
深度学习框架下类别不平衡数据情感分析
2021-10-21 03:10张志武薛娟陈国兰
现代情报 2021年10期
张志武 薛娟 陈国兰
DOI:10.3969/j.issn.1008-0821.2021.10.009
[中图分类号]TP391;G203 [文献标识码]A [文章编号]1008—0821(2021)10—0075—08
随着社交网络和移动互联网对人们日常生活影响的不断深入,人们习惯于在线浏览事物评论信息和发表留言,而这些评论中往往包含有用户的情感和观点信息。大数据时代,这些互联网观点数据急剧增长,对它们的情感分析与数据挖掘引起越来越多的学者的关注。情感分析是通过分析评论语句或文档中的情感词语和表达,来预测评论观点的情感极性。传统的基于词典和基于机器学习的情感分析是假设不同情感极性类别的样本是均衡分布的,而现实的网络语料中,不同类别的语料样本的数目有时相差很大。这种样本分布的类别不平衡性往往导致传统的机器学习方法的性能下降,甚至分类模型失效。随着大数据的出现,类别不平衡数据的情感分类又重新成为数据挖掘领域具有挑战性的实际问题。
类别不平衡问题是机器学习领域的经典研究课题。通常的不平衡数据情感分析是先进行采样不平衡处理,然后利用机器学习方法对数据进行模型训练与预测分类。本文针对二类情感极性分类问题,基于长短期记忆(Long Shon Term Memory,LSTM)神经网络,提出一种LSTM深度学习框架下自适应不平衡数据情感分析方法。针对低度不平衡数据集,先对少数类进行过采样,然后利用LSTM直接进行深度学习训练,最后用训练好的模型进行情感分类;针对高度不平衡数据集,先对多数类进行多组欠采样,并分别与少数类样本组合成多组平衡的训练数据集,然后分别对每组训练数据学习一个LSTM模型,在情感分类预测时通过集成学习获得最终情感极性。本文的创新点在于利用LSTM深度网络具备学习长期依赖关系的特性,提高情感分析性能;同时,针对训练数据集的不平衡程度,自适应采用相应的不平衡处理方法与集成学习模型。
1相关工作
1.1情感分类
传统的情感分类研究主要以二类情感极性分类为主,即将情感数据极性分为积极情感和消极情感两种类型,研究方法包括基于词典的方法、基于机器学习的方法以及混合方法。基于词典的方法以通用情感词典和特定领域情感词典为主要依据,同时根据评论数据的句法结构设计情感极性判断规则。Hu M等提出将形容词作为情感词建立情感词典,利用WordNet网络中形容词同义词集和反义词集来预测形容词的情感极性,进而判断整个评论的情感极性。Pang B等率先运用机器学习方法解决评论文档的二元情感分类,并在电影评论情感分类问题上对比了不同特征组合与不同机器学习方法的实验效果。Fang J等将评论中Unigrams特征词的词典信息融入语句特征向量中,然后使用支持向量机(SVM)分类器进行语句级的情感分类。张志武提出基于谱聚类的跨领域迁移学习,用于不完备数据的产品评论情感分析。随着互联网评论数据规模的与日俱增,基于大数据的深度学习技术被越来越多地应用于情感分析领域。Kim Y应用卷积神经网络(Convolutional Neural Network,CNN)模型对语句级隋感分类问题进行研究。Irsoy O等将循环神经网络(Recurrent Neural Network,RNN)应用于意见表达抽取任务的自然语言分析。Tang D等运用门控循环单元神经网络(Gate RecurrentUnit,GRU)进行短文本情感分类。Zhu X等提出使用长短期记忆网络LSTM序列模型来解决情感分类问题,将评论语句建模成词序列来捕捉其长依赖关系。梁军等在基于树结构的递归神经网络上扩展了LSTM模型,并利用词语间的关联性构建情感极性转移模型。吴鹏等在财经微博文本情感分类中,基于认知情感评价模型建立情感规则,并对文本进行情感标注,利用LSTM模型进行深度学习训练,进而实现海量微博数据的情感分类。Wu O等提出一种带区分的标签标注策略和词语极性翻转模型,利用两级LSTM网络构建情感分类器。
