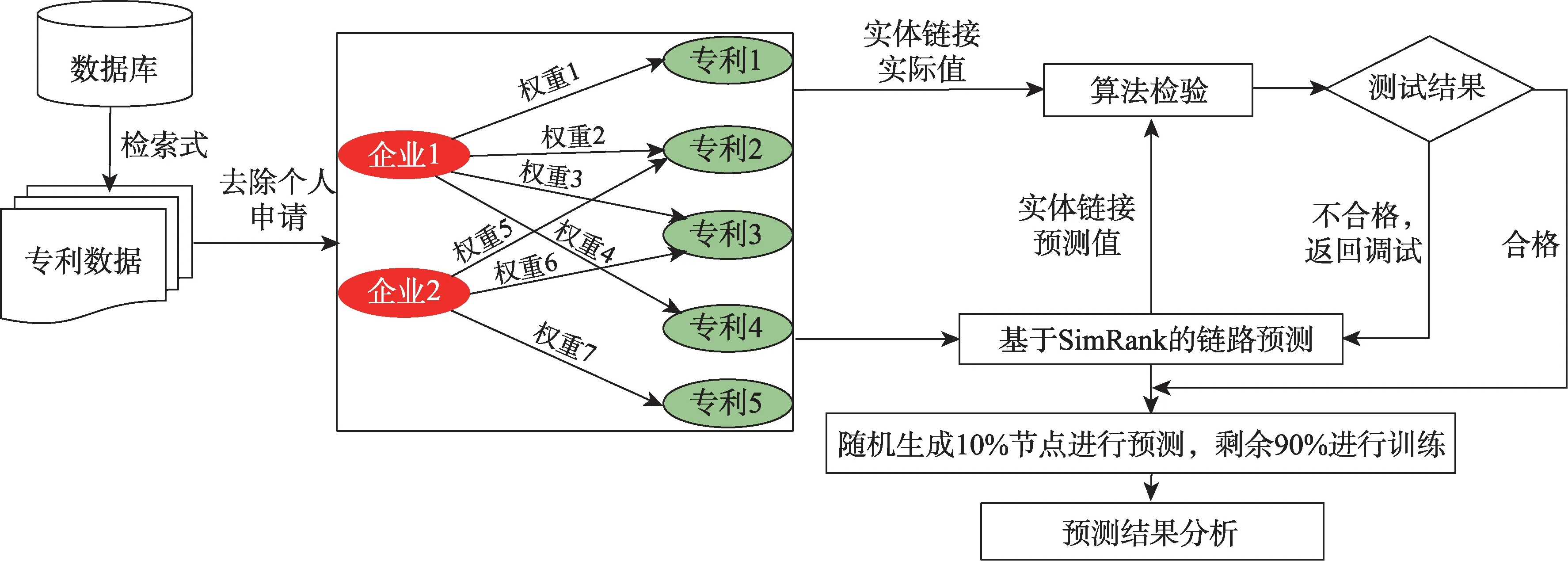
图2 企业合作/竞争关系预测流程图
3 实证分析
3.1 数据获取与处理
燃料电池是一种等温进行、直接将储存在燃料和氧化剂中的化学能高效、无污染地转化为电能的发电装置。从节约能源和保护生态环境的角度来看,燃料电池是极具应用价值的发电技术,因此成为新兴技术之一,目前被广泛应用在各个领域,包括航空航天、潜艇、电动汽车等。
本文将实证研究限定在燃料电池领域,地区限定为中国,选用IncoPat 专利数据库作为本文的数据来源,该数据库收录了120 个国家/地区/组织超过一亿件的专利著录数据和部分PDF 格式的说明书全文,其数据来源于官方和商业数据提供商,并且更新速度快。本文对2018 年至今的发明和授权专利数据进行获取,中文检索以 “燃料电池” 为主题词,英文检索以“fuel cell OR fuel batter*” 为主题词。数据下载时间为2020 年8 月,共6083 条,合并同族后获得5784 个专利族作为本文的源数据,由于本文主要研究主体为企业,故过滤掉申请人类型为 “个人” 的专利数据,剩余5561 个族。
获取数据之后对数据进行处理,去除没有引用数据的专利,提取每项专利的专利权人信息和引用的专利信息。将专利P1 对专利P2、P3 的引用视为P1 的专利权人对P2、P3 的引用,专利权人对每项专利引用的频次视为专利权人和专利链接的权重,由此可以获得企业与专利的链接关系,去除重复的引用对,最后,生成由5200 个节点组成的5423 对节点链接关系。同时,将专利权人中的合作关系提取出来,合作次数作为权利人之间的链接权重,记为对比数据,以便后续模型有效性的检验使用。
3.2 实证结果
3.2.1 模型测试
在实证之前,本文对模型进行有效性检验,检验方式采用预测链接权重与实际链接权重进行对比。首先,对全部数据进行预测,将预测结果与第3.1 节中数据处理的对比数据进行权利人合作关系匹配,得到不同权利人合作以及对应的两组数据值,分别是预测链接值和实际链接值,选取其中排名前200 对合作关系进行相关性检验,检验结果如图4 和表1 所示,图4 是预测链接值和实际链接值的散点图,表1 是回归分析结果。
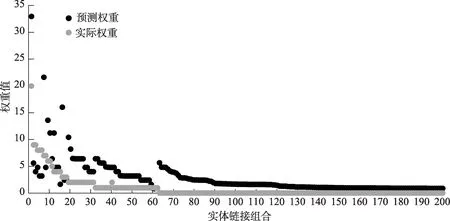
图4 预测值与实际值散点图
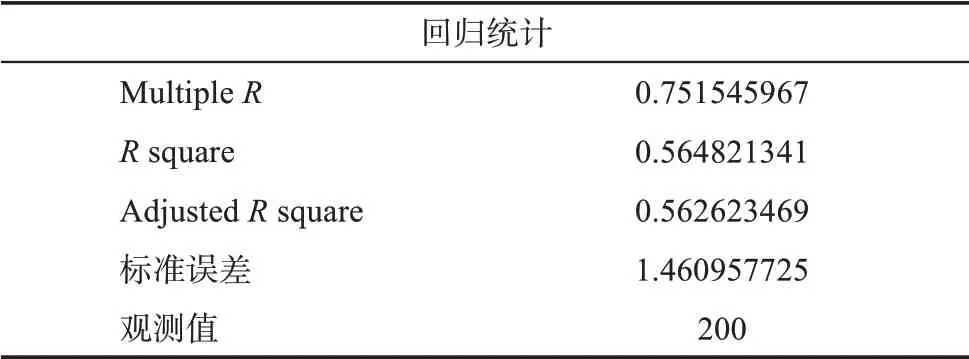
表1 回归分析结果
