
基于注意力机制的双向生成对抗压缩网络
2021-10-21 08:19陈旭彪
电视技术 2021年8期
陈旭彪
(福建捷联电子有限公司,福建 福州 350300)
0 引 言
近几年,基于深度学习的图像超分辨率重建算法为了追逐重建图像客观质量评价指标,研究者们设计出大量精妙的网络结构[1-5],但这些网络结构大体上都是增加卷积神经网络的深度或宽度,从最初网络深度仅有3层的SRCNN,发展到首次引入残差网络达到20层深度的VDSR,再到80层的超深记忆性网MemNet[6]。尽管这些算法在一定程度上提升了图像的重建质量,却大幅度增加了网络模型消耗的内存容量及网络前向推理的计算量。另外一个问题是,如VDSR、SRResNet等算法,其网络结构采用了直接级联的拓扑结构,网络中每层输出的特征图会被不加区分地输入到下一层,无法判断图像特征的重要程度。
针对以上两个问题,本文在双向生成对抗压缩网络的基础上,提出了一种轻量高效的基于注意力机制的双向生成对抗压缩网络(ADSRGAN)。本文所提出的算法引入了深度可分离卷积层及混合注意力机制,在保证图像超分辨率重建质量的同时加快了网络模型重建速度。
1 双向生成对抗网络弱监督算法
本文的双向生成对抗网络旨在解决现实生活中模糊图像超分辨率重建问题。该算法框架如图1所示,包括两个生成对抗网络,分别为重建网络(Low-to-High)和下采样网络(High-to-Low)。

图1 双向对抗生成网络
1.1 下采样网络
图像超分辨率重建面临的最大问题是缺乏真实的数据集,即低分辨率的噪声图像和相应的高分辨率图像。生成用于训练的图像对的困难主要来自两方面,一方面是对低分辨率(LR)图像进行建模和仿真,另一方面是生成像素相对应的低分辨图像。为了解决这两个问题,本文提出了下采样网络(H2L),低分辨率图片产生的方式为:

式中:LR表示生成的低分辨率图片,HR表示清晰的高分辨率图片,θ1表示网络要学习的参数。
下采样网络的网络架构如图2所示。高分辨率图片首先经过一个卷积层和ReLU激活函数层提取图像低层特征,然后将提取的低层特征输入到后面8个残差块中。每个残差块包含两层卷积层和一层激活函数层,相比于SRGAN的残差块,本文设计的残差块遵循EDSR[7]去除了归一化层以减少网络参数量并加快网络训练速度。每两个残差块间的设计运用ResNet中的跳跃连接(Short-Cut)方式,同时将低层特征与残差块输出的高层特征进行融合操作,促使网络模拟生成更逼真的、带噪声的低分辨率图片。最后,融合的特征图经过卷积层和亚像素卷积层生成低分辨率图片。

图2 下采样网络
下采样网络的损失函数由两部分组成,分别为生成对抗网络的对抗损失及结构感知损失。下采样网络的生成器生成的低分辨率图片需要骗过判别器,因此产生了对抗损失函数。为了保证双向生成对抗网络训练的稳定性,本文引入了WGAN的对抗损失函数,其定义为:

式中:D表示下采样网络的判别器,G代表下采样网络的生成器,N代表了图像的数量。
为了保护生成的图像与原图像之间的空间结构信息不发生改变,本文引入了用于风格迁移工作的结构感知损失函数,其定义为:

式中:N代表了图像块的数量,P表示VGG网络的卷积层的特征图,y是生成的低分辨率图片,x是输入的高分辨率图片。在计算损失的时候,图片会被裁剪到同一尺寸。
1.2 重建网络
本文提出的重建网络(L2H)实现了低分辨率图像超分辨率,可以描述为:

式中:HR表示重建的超分辨率图片,LR表示输入的低分辨率图片,θ2表示重建网络要学习的参数。
重建网络的网络架构如图3所示,和下采样网络架构类似。低分辨率图片首先经过一个卷积层和ReLU激活函数层以提取图像的低层特征。低层特征经过20层残差块学习高分辨率图片的高频细节部分,最后将融合了低层和高层的特征图输入到亚像素卷积层进行图像超分辨重建。反卷积层利用亚像素卷积层替代经典的转置卷积,以避免重建图像出现棋盘效应和边缘模糊。

