
Feedback-Aware Anomaly Detection Through Logs for Large-Scale Software Systems
2021-10-26 08:37:40HANJingJIATongWUYifanHOUChuanjiaLIYing
ZTE Communications 2021年3期
HAN Jing,JIA Tong,WU Yifan,HOU Chuanjia,LI Ying
(1.ZTE Corporation,Shenzhen 518057,China;2.Peking University,Beijing 100091,China)
Abstract:One particular challenge for large-scale software systems is anomaly detection.System logs are a straightforward and common source of information for anomaly detection.Existing log-based anomaly detectors are unusable in real-world industrial systems due to high false-positive rates.In this paper,we incorporate human feedback to adjust the detection model structure to reduce false positives.We apply our approach to two industrial large-scale systems.Results have shown that our approach performs much better than state-of-the-art works with 50%higher accuracy.Besides,human feedback can reduce more than 70%of false positives and greatly improve detection precision.
Keywords:human feedback;log-based anomaly detection;system log
1 Introduction
L arge-scale software systems face one particular challenge which is anomaly detection.System logs provide a straightforward and common information source for anomaly detection.Typically,administrators manually check log files and search for problem-related log entries,which is error-prone and time-tedious.To reduce human efforts,researchers have proposed many automatic log-based anomaly detectors[1-19].However,these detectors are ineffective in real-world industrial systems.First,most detectors typically operate by identifying statistical outliers.The utility of a particular detector for a system depends on how well its statistical outliers align with system anomaly symptoms.In general,the gap between statistical outliers and real system anomalies can result in high false-positive rates and easily render an anomaly detector unusable.Second,new types of anomalies may arise during system updates and conflict with existing anomaly detectors to produce false positives.Third,heterogeneous and complex log data contains massive noise.This noise may mislead detectors and further increase false positives.
One way to reduce the false-positive rate is to build domain knowledge into a detector.For example,a designer might apply domain expertise to label training logs that are more likely to produce correct anomalies and/or filter anomalies based on semantically defined white lists.Unfortunately,this requires significant expertise in both the system and anomaly detection.Besides,a large number of logs from industrial large-scale systems are almsot impossble to label;e.g.,a Microsoft online service system even generates over one petabyte(PB)of logs every day[20].
In this paper,we consider an approach to reduce false positives based on incorporating human feedback.In our settings of feedback-aware anomaly detection,humans only provide feedback about whether the detected anomaly is false positive or not.This feedback is used by the detector to adjust the anomaly detection model structure.This approach has the advantage of an easy and concise feedback process with little overhead on time.The main contributions of this paper includes:
1)To the best of our knowledge,we are the first to incorporate human feedback to reduce false positives for the log-based anomaly detection task.
2)We propose a feedback-aware online anomaly detection approach that builds a graph model from an online log stream and adjusts the graph structure through human feedback.
3)We apply our approach to two industrial large-scale systems.Results have shown that human feedback can reduce most false positives and greatly improve detection precision.
The rest paper is organized as follows.Section 2 discusses the related work,Section 3 proposes the approach,Section 4 shows the experiment results,and Section 5 concludes this paper.
2 Related Work
2.1 Human-in-the-Loop Anomaly Detection
In existing works,incorporating human feedback into anomaly detection has been introduced.These works leverage the idea of active learning and focus on tuning the weights and scores in machine learning models.For instance,the online mirror descent(OMD)algorithm[21]associates a convex loss function to each feedback response which rewards the anomaly score.Active anomaly discovery(AAD)algorithm[22–23]defines and solves an optimization problem based on all prior feedback,which results in new weights for the model.
2.2 Log-Based Anomaly Detection
Log-based anomaly detection first parses logs into log templates based on static code analysis or clustering mechanism,and then builds anomaly detection models.These models include template frequency-based model,graph-based model,and deep learning-based model. The template frequency-based model[1–4]usually counts the number of different templates in a time window and sets up a vector for each time window.Then it utilizes methods such as machine learning algorithms to distinguish outliers.