1.2类别不平衡学习
常用的类别不平衡学习方法有样本采样、单类别分类、代价敏感学习、集成学习、主动学习等方法。在样本采样方法中,增加少数类样本的方法称为过采样,减少多数类样本的方法称为欠采样,它们的目的都是使采樣后的不同类样本的数据分布趋向均衡。针对类别不平衡的中文语料,王中卿等提出一种基于数据欠采样和多分类器集成学习系统进行中文情感分类。Li S等提出了基于聚类的分层欠采样框架和平滑策略,解决真实情感分类的数据与特征分布不平衡问题。Ghosh K等利用微博平台研究了类不平衡问题对情感分析的影响,对少数类进行过采样不平衡处理,并用支持向量机和朴素贝叶斯两种分类器进行情感分类。Yan Y等基于概念之间的关联关系.提出一种两阶段的分类框架,以提高不平衡数据的分类准确性。殷昊等通过欠采样获得多组平衡训练语料,对每组语料训练一个LSTM模型,最后融合多个LSTM模型进行情绪分类预测。肖连杰等对不平衡数据集中的多数类进行模糊C-均值聚类欠采样,并与少数类样本构成平衡训练数据,最后在类平衡的数据集上进行集成学习和数据分类。陈志等针对不平衡文本数据,在卷积神经网络训练中,将类别标签权重引入到损失函数中,增强少数类对模型参数的代价敏感性,从而减小类不平衡对文本分类的影响。
2模型构建
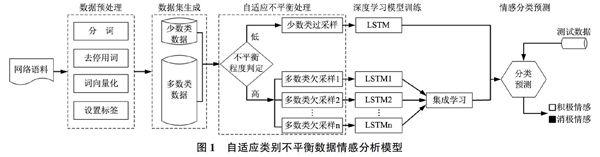
本文设计的深度学习框架下自适应类别不平衡数据情感分析模型如图1所示。首先,对网络语料进行必要的数据预处理,包括分词、停用词去除、词语向量表示以及根据情感极性设置情感分类标签;其次,将每条评论词汇向量转化为相应的矩阵,制作成适合于深度学习模型的数据集;再次,根据数据集中的类别不平衡程度,自适应地选择不同的采样方法和深度学习模型进行训练,如果不平衡程度低,则对少数类样本进行过采样,采样至与多数类样本数目相等,然后与多数类一起组成类别平衡的训练数据集,再进行一次LSTM深度学习训练,如果不平衡程度高,则对多数类样本进行多组欠采样,每次采样至与少数类样本数目相等,然后分别与少数类一起组成多组平衡的训练数据集,对每组数据集进行LSTM深度学习训练;最后,进行情感分类预测,当训练集的不平衡程度低时,测试数据直接在训练好的LSTM模型上进行分类预测,当训练集的不平衡程度高时,先对多个LSTM模型的测试输出进行集成学习,然后输出最后的分类预测结果。
2.1情感语料数据处理
在进行情感分析深度学习训练之前,需要对训练语料进行一定的预处理。网络评论情感语料首先经过jieba中文分词库分词,将对分类影响不大的停用词和高频词剔除,提取语料文档的情感词汇。为了适应机器学习算法,需要把数据输入转换成固定长度的特征向量。Google公司的开源Word2Vec模型可以将词汇从高维特征空间映射到一个嵌入的低维特征空间,同时保留词向量间的空间位置关系。在训练学习中,采用Python的Gensim包中集成的Word2Vec进行词向量的训练,维度值固定为200维,因此每条评论数据最终都转化为200维的向量。在设置二元情感分类标签时,采用0nehot编码向量作为标签向量,分别用[0,1]和[1,0]表示消极评论和积极评论。根据训练评论数据的情感极性,分别设置相应的情感分类标签向量。
2.2自适应不平衡采样
