
基于Mask R-CNN的行道树实例分割方法
2021-10-20 08:25陆清屿李秋洁童岳凯王明霞袁鹏成
林业工程学报 2021年5期
陆清屿,李秋洁,童岳凯,王明霞,袁鹏成
(南京林业大学机械电子工程学院,南京 210037)
行道树资源调查是现代林业资源调查的重要工作,目前主要采用人工实测、抽样调查的方法获取行道树树种、科属、胸径、树高、冠幅等参数,工作量大,效率低下,不能及时准确地反映行道树动态变化情况[1],因此快速高效地获取行道树参数具有重要的理论意义和实践价值。获取行道树参数的首要问题是如何快速从多样化的城市道路中分割出行道树。当前行道树信息采集方法主要有激光雷达扫描和图像拍摄两种[2-3],激光雷达作为一种主动遥感技术,运用激光波束扫描道路两侧地物信息获得街道三维点云数据,并对行道树划分网格索引[4-5],结合使用ICP、N-cut等算法,最终分割出行道树[6-7]。图像数据具有分辨率高、成本低、易获取的特点,并且可以更直观地反映行道树的色泽、纹理、树种等特征,已有的树木图像分割方法主要采用传统图像处理方法,如运用颜色的不连续性划分、基于相似区域增长、基于小波变换、基于局部二值特征等[8-11]。这些方法存在一定的局限性,具体体现在:街道环境较为复杂,较难分辨树林、草丛、灌木等与行道树相似的地物,难以滤除房屋、路面、路灯、汽车、广告牌等其他地物;行道树存在树冠相粘连的情况,在单木尺度上进行行道树分割也存在一定困难;空间位置和颜色属于各图像数据的底层固有特征,为实现精细分割应提取更加复杂的特征,如树冠结构、纹理等。
深度学习是近年来不断发展的新兴学科,利用端到端的模型处理方式,在林业的树种分类、森林预测、木材缺陷检测等方面都有成功的应用。目前行道树分割模型的研究大多基于卷积神经网络(convolutional neural network,CNN)模型,主要研究行道树的目标检测问题,即预测行道树的类别和边界框,如张良[12]采用基于YOLO深度学习算法进行分类以获取行道树的树种和边界框信息;乔莲花等[13]将随机森林模型与深度学习网络结合提取行道树的位置信息;沈雨等[14]基于Faster R-CNN提出一种分部加权策略实现行道树的目标检测。综合主流的目标检测网络,可提高算法的计算效率,如董彦锋等[15]采用YOLO-v2网络先完成目标定位再做实例分割;姚英楠[16]利用Mobile NetV2替换RPN网络等。
基于深度学习的行道树目标检测算法仅输出行道树的分类和边界框,无法解决有树冠相连的行道树分割问题,且无法提取行道树的精确形状。笔者基于深度学习的Mask R-CNN算法提出一种行道树实例分割(instance segmentation)方法,即对于图像的每个行道树实例都产生与原图相同大小的一层分割掩膜(mask),从而实现行道树的精细分割。本方法通过迁移学习的策略共享模型参数,并在行道树图像数据集上实现实例分割。
1 行道树实例分割方法
本研究提出的行道树实例分割算法可分为数据集采集、数据集标注、数据变换与扩充、模型训练和检测结果分析5个部分。其具体流程见图1。

