
面向云数据中心的成本感知容错算法
2021-10-21 01:32:20宋彩利
西安石油大学学报(自然科学版) 2021年5期
宋彩利,梁 斌,李 皎
(西安石油大学 计算机学院,陕西 西安 710065)
引 言
云服务的最终目的是使云用户可以稳定、快捷和方便地使用弹性的计算和存储服务。因此,提高云数据中心的稳定性不仅可以提升用户的使用体验,更能增加云服务提供商收益。然而,大型云数据中心都是由低性能的物理机构成,通过虚拟化技术将其以虚拟机的形式租用给云用户,这样就会由于机器性能不稳定而导致虚拟机故障。现代云数据中心为了提升云服务的稳定性和可靠性,通常在建立虚拟机时会设计合理的容错机制从而保证云任务顺利执行。但是,随着云数据中心规模不断扩大,大量的故障和容错问题已经成为制约云数据中心进一步发展的瓶颈之一。
云数据中心针对虚拟机故障的容错策略主要可以分为副本复制和重调度。副本复制一般开始于云任务映射初始阶段。当云数据中心的调度系统在进行云任务映射时,为了避免虚拟机故障,会激活一些冗余的虚拟机对部分云任务进行多次映射。其通过增加副本数量的方法,提升了云任务顺利完成的概率。这种方法虽然简单方便,但是也存在很多隐患。首先,由于虚拟机的故障是一个随机事件,调度系统并不能预测故障的发生,从而导致命中故障的几率较低。其次,冗余的虚拟机会带来云服务提供商成本的上升从而降低其收益。最后,副本数量的选择也是一个复杂的问题,设计人员需要综合统计学和半导体等多学科知识综合进行考虑,因此它的复杂度带来的损失将远大于问题自身的收益。重调度策略根据虚拟机的执行情况进行动态的调节,当执行云任务的虚拟机发生故障时,该调度系统会为失效云任务重新选择虚拟机进行映射。
之前的学者对云数据中心的调度和重调度算法进行了部分的研究。Yao等[1]提出了一种免疫机制,针对云系统(IRW)中的工作流提出了一种重新调度算法。有4个单位可以模仿IRW算法中的免疫系统。监视单元监视资源池中每个虚拟机的可能故障。一旦检测到资源故障,就会触发响应单元进行搜索存储单元或学习单元中的适当策略,用于重新安排可用时间资源。如果没有可用的虚拟机都能满足服务质量,则将为该云任务创建新的虚拟机。Liang等[2]提出基于内存利用率的云任务调度算法从而提高物理机综合利用率并降低云数据中心能耗。Topcuoglu等[3]针对有限数量的异构处理器提出了两种新颖的调度算法,目的是同时满足高性能和快速调度时间要求,分别称为异构最早完成时间(HEFT)算法和关键路径-处理器(CPOP)算法。Chen等[4]考虑了互联网托管中同质资源的能源效率管理问题,其主要挑战是确定资源需求使得每个应用程序在其当前请求负载级别并以最有效的方式分配资源,这样可以根据可用预算和当前用户的服务需求进行协商,即平衡资源使用成本以及收益。Raghavendra等[5]通过组合和管理数据中心环境协调5种不同的电力管理政策,从控制理论的角度探讨了问题并应用了一个反馈控制循环以协调控制器的动作。基于LP的无变化VM放置算法可以以最低的能耗生成VM放置。另一方面,该方法的可行性驱动随机VM放置(FDSP)算法与基于LP的算法无缝配合,以实现理想的放置可行性。王鹏等[6]实现了云计算集群相空间投影在不同负载请求情况下平稳的点状聚集。通过仿真实验利用相空间负载均衡度、广义温度、广义熵等参数和集群的相空间投影。Dodonov等[7]提出了一种基于预测的方法用于网格中调度分布式应用程序。文献中提议,迁移如果较低,则传达流程预期通信的成本与最小化总执行时间目标,并证明了这一点可以有效地应用于网格。但是由于虚拟机迁移成本较高,因此无法真正应用于虚拟化数据中心。Plankensteiner等[8]提出了一种新的启发式方法,称为“重新提交影响”,以支持科学流程中的容错执行异构并行和分布式计算环境。与相关方法相比,该方法可以有效地使用在新的或不熟悉的环境中,即使没有历史执行或故障跟踪模型。Moghaddam等[9]提出的虚拟机整合算法在每个阶段都包含不同的模型。