
基于知识图谱和语义相似度的岗位匹配与排序方法
2021-10-25 08:49何春辉郭博譞
湖南城市学院学报(自然科学版) 2021年5期
何春辉,郭博譞
(1.湘潭大学 数学与计算科学学院,湖南 湘潭 411105;2.北京工业大学 北京-都柏林国际学院,北京 100124)
从人力资源的角度看,组织机构之间的核心竞争力主要体现在人才的竞争上,谁拥有了核心人才和团队,谁就占据了市场的主导地位.不同企业在核心人才的招聘中,存在着非常激烈的竞争关系[1].随着“互联网+”政策的推进和人类思维方式的转变,传统线下招聘与求职方式已无法满足用人单位和求职者的招聘与求职需求.很多用人单位的招聘形式和求职者的求职方式都发生了变化,越来越多的用人单位会通过网络招聘平台发布岗位招聘信息,而求职者也更倾向于采用电子简历在网络平台上进行求职.
网络招聘能够成为用人单位和求职者的首选招聘方式,是因为它具有如下几方面优点[2]:1)用人单位和求职者的信息更加透明且可信度更高;2)网络招聘的成本更低;3)网络招聘的渠道更宽广;4)网络招聘更有助于实现人-岗匹配;5)网络招聘信息能够实现跨平台共享.虽然网络招聘具有诸多优点,但目前也存在2个问题急需解决[3]:1)用人单位所发布的1个招聘岗位,虽然可以收到成百上千份简历,但其中真正对口的极少;2)求职者虽然可以同时申请很多不同的就业岗位,但是经常会发现投递大量简历之后却无法收到用人单位的面试通知.结合行业特点并经过深入分析之后发现,若想突破上述困境,解决好以下2个问题是关键:1)如何为用人单位发布的岗位精准匹配潜在的求职者;2)如何根据求职者所具备的专业知识和就业意向自动匹配对口的就业岗位.若能解决好这2个问题,就可以极大地推动网络招聘平台的发展.
基于此,本文提出了一种基于知识图谱和语义相似度的岗位匹配与排序方法:首先,构建一个高等教育的学科专业知识图谱,并以它作为中间桥梁,将用人单位、求职者以及人才培养单位联系起来;其次,用人单位可根据自己的业务岗位需求,实时发布自己的招聘岗位与对应的专业技能要求信息,而求职者则可以结合自己的专业特性和招聘岗位的要求有针对性地进行专业知识的学习和强化培训,从而掌握相应岗位所要求的技能;最后,人才培养单位可以根据人才市场的行情,快速捕获用人单位提供的相关岗位任职要求并及时修订相关专业的培养方案,根据不同的专业做到有针对性地培养高级人才,从而进一步提高求职者与就业岗位之间的匹配度.系统相关实体之间的关系如图1所示.

图1 相关实体关系
从图1中可以看出,用人单位和求职者属于整个网络招聘过程中的直接参与者,而人才培养单位属于一个隐形的间接参与者,它主要起到调节整个市场供需平衡的作用.因此,本文的研究重点是解决用人单位发布的岗位与求职简历之间的智能匹配与排序问题.
1 专业知识图谱构建
考虑到用人单位发布的岗位任职要求和求职者所具备的专业知识之间存在一种很强的隐含关系(用人单位希望招聘到可以胜任岗位要求的求职者),二者之间可以建立映射关系的是专业、学科名称或者学位门类等实体,所以用人单位在发布招聘岗位时,通常会给出岗位的任职要求,其中会包含相关岗位对应的学科专业和技能要求等信息.
为了构建一个尽量完善的学科专业知识图谱,本文以国家教育部公布的普通高等学校本科专业目录[4]作为构建专业知识图谱的基础数据.该目录中的数据经过预处理后,最终构建出了一个专业知识图谱,并采用Neo4j[5]图数据库进行存储与查询.整个图谱共包含703个专业实体,93个专业类实体和12个学位门类实体.此外,还包含专业所属专业类和专业可授予学位类型以及专业所属门类3种实体关系共2 165条.所构建专业知识图谱的部分实体与所属关系的查询结果如图2所示.

