
基于卷积神经网络的时间序列数据融合算法
2021-10-21 01:32孙淑娥
西安石油大学学报(自然科学版) 2021年5期
孙淑娥,姚 柳,赵 怡
(1.西安石油大学 理学院,陕西 西安 710065; 2.西安热工研究院有限公司,陕西 西安 710054; 3.西安电子科技大学 数学与统计学院,陕西 西安 710126)
引 言
数据融合技术目的是通过多源信息来获取更简单、准确的判断,即通过融合多个传感器捕获的实时数据与相关数据库中的信息以获取更准确的数据。目前,该技术已被应用于多个领域,如人脸识别[1]、疾病诊断[2]、目标跟踪[3]等。在现实生活中,很多数据都属于时间序列数据。然而时间序列数据[4]除了具有数据量大、维度高、特征多、高噪声等特性,还有一个非常重要的特征,即数据的连续性,这些连续数据通常被看作是一个整体而非独立的个体。当前,时间序列数据融合面临着两大难题:一是原始数据去噪。由传感器捕获的数据通常存在大量的环境噪音和设备噪音,而这些噪音会增加特征提取的难度,因此数据去噪是数据融合中的核心步骤之一。传统去噪算法主要有小波阈值去噪、经验模式分解(EMD)等。由于多源时序数据具有数据量大、结构复杂等特点,以致这些方法难以获得稳定的结果。二是从多源传感器中提取序列数据的时间连续性特征。现有的特征提取方法主要有主成分分析法、线性判别分析,但其难以提取到时序数据的连续特征。
目前,基于神经网络的时间序列数据融合算法有:层叠自动编码器[5]、径向基函数(RBF)神经网络、BP神经网络[5-6]、深度神经网络(DNN)[7]、卷积神经网络(CNN)[8]。文献[7]研究表明DNN网络本身就是一个融合结构,通过网络层之间的连接实现原始数据的特征提取以及逐层融合。然而,DNN用于数据融合时,一方面复杂特征提取能力不高,另一方面忽略了序列数据的时间联系性。文献[8]研究表明,一维卷积神经网络可以有效的提取时序数据的时间联系性特征。其中,JING等人[8]提出了深度卷积神经网络(DCNN)结构。在DCNN网络中,卷积层进行特征提取,堆叠的卷积层和池化层结构使得信息再次融合并构建更复杂的特征,使得融合准确性有了较大的提升。但DCNN网络忽略了数据噪声的影响,导致融合准确度不高。文献[9-10]研究表明,降噪编码器(DAE)在原始数据的去噪重建方面效果显著。数据原始特征对于深度学习网络模型学习能力具有极大的影响,而降噪编码器(DAE)的引入在一定程度去噪重建了原始数据的特征;注意力机制(attention)模型已广泛应用于机器翻译、文本分类,推荐系统等领域。大量的研究[10-11]表明注意力机制模型在处理时序数据长距离信息捕获方面是有效的。因此,本文结合DAE与attention模型提出一种基于卷积神经网络的数据融合算法,即DAECNN_attention。