This model sacrifices the abundant information and the diagnosis ability of logs and it is not accurate and efficient.Thus it cannot provide help for problem identification and diagnosis.The graph-based model[5–17]is the current research hotspot.It extracts template sequence at first and then generates a graph-based model to compare with log sequences in the production environment to detect conflicts.This model has three advantages.First,it can diagnose problems deeply buried in log sequences,for example,performance degradation.Second,it can provide engineers with the context log messages of problems.Third,it can provide engineers with the correct log sequence and tell engineers what should have happened.The deep learning-based model[18–19]leverages long short-term memory(LSTM)to model the sequence of templates.This model takes a long time for training and inference,and thus cannot support online anomaly detection and diagnosis.
3 Approach
3.1 Overview
To solve the problems mentioned above,we design a human feedback-aware anomaly detection approach,called LogFlash,as shown in Fig.1.The input is an online log streaml:=(l1,l2,l3,...),which is a log entry.Our approach consists of three main components,namely the online log parser,the online model learner,and the online anomaly detector.In the online log parser,multiple log templates are mined from the log stream and each log entry is replaced by its corresponding template.In this way,the log stream is transformed into a template streamp:=(p1,p2,p3,...).This template stream then goes through online model learner and online anomaly detector concurrently.The online model learner infers and updates a graph model called time-weighted control flow graph(TCFG)through mining the template stream.The online anomaly detector utilizes the latest TCFG model to detect anomalies in the template stream.Humans provide false positives in anomalies as feedback to the online model learner.The learner then adjusts the TCFG structure based on the feedback.
We leverage the existing online template mining algorithm[24]in the online log parser.Due to space limitations,we will only describe the TCFG model,online model learner,online anomaly detector,and human feedback loop.
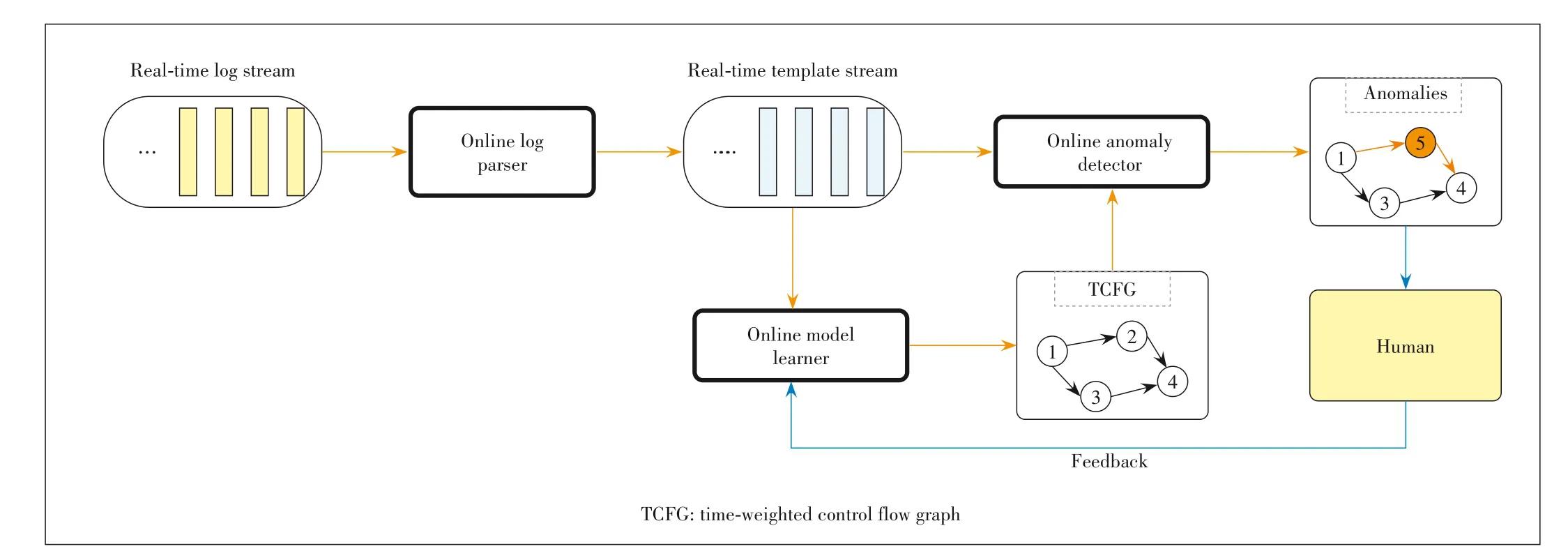
▲Figure 1.Approach overview
3.2 Time-Weighted Control Flow Graph
A TCFG is a directed graph consisting of edges and nodes and each edge has a time weight recording the transition time.The TCFG model stitches together various log templates and represents the healthy state of the baseline system.It is used to flag deviations from expected behaviors at runtime.A template is an abstraction of a print statement in a source code,which manifests itself in logs with different embedded parameter values in different executions.Represented as a set of invariant keywords and parameters(denoted by parameter placeholder*),a template can be used for summarization of multiple log lines.The TCFG is such a graph where the nodes are templates and the edges represent the transition from one template to another.Besides,every log has a timestamp indicating its print time,and thus the difference between two log timestamps represents the program execution time between the two logs.The time weight on each edge in the TCFG records the longest normal transition time between two templates.If the execution time between two logs exceeds the time weight,it means the system is suffering from performance problems.