图1 行道树实例分割算法Fig. 1 Instance segmentation algorithm of street trees
1.1 实例分割算法Mask R-CNN
Mask R-CNN算法在2018年由He等[17]首次提出,该算法以Faster R-CNN为基础,不仅能够准确分类目标实例,输出目标边界框,还能精细分割出实例的分割掩膜,该算法流程见图2[18]。模型首先将原始图像输入主干CNN网络提取特征,再将CNN输出的特征向量和原图一起输入区域建议网络(region proposal network,RPN)生成候选区域。RPN输出的候选区域和对应特征向量将会进入感兴趣区域(region of interest,RoI)对齐层,对齐层的输出分成两个分支,其中分类检测分支经过全连接层转换后,对每个RoI区域输出概率最高的类别,并预测边界框。掩膜预测分支使用全卷积网络(fully convolutional network,FCN)针对RoI区域对每个分类都生成一幅二值掩膜图,根据先前计算的分类输出概率最高分类的二值掩膜,完成像素级分割。Mask R-CNN可用于多分类问题,本研究设置分类数量时仅采用两个类别,即背景和行道树。
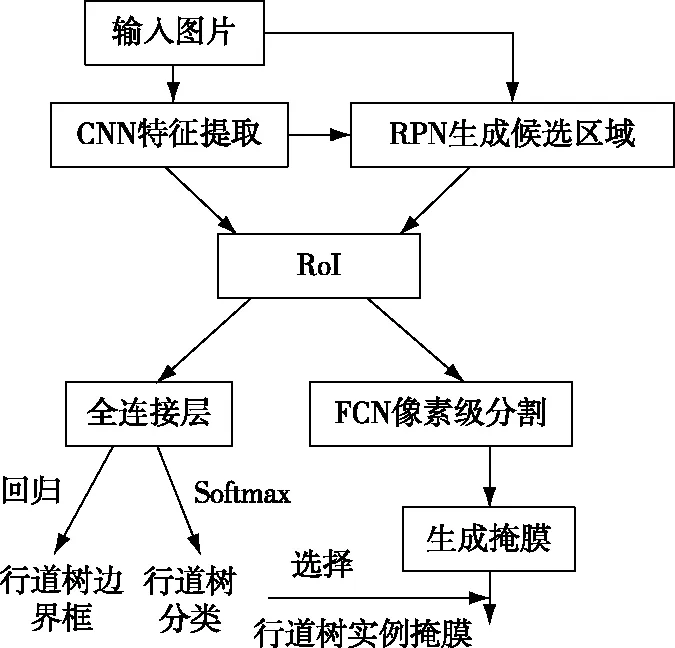
图2 Mask R-CNN算法Fig. 2 Mask R-CNN algorithm
Mask R-CNN算法针对实例分割问题,进行了两点改进。
1)在RPN网络中引入了特征金字塔网络(feature pyramid network,FPN)[19],FPN对不同维度的特征图进行特征融合,以提升特征提取的效率。FPN的网络结构见图3。FPN主要由3种不同路径构成,第1种为自底向上的降采样过程(图3①),该过程每次将特征图的长宽缩小为前一层的一半,从而得到多种不同大小的语义特征;第2种为自顶向下的上采样过程(图3②),每层特征图的长宽扩大到前一层的2倍;第3种为横向连接过程(图3③),指的是第2种路径在上采样前会与第一种路径中相同尺寸的区域进行特征融合;融合后的结果采用3×3的卷积核进行提取,最终输出特征图既有良好的空间信息又具有丰富的语义特征。

图3 特征金字塔网络Fig. 3 Feature pyramid network
2)在RoI对齐层引入双线性插值算法,使后端网络的掩膜分割结果更加精细准确。双线性插值算法和RoI对齐层的处理方法见图4。双线性插值是数值分析中的一种插值算法(图4a),该算法主要用于解决坐标为浮点数的像素点数值的计算问题。其原理[20]简述如下。
设待插值节点为P(x,y),其周围的整数坐标节点分别为M11(x1,y1)、M12(x1,y2)、M21(x2,y1)、M22(x2,y2),中间节点坐标分别为N1(x,y1)、N2(x,y2),各点处的像素值用f(·)表示。先对x方向进行线性插值:
(1)
(2)
再对y方向进行线性插值:
(3)
对特征区域的每个候选单元,利用上述的双线性插值算法计算4个固定坐标像素值,再进行最大池化操作(图4b),得到RoI对齐层的输出。