网络语料往往是情感类别不平衡的,而且不同的领域和平台的不平衡程度差异较大。对这种语料直接采用传统的机器学习情感分类方法进行情感分析会造成分类结果向多数类偏倚。如果统一采用简单的过采样不平衡处理有时会造成过拟合现象,而统一采用简单的欠采样不平衡处理有时又会损失较多的样本信息。因此,根据训练语料数据集中的类别不平衡程度,采取自适应地选择不同的采样策略,并为后续阶段的深度学习训练模型提供不同形式的平衡训练数据。
当不平衡程度低(多数类样本数量小于少数类样本数量的3倍)时,处理策略是对少数类样本进行过采样,采样至与多数类样本数量相等,然后与多数类一起组成平衡的训练数据集,输入到后续的LSTM深度学习模型中进行训练学习。最流行的过采样方法是综合少数类过采样技术(Synthetic Minority Oversampling Technique,SMOTE),它的工作方式是在特征空间中选择较近的少数类样本示例,在它们之间进行插值,从而产生额外的新样本。由于SMOTE对每个少数类样本产生相同数目的新样本,所以采用一种SMOTE变体方法——自适应合成采样(Adaptive Synthetic Sampling,ADASYN)方法,它利用样本分布来自动决定每个少数类样本需要产生多少个合成样本,近邻的多数类样本越多则产生的合成样本越多。
当不平衡程度高(多数类样本数量大于等于少数类样本数量的3倍)时,处理策略则是对多数类样本进行多次有放回欠采样,每次欠采样的数量与少数类样本数量相等,形成多个相互独立的训练子集,然后分别与少数类一起组成多组平衡的训练数据集,分别输入到后续的多个LSTM深度学习模型中进行训练与集成学习。虽然每个子集的数量少于总体样本数,但集成后的总信息量损失并不多。
2.3 LSTM模型与训练
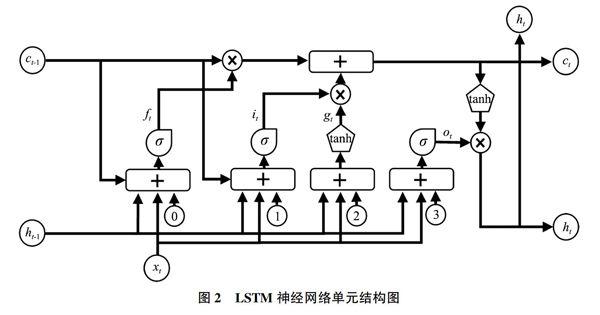
LSTM深度学习神经网络是标准的循环神经网络RNN的变体,它是在RNN基础上增加了3个控制信息流动的门单元。LSTM神经网络通过门控制的方式,丢弃近距离不重要信息,同时增强长距离重要信息,使得网络中的记忆单元具备记忆功能,可以利用历史信息学习长期依赖关系,同时避免了反向传播过程中的梯度消失和爆炸问题。由于其性能优越,在很多机器学习与人工智能应用中得到广泛运用,因此,本文采用LSTM深度学习模型进行情感分析训练与分类预测。
单个的LSTM网络单元结构如图2所示,遗忘门ft决定节点有多少信息会被遗忘,输入门it决定有多少信息可以流进节点,输出门ot决定节点内有多少信息被输出。ct-1表示从前一个单元传递来的记忆信息,ht-1表示前一个单元的输出,xt表示当前的输入向量,ct表示当前单元的记忆,ht表示当前单元的输出。信息在LSTM神经网络单元内部流动经历3个阶段:
1)遗忘门决定忘记信息。这个阶段主要是对上一个节点单元传过来的输入ht-1進行选择性忘记,它是通过一个Sigmoid输出层遗忘门实现的,它使单元状态中的每一个输出值介于0和1之间,越接近于0表示越应该丢弃,越接近于1表示越应该保留。遗忘门的作用是度量循环过程中每一个单元的相对重要程度,其计算公式如下:
2)输入门选择更新记忆信息。输入门用于对单元状态进行更新。首先,将前一个单元的输出ht-1和当前单元的输入xt信息传递到Sigmoid函数中去得到it,将其值调整到0~1之间来决定哪些信息需要更新;其次,还要将前一个单元的输出ht-1和当前单元的输入xt信息传递到tanh函数中去,创建一个新的候选值向量得到gt,里面包含可添加到新的状态单元的信息;最后,将前一单元传递的记忆信息ct-1与ft相乘用来表示遗忘信息,将it与gt相乘作为新的备选信息,用这两部分之和一起对单元状态进行更新。这一过程计算公式如下:
3)输出门选择输出信息。首先用Sigmoid层来决定要输出的单元状态的相关信息ot,然后用tanh函数处理单元状态,得到一个-1~1之间的值,最后将两部分信息相乘,得到要输出的部分ht,计算公式如下:
在实际训练学习过程中,搭建LSTM模型过程如下:
第一,训练词向量,提取语料特征。利用Py-thon的Gensim包中集成的Word2Vec进行词向量训练,将词语映射成200维向量,并做去停用词、去除乱码预处理。
第二,生成训练与测试数据集。根据不同平衡率的实验要求,从特征提取后的语料中选择相应的比例数据生成积极类和消极类训练数据集以及测试集的数据。
第三,定义LSTM的计算过程。用TensorFlow来实现LSTM,隐藏层网络输出维度为128,输出层节点数为2,学习率设置为0.01,每批次传入训练数据大小为16。定义损失函数Loss和优化器Optimizer。
第四,将数据传人定义模型的占位符,开始参数训练,设定迭代次数为20000次,训练结束后保存模型参数。
2.4集成学习
在类别不平衡程度较高的情况下,模型自适应地采用将多数类样本进行多组欠采样,并分别与少数类样本构成平衡的训练样本集,然后进行多组LSTM训练学习,每组LSTM模型相当于集成学习中一个弱分类器。由于基学习器采用的是LSTM深度神经网络学习器,这种不稳定学习算法对训练集十分敏感,采用多组欠采样方式实现数据样本扰动可以增强基学习器之间的多样性,因此,集成学习采用Bagging法(又称装袋法),既能降低方差,又能提高训练稳定性。多组LSTM基学习器还可以并行学习训练。
当需要进行分类预测时,测试样本先在每一个训练好的LSTM基学习器上分别进行分类预测,然后通过集成学习的投票法策略,对所有基学习器的分类结果进行统计,将出现次数最多的预测类别作为最终的分类结果。
3实验与结果分析
3.1实验数据集
本文选取搜狗实验室提供的网络评论语料作为情感分析词向量的实验语料(搜狗实验室网络语料URL地址:http:∥www.sogou.com/labs/resource/list_yuliao.php)。语料库中包含图书评论、酒店评论、电子产品评论等,其中积极评论有10673条,消极评论有10428条,表1给出了语料集合的部分样例。实验在原始语料库上,分别针对实验研究的低度和高度两种类别不平衡程度,选择积极类评论与消极类评论的比例分别为3:1和7:1。
3.2买验结果
为了验证本文选择的LSTM深度学习框架和不平衡处理方法的有效性,实验采用情感分类中常用的准确率作为评价指标,由于本文研究的是不平衡数据的二类分类问题,实验中还选取了不平衡数据二元分类常用的综合指标F1值作为评价指标。具体实验分成了3种情形进行对比和分析:
1)LSTM方法与典型的深度学习方法在不平衡数据上的情感分析对比实验。
2)LSTM框架下不平衡处理方法的对比实验。
3)LSTM情感分析有效性验证。
3.2.1深度学习类别不平衡情感分析方法对比
为了验证深度学习方法在类别不平衡数据上的情感分析性能,本文选取典型的深度学习方法:卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)和门控循环单元(Gate Recurrent Unit,GRU)神经网络与本文采用的LSTM方法进行对比。为了体现对比实验的公平性,实验中所有方法采用统一的不平衡数据处理:当不平衡程度低时,对少数类样本进行随机过采样;当不平衡程度高时,对多数类样本进行多次有放回欠采样。