Fig.2 shows an example of log templates and TCFG model.Each log has some invariant keywords and some variable parameters(shown in green),and log templates only reserve invariant keywords.Nodes in the TCFG are different log templates.Edges represent how each request flow passes between nodes,and the weight of edges indicates the transition time between two nodes.
3.3 Online Model Learner
We aim to construct a TCFG model in a black-box manner with only the template streamp.Our key idea is to define a dynamic pairwise transition rateαj,iwhich models how frequently a request flows from templatejto templateiand trains/updates the transition rateαj,iovertime with template streamp.
We further definef(t i|t j,αj,i)to be the conditional likelihood of transition between templatejand templatei,wheret jandt iare the timestamps of two occurrences of templatejand templateiinp.We assume the conditional likelihood depends on the transition time(t j,ti)and the transition rateαj,i.To model this parametric likelihood,we first conduct a statistical analysis of the distribution of template transitions.
We collect system logs of 5 minutes from an industrial cloud system Ada.Then we record the transition time between every occurrence of two neighboring templates in the same request by calculating the difference of their timestamps.Next,we count the number of occurrences with the same transition time and plot the distribution of each template transition.Results are shown in Fig.3.The distributions of these transitions show obvious long-tail distribution characteristics and the most transitions cost less than 0.2 norm-value of time.
Based on the above observations,the power-law likelihood is appropriate to modelf(t i|t j,αj,i),that is:
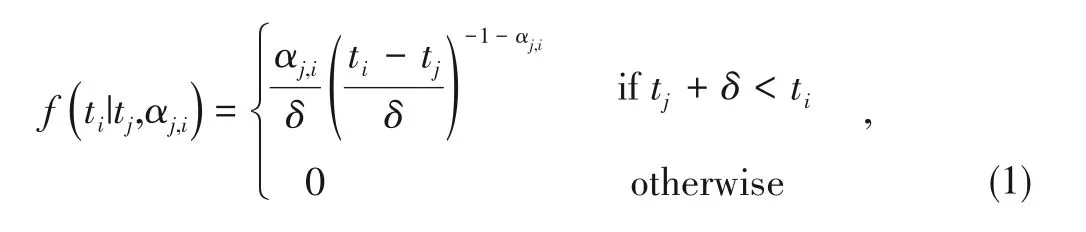
whereδstates the minimum transition time from templatejto templatei.In Section 4,the power-law distribution proves to be generic enough to adapt anomaly detection methods to testing logs from diverse industrial systems.Then we apply network inference algorithm to train the structure of TCFG.