图3 重建网络
重建网络的损失函数由3部分组成,分别为生成网络的对抗损失、结构感知损失和L1像素损失组成。其中,对抗损失及结构感知损失与下采样一致。L1像素损失的定义为:
式中:N表示图像块数量,y表示重建的超分辨率图像,x表示真实的标签高分辨率图片。

2 深度可分离卷积和自注意力机制
2.1 深度可分离卷积
随着人工智能产品落地需求的产生,训练轻量高效的卷积神经网络逐渐成为研究者关注的焦点。轻量级神经网络模型的设计一般通过减少网络中参数数量、减少网络模型前向推理计算量等方法实现。2017年,针对减少网络模型计算量这一问题,Google公司的Sifre等人提出了轻量级小型化网络MobileNetV1[8],其最重要的创新就是提出了使用深度可分离卷积代替标准卷积操作,该算法在保证图像分类精度的同时大大减少了网络的计算量,并实现了将基于MobileNet网络的图像分类应用部署在移动平台端。
深度可分离卷积层把普通卷积拆分为深度卷积(Depthwise Convolution)与逐点卷积(Pointwise Convolution)两部分,它属于因式分解卷积的一类。传统卷积操作如图4所示。若输入图片是5×5像素大小且通道数为3的彩色图片,经过卷积核大小为3×3的传统卷积层(假设该层卷积层包含4个滤波器),最终将输出5×5×4大小的特征图。该普通卷积操作中包含的参数量为3×3×3×4,计算量为3×3×4×3×5×5。若传统卷积层将特征图为DH×DW×M作为输入,经传统卷积操作后其输出尺寸为DH×DW×N(假设卷积过程中添加了Same Padding,即输入输出宽高保持不变),其中DH表示输入特征图的高,DW表示的输入特征图的宽,M和N分别代表了输入通道数和输出通道数。最终可得出该传统卷积的参数量为DK×DK×M×N,DK代表卷积操作中卷积核的尺寸,总计算量为DK×DK×M×N×DH×DW。

图4 传统卷积示意图
深度卷积操作与传统卷积操作最大差异之处在于前者的一个卷积核只负责一个通道。具体来说,深度卷积一个通道与一个卷积核做运算,而传统卷积的每个卷积核都需要同时与每个通道做运算,深度卷积如图5所示。与传统卷积计算类似,深度卷积的参数量为DK×DK×M,计算量为DK×DK×M×DW×DH。从计算量及参数量对比可知,深度卷积操作比传统卷积更为高效,但经深度卷积操作后输出的特征图的数量与通道数的数量一致,且特征在卷积过程中无法组合不同通道的图像特征,因此需要逐点卷积来融合不同通道间 的信息。
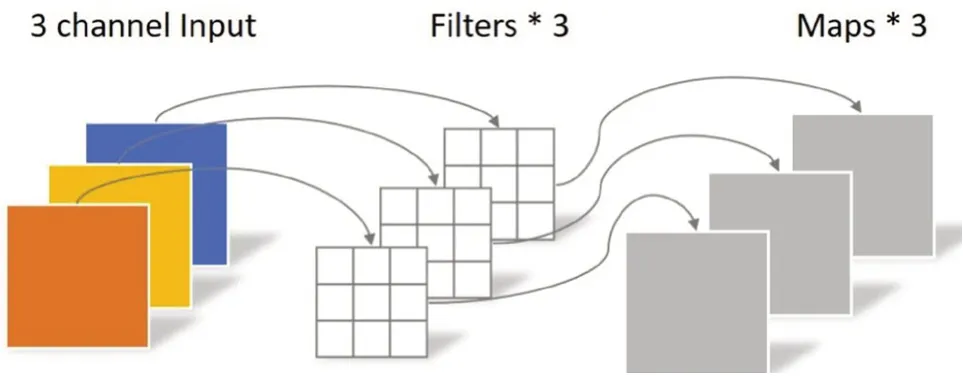
图5 深度卷积示例图
逐点卷积操作的原理与传统卷积原理是相同的,但是其卷积核的尺寸是固定的1×1×M大小,M代表上一层输出特征图的通道数。逐点卷积的实质是对上一步深度卷积产生的特征图进行深度上的加权融合,产生具有信息交融的特征图,其原理如图6所示。与传统卷积类似,逐点卷积的参数量为1×1×M×N,计算量为M×N×DH×DW。
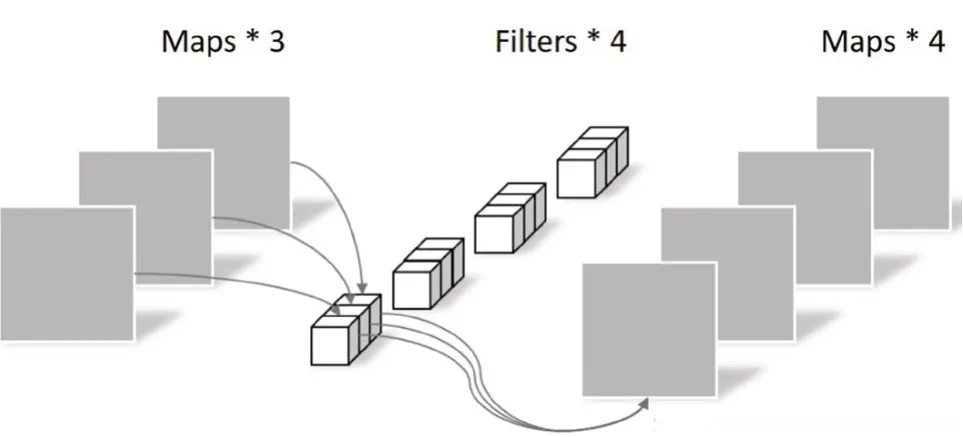
图6 逐点卷积示例图
综上所述,深度可分离卷积可分解为提取特征和组合特征两部分,相对于传统卷积而言,其计算量和参数量的对比为:

