
多通道特征向量的新三角距离高效推荐
2021-10-21 02:40:10吕亚兰张恒汝徐媛媛
西南大学学报(自然科学版) 2021年10期
吕亚兰,张恒汝,秦 琴,徐媛媛
西南石油大学 计算机科学学院,成都 610500
推荐系统是目前解决信息过载的有效手段.协同过滤[1]是主流的推荐算法之一,它利用历史评分数据来获取用户对项目的偏好.协同过滤按照不同的实现方式可以分为基于k近邻[2]、 基于矩阵分解[3]以及基于神经网络的协同过滤算法[4]等.k近邻利用历史评分获取k个具有相似偏好的用户或者具有相似属性的项目[2],常用表征用户或项目相似度的距离有:Cosine[5],PCC(pearson correlation coefficient)[6],Jaccard[7]和CPC(constrained pearson correlation)[8].然而这些算法大都采用用户或者项目的全局评分来计算相似度,导致其时间复杂度较高,推荐效率低.
本文提出了一种多通道特征向量的新三角距离推荐算法(new triangular distance recommendation algorithm for multi-channel feature vector,NTRFC).算法的输入为从原始评分矩阵中提取的多通道特征向量(简称特征向量),在k近邻算法中采用新三角距离,从而提高推荐效率并保持较好的推荐准确度.
首先,从原始评分矩阵中提取得到特征向量,其通道数目为原始评分矩阵中评分等级的数目[9],将其作为输入,可有效降低算法的复杂度.假定评分矩阵有n个用户,m个项目,以及l个评分等级.以原始评分矩阵为输入,计算相似度的时间复杂度为O(nm),而以多通道特征向量为输入,计算相似度的时间复杂度是O(lm).评分矩阵中用户数目n远远大于评分等级数目l,故O(lm)远远小于O(nm).例如,数据集Amazon(http://snap. stanford. edu/data/web-Amazonlinks. html)和Movielens943u (https://grouplens. org/ datasets/movielens/100k/)的评分等级均为1~5分,故它们的通道数目为5,即每个项目的特征向量长度为5.
其次,利用两个项目的特征向量构建新三角距离.该距离将三角距离和Jaccard系数结合.这是因为在提取特征向量后,损失了用户、 项目以及评分之间的关系信息,仅保留用户对项目评分的数量信息.若仅考虑三角距离,则无法精确判断项目之间的相似度.考虑到Jaccard系数能充分利用共同评分项目数占所有项目数的比值信息,故结合Jaccard系数,从而在一定程度上弥补了原始评分信息.
最后,将设计的新三角距离用于k近邻算法中,以判断两个项目的相似度.本文提出的NTRFC算法与基于其他距离的k近邻算法在4个真实数据集上进行对比实验,利用6种准确度指标和运行时间进行评价.实验结果表明:NTRFC算法运行时间低于已有算法,并在大部分准确度指标上占优.
1 相关工作
本节介绍评分系统[10]定义和常见的几种距离,本文使用的符号见表1.

表1 符号系统
1.1 评分系统
现回顾评分系统[10]的定义,令U={u1,u2,…,un}为一个推荐系统的用户集合,令T={t1,t2,…,tm}为推荐给用户的项目集合,由此,评分函数定义为
R:U×T→C
(1)
其中,R为一个n×m的评分矩阵;R=(rip)n×m;C表示用户评价每个项目的评分等级构成的集合,如C={1,2,3,4,5}.
表2给出了一个用户数为5和项目数为6的评分矩阵.评级为1~5分,则通道数为5.评分反映出用户对项目的喜爱程度,分值越高表示用户越喜爱该项目,0表示用户未给项目评分.rip表示用户ui给项目tp的实际评分,G(tp,tq)表示对项目tp和tq共同评分的用户集合.例如,r12=3表示用户u1给项目t2评分为3分,G(t1,t2)={u1,u4}表示对项目t1和t2共同评分的用户是u1和u4.

表2 评分矩阵(R)
1.2 已有的距离
k近邻算法通常计算用户或项目之间的距离来寻找用户或项目的邻居,从而预测用户对项目的评分.表3列出了9个常用距离度量公式,并分析它们的时间复杂度.
表3中,Cosine[5],ED[11],BC[12],PCC[6],MD[13],SØrensen[14-15],Canberra[16],Lorentzian[17]和Divergence[18]距离的时间复杂度均为O(n),但BC[12]距离的时间复杂度为O(l).其中,n表示输入向量的长度,l表示评分的等级数.