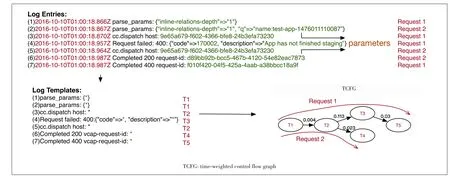
▲Figure 2.Log templates and TCFG model
1)Template stream likelihood.In the template streamp,transitions from different templates to a certain template are independent,that is,each occurrence of templateican only be transmitted from the occurrence of one parent template.Then the likelihood of occurrence of templateiat timet i,given a collection of previous occurred templates(t1,...,t N|t k≤t i),results from summing over the likelihood of the mutually disjoint transition from each previously occurred template to templatei:

▲Figure 3.Template transition distributions of an industrial software system Ada
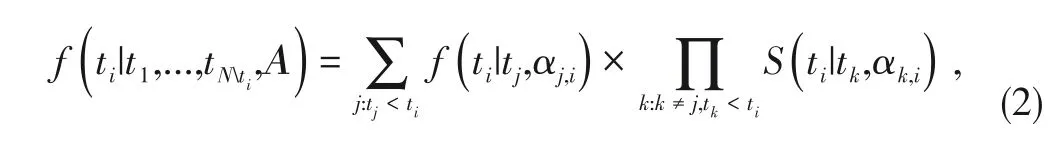
whereΑ={αj,i|i,j=1,...,N,i≠j},andS(t i|t k,αk,i)is a defined survival function of transitionj→ias

To simplify the modeling process,we assume that transitions are conditionally independent,given a set of parent templates.The likelihood of all transitions in the template stream is

wheret≤Tdenotes that the time of template stream is up toT.After plugging Eq.(2)into Eq.(4)and removing the conditionk≠j,the product result is independent ofj:

The fact that some templates are not shown in the observation window is also informative.We therefore add multiplicative survival terms to Eq.(5)and rearrange it with hazard function[25]or instantaneous transition rate of transitionj→iasH(t i|t j,αj,i)=f(t i|t j,αj,i) /S(t i|t j,αj,i).Then the likelihood of the template stream is reformulated as

2)TCFG structure inference problem.Our purpose is to infer a TCFG structure that is most possible to generate the template streamp.Given a TCFG with constant edge transition rateΑ,the TCFG structure inference problem problem reduces to solving a maximum likelihood problem:
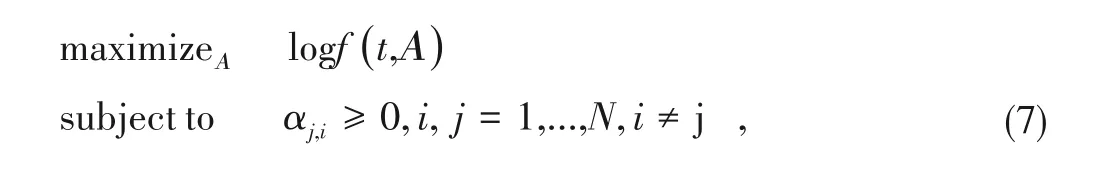
whereΑ={αj,i|i,j=1,...,N,i≠j}are the edge transitions we aim to train.The edges in TCFG are those pairs of templates with transition ratesαj,i≥0.