从回归分析结果来看,MultipleR为0.75,表明预测值和实际值之间具有一定的相关性,该模型是可行的。
3.2.2 结果分析
1) 目标企业确定
对于随机生成的10% 的预测主体,本文将预测链接值排名前20 位的链接组合显示如表2 所示。其中,预测对象1 和预测对象2 均来自随机生成的主体之中,并且在实际中还未有链接关系,预测链接权重是各个主体对在未来链接的可能性。
由表2 可知,预测结果中,排名第1 位的是安徽江淮汽车集团股份有限公司和大连理工大学,预测链接为1.117。为了更加清晰地显示预测对象的活跃度,将预测值排名前1000 位的节点对中各个节点出现的频次进行统计并可视化(图5)。其中,连线代表存在潜在的合作或竞争关系,节点的大小代表出现频次。由图5 可以明显看到,安徽江淮汽车集团股份有限公司在所有主体中相对比较活跃,通过检查本研究的原数据发现,其与燃料电池技术相关的专利申请均为独立发明,下文将其作为目标企业进行分析。
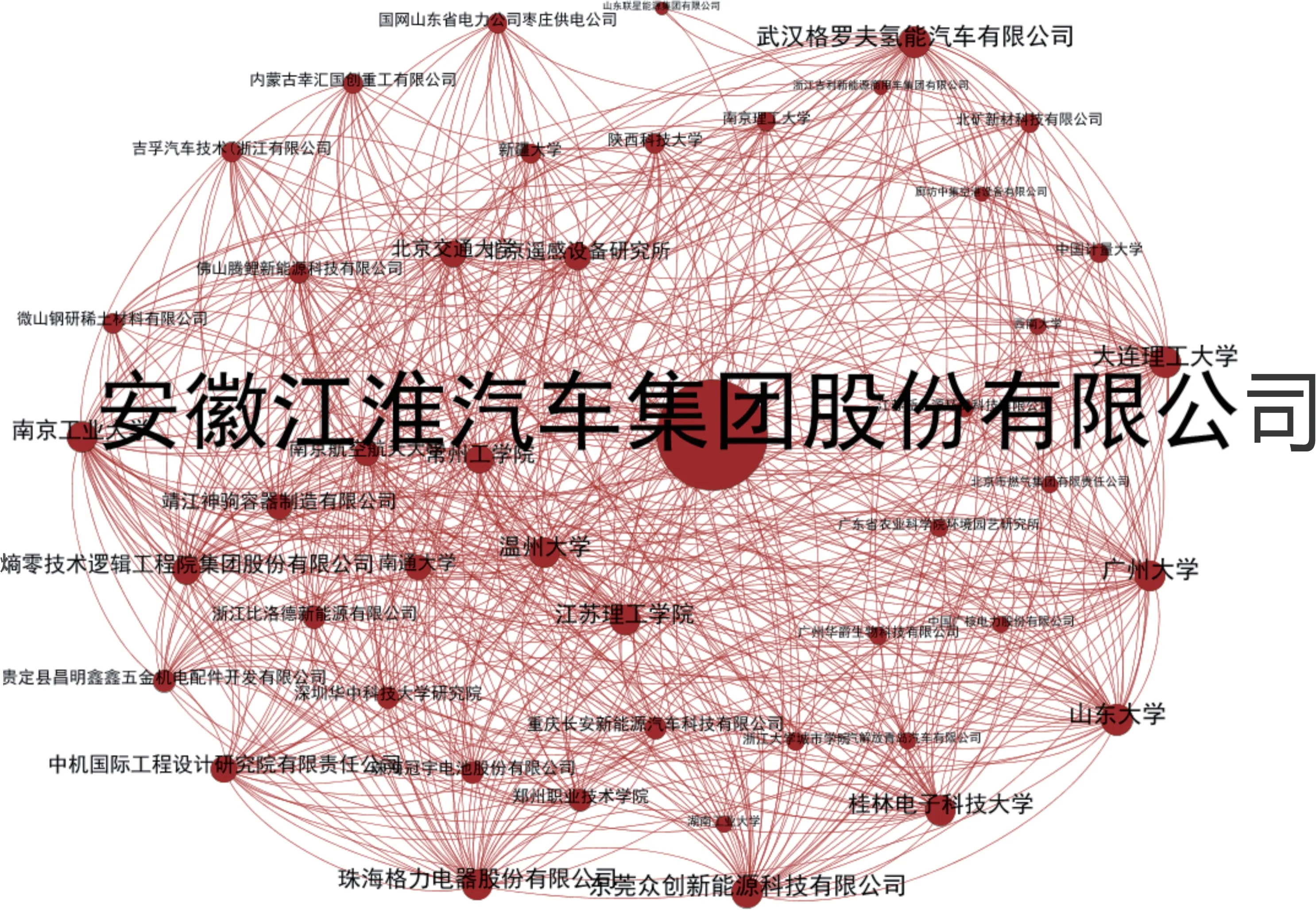
图5 随机节点出现频次

表2 随机节点中预测分数排名Top20
安徽江淮汽车集团股份有限公司是一家集全系列商用车、乘用车及动力总成等集研、产、销和服务于一体的先进节能汽车与新能源汽车并举的综合型汽车企业集团。该企业拥有上万件专利,其中,燃料电池相关专利共107 条,专利申请信息如图6所示。

图6 安徽江淮汽车集团股份有限公司燃料电池专利申请情况
安徽江淮汽车集团股份有限公司对于燃料电池的关注从2008 年开始;2009—2011 年的专利申请量为0,表明此时期企业对于燃料电池技术的利用还处于摸索阶段;2015—2018 年是企业对燃料电池专利申请量极具上升的阶段时期,意味着已经将燃料电池技术与企业的产品进行有效结合,如燃料电池汽车及其配套设施等。
2) 潜在关系预测与竞合关系判别
本研究将以安徽江淮汽车集团股份有限公司作为研究的目标对象,对其潜在转移转化对象和竞争者进行预测,即将其与实验数据的全部主体进行链接预测,得到预测值排名前10 位的结果,如表3 所示。
从表3 可以看出,安徽江淮汽车集团股份有限公司的潜在转移转化对象包含四所高校,分别是清华大学、西安交通大学、大连理工大学以及湘潭大学,从预测链接权重可以看出,其与清华大学的合作最为可能。通过中英文主题词检索加专利权人限定,检索出清华大学拥有的燃料电池相关专利共813 件;之后可能合作的是西安交通大学,拥有燃料电池专利261 件;最后可能合作的是大连理工大学和湘潭大学,分别拥有专利399 件和34 件。