1 相关算法介绍
1.1 降噪自编码器
降噪自编码器(DAE)[12]是一种人工神经网络的方法,能够对抗原始数据污染、缺失等情况。其通过对原始数据添加高斯白噪声进行编码与解码并使用无监督学习的方法来训练网络,以实现真实数据的复原,从而增强数据的鲁棒性。DAE网络使用梯度下降法最小化代价函数:
(1)
来获得一组参数(W,c)=((W1,c1),(W2,c2)),其中隐藏层为
(2)
输出层为
y=δ(hW2+c2)。
(3)
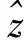
1.2 一维卷积神经网络
一维卷积神经网络[8-13]的结构如图1所示。主要结构由输入层、卷积层、池化层、全连接层、输出层组成。卷积层用以提取数据的抽象特征,池化层用以获取关键信息并降低维度,全连接层用以综合主要信息。用以聚合关键信息并降低维度,全连接层用以综合主要信息。
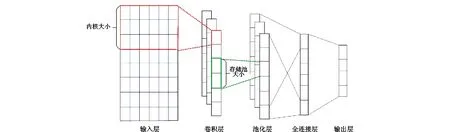
图1 一维卷积神经网络结构Fig.1 Structure of one-dimensional convolutional neural network
在卷积层上,每个卷积核向下滑动执行卷积操作。卷积层通过卷积计算提取数据特征,通过多个卷积层结构来获得更多复杂的抽象特征。并且每个卷积层的卷积核是权值共享的,在很大程度上减小了神经网络的运算复杂度。卷积计算过程式:
(4)
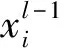
在池化层中,通过池化方法提取出特征图中的关键点并减小参数维度。池化方法主要分为平均池化和最大池化:平均池化即将池化窗中数据的平均值作为输出,最大池化即将池化窗中的最大数据作为输出。通过池化操作进行二次采样形成新的特征图。采样公式为:
(5)
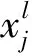
在全连接层中,可以将特征图转换为一维向量的形式,从而有效的增强原始信号的特性,减小数据的维数,保存主要信息;并且全连接层深度的增加可以有效的提高模型的非线性表达能力。同时采用dropout正则化方法,用以防止过拟合。输出层采用softmax函数进行最终的决策(根据需要解决的不同问题输出层可进行调整),输出层有q个可能的结果,则softmax函数的输出为:
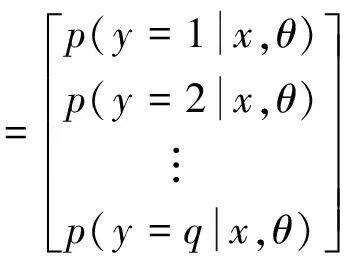
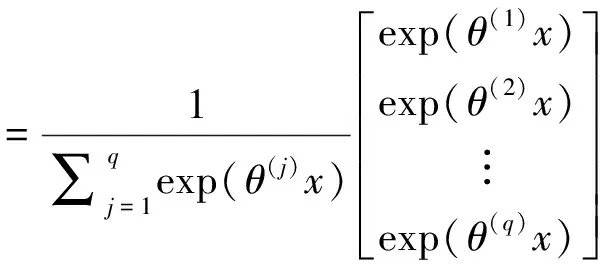
(6)
其中,x为softmax函数相邻全连接层的输出结果。
Adam算法具备AdaGrad算法及RMSProp的优势,在实践中能适应不同的问题,故本文采用Adam优化算法来训练网络。网络训练方式采用小批量训练,并使用交叉熵损失函数。损失函数式为:
(7)
其中,B,Y,y_分别为最小批量的大小,真实值和预测值。
1.3 注意力机制
ROY等[10]给出注意力机制模型的一般框架,如图2所示。该模型思想来源于人类在观察事物时注意力分布的不同,其数学本质即为加权求和。注意力机制模型首先使用点积作为相似度函数来获得序列的权重值,其次利用softmax函数将权重归一化;最后将归一化的权重矩阵与序列矩阵相乘。计算式为:
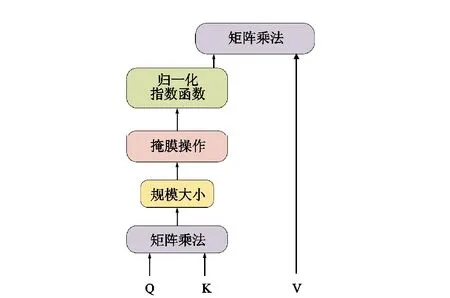
图2 注意力机制Fig.2 Attention mechanism
(8)
其中Q∈Rn×dk,K∈Rm×dk,V∈Rm×dv,Q为查询(query),表示目标序列值;K,V分别为键(key)、值(value),是一组键值对,表示序列中间状态的键值对;通过计算Q、K的相似度,获得权重矩阵;dk为比例因子;当Q=K=V时即为自注意力机制,用以获得序列内部的全局信息。
2 DAECNN_attention网络模型
2.1 DAECNN_attention模型框架
DAECNN_attention模型主要由两部分组成:一是采用降噪编码器(DAE)对原始数据进行去噪重建处理,用以获得更具有鲁棒性的数据;二是在DCNN[8]基础上增加自注意力机制模块(记为CNN_attention),用以捕获时序数据的长距离依赖性。数据的原始特征对于深度学习网络的性能有极大的影响,而降噪编码器在数据去噪复原方面具有良好的表现。因此,本文首先通过DAE网络对原始数据进行去噪重建处理,用以获得具有鲁棒性的数据;然后将经过DAE处理的多传感器数据送入CNN_attention模型中。在CNN_attention模型中通过一维卷积操作来提取时序数据的局部特征,进而通过池化层进行关键信息的提取。然而卷积核只能提取到局部信息,难以获得长距离信息。故本文引入自注意力机制模型,用以弥补其捕获序列的长短距离依赖性的不足(其原理如2.3节所述)。因此本文结合DAE以及带有注意力机制模块的DCNN网络提出一种新的DAECNN_attention算法。DAECNN_attention其结构如图3所示:
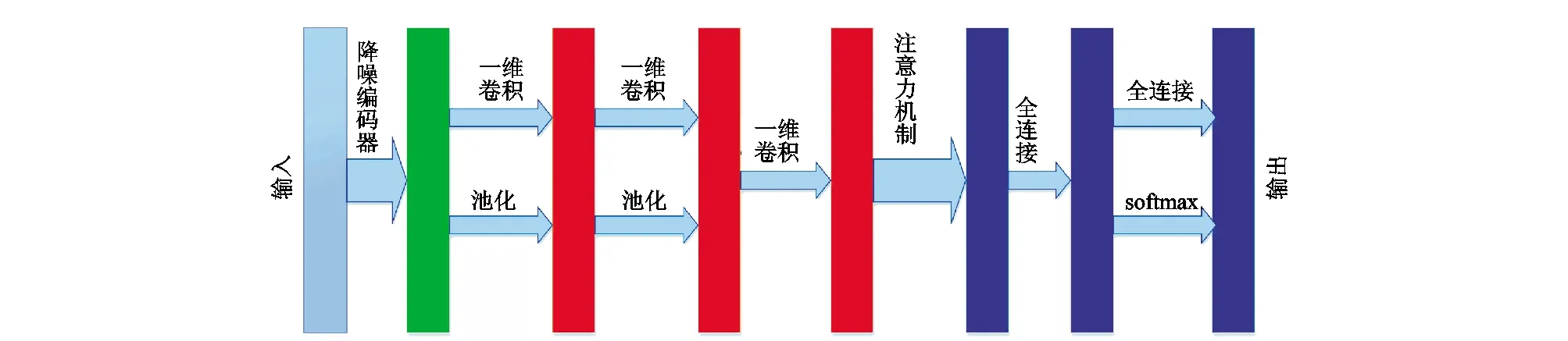
图3 自注意力降噪编码模型结构Fig.3 Structure of DAECNN_attention model
2.2 DAECNN_attention模型参数设置
DAECNN_attention算法包含DAE模型和CNN_attention模型。DAE模型包括:输入层、隐藏层、输出层,具体参数设置见表1,其中,n表示该层的神经元个数。

表1 降噪编码模型结构及变量参数Tab.1 Structure and variable parameters of DAE model
CNN_attention模型由3个卷积层、2个池化层、1个注意力机制模块、1个全连接层以及1个带有softmax回归的全连接层。CNN_attention结构参数见表2。
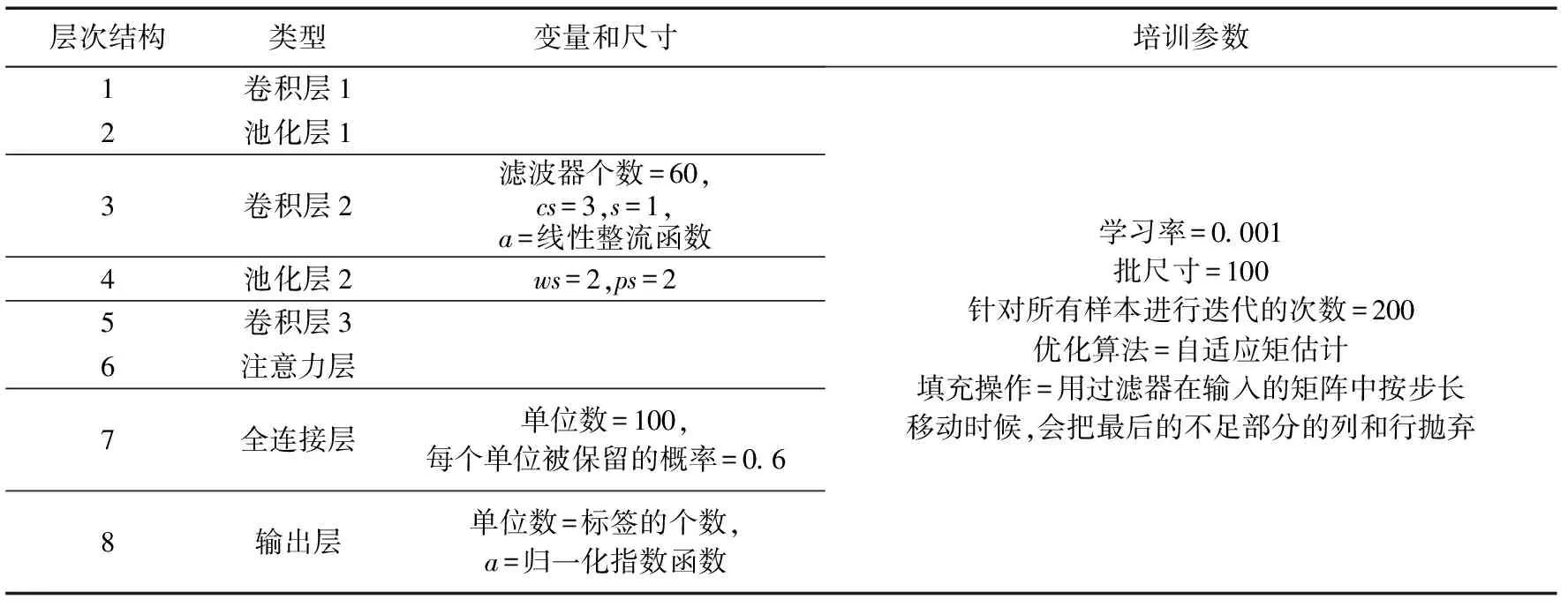
表2 自注意力降噪编码模型结构及参数设置Tab.2 Structure and variable parameters of CNN_attention model
化操作的步长;a表示激活函数;num_labels表示标签类别数。
3 试验结果与分析
本文采用UCI数据集AReM2016和HAR Dataset进行试验,通过与经典算法DCNN、BPNN各项指标进行对比,以验证DAECNN_attention算法的性能。使用准确率(ACC)[14]、精确率(P)[14]、召回率(R)[14]、F1分数(F1)[14]度量DAECNN_attention算法的性能,其中ACC、P、R、F1的取值范围均为[0,1],指标越大,表明融合性能越好。
ACC、P、R、F1计算式分别为:
(9)
(10)
(11)
(12)
其中,TP,TN,FP,FN分别为正阳性、正阴性、假阳性、假阴性。
ACC、P、R、F1是机器学习中常用的评价指标,其中ACC表示正确分类的个数占总体测试样本的比例,但在样本不均衡时无法判断模型的好坏;P表示预测为正例的测试样本中预测正确的比例;R表示预测正确的样本中正例所占比例;F1为P和R的调和均值,用以兼顾精确率和召回率。
3.1 数据集
本文使用的数据来源于UCI数据AReM2016[15]和HAR Dataset[16]。其中,AReM2016包含执行人类活动时志愿者所佩戴的无线传感器获得的时间序列数据。试验中使用的数据包含五种动作类别的数据:骑、卧、坐、站、走;每种类别的动作包含15组采样数据,每组数据包含480个采样点;数据的采样标准为:采样频率为20 Hz,每个动作的持续时间为120 s;每个采样点包含6个属性,相当于6个传感器测量的结果。融合值等于活动动作的标签值见表3。