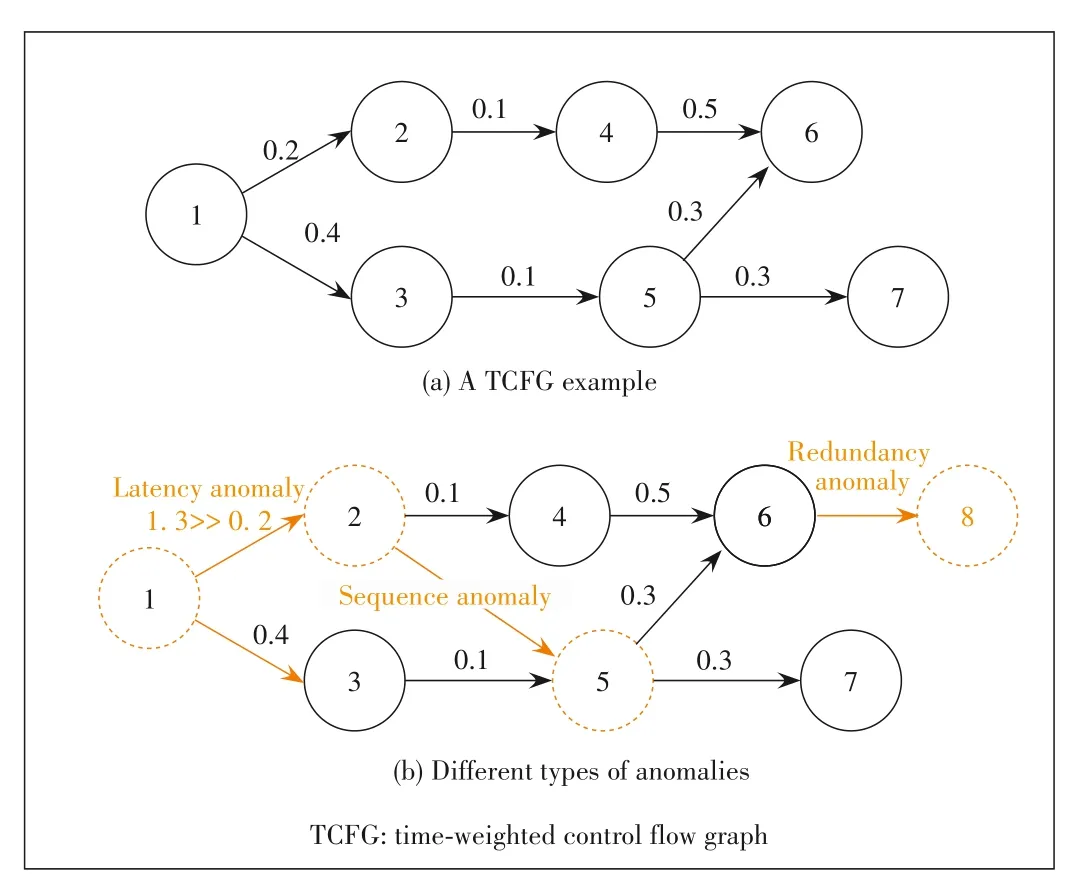
▲Figure 4.A TCFG example and different types of anomalies
To support online model update,we generalize the inference problem to dynamic TCFG structure with edge transition ratesΑ(t)that may change over time.To this aim,we first split the template streampto a set of sub-streamsc=(c1,c2,c3,...)based on the arrival of new templates.Given a time window sizew,each time a templateiarrives,we split out a sub-stream in whichiis the latest template.An example is shown in Fig.4.At timet1,log stream in the red block is the current sub-stream.At timet2,a new templateT2is observed and the current sub-stream becomes{T3,T4,T3,T2}.When it comes to timet3whenT5is observed,the current sub-stream becomes{T4,T3,T2,T5}.In this way,at any given timet,we solve the maximum likelihood problem over the set of sub-streams:
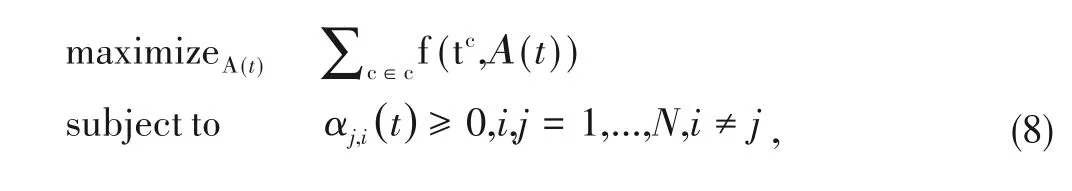
wherec∈c.Next,we show how to efficiently solve the above optimization problem for all time pointst.
3)Training method.The problem defined by Eq.(8)is serious for the power-law transition model.Therefore,we aim to find optimal training solution at any given timet.Since in the condition of power-law model,the edge transition rates usually vary smoothly,classical stochastic gradient descent[26]can be a perfect method for our training as we can use the inferred TCFG structure from the previous time step as initialization for the inference procedure in the current time step.The training phase uses iterations of the form:
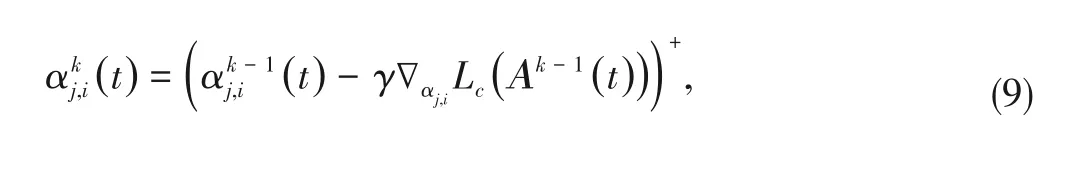
wherekis the iteration number,∇αj,i L c(·)is the gradient of the log-likelihoodL c(·)of sub-streamcwith respect to the edge transition rateαj,i,γis the update step size,and(z)+=max(0,z).The computations of log survival function,hazard function and gradient of sub-streamcfor power-law model in Eq.(1)are given in Table 1.