在第一阶段,为各个VM开发了不同的微调机器学习(ML)预测模型,以预测触发主机迁移的最佳时间。对于第二阶段,从字典的角度来考虑选择虚拟机进行迁移时的迁移时间和主机CPU使用率。最后,开发了一种基于最佳适合递减(BFD)算法的新方法,为要迁移的VM选择目标主机。与基准VM整合算法进行了比较,该算法使用本地回归来检测过度利用的主机,VM选择阶段所需的迁移时间最短,并且Power-Aware最适合主机选择阶段。最终,该算法大幅降低了云数据中心能耗。Fei和Hadji等[10-11]为了增强系统利用率的性能测量而介绍了基于阈值的负载均衡概念,负载分配和负载均衡策略一起可以减少总执行时间并增加系统吞吐量,并且讨论了能耗和负载矩阵以保持定时更新。但是全局最优解决方案会产生许多不必要的迁移,无法工作在大规模的云计算环境中。Khandelwal等[12]旨在提出回归随机森林模型,以预测提前一周和提前一天的现货价格。该预测将帮助云用户提前计划何时购买竞价型实例,并且还帮助他们进行投标决策以最小化执行成本和超标失败概率。Sharma等[13]针对数据中心的热效资源管理进行了大量的研究工作,研究表明软件驱动的热管理和温度感知工作负载的放置带来了额外的节能。然而,虚拟化数据中心背景下的热管理问题尚未进行调查,且没有研究根据当前资源利用率通过热量和网络优化虚拟化数据中心综合优化的方法进行虚拟机放置。Chen等[14]提出了一种动态任务重排和重新调度算法,从任务之间的优先级约束中利用调度灵活性。算法可以优化多个工作流之间的资源分配,并且通常会停止延迟执行对后续任务的影响。
这些算法虽然解决了部分技术问题。但是它们都未考虑以下几个方面。首先,云数据中心也会提供包含不同频率CPU的虚拟机供云用户选择,在进行失效云任务的重调度时,系统可以根据它的截止时间选择高频率CPU的虚拟机进行映射从而节约成本。其次,由于之前的研究中对部分云任务进行放弃,这就意味着最终无法向云用户交付结果。这样不仅会带来收益的降低,更重要的是服务品牌和企业形象的损失。延迟的交付虽然会降低云用户再次购买云服务的几率但是至少保证了企业的基本信誉。因此即使会产生较大的代价,云服务提供商也应该尽可能地完成所有的云任务。最后,延迟交付的赔偿也决定了云服务提供商的最终收益,重调度策略必须根据赔偿比率进行合理的设计使得收益最大化。
基于以上原因,提出了面向云数据中心的成本感知容错算法(Cost-aware Fault-tolerant Algorithm for Cloud Data Centers,CAFT)。该调度策略通过提高云任务的故障修复率从而降低云服务提供商的损失。
1 云数据中心重调度模型及定义
1.1 云数据中心整体架构
首先介绍云数据中心的整体架构。研究的云数据中心通过虚拟化技术向云用户提供服务。该云数据中心包含了虚拟机集合VM={vm1,vm2,…,vmn},其中n代表了该云数据中心所能提供的虚拟机总数。每个虚拟机可以表示为vmi={ci,mi,si,pi,ni,ti,ei},其中ci,mi,si,pi,ni,ti,ei分别代表每台虚拟机包含的CPU核数量、内存大小(单位:GB)、CPU核的处理速度(单位为MIPS)、CPU核的使用价格(单位为$/h,低频=price_low,高频=price_high)、该虚拟机上所运行的云任务编号、虚拟机的运行时间(单位为秒)及虚拟机的状态(1:正常,2:故障和3:副本)。云用户所提交的云任务也可以表示为一个云任务集合CT={ct1,ct2,…,ctm},其中m代表这个集合中云任务的个数。通过调度算法依次将该集合中的云任务映射到相应的虚拟机上执行,每个云任务都可以描述为ctj={lj,mj,dj,tj,pj,fj}的形式,其中lj,mj,dj,tj,pj,fj分别代表该云任务的长度(单位为百万指令集)、需要的内存大小(单位:GB)、该云任务的截止时间(单位:s)、该云任务的实际需要时间(单位:s)、完成该云任务的收益(单位:$)及故障所付出的代价(单位:$)。