表3 不同距离公式
2 NTRFC
NTRFC首先利用原始评分矩阵提取特征向量,然后基于特征向量设计新三角距离,最后将新三角距离应用到k近邻算法中.
2.1 特征向量的提取
项目的评分等级构成通道集合C.例如,当评分等级为1~5分时,通道集合C={1,2,3,4,5}.该集合包含有通道1~5,通道数l为5.为了处理项目的离散评分,本文将每个项目的评分映射到多个通道.
用户ui对项目tp的评分rip与通道的关系为
(2)
其中c表示当前通道数值.
当rip与c相等时,连接用户ui和通道c的边的数量加1.项目tp上通道c的连接数为
(3)
对于长度为l的通道,项目tp提取后的特征向量为
vp=[d(tp,c1),d(tp,c2),…,d(tp,cl)]
(4)
以表2展示的评分矩阵为例,项目t1对应的特征向量为v1=[0,2,0,1,0],如图1.

图1 多通道特征向量的构建
2.2 新三角距离
利用特征向量,设计新三角距离公式为
NTJ(vp,vq,tp,tq)=NT(vp,vq)×Jaccard(tp,tq)
(5)
其中,vp,vq分别为项目tp,tq的特征向量.NT(vp,vq)为三角距离,Jaccard(tp,tq)为Jaccard系数.
NT(vp,vq)为
(6)
其中‖·‖为向量的二范数.Jaccard(tp,tq)为
(7)
其中,Ip为对项目tp评过分的用户集合;Iq为对项目tq评过分的用户集合; |·|表示集合的基.
为了更准确地描述项目之间的相似度,新三角距离引入Jaccard系数.这是由于原始评分矩阵进行特征向量提取后,损失了用户、 项目以及评分之间的对应关系信息,只保留了用户对项目评分的数量信息.如果仅使用三角距离或其他一般距离则无法准确计算项目之间的相似度.以表2中项目t5和t6为例,通过提取后它们的特征向量v5和v6均为[0,0,0,1,1],使用三角距离计算后相似度为1,使用Cosine距离计算后相似度也为1.但实际上,t5和t6的评分分别来源于完全不同的用户u1,u2和u4,u5.使用新三角距离计算得到相似度为0,更加合理.
以表2展示的评分矩阵为例,使用新三角距离计算项目t1和t2相似度流程如下:
1) 提取项目t1和t2的特征向量v1=[0,2,0,1,0]和v2=[0,1,1,1,0].
2) 计算NT距离为
2.3 基于新三角距离的k近邻算法
将新三角距离应用到k近邻算法[19]中,预测用户对项目的评分.其计算公式[20]定义为
(8)

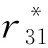
1) 分别提取项目t1,t3和t4的特征向量v1=[0,2,0,1,0],v3=[1,1,0,2,1]和v4=[1,2,0,1,1].
2) 使用新三角距离分别计算项目t1和t3,t4之间的相似度NTJ(v1,v3,t1,t3)=0.11,NTJ(v1,v4,t1,t4)=0.25.