Importantly,in each iteration of the training phase,we only need to compute the gradients∇αj,i L c(Αk)for edges between templatejand templatei,as nodejhas been observed in sub-streamc,and the iteration cost and convergence rate are independent of|c|.
3.4 Online Anomaly Detector
The basic idea for anomaly detection is to compare the log stream with TCFG to find the deviation.We first define three types of deviations/anomalies,namely sequence anomaly,redundancy anomaly,and latency anomaly.A sequence anomaly is raised when the log that follows the occurrence of a parent node cannot be mapped to any of its children.A redundancy anomaly is raised when unexpected logs that cannot be mapped to any node in the TCFG occur.A latency anomaly is raised when the child of a parent node is seen but the transition time exceeds the time weight recorded on the edge.Fig.4 shows an example of different types of anomalies.Fig.4(a)is an example of TCFG with 7 nodes.As shown in Fig.4(b),suppose the transition time between Node 1 and Node 2 exceeds the time weight 0.2,they suffer from a latency anomaly.Node 5 appears after Node 2 unexpectedly and suffers from a sequence anomaly.Node 8 appears after Node 6 while Node 8 is a new template that has not been recorded in the TCFG,and thus a redundancy anomaly occurs.

▼Table 1.Computations of transition likelihood for power-law model
3.5 Human Feedback Handling
As mentioned before,users report false positives in anomalies through detection results webpage as human feedback.The online model learner receives the feedback and adjust the TCFG based on the feedback.For different types of anomalies,the online model learner takes different operations.These operations are shown in Algorithm 1.

Algorithm 1.Human Feedback Handling Algorithm Input:Human feedback Anomaly.Definition:TCFG denotes the current TCFG model 1. if Anomaly.type=“Sequence”2. then TCFG.addEdge(Anomaly.parentNode,Anomaly.childNode)3. if Anomaly.type=“Redundancy”4. then TCFG.addNode(Anomaly.redundant Node)5. if Anomaly.type=“Latency”6. then TCFG.setTimeWeight(Anomaly.parentNode,Anomaly.childNode,Anomaly.transitionTime)
•Sequence anomaly.A sequence anomaly is raised when the log that follows the occurrence of a parent node cannot be mapped to any of its children.If a sequence anomaly is a false positive,it means the log that follows the occurrence of the parent node should be its child.In other words,the transition between the parent and the child has not been correctly learned.For instance,in Fig.4(b)Node 5 appears after Node 2 unexpectedly and suffers from a sequence anomaly.If it is a false positive,it means there should be a transition edge from Node 2 to Node 5.Therefore,the online model learner takes the operation to add a transition edge from the parent and the child in TCFG.
•Redundancy anomaly.A redundancy anomaly is raised when unexpected logs occur that cannot be mapped to any node in TCFG.If a redundancy anomaly is a false positive,it means the template of the unexpected log should be in TCFG.For instance,in Fig.4(b)Node 8 appears unexpectedly and raises a redundancy anomaly.If it is a false positive,it means Node 8 should be in the path.Therefore,online model learners take the operation to add the template of the unexpected log to TCFG.
•Latency anomaly.The time weight on each edge in the TCFG records the longest normal transition time between two nodes.An intuitive way to determine time weight is to update the time weight once it meets a longer transition time in the log stream.However,it is hard to determine whether the longer transition time is a real latency anomaly or normal latency fluctuation.Therefore,we rely on human feedback to update the time weight.If a latency anomaly is a false positive,it means the time weight is too small and should be updated.Therefore the online model learner updates the time weight once it receives feedback of latency anomaly.For instance,in Fig.4(b)the transition time between Node 1 and Node 2 exceeds the time weight 0.2,and then they suffer a latency anomaly.If it is a false positive,it means the transition time 1.3 is normal.Therefore,the online model learner takes the operation to update the time weight from 0.2 to 1.3.
4 Experiment and Evaluation
4.1 Experiment Setup
We test our approach on three industrial large-scale systems called Ada,Bob,and Dockerd.Ada is an online image identification and analytics system that serves thousands of users.Bob is a software distribution system for 5G stations and chipboards.It distributes upgrade or bug fixing patches to thousands of 5G chipboards.We collect system logs of two days from Ada and Bob and use logs for training.Dockerd is a component of a Platform as a Service(PaaS)platform which contains 10 components and 957 nodes producing more than 8.1 million system logs per day.We collect logs of 20 days with a size of 52.94 G to verify the effectiveness of our approach.