图4 RoI对齐层Fig. 4 RoI align layer
1.2 模型初始化与训练
训练深度学习模型需要巨大的计算资源或使用庞大的数据集,在样本量过小时模型难以收敛,也无法具备很好的检测能力。为解决行道树图像数据集规模较小的问题,模型初始化时采用迁移学习的策略,将大型图片数据集中已经预训练好的网络参数迁移到图像数据集的Mask R-CNN模型上来,这样模型已经具有了一定的特征提取能力,方便模型快速收敛。
本研究采用COCO图像数据集来进行模型预训练,它是由微软公司在2014年创建的一个权威性的用于目标检测的大型图像数据集,包括91类目标、328 000幅图像和约2 500 000个图像掩膜标注。
模型训练时采取多任务损失函数来计算损失,计算公式为:
L=Lcls+Lbox+Lmask
(4)
式中:Lcls为分类损失,指的是RPN在预测锚点时分类是否正确的二分类平均交叉熵损失;Lbox为边界框的回归损失,指的是每个边界框结果与真实边界框之间各个偏移量之和的平均交叉熵损失;Lmask为将每个RoI区域的掩膜与真值掩膜进行各像素比较,并将结果经过sigmoid函数,最后计算平均交叉熵损失。
1.3 模型检测指标
采用平均交并比(mean intersection of union,mIoU)、平均查准率(average precision,AP)、平均查全率(average recall,AR)3个指标对模型检测结果进行评价。交并比rIoU用于衡量检测结果掩膜与真值掩膜之间的重叠程度,即:
(5)
式中:Ωtr为检测结果掩膜;Ωgt为真值掩膜;SΩtr∩Ωgt为两掩膜相交的部分面积;SΩtr∪Ωgt为两掩膜所占有的所有面积。rIoU值越接近1,说明检测结果掩膜与真值掩膜越接近,实例分割的效果越好。
查准率指标rap为正确识别出的行道树数量与总识别出的行道树数量之比,计算方法如下:
(6)
式中:ntp为正确识别出的行道树数量;nfn为错将背景识别成行道树的数量。
查全率指标rar为正确识别出的行道树数量与真实的行道树总数量之比,计算方法如下:
(7)
式中,ntn为未检测出的行道树数量。
2 结果与分析
2.1 数据采集
根据行道树实例分割方法,实验图像数据集采用华为荣耀V30手机拍摄,共741张,每张图像为jpg格式,尺寸是2 976×3 968像素,均为RGB三通道,拍摄地点在南京林业大学、南京玄武湖、江苏盐城大丰区南阳镇附近;道路种类包含城市道路、乡村道路、景区道路;树种可分为常绿树和落叶树,落叶树包括柳(Salix)、银杏(Ginkgobiloba)、悬铃木(Platanus)等,常绿树包括香樟(Cinnamomumcamphora)、广玉兰(Magnoliagrandiflora)、棕榈(Trachycarpusfortunei)等。图像数据集共含行道树1 028棵,各树种图片及树木数量如表1所示。

表1 树种图片及树木数量Table 1 Number of images and trees of different tree species
2.2 数据预处理与数据集划分
获取行道树图像数据后,需对数据进行标注。实验采用开源图像标注软件VGG Image Annotator(VIA)对行道树图像进行人工标注。标注时,沿着行道树树冠和树干边缘取点组成一个多边形,就完成了一棵行道树的轮廓标注。将标注中的多边形以顶点的形式保存,然后对每一棵标注的行道树建立一张与原图像数据相同尺寸的图像文件,将该文件中所有在行道树轮廓内的像素点设为白色,其他像素点设为黑色,按此方法构造的图像标注即为掩膜。该软件的在线版本标注界面见图5a,标注后提取的掩膜文件示例见图5b。

图5 软件标注界面与生成的掩膜Fig. 5 Annotation software interface and generated masks
为保证图像数据尺寸相同,本实验调整行道树数据集的图像文件和掩膜文件尺寸均为512×512×3。尺寸统一后带掩膜的图像数据文件见图6。为扩充样本数量,缓解过拟合,对加入训练的图像数据集采取水平翻转的扩充措施。

图6 带掩膜的图像形成过程Fig. 6 Combination of images and masks
本实验数据经预处理后,得到的图像数据集图片总数为1 482张。对图像顺序随机打乱,并按6∶2∶2的比例进行数据集划分,划分出894张作为训练集,294张作为验证集,294张行道树图像用于检测。
2.3 实验平台与模型参数
实验使用的深度学习模型是Matterport开发的Mask R-CNN开源代码,采用的基础神经网络模型是Resnet-101残差卷积网络模型,在深脑链公司提供的GPU硬件平台上进行训练。实验平台配置如表2所示。