图2 专业知识图谱的部分实体关系查询结果
2 命名实体识别
命名实体识别[6]属于自然语言处理中的热点研究方向,其目标是从给定的一段文本序列中自动识别出命名实体并打上对应实体类型标签.本文用命名实体识别算法从岗位任职要求对应的文本片段中自动识别并抽取出相应的学历、专业名称、所属专业类和学位门类等信息.特别地,对于那种没有学历和专业知识要求的岗位,此步骤识别的结果为空,也就意味着这类岗位对所有求职者都没有学历和专业知识的门槛要求.近些年,命名实体识别任务在很多领域都取得了很好的效果,最常见的有2大类方法.
第一类是基于条件随机场(CRF)的命名实体识别方法[7];第二类是基于预训练语言模型和深度学习的Bi-LSTM-CRF命名实体识别方法[8-10].上述2类方法有一个共同点,即只适用于已知命名实体类别,且命名实体列表无法穷举的情况.考虑到招聘岗位要求中所涉及的命名实体比较特殊,它属于既知道命名实体类型又可以穷举实体列表的情况.因此,上述2类方法对它并不太适用.为解决这个问题,本文采用基于规则库的命名实体识别方法,用于完成岗位要求中的命名实体识别任务.由于识别任务中需要识别学历、专业名称、专业类和学位门类4类命名实体,本文设计了4种可扩展的规则库,分别为学历库(涵盖所有学历类型:专科、本科、研究生),专业名称库(涵盖专业目录[4]中提取的计算机科学与技术、数学与应用数学等703个不同的专业名称),专业类库(涵盖专业目录[4]中提取的计算机类、数学类等93个不同的专业类名称)和学位门类库(涵盖专业目录[4]中提取的理学、工学等12个不同的学位门类名称).首先,通过对上述4个规则库进行实体标注和权重赋值,并以自定义方式集成到HanLP[11]自然语言处理工具包中,构建出一个简单高效的命名实体识别模型;其次,用该方法对岗位要求的文本片段内容进行分词和命名实体识别建模求解,抽取出对应的实体.
3 智能匹配与排序
现有的主流网络招聘平台,通常都是在同一个大平台下,划分成不同的2个子系统,即用人单位登录子系统和求职者登录子系统,且其功能各不相同.
对于用人单位登录子系统而言,主要功能是给用人单位编辑和发布招聘岗位信息.用人单位注册账号后,就可以在授权范围内发布一定量的有效招聘岗位.其发布的岗位信息需要通过平台提供的模板、按照特定的格式要求(便于解析和存储)进行组织;招聘平台还允许用人单位查询与导出部分与相关岗位要求契合度较高的求职者的简历.求职者登录子系统的主要功能是让求职者填写简历和浏览岗位并投递简历.招聘平台服务提供方会免费为实名制认证的求职者开放账号并允许其准备和发布一定量的求职简历,这些求职简历同样需要通过平台提供的模板、按照特定的格式进行组织;招聘平台也允许实名制认证的求职者浏览自己感兴趣的岗位并投递简历.
在上述场景下,如何有效地将2个子系统从后台关联起来并自动根据简历信息对岗位进行匹配与排序是打通2个系统壁垒的关键.为解决上述问题,本文提出了一个基于知识图谱和语义相似度的岗位匹配和排序方法.
3.1 智能匹配
考虑到求职简历通常只会包含求职者基本情况、学历、所学专业、项目经历或者掌握的专业技能等信息.因此,提出了两阶段方法来解决岗位和求职简历之间的智能匹配与排序问题.
第一阶段(初筛阶段),利用第2节所述命名实体识别方法对平台中有效招聘岗位的要求内容进行分析,得到所有岗位要求中对应的学历、专业、专业类、学位门类4种实体列表;将专业类列表和学位门类列表中的所有实体通过第1节所述的专业知识图谱进行查询(查询示例如图2所示),得到它们对应的专业名称,将其与命名实体识别专业列表中的专业实体名称进行融合并去重,仅保留学历和专业名称2个列表;采用“与或”相结合的方式对学历列表中实体和专业列表中实体构造统一的检索表达式,即[e.g:((学历=专科OR学历=本科OR学历=研究生)AND(专业=软件工程OR专业=信息安全OR专业=计算机科学与技术OR专业=网络工程))],并在求职者简历库中进行检索,找出符合学历和专业要求的简历子集.