We choose the state-of-the-art log-based anomaly detection DeepLog[18]and LogSed[6]as baselines.DeepLog leverages LSTM to model template sequences and detect anomalies through computing the distance between observed templates and predicted templates.LogSed first proposes TCFG model and infers the TCFG model based on frequent sequence mining.
We use typical Recall and Precision as our evaluation metrics,which are defined as follows:

where TP,FP,TN,FN are referred to as true positive,false positive,true negative,and false negative.
4.2 Evaluation Results
Logs in real-world industrial systems are much more complex and heterogeneous than lab systems,and it is very hard for today’s anomaly detectors to produce satisfying results.Table 2 shows the evaluation results of Ada.Both LogSed and DeepLog show poor precision which means they produce lots of false positives.Our approach outputs 74 anomalies in which 31 anomalies are true positives leading to a precision of 0.42 without human feedback(statistics in parentheses).After we incorporate human feedback,our approach produces 36 anomalies.We also record the times of human feedback during training.Experts labeled 28 false positives as feedback to guide the system and the labeling task only costs about 5 minutes.
Bob is even more complex than Ada.Each 5G station and chipboard are in different environments with different network status,load status,etc.Logs of many processes such as network test,heartbeat,software download,reconnect,software security and consistency check are interleaved together.It is almost impossible for existing detectors to learn a usable model from such noisy system logs.As shown in Table 3,LogSed and DeepLog show a precision of 0.04 and 0.09 separately.Our approach detects 137 anomalies without human feedback in which 10 anomalies are true positives.After incorporating human feedback,the number of detected anomalies reduces to 13 leading to 0.77 precision.During training,experts label 52 false positives as feedback in total that costs about 15 minutes.
As evaluating the performance of the framework on Dockerd logs,our approach detects 1 515 sequence anomalies without human feedback,of which less than 160 are true positives.After dropping duplicates and incorporating human feedback,the accuracy rate increases to 0.82.In summary,our approach achieves much better precision than baseline works.Incorporating human feedback effectively reduces false positives and significantly improves model performance.Besides,the feedback process is very easy for experts and saves a lot of time.
5 Conclusions and Future Work
In this paper,we propose a feedback-aware anomaly detection approach.It builds a TCFG model to describe normal system status and incorporates human feedback to adjust the graph structure to reduce false positives.Experiment results on two industrial large-scale systems show that our approach enjoys much better precision than baselines.Besides,human feedback can significantly reduce false positives and improve model performance.

▼Table 2.Evaluation results of Ada
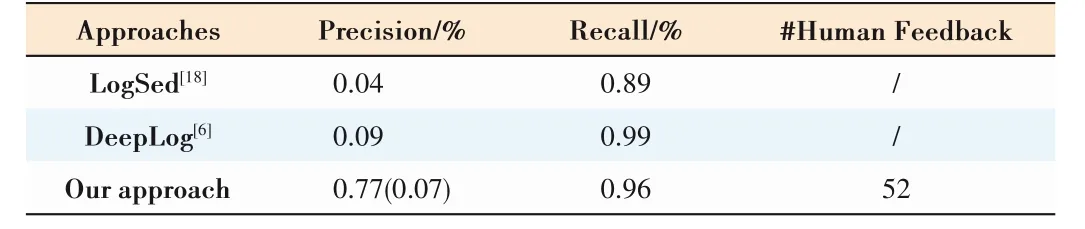
▼Table 3.Evaluation results of Bob
In the future,we will improve the human feedback handling process and perform more sophisticated tuning on the model with human feedback.

- ZTE Communications的其它文章
- ZTE Communications Guidelines for Authors
- Editorial:SpecialTopic on Wireless Intelligence for Behavior Sensing and Recognition
- Semiconductor OpticalAmplifier and Gain Chip Used in Wavelength Tunable Lasers
- Super Resolution Sensing Technique for Distributed Resource Monitoring on Edge Clouds
- QoE Management for 5G New Radio
- A Survey of Intelligent Sensing Technologies in Autonomous Driving