云任务i的实际需要时间计算方法如下:
ct.tj=ct.lj/((f/1000)×vm.ci×0.9)
(1)
其中f为虚拟机的CPU频率。云数据中心由于其虚拟机性能的波动,一般都会有10%的冗余。因此,提供给云用户的截止时间为实际需要时间的1.1倍[15]。云任务i的截止时间计算方法如下:
ct.dj=1.1ct.tj
(2)
1.2 云任务的初始化映射
云用户需要租用云数据中心的虚拟机完成自己所提交的云任务,成熟的云数据中心都提供标准规格的虚拟机让用户选择。例如Amazon的美国东部(俄亥俄)数据中心所提供的常规虚拟机包含4个系列,表1所示的参数为每个系列的最低型号。例如m5a.large(Low-frequency Universal)为该系列虚拟机的最低配置,它的CPU核数量和内存大小固定为1∶4。而对于计算型云任务通常需要较大CPU的虚拟机,则可以选择m5a.large(Low-frequency Computational)低频计算型虚拟机,它的CPU数量和内存大小固定为1∶2。同时,该云数据中心还提供了高频的虚拟机系列m5a.large(High-frequency Universal)和m5n.large(High-frequency Computational),这两种系列虚拟机的配置与低频的配置相比只是频率不同。同时,云计算中心还提供了这4种虚拟机对应的同比例扩大后的虚拟机。m5a.large(Low-frequency Universal)扩大一倍后的虚拟机为m5a.xlarge(Low-frequency Universal),m5a.24xlarge(Low-frequency Universal)为该系列配置最大的虚拟机。它的CPU核数量、内存大小都扩大了24倍,当然其租用价格也会根据配置同比例上升。

表1 虚拟机价格(Amazon的美国东部(俄亥俄)数据中心)Tab.1 Price of virtual machines (Amazon's East (Ohio) data center)
假设云用户提交了一个云任务的集合,云数据中心需要对它们进行映射。只分析其中的前3个云任务,它们的参数见表2。首先,为了满足云任务的内存需求且使得费用最低,一般都会选择满足内存需求的最小规模虚拟机。假设初始映射时都选择低频通用型虚拟机,云任务ct1在进行映射时会选择m5a.large(Low-frequency Universal)型虚拟机,分别根据式(1)和(2)计算实际需要时间和截止时间,同时针对其它的云任务也采用相同的方法进行部署。

表2 云任务映射前的参数Tab.2 Parameters before cloud task mapping
1.3 云数据中心重调度
当云数据中心的虚拟机发生了故障,其对应的云任务就会执行失败。调度系统为了继续执行失效云任务则需要重新调度云任务并且激活新的虚拟机进行映射,如果激活相同配置的虚拟机则有可能导致云任务的完成时间超过截止时间,尤其是故障发生较晚的情况下,这种超时更加明显,使云服务提供商不仅面临较高的赔偿同时还会影响其声誉。因此,调度系统通常会同比例地扩大虚拟机配置从而确保云任务能够按时完成。但是,这样也会大幅地增加云服务提供商的运营成本。通过对Amazon和Alibaba Cloud等云服务提供商所提供的虚拟机进行分析,云用户通常租用的是低频通用型虚拟机,也可以通过使用高频型或计算型虚拟机进行执行速率的提升,从表1中可以看出它们的价格依次上升。据此笔者提出失效云任务分类定义。
定义1.失效云任务分类。对于失效云任务进行重映射时,可以通过改变虚拟机的类型从而使失效云任务满足其截止时间。若使用原配置的虚拟机则可满足截止时间则将该失效云任务归为低频通用型云任务。若需将故障CPU的频率升高为3.1 GHz则可满足截止时间,则将该失效云任务归为高频通用型云任务。若需将故障CPU核数量和内存大小的比率升高为4∶8则可满足截止时间,则将该失效云任务归为低频计算型云任务。若需同时升高两个方面可满足截止时间,则将该失效云任务归为高频计算型云任务。若上面都不能满足,则将4种配置的虚拟机同比例扩大后选择成本最小的虚拟机进行归类和重映射。