2.4 算法描述
算法总结了NTRFC的具体步骤.步骤1读取并初始化评分数据; 步骤2根据式(2)至式(4)为每一个项目提取多通道特征向量; 步骤3初始化k个邻居,并计算与邻居的新三角距离,得到最远距离D; 步骤4至步骤10根据式(5)至式(7)计算与其余项目之间的新三角距离,并得到最终k个最近邻居; 步骤11根据式(8)计算预测评分.
算法NTRFC
输入:用户-项目评分矩阵R
step 1:初始化评分数据
step 2:根据式(2)至式(4)提取特征向量
step 3:初始化k个邻居,并计算新三角距离,得到最远距离D
step 4:for其余有评分的项目do
step 5:根据式(5)至式(7)计算新三角距离d
step 6:if (d step 7:用该项目替代最远距离项目 step 8:D=d step 9:end if step10:end for 算法时间复杂度分析如下:步骤1读取评分数据的时间为O(nm); 步骤2提取多通道特征向量的时间为O(nm); 步骤3初始化并计算与k个邻居的距离时间为O(kl); 步骤4至步骤10获得最近k个邻居的时间为O(ml); 步骤11预测评分的时间为O(k).故整个模型的时间复杂度为O(nm). 针对提出的算法进行两组对比实验,用来回答以下两个问题:1) 本文算法是否能提高推荐效率? 2) 本文提出的新三角距离能否保证较好的推荐准确度? 问题一中采用特征向量或原始评分矩阵作为输入,使用本文提出的NTJ距离与另外9种距离计算项目间的相似度,利用k近邻算法进行协同过滤推荐,比较两者的运行时间从而判断何种输入下的推荐效率更高. 问题二比较使用NTJ距离或其他9种距离的k近邻算法推荐准确度的高低. 本文使用Amazon,Movielens943u,Movielens706u (https://grouplens.org/datasets/movielens/100k/)和Eachmovie (http://www.research.digital.com/SRC/eachmovie/)数据集.表4给出了它们的基本信息,前3个数据集采用的评分等级是1~5分,Eachmovie数据集采用的评分等级是0.2~1分,0分表示用户没有给项目评分.在提取特征向量时,将Eachmovie数据集的评分等级扩展为1~5分,预测后按比例还原. 表4 数据集 通过两组实验Exp1和Exp2分别回答本节开始提出的两个问题. Exp1:比较输入分别为特征向量和原始评分矩阵的算法的运行时间.使用本文提出的NTJ距离与另外9种距离计算项目间的相似度,并将其应用于k近邻算法.记录不同输入下,使用同样距离公式的算法在4个数据集下的运行时间,运行时间越少,表示推荐效率越高. Exp2:在输入为特征向量时,分别采用本文提出的NTJ距离与另外9种距离进行推荐准确度对比实验. 在本文使用的k近邻算法中,设置两个参数LR和TR.LR表示用户是否喜欢某项目的门限值,设置为3.TR表示是否给用户推荐某项目的门限值,设置为3.5. 采用交叉验证的方式进行实验,首先将原始评分随机分为5等份,从中选取其中4份作为训练集,1份作为测试集; 其次,提取多通道特征向量,结合不同的距离预测评分; 最后,通过6个指标来衡量预测评分与真实评分的差距.上述步骤重复5次,每个指标下将得到5次不同的数据,将这些指标平均后做对比实验. 表5给出了6个准确度评价指标. 表5 评价指标 3.3.1 Exp1的结果 在4个数据集上,分别使用特征向量和原始评分作为输入,采用本文提出的NTJ距离和其余9种已有距离计算项目相似度的k近邻算法的运行时间结果,如图2,其中图2(d)在Eachmovie上的运行时间进行了对数处理. 以NTJ距离为例,对运行时间结果进行简要分析.在Amazon数据集上,采用特征向量作为输入使得运行时间下降了39.33%,如图2(a).在Movielens943u数据集上,采用特征向量作为输入使得运行时间下降了48.79%,如图2(b).在Movielens706u数据集上,采用特征向量作为输入使得运行时间下降了40.67%,如图2(c).在Eachmovie数据集上,采用特征向量作为输入使得运行时间下降了52.54%,如图2(d). 图2 4个数据集上的运行时间结果 综上所述,使用特征向量作为输入,能有效提高算法效率并大幅减少运行时间. 3.3.2 Exp2的结果 不同距离在4个数据集上的准确度结果如表6.每一个子表包括5次实验的平均结果、 标准差和平均性能排名,NTRFC为本文提出的算法,括号中的数字表示当前距离的性能排名.若平均结果相同,则比较标准差,标准差越小,性能越好. 在Amazon数据集上,本文提出的NTRFC算法在F1,Accuracy,Precision,MAE及RMSE评价指标上排名第一,如表6(a)所示.在Movielens943u数据集上,本文提出的NTRFC算法在F1,Accuracy,Precision及Recall评价指标上排名第一,如表6(b)所示.在Movielens706u数据集上,本文提出的NTRFC算法在F1,Precision及MAE评价指标上排名第一,如表6(c)所示.在Eachmovie数据集上,本文提出的NTRFC算法在F1,Accuracy及Recall评价指标上排名第一,如表6(d)所示.总体而言,在4个数据集上,NTRFC算法在个数准确度指标上占优. 表6 6个评价指标下的实验结果对比 续表6 综上所述,本文提出的NTRFC算法能有效提高算法效率节省时间,并保持较好的推荐准确度. 本文提出了基于多通道特征向量的新三角距离高效推荐算法.多通道特征向量能降低算法的时间复杂度,新三角距离能更精准地描述特征向量之间的相似度.在4个真实数据集上的实验结果表明,本文算法比已有算法在多个指标上表现得更好. 下一步工作拟替换Jaccard系数,使用其他距离公式与三角距离结合,构建新的距离公式.另外,考虑将新三角距离应用到可解释性推荐系统中,以期提升可解释性推荐系统的性能.3 实 验
3.1 数据集

3.2 实验设计

3.3 实验结果



4 结 论
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
中国惯性技术学报(2019年6期)2019-03-04 09:50:10
许昌学院学报(2018年4期)2018-05-02 12:27:37
数学物理学报(2017年5期)2017-11-23 07:51:31
中央民族大学学报(自然科学版)(2017年2期)2017-06-11 07:14:54
中华建设(2017年1期)2017-06-07 02:56:14
火控雷达技术(2016年3期)2016-02-06 02:30:28