表2 实验平台配置Table 2 Experiment platform configuration
实验使用的模型配置参数如表3所示。

表3 模型参数配置Table 3 Model configuration parameters
2.4 深度学习模型训练
对行道树数据集的训练包括两个阶段:1)对除主干CNN以外的其他网络训练,包括RPN、FCN、RoI对齐层和全连接层。这些网络是随机初始化的,先以0.001的学习率训练迭代20轮,每轮1 000次;2)对所有网络微调。以0.000 1的学习率对所有网络进行微调训练迭代20轮,每轮1 000次,使网络充分收敛,具备对行道树实例分割能力。网络训练过程中L1损失下降的情况见图7。从图中可看出,模型损失下降速度很快,约30轮后趋于收敛。

图7 损失下降曲线Fig. 7 Loss reduction curve
2.5 检测结果与分析
测试集共使用294张图片进行检测,并通过对比真值掩膜,计算相关评价指标。实验中认为,真值掩膜与检测掩膜的rIoU≥0.5时,识别结果是正确的。部分代表性的检测结果见图8,相关评价指标计算结果见表4。

表4 模型性能评价Table 4 Model performance assessment %

图8 模型检测结果Fig. 8 Detection results
对实验结果进行分析,可得出以下结论:
1)检测出的行道树掩膜与真实行道树掩膜的平均交并比指标约为80%,能较好地实现行道树轮廓的精细分割。对于树冠枝叶相对密集、形状规则的行道树(如香樟、悬铃木、银杏等),树冠轮廓的分割结果相对完整(图8a、b、c、i、j);当行道树树冠较稀疏且生长不规则时(如柳、栎树、乌桕、棕榈等),树冠的边缘部分轮廓检测不够精确(图8h、k、l、m)。
2)行道树图像的平均查准率几乎都能达到95%以上,对无粘连或粘连较小的多棵行道树,能够实现精细分割(图8b、f、i、n);模型将行道树与路灯(图8a)、草地(图8j)、河流(图8g)、建筑(图8e)、行人(图8l)、车辆(图8i)等复杂地物进行了有效分离;树干部分的识别方面,若树干部分拍摄光线较暗(图8i)、涂白色石灰乳(图8c、j)、与河流、草丛地物重合(图8b、g)时,树干会出现识别不完整的情况;当树干较粗、相机到树木距离较近时,识别相对清晰(图8d、m)。
3)行道树图像的平均查全率均超过95%,说明对不同树种的行道树,模型都能识别出来。当只有不到一半的树冠部分出现在图像中时(图8o),或行道树在图像中所占面积较小,或电线杆与树木重叠时(图p),可能存在漏检情况。
4)检测一张图像平均消耗时间为0.476 s,由于行道树参数检测的实时性需求不高,因此该检测效率可满足行道树资源调查的需要。
3 结 论
本研究针对行道树实例分割问题,基于Mask R-CNN深度学习算法,提出一种行道树图像实例分割的策略,先对不同树种的行道树图像进行采集标注,接着进行图像变换扩充,最后训练行道树实例分割模型。本方法利用迁移学习的思想,将COCO图片数据集预训练的网络参数迁移到行道树实例分割模型上,并在此基础上进行微调。实验中采集了多个不同树种的行道树图像,经预处理得到1 482张的行道树图像数据集,模型训练好后在294张图像上进行测试,并对不同树种的测试结果进行对比分析。根据检测结果及评价指标,平均交并比约80%,平均查准率和查全率均达到95%,说明模型精度较高,能有效分割出行道树轮廓;相比传统方法,该模型不容易受到相近颜色、光照强度、照片亮度、对比度等影响,在不同树种的行道树图片数据集上有较强的泛化能力;模型检测速度大致为0.476 s/张。今后的工作准备在以下方面进行改进:为解决Mask R-CNN实时性不足的问题,可综合主流的目标检测网络,以减少Mask R-CNN模型的运行时间;通过优化网络结构和行道树图像数据集质量,增强树干部分和树冠轮廓等细节的分割完整性。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
电子技术与软件工程(2021年5期)2021-06-16
家教世界·创新阅读(2021年12期)2021-01-13
文萃报·周二版(2020年30期)2020-09-02
证券市场红周刊(2019年44期)2019-11-23
故事家·花开不败(2019年10期)2019-09-10
电子技术与软件工程(2018年5期)2018-04-09
散文诗世界(2017年7期)2017-07-25
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