表3 人类活动识别数据融合标签值Tab.3 AReM2016 label value
AReM2016首先通过DAE模型进行归一化和去噪重建处理;其次在75%重叠的固定宽度滑动窗口(60个读数/窗口)中进行重采样;通过这个方式获得的样本格式为60×6,试验数据样本总量为2 100个;样本的80%作为训练集,20%作为测试集;并在训练之前将训练集中不同类别的数据按组打乱顺序,用以提高网络的收敛速度;最后送入CNN_attention网络中。
HAR Dataset由30名志愿者佩戴智能手机执行6个基本活动:站立、坐、平躺、走路、下楼、上楼,试验数据的采样标准为:采样频率50Hz,采样方式为固定窗口采样,其中每个窗口的采样时间为2.56 s,并且相邻窗口具有50%重叠。本文试验数据主要包括:加速度信号total_acc、加速度减去重力获得的body_acc以及角速度信号gyro_acc的X轴、Y轴和Z轴数据,相当于9个传感器测量的结果。标签值描述见表4。
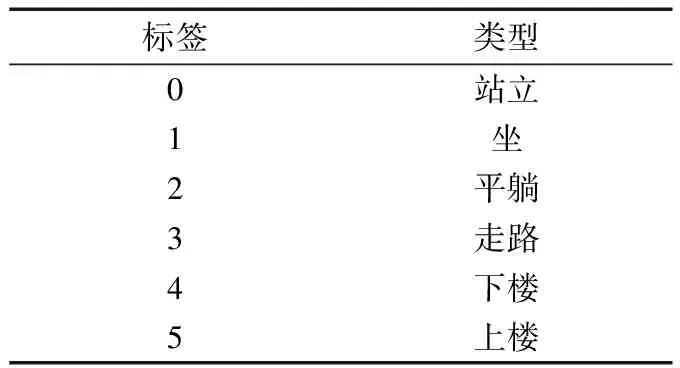
表4 归一化去噪重建数据标签值Tab.4 HAR Dataset label value
HAR Dataset首先通过DAE模型进行归一化和去噪重建处理;样本形式为128×9,训练样本数为7 352,测试样本数为2 947;最后送入CNN_attention网络中。
3.2 试验结果
本文分别测试了DAECNN_attention、DCNN和BPNN算法在AReM2016和HAR Dataset数据集上的融合性能,试验的最终结果为5次测试均值,如表5所示。
表5为DAECNN_attention、DCNN和BPNN算法在UCI数据集AReM2016以及HAR Dataset的实验结果。从表5可以看出,在2个数据集上DAECNN_attention算法的融合准确度指标均高于DCNN和BPNN算法;尤其是在AReM2016数据集,DAECNN_attention算法的融合准确度指标ACC、P、R、F1分别为99.52%、99.53%、99.52%和99.52%,远高于DCNN算法和BPNN算法。原因在于数据原始特征对于深度学习网络模型学习能力具有极大的影响,而DAE模型的引入在一定程度去噪重建了原始数据的特征;并且自注意力机制模块的引入,提高了网络捕获长距离信息的性能。但在HAR Dataset数据集中DAECNN_attention算法的融合性能略高于DCNN算法,原因可能在于HAR Dataset数据集是经过噪声滤波器预先处理的。