在预测排名前10 位的主体中含有6 家企业,分别是潍柴动力股份有限公司、中通客车控股股份有限公司、上海楞次新能源汽车科技有限公司、小飞象汽车技术(苏州) 有限公司、珠海格力电器股份有限公司以及湖北雷迪特冷却系统股份有限公司。对于链接关系,在实际中可能是合作也可能是竞争关系,需要结合企业的实际技术产品和发展战略而定,本研究只进行初步的关系确认。

表3 与安徽江淮汽车集团股份有限公司有潜在链接关系对象Top10
由于篇幅限制,在竞合关系对象中,本文以中通客车控股股份有限公司为例进行竞合关系确认,对于其他企业的分析同理。在技术差距上,统计目标企业和中通客运的发明和授权专利数量,两家企业分别为73 条和26 条,可以看出,在技术差距上,目标企业处于优势地位。本研究抽取每项专利的功效句作为专利的技术内容表征,将专利内容进行语义向量表示,通过计算向量之间的相似度来度量技术差异性,得到73×26 的专利矩阵。相似性分值排序前10 名和后10 名如表4 所示。

表4 安徽江淮和中通客运的燃料电池技术相似性
从相似性的分值可以将中通客运基本确定为竞争对手,将其主要技术与目标企业进行对比,主要技术以IPC 分类号进行表示,如图7 所示。其中,B60L 代表电动车辆动力装置,B60K 代表车辆动力装置或传动装置的布置或安装,B60J 代表车辆的窗、挡风玻璃、非固定车顶、门或类似装置。研究发现,除了在B60L 和B60K 两项技术上两家企业的专利数量持平,以及在B60J 技术上中通客运略领先之外,其余安徽江淮的专利数量均在中通客运之上。虽然目标企业在整体技术差距上位于优势地位,但若进行布局或预警的防范考虑,上述三个技术均存在技术差距专利风险,需要企业及时调整专利布局。

图7 安徽江淮和中通客车的主要技术分布
对于其他企业,譬如,上海楞次新能源汽车科技有限公司,其主营业务范围包括新能源汽车技术、船舶动力系统技术、燃料电池技术领域内的技术开发,与本研究的目标企业安徽江淮汽车集团股份有限公司有重合的产品,即新能源汽车,所以在该项业务中更有可能成为目标企业的潜在竞争对手;而其另一项主营业务,燃料电池技术的开发以及汽车零部件的生产经营也有可能为两家企业带来合作,所以企业之间既有竞争关系又有合作关系,不能简单凭预测权重数值判断,需要结合实际的生产发展来分析。本研究的现阶段结果只是为企业发展战略提供参考。
4 结论与不足