表2给出了高低两种不平衡率情况下的深度学习方法在准确率与F1值评价指标上的对比实验结果。从实验结果看,在低不平衡率和高不平衡率两种情况下,卷积神经网络CNN性能最差,循环神经网络RNN性能较差,门控循环单元神经网络GRU性能较好,长短期记忆神经网络LSTM性能最好,GRU与LSTM在低度不平衡情况下性能比较接近。具体来看,最低的准确率是CNN方法在高度不平衡情况下取得的,其值为0.7001,同时它的F1值也是最低,其值为0.4419;最高的准确率是LSTM方法在高度不平衡情况下取得的,其值为0.9349,最高的F1值是LSTM方法在低度不平衡情况下取得的,其值为0.8556。相对其他的深度学习方法,LSTM在准确率指标上至少提升4.09%((0.9276-0.8897)/0.9276),在F1值指标上至少提升9.29%((0.8221-0.7457)/0.8221)。
3.2.2 LSTM框架下不平衡处理方法对比
为了验证LSTM框架下情感分析在不同不平衡处理情况下的实验性能,本文设计了5种数据不平衡处理情况下的基于LSTM的情感分类方法:
1)完全训练+LSTM方法,未对不平衡训练集做平衡化处理,直接用全部数据作为训练数据,利用LSTM进行深度学习训练和分类预测。
2)随机过采样+LSTM方法,对少数类样本进行随机过采样,并与多数类样本组合成平衡的训练数据,再利用LSTM进行深度学习训练和分类预测。
3)随机欠采样+LSTM方法,对多数类样本进行随机欠采样,并与少数类样本组合成平衡的训练数据,再利用LSTM进行深度学习训练和分类预测。
4)随机欠采样+多通道LSTM,这是文献[18]的方法,对多数类样本进行多组随机欠采样,并与少数类样本组合成多组平衡的训练数据,分类器使用多通道LSTM神经网络。
5)自适应采样+LSTM方法,这是本文提出的方法,根据数据集不平衡程度自适应选择不同的采样不平衡处理和训练预测框架。
图3和图4分别比较了低不平衡率和高不平衡率两种情况下的不同方法在準确率指标上的对比实验结果,表3给出了这两种情况下F1值指标上的对比实验结果。从实验结果可以看出:
1)所有经过不平衡处理后的LSTM方法性能都优于未经不平衡处理完全训练的LSTM方法。
2)随机欠采样和随机过采样方法在不同平衡率下各有优劣。
3)随机采样多通道LSTM方法在低不平衡率情况下,由于通道较少,性能优势不明显。
4)自适应采样LSTM在不同平衡率下采用不同的采样策略和学习策略,能保持很好的性能优势,总体性能最优,相对未经平衡化处理的完全训练LSTM方法准确率至少提升22.82%((0.9526-0.7756)/0.7756),F1值至少提升96.64%((0.8426-0.4285)/0.4285),相对其他经过平衡化处理的LSTM方法性能准确率至少提升5.77%((0.9526-0.9006)/0.9006),F1值至少提升23.89%((0.8426-0.6801)/0.6801)。
3.2.3 LSTM情感分析有效性验证
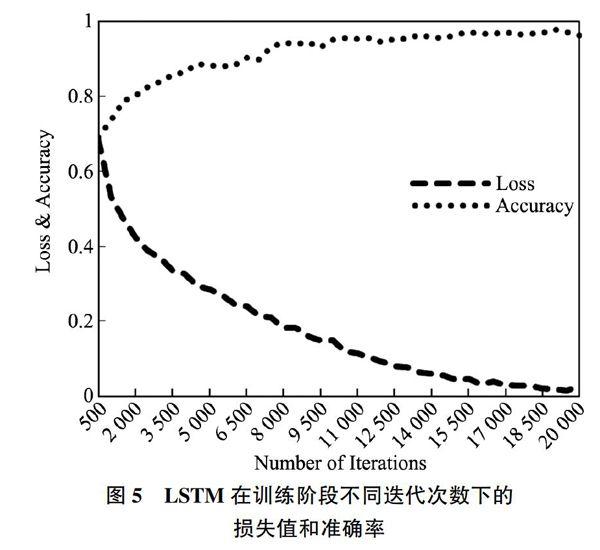
为了验证LSTM深度学习网络的训练收敛性和有效性,在LSTM的迭代训练过程中统计了损失函数和预测准确率。图5给出了LSTM深度学习网络在训练过程中不同迭代次数下的损失值Loss和预测准确率Accuracy的变化曲线。从损失值曲线和准确率曲线可以看出,LSTM在迭代过程中,随着迭代次数的不断增加,损失函数值逐渐减少,而准确率在不断上升。准确率随迭代次数的变化趋势是开始时准确率增加较快,后期的增长速率趋于平缓,逐渐趋向于1;损失函数值开始时减少速度快,后期减少速度放慢,并逐渐趋向于0。
3.3结果分析
1)典型深度学习方法在类别不平衡数据上的对比分析。