式中:N表示输出通道数,其数值一般很大,DK表示卷积核的尺寸。因此,如果卷积神经网络使用3×3大小的卷积核,深度可分离卷积操作可将网络的参数量及计算量减少到1/8至1/9,而相应的代价是网络的预测精度轻微下降。本文所提出的算法中,网络结构的卷积操作将利用深度可分离卷积操作代替。
2.2 自注意力机制
自注意力机制(Self-attention Mechanism)来源于人类感知神经学科。自注意力机制是指在人类感知视觉中,由于大脑处理信息的能力具有一定瓶颈,人脑会选择性地关注一部分重要的信息,忽略一些无关紧要的信息。自2014年Mnih等人将自注意力机制引入进计算机视觉领域获取目标任务效果提升,自注意力机制开始受到科研人员的广泛关注。2014年,Bahdanau[9]将自注意力机制与机器翻译相结合。图像超分辨率重建属于低层计算机视觉领域,其核心任务是恢复图像中的高频细节,而重建的高分辨率图像与低分辨率图像存在相似图案,因此可引入自注意力机制,将更多的精力用于恢复丢失的高频细节,使重建图像更符合人眼视觉效果。本文将引入自注意力机制,与双向生成对抗网络 相结合。
在图像处理领域中,常用的注意力机制包括硬(Hard)注意力机制及软(Soft)注意力机制。硬注意力机制(Hard Attention)通常只选择对目标任务最重要的某些特征,将其他未被选择的特征忽略。硬注意力机制在一定程度上对减少网络计算量有益,但更大的劣势是原图像中的部分信息将丢失。在图像超分辨率重建中,低分辨率图像中的所有像素对重建图像都是有影响的。因此,硬注意力机制在图像超分辨率重建任务中并不适用。软注意力机制(Soft Attention)相对于硬注意机制而言,采用了根据图像特征的重要性来分配权重的方式。软注意力机制考虑到所有的图像特征,符合图像超分辨率重建任务的原始出发点,因此本文将软注意力机制与双向对抗生成网络结合。
软注意力机制在计算机视觉应用领域中又分为通道注意力机制及位置注意力机制,本文使用的是通道注意力机制。在深度学习训练过程中,训练集中的输入图像通过若干层卷积神经网络,最终将得到多张不同的特征图(Feature Map)。通道注意力机制主要关注的是不同通道之间的关联性。具体来说,通道注意力机制会赋予每张特征图不同的权重,其原理如图7所示。输入特征图首先需改变特征维度,其次经过全局平均池化层获取单个通道C的初始权重。两层全连接层分别对通道进行下采样和上采样操作以提升网络学习通道特征的能力,同时Sigmoid激活函数将通道权重归一化得到通道注意力特征图,最后将通道注意力特征图与输入特征图加权相乘。