本文的创新之处在于指明了异质性网络构建的理论基础,构建企业-专利有向异质性网络,并在理论基础之上选择基于SimRank 指标的链路预测算法作为本文的研究方法。本文的研究思想是将企业持有专利的引用专利视为企业对引用专利所蕴含的技术知识的关注和需要,本文的研究目的是挖掘企业的相似技术需要,以帮助企业在寻找潜在转移转化对象和防范竞争者的工作缩小范围,快速、准确地定位关系对象。在实证中,为符合二部图理论的标准,本文忽略企业之间的合作以及专利之间的引用,建立了企业与专利的直接互动关系,并将企业之间的实际合作作为对算法有效性的检验。最后,本文以燃料电池技术为例进行实证,将实验随机产生的10% 的测试节点中出现频次最大的节点作为本研究的目标对象,预测目标企业的潜在技术转移转化对象,并利用深度学习的表示学习方法对目标企业的竞合对象进行技术差异度度量,对竞合关系做进一步判别。
在实际生活中,专利技术转移转化以及研发合作多发生在具有亲缘、地缘、业缘等关系的企业之间,如母公司和子公司之间、隶属于同一母公司的多个子公司之间、在商业领域存在战略合作关系的公司之间等[9]。因此,本文的研究思路应用到实际中还需结合企业的实际发展规划以及潜在关系对象的发展情况。若实际中企业的业务或产品相同或相似,则为直接竞争者;若业务存在上下游关系或产品以及产品零部件存在互补关系,则更可能成为合作联盟。同时,竞争与合作是相互转化、相互依存的,由企业发展的不同时期和市场环境等多种因素而定。本文现阶段的研究是在大的行业范围内帮助企业缩小寻找最佳的转移转化对象范围,定位潜在关系对象,提供方法的参考,节约企业发展成本并对企业战略规划起到一定的辅助作用。
本研究的不足之处在于,对潜在转移转化关系的预测是基于图的拓扑结构信息进行随机游走来衡量任意对象之间的相似性程度,进而达到预测的目的,缺少对专利文本内容的深入挖掘。下一步工作将对文本内容的研究进行补充完善。
猜你喜欢
廉政瞭望·下半月(2021年5期)2021-07-20
中学生数理化·中考版(2020年10期)2020-11-27
中学生数理化(高中版.高二数学)(2020年2期)2020-04-21
意林(2018年3期)2018-03-02
车迷(2017年12期)2018-01-18
电子制作(2017年10期)2017-04-18
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
汽车与新动力(2014年4期)2014-02-27
中国发明与专利(2007年7期)2007-08-09