从对比实验结果来看,性能从低到高的方法依次是CNN、RNN、GRU和LSTM。而这4种方法的复杂程度也与这个顺序一致。CNN是具有深度结构的包含卷积计算的前馈神经网络,常用于视觉数据之类的空间特征数据,如图像识别。将情感分析的文本数据中的每个词语表示成一个列向量,将一条评论文本看成是多个词语列向量组成的二维数据时,CNN方法可以进行情感分析。传统RNN是序列模型,常用于文本数据分析,RNN的单元数比较多,梯度被近期单元的梯度主导,导致模型对长期的依赖关系不敏感,因此会出现梯度消失和梯度爆炸问题。而LSTM利用门机制解决了梯度消失问题,与此同时,LSTM利用细胞状态保存长期记忆,结合门机制对信息进行过滤,实现了对长期记忆的控制。GRU作为LSTM的一种变体,相对于LSTM而言参数更少、收敛更快,性能与LSTM接近,实验结果表明,LSTM性能略优于GRU。总体来看,带门控单元的RNN比传统的RNN性能表现更好。
2)LSTM框架下不平衡处理方法对比分析。
在LSTM深度学习框架下,所有经过不平衡处理后的方法的性能均优于未经不平衡处理完全训练的LSTM方法,这是因为数据分布不平衡影响了机器学习的性能.通常這种情况下机器学习会向多数类产生偏倚,经过平衡化处理后,不平衡性的影响得到一定程度的纠正,因此性能得到提升。简单的随机欠采样和随机过采样方法在不同平衡率下各有优劣,这说明选择机器学习方法时应在采样信息损失与数据分布影响之间进行平衡。将随机采样方法与多通道LSTM方法结合,进行不平衡数据情感分析,在低不平衡率情况下,由于产生通道较少,性能优势不明显。针对数据的不平衡程度,在不同平衡率下采用不同的采样策略和学习策略,自适应采样LSTM方法能保持很好的性能优势,这表明机器学习对输入数据的质量与分布有较强的依赖性,机器学习的总体性能除了与方法模型有关外,还与输入数据特性和数据预处理密切相关。
3)LSTM应用于情感分析的有效性分析。
在LSTM深度学习的迭代优化过程中,优化器的优化目标是使预测值与真实值之间的损失最小,在不断的迭代训练过程中,损失函数值逐渐减少,同时准确率在不断上升。实验验证结果显示训练过程中预测准确率一直上升,直至趋于平稳,偶有波动,说明训练时也有过拟合情况,但LSTM的学习性能总体是很稳定的。LSTM深度学习网络由于采用门机制,解决了梯度消失问题,同时也简化了调参的复杂度,门机制还具有特征过滤功能,丰富了自然语言处理中的向量的表示信息,在情感分析任务中是有效的方法模型。
4结语
本文针对不平衡数据的情感分析,在深度学习框架下,设计了一个自适应的类别不平衡数据情感分析处理框架,分别对低不平衡率数据集进行自适应合成采样或对高不平衡率数据集进行有放回欠采样,然后相应地进行一次LSTM深度学习训练或多组并行LSTM深度学习训练,以及单独预测分类或集成学习预测分类。在真实的网络语料上的实验表明,本文提出的方法能自适应地处理不同程度的不平衡数据,充分利用LSTM具备学习长期依赖关系的特性,提高了不平衡数据情感分析性能。未来的改进工作中,将探索不同的类别不平衡学习方法,优化采样技术,将代价敏感学习技术与主动学习技术融入不平衡数据情感分析中,以进一步提升情感分类方法的性能。多类别不平衡情感数据分析和情感强度分析也是未来研究工作的主要方向。
(责任编辑:孙国雷)
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
海外华文教育(2016年1期)2017-01-20
新校长(2016年8期)2016-01-10
当代教育理论与实践(2015年9期)2015-12-16
民族古籍研究(2014年0期)2014-10-27
商事法论集(2014年1期)2014-06-27
外语教学理论与实践(2014年2期)2014-06-21