依然采用前面的示例进行演示。假设虚拟机产生故障时间随机且其它参数不变,按照失效云任务动态分类定义进行分类,这3个失效云任务的分类结果见表3。

表3 虚拟机故障后的云任务分类Tab.3 Classification of cloud tasks after virtual machine failure
经过上面的分析,已经对失效云任务进行了分类,之后按照其所需的虚拟机参数激活相应的虚拟机进行重映射,重调度之后的虚拟机参数见表4。

表4 重调度后的虚拟机参数Tab.4 Parameters of virtual machine after rescheduling
通过上面的示例可以看出,3个失败的云任务在重映射后都满足了截止时间的要求。同时,失效云任务根据分类定义合理地选择了虚拟机。这样避免了盲目扩大虚拟机的容量,从而节约了运营的成本。
2 CAFT算法
CAFT算法通过提高云任务的故障修复率从而降低云服务提供商的损失。CAFT算法主要包括以下8个步骤:
Step 1:根据虚拟机的运行情况,依次选取故障虚拟机上的失效云任务。
Step 2:根据失效云任务的截止时间和故障虚拟机的参数确定云任务的类型。若为低频通用型云任务则转向Step 3,若为高频通用型云任务则转向Step 4,若为低频计算型云任务则转向Step 5,若为高频计算型云任务则转向Step 6,若上面都不能满足则转向Step 7。
Step3:在空闲的虚拟机队列中选择与原故障虚拟机参数相同的低频通用型虚拟机进行映射。之后转向Step 8。
Step4:在空闲的虚拟机队列中选择与原故障虚拟机参数相同的高频通用型虚拟机进行映射。之后转向Step 8。
Step5:在空闲的虚拟机队列中选择与原故障虚拟机参数相同的低频计算型虚拟机进行映射。之后转向Step 8。
Step6:在空闲的虚拟机队列中选择与原故障虚拟机参数相同的高频计算型虚拟机进行映射。之后转向Step 8。
Step7:将4种虚拟机参数同比例扩大后转向Step 2。
Step8:判断是否存在未重映射的云任务,若有则重复Step 2,否则结束整个调度算法。
3 测试结果
为了验证CAFT算法的效果,利用CloudSim实现了该策略。同时在CloudSim中又嵌入了一个仿真验证平台,在该仿真验证平台中模拟实现了IRW算法、RI算法和DTRDT算法。IRW算法主要是采用相同性能的虚拟机完成容错。RI算法相对于IRW算法加入了10%的副本复用。DTRDT算法在重调度时选择了容量同比例扩大的虚拟机完成部署。之后,又在该平台中加入了比较模块,它能够对不同映射算法之间的云数据中心故障修复率和云服务提供商的损失进行比较,同时Gao、Dorterler、Chen等[16-18]中的方法生成相应的云任务参数进行仿真。其它虚拟机参数参考Amazon所提供的真实虚拟机参数,如表5所示。本节将从云数据中心故障修复率和云服务提供商的损失进行验证,结果取1 000次仿真的平均值。云数据中心故障修复率为所有失败云任务重调度后按时完成的比例。云服务提供商的损失就是为了执行失败的云任务所多建立的虚拟机的费用加上违约的赔偿金。云数据中心故障修复率:
Fault_repair=n1/n2
(3)
其中,n1表示被修复的故障数量,n2表示所有的故障数量。
云服务提供商的损失:
(4)
其中,ct.fj表示编号为j的云任务的损失(单位:$)。
3.1 基于云任务数量的测试
验证算法效果随云任务数量的变化。虚拟机故障率取0.01,虚拟机价格取0.086,其它参数如表5所示。

表5 仿真参数Tab.5 Simulation parameters