图7 通道注意力机制
3 基于注意力机制的双向生成对抗压缩网络(ADSRGAN)模型结构
本文提出的基于注意力机制的双向生成对抗压缩网络(ADSRGAN)在双向对抗生成网络模型引入了深度可分离卷积层和混合注意力机制。
(1)利用深度可分离卷积层代替普通卷积层。将重建网络及下采样网络中的普通卷积层替换成深度可分离残差层,深度可分离残差模块如图8 所示。
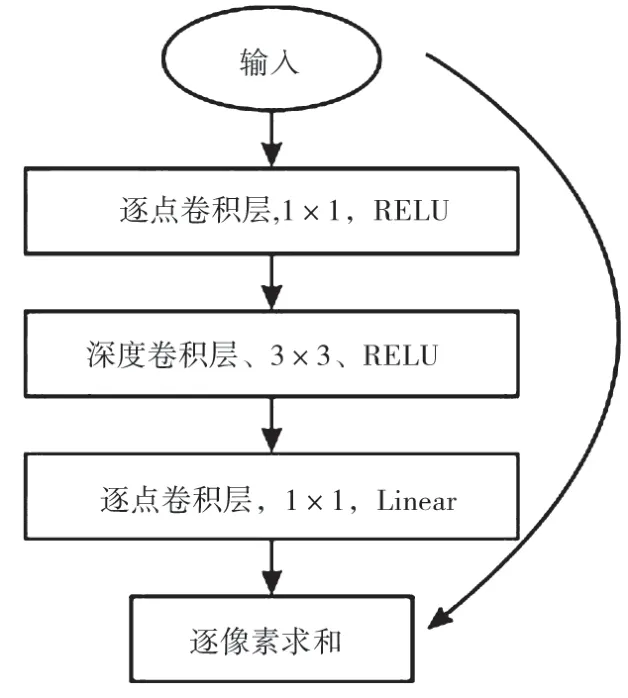
图8 深度可分离残差模块
(2)引入混合注意力机制。为了不增加重建网络的参数量,本文算法仅在下采样网络的残差块中引入通道注意力模块,并在下采样网络的降采样层引入位置自注意力模块,促使生成的低分辨率图片更贴近于现实生活。引入混合注意力的下采样网络结构如图9所示。

图9 引入混合注意力的下采样网络结构
4 实验结果及分析
为了验证本文提出的基于注意力机制的双向生成对抗压缩网络算法(ADSRGAN)的有效性,将本文算法的重建模型与其他基于卷积神经网络的单幅图像超分辨率重建方法进行比较。这些方法是专门为基于双三次插值退化的超分辨率设计的,比如SRCNN、SRGAN、ESGANG等。
本文提出的ADSRGAN算法与其他算法在测试集Urban100上基于i7 8700 CPU的重建速度对比结果如表1所示。由表1可知,本文提出的算法重建效率比SRGAN提升近5倍。

表1 本文方法与其他重建算法时间对比
本文提出的ADSRGAN算法与其他算法在测试集Urban100、DIV2K及数据集RMSR上的峰值信噪比(Peak Signal to Noise Ratio,PSNR)对比结果如表2所示。所有算法在测试集Urban100、DIV2K上的测试过程为:首先对测试集中全部图像运用双三次插值方法进行4倍的下采样,其次将下采样得到的低分辨率图像输入进不同的重建模型中得出重建结果。在Urban100、DIV2K数据集上,本文的ADSRGAN算法相对于ESRGAN算法,PSNR值分别提升了0.05 dB、0.06 dB,在真实生活数据集RMSR上,本文算法的PSNR值相比于其他算法平均提升了1.51 dB。由实验数据定量分析可知,本文设计的压缩算法比双向生成对抗网络算法精度略微下降一点,仍优于其他基于生成对抗网络的超分辨率重建算法。