第二阶段(排序阶段),所得简历子集包含的简历虽然都符合岗位所要求的学历和专业知识,但是岗位所要求的技能信息和工作经验等情况并未考虑,因此,需要根据求职简历中填写的技能信息以及工作经历与岗位任职要求的匹配程度进行排序,才能实现最终的岗位与简历的匹配,详细的排序算法见3.2小节.
3.2 排序算法
排序算法的功能是对3.1节得到的简历子集,采用基于BERT向量表示[12]的语义相似度排序算法对简历进行排序,为招聘岗位自动匹配最相关且符合岗位要求的简历.整个排序算法共分为4个核心步骤:
1)输入某份招聘岗位任职要求所对应的文本片段和3.1节中筛选出的简历子集中所对应的技能和工作经验文本片段.
2)调用开源的BERT向量转化模型[12],将上述文本转化为向量(详细步骤见文献[13]).
3)利用余弦相似度[14]算法计算这2个向量之间的相似度,以此作为岗位和简历之间的匹配度得分,输入到下一步.
4)按照每个岗位与不同简历的匹配得分进行降序排序,排序列表即为岗位与简历的最优匹配结果.用人单位可以根据该列表找到最合适的潜在求职者.换言之,根据上述匹配结果,求职者也可以知道当前招聘系统中最适合自己的岗位.
值得注意的是,BERT预训练语言模型采用双向transformer作为编码器实现特征抽取,并结合多头注意力机制捕获更多的上下文信息,从而将词语转化为语义特征更丰富的向量形式.注意力机制输入部分由Query(Q),Key(K)和Value(V)3个不同的向量构成,先通过Q*K向量来表示输入部分字向量之间的相似度,再通过Dk进行合理的缩放,并由softmax函数做归一化处理得到最终的概率分布,进而得到句中所有词向量的权重求和表示.注意力和多头注意力公式为
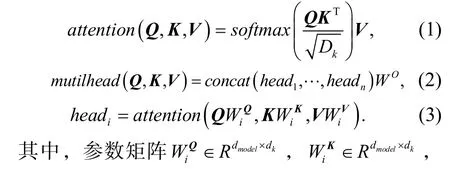
4 实验结果与分析
为了验证BERT语义相似度算法的排序准确性,在实验中,人工标注了200组招聘岗位任职要求文本片段与求职简历中所对应的技能和工作经验文本片段数据集,分别用ESim[15],Linkage[15]和BERT+余弦相似度算法来计算语义相似度匹配准确性,并采用平均准确率指标(accuracy)来评估相关模型的性能,实验结果如表1所示.

表1 不同算法的语义相似度匹配准确率 %
从表1可看出,BERT+余弦相似度匹配准确性最高,平均准确率为85.6%.
以Java开发工程师和数据分析师简历作为样例进行分析,图3展示了本文所提方法分别为其自动匹配的Top5岗位列表.

图3 Java工程师和数据分析师简历智能匹配的Top5岗位列表
5 结束语
本文提出了一种先按字符检索来筛选符合招聘岗位的简历子集,后按语义相似度算法对所选简历子集进行排序的两阶段岗位智能匹配与排序方法.实验结果表明,引入知识图谱和基于BERT+余弦的语义相似度计算方法后,其平均排序准确率相对基线方法有显著的提升,它可以根据简历中的求职要求给出契合度最高的岗位.本研究目前仅采用BERT+余弦的语义相似度计算方法来实现排序,在后续研究中,可以考虑结合BERT和全连接网络来提升语义相似度的计算性能,进一步优化排序结果.
猜你喜欢
英语文摘(2022年9期)2022-10-26
名家名作(2021年4期)2021-05-12
科普童话·学霸日记(2020年1期)2020-05-08
今日农业(2019年11期)2019-08-15
小天使·一年级语数英综合(2019年2期)2019-01-10
环球时报(2018-07-18)2018-07-18
环球时报(2018-01-10)2018-01-10
黄河黄土黄种人(2017年4期)2017-04-26
航天工业管理(2016年5期)2016-03-28
海外英语(2013年8期)2013-11-22