从图1中可以看出,CAFT算法的故障修复率接近100%。这主要是因为在进行虚拟机的选择时按照失效云任务分类定义从小到大依次寻找可以满足截止时间的虚拟机,同时,升高频率和加大CPU的比例都可以加快云任务的执行速度。IRW算法在选择虚拟机时依旧采用原来的配置,因此大量的失效云任务超出了截止时间。RI算法增加了副本复制技术,它在云数据中心内增加了10%的虚拟机副本,这样虽然可以提高一些故障修复率但效果并不明显。DTRDT算法在进行虚拟机选择时只是单纯地扩大虚拟机配置,而没有利用升高频率和CPU比例的方法,因此故障修复率稍逊于CAFT策略。4种算法的效果随云任务数量的增大表现较为稳定。从图2可以看出RI算法的云服务提供商的损失最大,这主要是因为它采用了副本复制技术增加了额外的冗余。IRW算法和DTRDT算法的云服务提供商的损失略高于CAFT算法,这主要是因为它们的故障修复率较低,因而造成赔偿的金额较大。
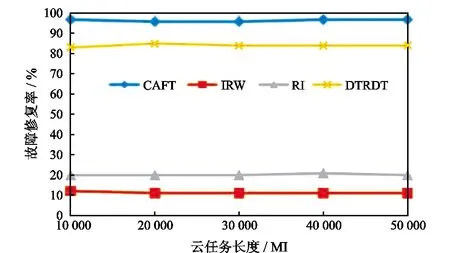
图1 云数据中心故障修复率随云任务数量的变化Fig.1 Variation of failure repair rate of cloud data center with the number of cloud tasks
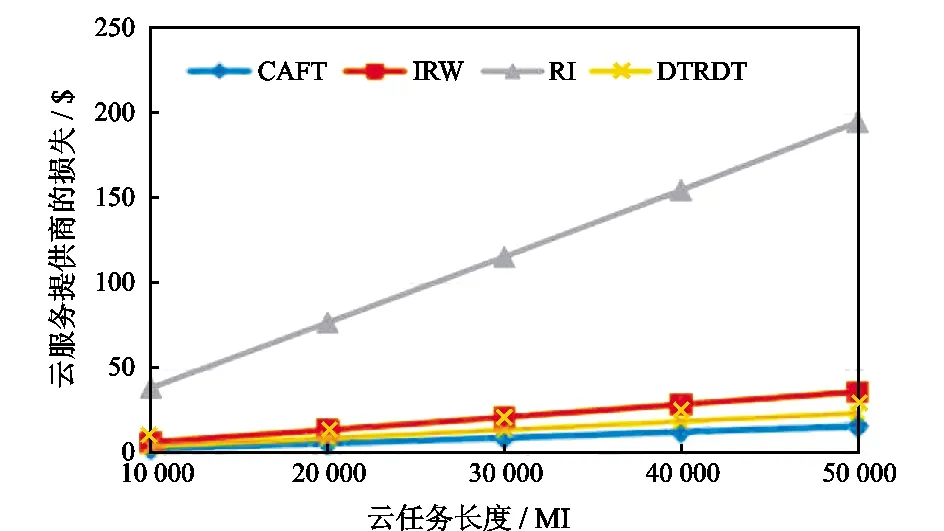
图2 云服务提供商的损失随云任务数量的变化Fig.2 Variation of loss of cloud service provider with the number of cloud tasks
3.2 基于虚拟机价格的测试
验证算法效果随虚拟机价格的变化。云任务数量取10 000,虚拟机故障率取0.01,其他参数见表5。
图3和图4中选取的为Amazon在美国东部(俄亥俄)、亚太地区(新加坡)、亚太地区(东京)和欧洲(爱尔兰)的4个云数据中心的真实价格。可以看出无论是哪个数据中心,CAFT算法的故障修复率都高于其它3种算法,相应的云服务提供商的损失也小于其它3种算法,这也说明了本文所提出的算法的通用性。
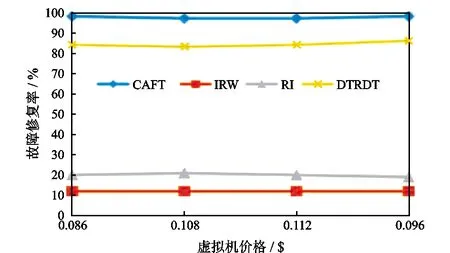
图3 云数据中心故障修复率随虚拟机价格的变化Fig.3 Variation of failure repair rate of cloud data center with the price of virtual machines
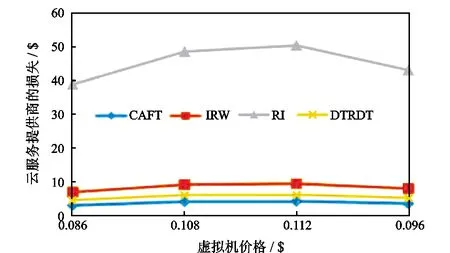
图4 云服务提供商的损失随虚拟机价格的变化Fig.4 Variation of loss of cloud service provider with the price of virtual machines
4 结 论
(1)分析了云数据中心的整体架构和模型。
(2)研究了云任务的初始化映射和虚拟机故障。
(3)提出了面向云数据中心的成本感知容错算法(CAFT)。
(4)借助CloudSim实现了该算法,利用Amazon云数据中心的真实数据验证了所提出的CAFT算法的效果。相比于IRW、RI和DTRDT算法,CAFT算法极大地提高了云数据中心故障修复率,降低了云服务提供商的损失。
猜你喜欢
机械研究与应用(2022年4期)2022-09-15 02:21:32
中国经贸导刊(2020年2期)2020-06-01 07:53:52
铁道通信信号(2020年10期)2020-02-07 01:01:32
成都信息工程大学学报(2019年3期)2019-09-25 08:31:10
三门峡职业技术学院学报(2019年1期)2019-06-27 07:32:58
计算机世界(2018年36期)2018-10-15 09:29:18
电子测试(2018年11期)2018-06-26 05:56:24
软科学(2017年3期)2017-03-31 17:18:32
中国交通信息化(2015年3期)2015-06-05 03:53:30
电视技术(2014年4期)2014-04-17 03:35:10