表2 不同重建算法在不同数据集上的PSNR结果对比(单位:dB)
本文提出的ADSRGAN算法与其他算法在测试集Urban、DIV2K及数据集RMSR上的结构相似性(Structural Similarity,SSIM)对比结果如表3所示。在Urban100数据集上,ADSRGAN算法相对于ESRGAN算法平均SSIM值提升了0.009 5;在DIV2K测试集上,平均SSIM值提升了0.021;在RMSR测试集上,平均SSIM值提升了0.012。由实验数据定量分析可知,本文设计的压缩算法比双向生成对抗网络算法精度略微下降一点,但仍优于其他基于生成对抗网络的超分辨率重建算法。
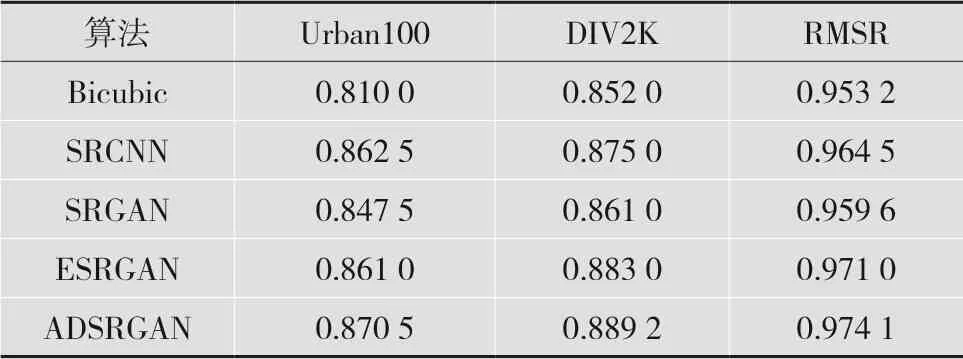
表3 本文方法与其他重建算法的SSIM
基于测试集Urban100、DIV2K上的图片,分别对各种深度学习模型进行超分辨率重建的结果对比如图10和图11所示。从重建图像的对比结果可看出,双三次插值算法的重建效果最模糊,SRGAN算法会产生伪影,ESRGAN算法在边缘部分也会有一些较少的伪影部分出现。本文的ADSRGAN算法重建的图像细节清晰,边缘明显,与原图最为相近。

图10 本文算法与其他算法在Urban100测试集上的对比

图11 本文算法与其他方法在DIV2K测试集上的对比
图12 为Real-World数据集中的禁止抽烟测试图像,通过对比各模型超分辨率重建结果图可以看出,本文提出的算法在人眼感知视觉的效果最好,边界明显、细节清晰,与原始高分辨率图像最相近。

图12 现实世界图像的重建结果对比
综上所述,本文提出的基于注意力机制的双向对抗生成压缩网络重建算法可处理现实世界模糊、低分辨率图像并重建出视觉良好、细节丰富的高分辨率图片,同时,本文设计的压缩网络在i7 8700 CPU上对Urban100测试集中的图像放大4倍时,重建速度比SRGAN算法提升了约5倍。
5 结 语
本文介绍了注意力机制及深度可分离卷积的基本概念及主要特性。由于注意力机制在自然语言处理领域方向的成功应用,本文基于注意力机制提出了混合注意力模块与可减少参数的深度可分离卷积层相结合的双向生成对抗压缩网络。在实验部分,与SRGAN方法和ESRGAN方法进行比较,实验结果表明,本文提出的方法能够有效地提高图像重建质量及重建速度。
猜你喜欢
红外技术(2022年11期)2022-11-25
小雪花·成长指南(2022年1期)2022-04-09
计算机应用(2020年7期)2020-08-06
数学物理学报(2019年3期)2019-07-23
家庭影院技术(2018年9期)2018-11-02
艺术科技(2018年2期)2018-07-23
传媒评论(2017年3期)2017-06-13
自动化学报(2017年5期)2017-05-14
成都信息工程大学学报(2017年6期)2017-03-16
第二课堂(课外活动版)(2016年2期)2016-10-21