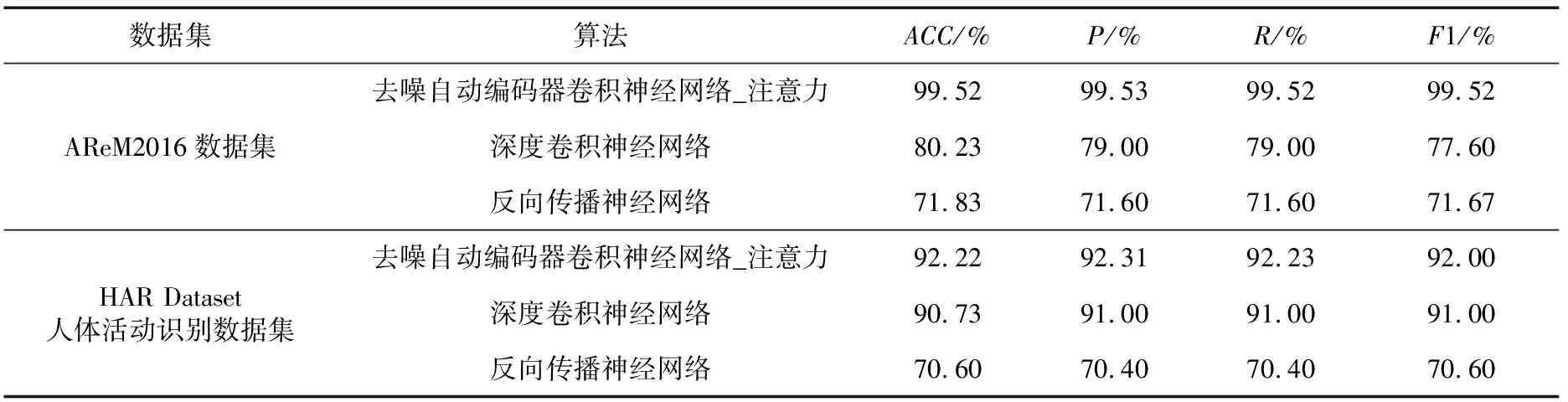
表5 对比算法的平均测试精度Tab.5 Contrast of average test accuracy of algorithms
3.3 PCA可视化分析
为了更直观地说明DAECNN_attention算法的融合性能,将DAECNN_attention、DCNN以及BPNN算法倒数第二层的输出作为融合的特征向量;首先使用主成分分析法(PCA)将原始的实验数据、DAECNN_attention、DCNN和BPNN算法融合的特征向量映射为二维特征,对应于图3和图4中的X1和X2坐标;其次利用得到的二维特征进行最终的决策,标签分别对应于表3和表4,从而可以在二维平面更好地展示算法的性能。可视化结果如图4和图5所示。
从图4和图5可以直观看出,原始数据、DCNN、BPNN的重叠度较高,而经过DAECNN_attention算法融合得出的特征向量能更好区分目标的类别。
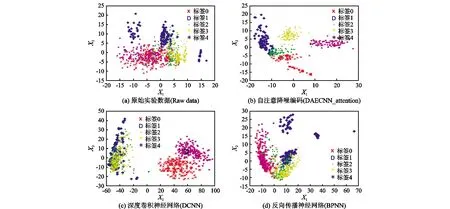
图4 识别数据融合的主成分分析的可视化结果Fig.4 Visualization results of AReM2016 dataset PCA
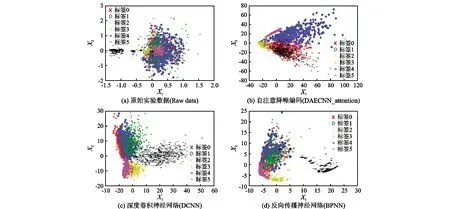
图5 归一化去噪重建的主成分分析数据可视化结果Fig.5 Visualization results of HAR dataset PCA
4 结 语
提出了一种结合降噪编码器和注意力机制模型的DAECNN_attention算法,DAE网络对原始数据进行预处理以及复原,以增强特征的鲁棒性;自注意力机制模块的引入,在一定程度上提高了捕获时序数据长距离时间相关性的能力。试验结果表明,DAECNN_attention算法具有良好的性能。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
物联网技术(2020年12期)2021-01-27
电子制作(2019年11期)2019-07-04
科技创新与应用(2017年17期)2017-06-16
第二课堂(课外活动版)(2016年2期)2016-10-21
教学月刊·中学版(教学参考)(2016年5期)2016-06-14
中学英语之友·高一版(2008年10期)2008-12-11
